
本文为您介绍如何搭建Spark on MaxCompute开发环境。
如果您安装了Windows操作系统,请前往搭建Windows开发环境。
前提条件
搭建Spark开发环境前,请确保您已经在Linux操作系统中安装如下软件:
本文采用的软件版本号及软件安装路径仅供参考,请根据您的操作系统下载合适的软件版本进行安装。
JDK
安装命令示例如下。JDK名称请以实际为准。具体的JDK名称可通过执行
sudo yum -y list java*获取。sudo yum install -y java-1.8.0-openjdk-devel.x86_64Python
安装命令示例如下。Python包名称请以实际为准。
# 获取Python包。 sudo wget https://www.python.org/ftp/python/2.7.10/Python-2.7.10.tgz # 解压缩Python包。 sudo tar -zxvf Python-2.7.10.tgz # 切换到解压后的目录,指定安装路径。 cd Python-2.7.10 sudo ./configure --prefix=/usr/local/python2 # 编译并安装Python。 sudo make sudo make installMaven
安装命令示例如下。Maven包路径请以实际为准。
# 获取Maven包。 sudo wget https://dlcdn.apache.org/maven/maven-3/3.8.7/binaries/apache-maven-3.8.7-bin.tar.gz # 解压缩Maven包。 sudo tar -zxvf apache-maven-3.8.7-bin.tar.gzGit
安装命令示例如下。
# 获取Git包。 sudo wget https://github.com/git/git/archive/v2.17.0.tar.gz # 解压缩Git包。 sudo tar -zxvf v2.17.0.tar.gz # 安装编译源码所需依赖。 sudo yum install curl-devel expat-devel gettext-devel openssl-devel zlib-devel gcc perl-ExtUtils-MakeMaker # 切换到解压后的目。 cd git-2.17.0 # 编译。 sudo make prefix=/usr/local/git all # 安装Git至/usr/local/git路径。 sudo make prefix=/usr/local/git install
下载Spark on MaxCompute客户端包并上传至操作系统
Spark on MaxCompute发布包集成了MaxCompute认证功能。作为客户端工具,它通过Spark-Submit方式提交作业到MaxCompute项目中运行。MaxCompute提供了面向Spark1.x、Spark2.x和Spark3.x发布包,下载路径如下:
Spark-1.6.3:适用于Spark1.x应用的开发。
Spark-2.3.0:适用于Spark2.x应用的开发。
Spark-2.4.5:适用于Spark2.x应用的开发。使用Spark-2.4.5的注意事项请参见Spark 2.4.5使用注意事项。
Spark-3.1.1:适用于Spark3.x应用的开发。使用Spark-3.1.1的注意事项请参见Spark 3.1.1使用注意事项。
将Spark on MaxCompute客户端包上传至Linux操作系统中,并解压。您可以进入Spark客户端包所在目录,执行如下命令解压包。
sudo tar -xzvf spark-2.3.0-odps0.33.0.tar.gz设置环境变量
下述设置环境变量的命令,只能由具有管理员权限的用户执行。
您需要在Linux操作系统的命令行执行窗口配置如下环境变量信息,配置方法及信息如下。
配置Java环境变量。
获取Java安装路径。命令示例如下。
# 如果通过yum方式安装,默认安装在usr目录下,您可以按照如下命令查找。如果您自定义了安装路径,请以实际路径为准。 whereis java ls -lrt /usr/bin/java ls -lrt /etc/alternatives/java # 返回信息如下。/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.322.b06-1.1.al7.x86_64即为安装路径。 /etc/alternatives/java -> /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.322.b06-1.1.al7.x86_64/jre/bin/java
编辑Java环境变量信息。命令示例如下。
