
模型训练完成后,可以通过EAS(Elastic Algorithm Service)快速部署为在线推理服务或AI-Web应用。EAS支持异构资源,结合自动扩缩容、一键压测、灰度发布、实时监控等能力,以更低成本保障高并发场景下的服务稳定性与业务连续性。
产品架构
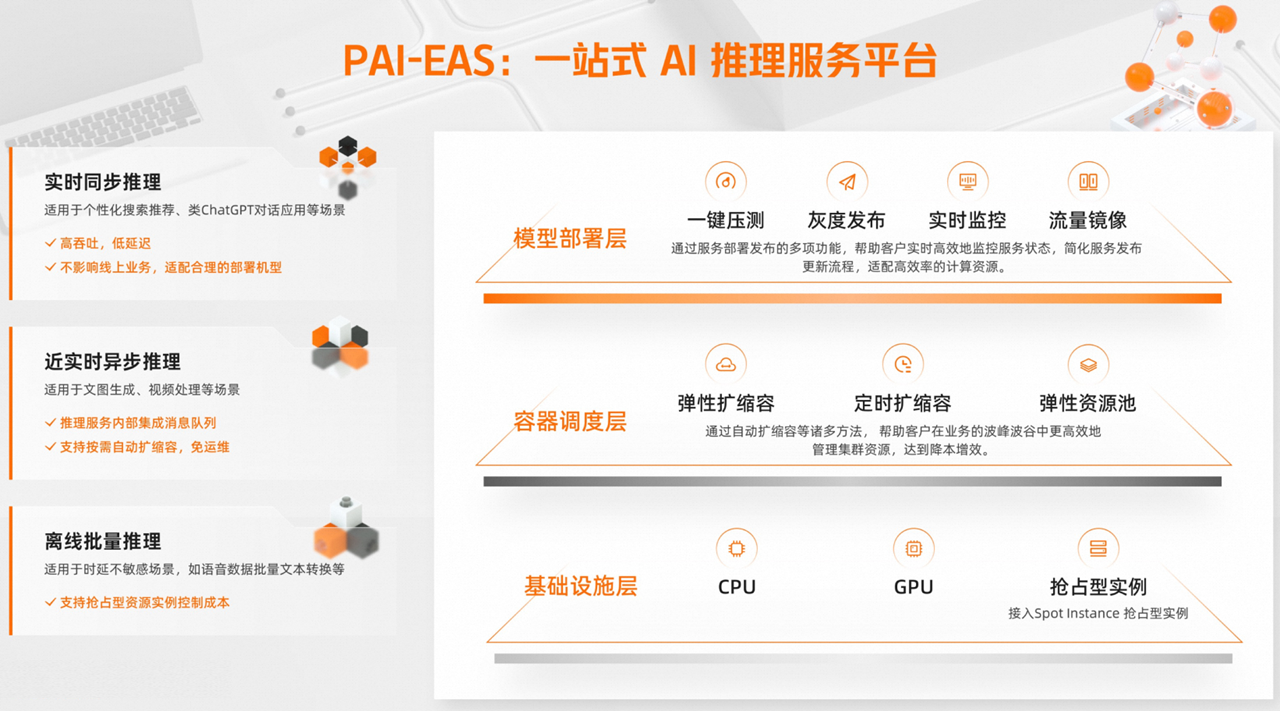
核心能力
EAS提供从资源管理、模型部署到服务运维的全链路能力,保障业务稳定、高效运行。
灵活的资源与成本管理
异构硬件支持:支持CPU、GPU及AI专属GU机型,满足不同模型的性能需求。
成本优化:支持使用抢占型实例,显著降低计算成本。通过定时扩缩容功能,可根据业务周期规律提前设定策略,精准控制资源投入。
弹性资源池:当专属资源组用满后,可自动将新增实例调度至公共资源组,在控制成本的同时保障服务的稳定性。
全面的稳定性与高可用保障
弹性扩缩容:根据实时负载自动调整服务副本数量,从容应对不可预测的流量高峰,避免资源闲置或服务过载。
高可用机制:提供自动故障恢复机制,确保服务连续性。专属资源为物理隔离,无资源抢占风险。
安全发布:支持灰度发布,可按比例分配流量至新版本进行验证。同时支持流量镜像,可将线上流量复制到测试服务进行可靠性验证,不影响真实用户请求。
高效的部署与运维
一键压测:提供一键压测功能,支持动态加压并自动探测服务性能极限,实时查看秒级监控数据与压测报告,帮助您快速评估服务能力。
实时监控:提供QPS、响应时长、CPU利用率等关键指标的实时监控,并支持开通服务监控报警,让您全面掌握服务运行状态。
多种部署方式:支持通过镜像(推荐)或Processor部署方式部署服务,满足不同技术栈的需求。
多样的推理模式
实时同步推理:具备高吞吐、低延迟特性,适用于对响应延迟敏感的场景,如搜索推荐、对话机器人等。具备高吞吐、低延迟特性。
近实时异步推理:内置消息队列,适用于文图生成、视频处理等长耗时任务。支持根据队列积压程度自动扩缩容,避免请求堆积。
离线批量推理:适用于响应时长不敏感的批量处理场景,如语音数据批量转换。同时支持抢占型资源实例,以控制成本。
使用流程
步骤1:准备工作
步骤2:部署服务
步骤3:调用与压测服务
步骤4:监控与管理服务
监控与报警:在推理服务列表中查看服务运行状态及各服务所使用的资源组信息,可按资源组筛选服务,快速定位使用特定资源组(如灵骏智算资源组)运行的服务。建议开通服务监控报警以实时掌握服务健康状况。
弹性伸缩:根据业务需求配置弹性扩缩容或定时扩缩容策略,实现计算资源的动态管理。
服务更新:在操作列下单击更新以部署新版本。更新完成后,可查看版本信息或切换版本。
警告服务更新过程中将暂时中断运行,可能导致依赖此服务的请求失败,请务必谨慎操作。
服务迁移:如需将EAS服务配置跨地域迁移(异地部署),可使用EASCMD命令行工具导出源地域(如北京)的服务配置,然后在目标地域(如上海)使用导出的配置文件创建新服务,实现配置导出与跨地域迁移部署。
重要提示
若EAS服务持续180天处于非运行中状态,系统将自动删除该服务。
EAS支持的地域参见地域和可用区。
计费说明
详情请参见模型在线服务(EAS)计费说明。
快速开始
场景案例
常见问题
Q:专属资源 vs 公共资源?
公共资源:适合对成本敏感、性能波动容忍度较高的开发测试或小规模业务。成本较低,但高峰期可能存在资源争用。
专属资源:适合对服务稳定性和性能有高要求的生产环境核心业务。物理隔离无抢占风险,弹性资源池特性允许在专属资源用满后,自动溢出到公共资源,兼顾成本与高峰期的业务稳定性。对于库存紧张的机型,需要通过专属资源锁定购买。
Q:EAS相比自建服务有什么优势?
EAS提供托管运维:自动处理资源调度、故障恢复和监控,提供标准化的弹性伸缩、灰度发布功能。开发者可专注模型开发,省去运维成本,加速上线。