# 编辑环境变量配置文件。 vim /etc/profile # 按下i进入编辑状态后,在配置文件末尾添加环境变量信息。 # JAVA_HOME需要修改为实际Java的安装路径。 export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.322.b06-1.1.al7.x86_64 export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar export PATH=$JAVA_HOME/bin:$PATH # 按ESC退出编辑,按:wq退出配置文件。 # 执行如下命令使修改生效。 source /etc/profile # 确认Java已配置成功。 java -version # 返回结果示例如下。 openjdk version "1.8.0_322" OpenJDK Runtime Environment (build 1.8.0_322-b06) OpenJDK 64-Bit Server VM (build 25.322-b06, mixed mode)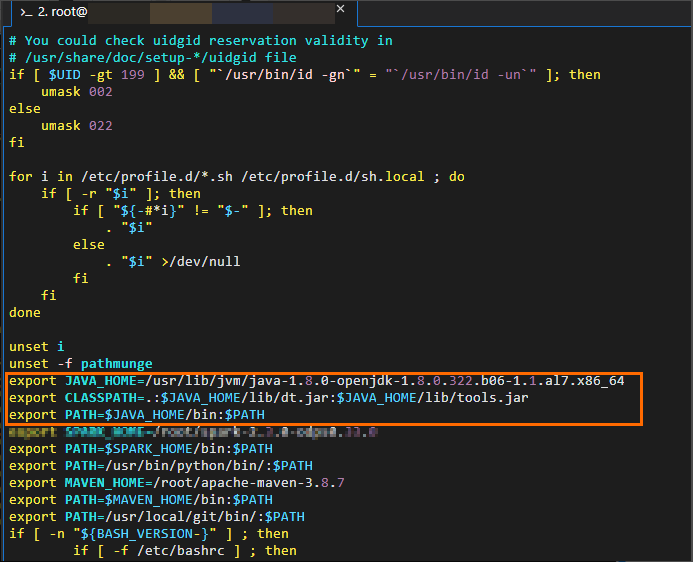
配置Spark环境变量。
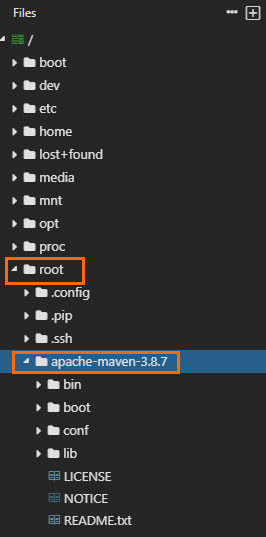
获取Spark客户端包解压后的路径。图示如下,表明包所在路径为
/home/spark-2.3.0-odps0.33.0。请以实际解压路径及名称为准。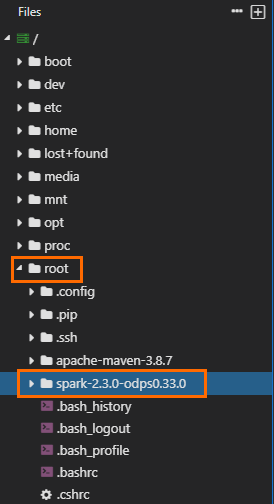
编辑Spark环境变量信息。命令示例如下。
# 编辑环境变量配置文件。 vim /etc/profile # 按下i进入编辑状态后,在配置文件末尾添加环境变量信息。 # SPARK_HOME需要修改为实际解压后的Spark客户端包所在路径。 export SPARK_HOME=/home/spark-2.3.0-odps0.33.0 export PATH=$SPARK_HOME/bin:$PATH # 按ESC退出编辑,按:wq退出配置文件。 # 执行如下命令使修改生效。 source /etc/profile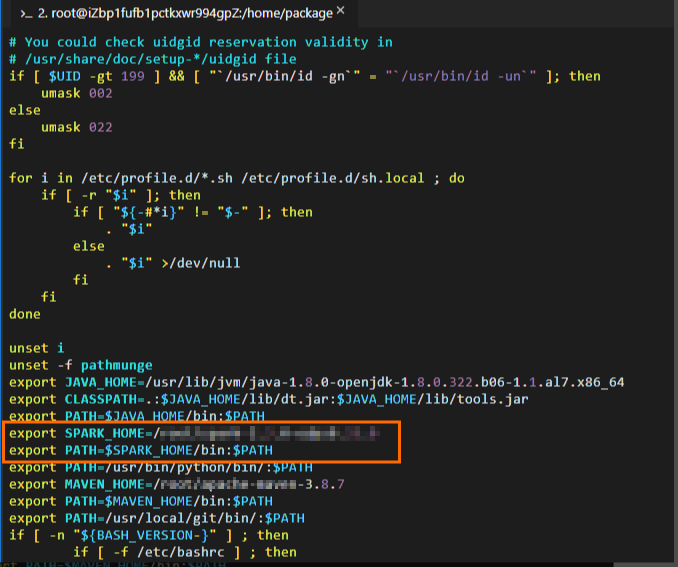
配置Python环境变量。
使用PySpark的用户,需要配置该信息。
获取Python安装路径。命令示例如下。

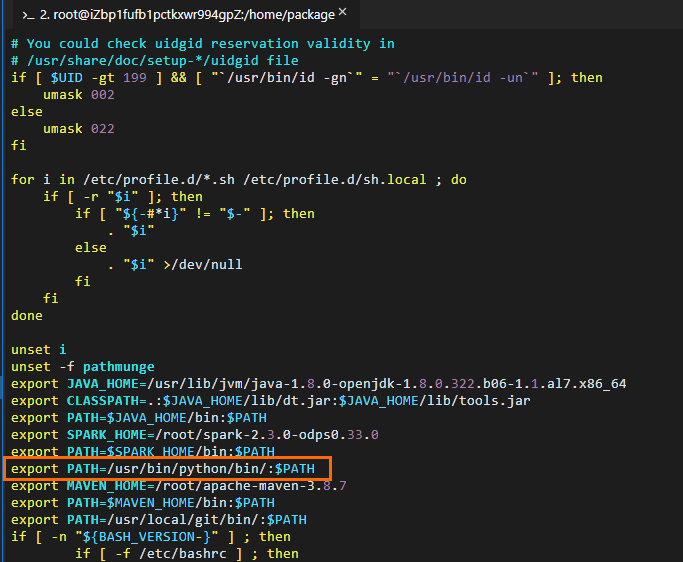
编辑Python环境变量信息。命令示例如下。
# 编辑环境变量配置文件。 vim /etc/profile # 按下i进入编辑状态后,在配置文件末尾添加环境变量信息。 # PATH需要修改为Python的实际安装路径。 export PATH=/usr/bin/python/bin/:$PATH # 按ESC退出编辑,按:wq退出配置文件。 # 执行如下命令使修改生效。 source /etc/profile # 确认Python已配置成功。 python --version # 返回结果示例如下。 Python 2.7.5
配置Maven环境变量。
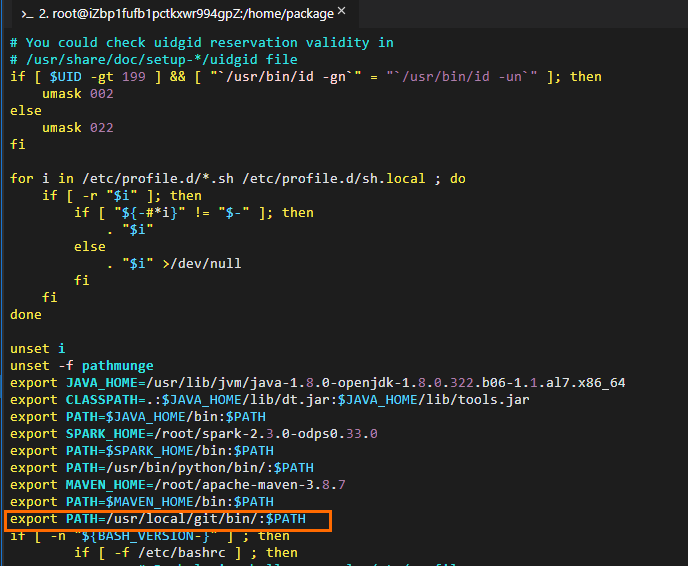
获取Maven包解压后的路径。图示如下,表明包所在路径为
/home/apache-maven-3.8.7。请以实际解压路径及名称为准。编辑Maven环境变量信息。命令示例如下。
# 编辑环境变量配置文件。 vim /etc/profile # 按下i进入编辑状态后,在配置文件末尾添加环境变量信息。 # MAVEN_HOME需要修改为实际解压后的Maven包所在路径。 export MAVEN_HOME=/home/apache-maven-3.8.7 export PATH=$MAVEN_HOME/bin:$PATH # 按ESC退出编辑,按:wq退出配置文件。 # 执行如下命令使修改生效。 source /etc/profile # 确认Maven已配置成功。 mvn -version # 返回结果示例如下。 Apache Maven 3.8.7 (9b656c72d54e5bacbed989b64718c159fe39b537) Maven home: /home/apache-maven-3.8.7 Java version: 1.8.0_322, vendor: Red Hat, Inc., runtime: /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.322.b06-1.1.al7.x86_64/jre Default locale: en_US, platform encoding: UTF-8 OS name: "linux", version: "4.19.91-25.1.al7.x86_64", arch: "amd64", family: "unix"
配置Git环境变量。
获取Git安装路径。命令示例如下。
whereis git编辑Git环境变量信息。命令示例如下。
# 编辑环境变量配置文件。 vim /etc/profile # 按下i进入编辑状态后,在配置文件末尾添加环境变量信息。# PATH需要修改为Git的实际安装路径。 export PATH=/usr/local/git/bin/:$PATH # 按ESC退出编辑,按:wq退出配置文件。 # 执行如下命令使修改生效。 source /etc/profile # 确认Git已配置成功。 git --version # 返回结果示例如下。 git version 2.24.4

配置spark-defaults.conf
第一次使用Spark on MaxCompute客户端时,请在Spark客户端包的解压路径下,将conf文件夹下的spark-defaults.conf.template文件重命名为spark-defaults.conf后再进行相关配置。如果没有对文件进行重命名,将会导致配置无法生效。命令示例如下。
# 切换至Spark客户端包的解压路径,并进入conf文件夹。请以实际路径为准。
cd /home/spark-2.3.0-odps0.33.0/conf
# 修改文件名。
mv spark-defaults.conf.template spark-defaults.conf
# 编辑spark-defaults.conf。
vim spark-defaults.conf
# 按下i进入编辑状态后,在配置文件末尾添加如下配置信息。
spark.hadoop.odps.project.name = <MaxCompute_project_name>
spark.hadoop.odps.access.id = <AccessKey_id>
spark.hadoop.odps.access.key = <AccessKey_secret>
spark.hadoop.odps.end.point = <Endpoint> # Spark客户端连接访问MaxCompute项目的Endpoint,您可以根据自己情况进行修改。详情请参见Endpoint。
# spark 2.3.0请将spark.sql.catalogImplementation设置为odps,spark 2.4.5请将spark.sql.catalogImplementation设置为hive。
spark.sql.catalogImplementation={odps|hive}
# 如下参数配置保持不变
spark.hadoop.odps.task.major.version = cupid_v2
spark.hadoop.odps.cupid.container.image.enable = true
spark.hadoop.odps.cupid.container.vm.engine.type = hyper
spark.hadoop.odps.moye.trackurl.host = http://jobview.odps.aliyun.comMaxCompute_project_name:待访问MaxCompute项目的名称。
此处为MaxCompute项目名称,非工作空间名称。您可以登录MaxCompute控制台,左上角切换地域后,在左侧导航栏选择工作区 > 项目管理,查看具体的MaxCompute项目名称。
AccessKey_id:具备目标MaxCompute项目访问权限的AccessKey ID。
您可以进入AccessKey管理页面获取AccessKey ID。
AccessKey_secret:AccessKey ID对应的AccessKey Secret。
您可以进入AccessKey管理页面获取AccessKey Secret。
Endpoint:MaxCompute项目所属区域的外网Endpoint。
各地域的外网Endpoint信息,请参见各地域Endpoint对照表(外网连接方式)。
VPC_endpoint:MaxCompute项目所属区域的VPC网络的Endpoint。
各地域的VPC网络Endpoint信息,请参见各地域Endpoint对照表(阿里云VPC网络连接方式)。
特殊场景和功能,需要开启一些其他的配置参数,详情请参见Spark配置详解。
准备项目工程
Spark on MaxCompute提供了项目工程模板,建议您下载模板复制后直接在模板里开发。
模板工程里的关于spark依赖的scope为provided,请不要更改,否则提交的作业无法正常运行。
准备项目工程命令示例如下:
下载Spark-1.x模板并编译
git clone https://github.com/aliyun/MaxCompute-Spark.git cd MaxCompute-Spark/spark-1.x mvn clean package下载Spark-2.x 模板并编译
git clone https://github.com/aliyun/MaxCompute-Spark.git cd MaxCompute-Spark/spark-2.x mvn clean package下载Spark-3.x 模板并编译
git clone https://github.com/aliyun/MaxCompute-Spark.git cd MaxCompute-Spark/spark-3.x mvn clean package
上述命令执行完毕后,如果显示创建失败,说明环境配置有误,请按照上述配置指导仔细检查并修正环境配置信息。
配置依赖说明
在准备的Spark on MaxCompute项目下,配置依赖信息。命令示例如下。
配置访问MaxCompute表所需的依赖。
使用Spark-1.x模板场景
# 进入spark-1.x文件夹。 cd MaxCompute-Spark/spark-1.x # 编辑Pom文件,添加odps-spark-datasource依赖。 <dependency> <groupId>com.aliyun.odps</groupId> <artifactId>odps-spark-datasource_2.10</artifactId> <version>3.3.8-public</version> </dependency>使用Spark-2.x模板场景
# 进入spark-2.x文件夹。 cd MaxCompute-Spark/spark-2.x # 编辑Pom文件,添加odps-spark-datasource依赖。 <dependency> <groupId>com.aliyun.odps</groupId> <artifactId>odps-spark-datasource_2.11</artifactId> <version>3.3.8-public</version> </dependency>
配置访问OSS所需的依赖。
如果作业需要访问OSS,直接添加以下依赖即可。
<dependency> <groupId>com.aliyun.odps</groupId> <artifactId>hadoop-fs-oss</artifactId> <version>3.3.8-public</version> </dependency>
更多Spark-1.x、Spark-2.x以及Spark-3.x的依赖配置信息,请参见Spark-1.x pom文件、Spark-2.x pom文件和Spark-3.x pom文件。
引用外部文件
用户在开发过程中涉及到如下场景时,需要引用外部文件:
作业需要读取一些配置文件。
作业需要额外的资源包或第三方库。例如JAR包、Python库。
在实际操作中,您需要先上传文件后才可以引用文件,上传文件方式有以下两种,任选其中一种即可:
方式一:通过Spark参数上传文件
Spark on MaxCompute支持Spark社区版原生的
--jars、--py-files、--files、--archives参数,您可以在提交作业时,通过这些参数上传文件,这些文件在作业运行时会被上传到用户的工作目录下。通过Spark on MaxCompute客户端,使用Spark-Submit方式上传文件。
说明--jars:会将配置的JAR包上传至Driver和Executor的当前工作目录,多个文件用英文逗号(,)分隔。这些JAR包都会加入Driver和Executor的Classpath。在Spark作业中直接通过"./your_jar_name"即可引用,与社区版Spark行为相同。--files、--py-files:会将配置的普通文件或Python文件上传至Driver和Executor的当前工作目录,多个文件用英文逗号(,)分隔。在Spark作业中直接通过"./your_file_name"即可引用,与社区版Spark行为相同。--archives:与社区版Spark行为略有不同,多个文件用英文逗号(,)分隔,配置方式为xxx#yyy,会将配置的归档文件(例如.zip)解压到Driver和Executor的当前工作目录的子目录中。例如当配置方式为xx.zip#yy时,应以"./yy/xx/"引用到归档文件中的内容;当配置方式为xx.zip时,应以"./xx.zip/xx/"引用到归档文件中的内容。如果一定要将归档内容直接解压到当前目录,即直接引用"./xxx/",请使用下文中的spark.hadoop.odps.cupid.resources参数进行配置。
通过DataWorks,添加作业需要的资源,操作详情请参见创建并使用MaxCompute资源。
说明DataWorks中上传资源限制最大为200 MB,如果需要使用更大的资源,您需要通过MaxCompute客户端将资源上传为MaxCompute资源,并将资源添加至数据开发面板。更多MaxCompute资源信息,请参见MaxCompute资源管理。
方式二:通过MaxCompute资源上传文件
Spark on MaxCompute提供
spark.hadoop.odps.cupid.resources参数,可以直接引用MaxCompute中的资源,这些资源在作业运行时会被上传到用户的工作目录下。使用方式如下:通过MaxCompute客户端将文件上传至MaxCompute项目。单个文件最大支持500 MB。
在Spark作业配置中添加
spark.hadoop.odps.cupid.resources参数,指定Spark作业运行所需要的MaxCompute资源。格式为<projectname>.<resourcename>,如果需要引用多个文件,需要用英文逗号(,)分隔。配置示例如下:spark.hadoop.odps.cupid.resources=public.python-python-2.7-ucs4.zip,public.myjar.jar指定的资源将被下载到Driver和Executor的当前工作目录,资源下载到工作目录后默认名称是
<projectname>.<resourcename>。此外,您可以在配置时通过
<projectname>.<resourcename>:<newresourcename>方式重命名资源名称。配置示例如下:spark.hadoop.odps.cupid.resources=public.myjar.jar:myjar.jar重要该配置项必须在spark-defaults.conf或DataWorks的配置项中进行配置才能生效,不能写在代码中。
通过上述两种方式将文件上传后,即可在代码中引用文件,文件读取示例如下:
val targetFile = "文件名"
val file = Source.fromFile(targetFile)
for (line <- file.getLines)
println(line)
file.closeSparkPi冒烟测试
完成以上的工作之后,执行冒烟测试,验证Spark on MaxCompute是否可以端到端连通。以Spark-2.x为例,您可以提交一个SparkPi验证功能是否正常,提交命令如下。
# /path/to/MaxCompute-Spark请指向正确的编译出来后的应用程序的Jar包。
cd $SPARK_HOME
bin/spark-submit \
--class com.aliyun.odps.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
/path/to/your/spark-examples_2.11-1.0.0-SNAPSHOT-shaded.jar
# 当看到以下日志表明冒烟作业成功。
19/06/11 11:57:30 INFO Client:
client token: N/A
diagnostics: N/A
ApplicationMaster host: 11.222.166.90
ApplicationMaster RPC port: 38965
queue: queue
start time: 1560225401092
final status: SUCCEEDEDIDEA本地执行注意事项
通常,本地调试成功后会在集群上执行代码。但是Spark可以支持在IDEA里以Local模式直接运行代码,运行时请注意以下几点:
代码需要手动设置spark.master。
val spark = SparkSession .builder() .appName("SparkPi") .config("spark.master", "local[4]") // 需要设置spark.master为local[N]才能直接运行,N为并发数。 .getOrCreate()在IDEA里手动添加Spark on MaxCompute客户端的相关依赖。
<dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_${scala.binary.version}</artifactId> <version>${spark.version}</version> <scope>provided</scope> </dependency>pom.xml中设置要求scope为provided,所以运行时会出现NoClassDefFoundError报错。
Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/spark/sql/SparkSession$ at com.aliyun.odps.spark.examples.SparkPi$.main(SparkPi.scala:27) at com.aliyun.odps.spark.examples.Spa。r。kPi.main(SparkPi.scala) Caused by: java.lang.ClassNotFoundException: org.apache.spark.sql.SparkSession$ at java.net.URLClassLoader.findClass(URLClassLoader.java:381) at java.lang.ClassLoader.loadClass(ClassLoader.java:424) at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:335) at java.lang.ClassLoader.loadClass(ClassLoader.java:357) ... 2 more您可以按照以下方式手动将Spark on MaxCompute下的Jars目录加入IDEA模板工程项目中,既可以保持
scope=provided,又能在IDEA里直接运行不报错:在IDEA中单击顶部菜单栏上的File,选中Project Structure…。
在Project Structure页面,单击左侧导航栏上的Modules。选择资源包,并单击资源包的Dependencies页签。
在资源包的Dependencies页签下,单击左下角的+,选择JARs or directories…添加Spark on MaxCompute下的Jars目录。
Local不能直接引用spark-defaults.conf里的配置,需要手动指定相关配置。
通过Spark-Submit方式提交作业,系统会读取spark-defaults.conf文件中的配置。通过Local模式提交作业,需要手动在代码里指定相关配置。例如,在Local模式下如果要通过Spark-Sql读取MaxCompute的表,配置如下。
val spark = SparkSession .builder() .appName("SparkPi") .config("spark.master", "local[4]") // 需设置spark.master为local[N]才能直接运行,N为并发数。 .config("spark.hadoop.odps.project.name", "****") .config("spark.hadoop.odps.access.id", "****") .config("spark.hadoop.odps.access.key", "****") .config("spark.hadoop.odps.end.point", "http://service.cn.maxcompute.aliyun.com/api") .config("spark.sql.catalogImplementation", "odps") .getOrCreate()
Spark 2.4.5使用注意事项
使用Spark 2.4.5提交作业
直接使用Yarn-cluster模式在本地提交任务。详情请参见Cluster模式。
在DataWorks中配置参数
spark.hadoop.odps.spark.version=spark-2.4.5-odps0.33.0。当前DataWorks独享资源组尚未升级到Spark 2.4.5,用户可以采用公共资源组进行调度,或联系MaxCompute技术支持团队进行升级。
Spark 2.4.5使用变化
如果使用Yarn-cluster模式在本地提交任务,需要新增环境变量
export HADOOP_CONF_DIR=$SPARK_HOME/conf。如果使用Local模式进行调试,需要在
$SPARK_HOME/conf目录下新建odps.conf文件,并添加如下配置。odps.project.name = odps.access.id = odps.access.key = odps.end.point =
Spark 2.4.5参数配置变化
spark.sql.catalogImplementation配置为hive。spark.sql.sources.default配置为hive。spark.sql.odps.columnarReaderBatchSize,向量化读每个batch包含的行数,默认值为4096。spark.sql.odps.enableVectorizedReader,开启向量化读,默认值为True。spark.sql.odps.enableVectorizedWriter,开启向量化写,默认值为True。spark.sql.odps.split.size,该配置可以用来调节读MaxCompute表的并发度,默认每个分区为256 MB。
Spark 3.1.1使用注意事项
使用Spark 3.1.1提交作业
直接使用Yarn-cluster模式在本地提交任务。详情请参见Cluster模式。
针对Scala、Java类型的作业,可以在spark-defaults.conf配置文件中添加以下参数运行Spark 3.x。
spark.hadoop.odps.cupid.resources = public.__spark_libs__3.1.1-odps0.33.0.zip,[projectname].[用户主jar包],[projectname].[用户其他jar包] spark.driver.extraClassPath = ./public.__spark_libs__3.1.1-odps0.33.0.zip/* spark.executor.extraClassPath = ./public.__spark_libs__3.1.1-odps0.33.0.zip/*说明采用如上方式提交任务,需要将所依赖的资源全部添加到spark.hadoop.odps.cupid.resources参数中(包括主JAR包),否则可能出现类找不到的问题。
暂时还无法通过以上方式提交Pyspark作业。
Spark 3.1.1使用变化
如果使用Yarn-cluster模式在本地提交任务,需要新增环境变量
export HADOOP_CONF_DIR=$SPARK_HOME/conf。如果使用Yarn-cluster模式提交PySpark作业,需要在spark-defaults.conf配置文件添加以下参数使用Python3。
spark.hadoop.odps.cupid.resources = public.python-3.7.9-ucs4.tar.gz spark.pyspark.python = ./public.python-3.7.9-ucs4.tar.gz/python-3.7.9-ucs4/bin/python3如果使用Local模式进行调试:
需要在
$SPARK_HOME/conf目录下新建odps.conf文件,并添加如下配置。odps.project.name = odps.access.id = odps.access.key = odps.end.point =需要在代码中添加
spark.hadoop.fs.defaultFS = file:///,示例如下。val spark = SparkSession .builder() .config("spark.hadoop.fs.defaultFS", "file:///") .enableHiveSupport() .getOrCreate()
Spark 3.1.1参数配置变化
spark.sql.defaultCatalog配置为odps。spark.sql.catalog.odps配置为org.apache.spark.sql.execution.datasources.v2.odps.OdpsTableCatalog。spark.sql.sources.partitionOverwriteMode配置为dynamic。spark.sql.extensions配置为org.apache.spark.sql.execution.datasources.v2.odps.extension.OdpsExtensions。spark.sql.odps.enableVectorizedReader,开启向量化读,默认值为True。spark.sql.odps.enableVectorizedWriter,开启向量化写,默认值为True。spark.sql.catalog.odps.splitSizeInMB,该配置可以用来调节读MaxCompute表的并发度,默认每个分区为256 MB。