当您需要将上游节点任务的查询或输出结果提供给下游节点使用时,可通过赋值节点实现。赋值节点(即上游节点)支持 ODPS SQL、Python 2和Shell三种语言,会自动将最后一条查询或输出结果赋值给节点自带的输出参数(outputs),下游节点可以通过引用该参数来获取赋值节点的输出结果。
适用范围
版本限制:仅支持 DataWorks 标准版及以上版本。
权限限制:RAM 账号需被添加至对应工作空间,并具备相应开发权限。
核心概念:参数的传递与引用
赋值节点的核心是参数传递,负责将上游节点产生的数据传递给下游节点。
上游赋值节点:负责产生数据。它会将最后一条输出或查询结果自动赋值给一个名为
outputs的节点输出参数。下游业务节点:负责接收和使用数据。通过在下游节点的调度配置 > 节点上下文中添加一个本节点输入参数(例如,
sql_inputs),并让它引用上游节点的outputs参数,就可以在代码中使用这些数据。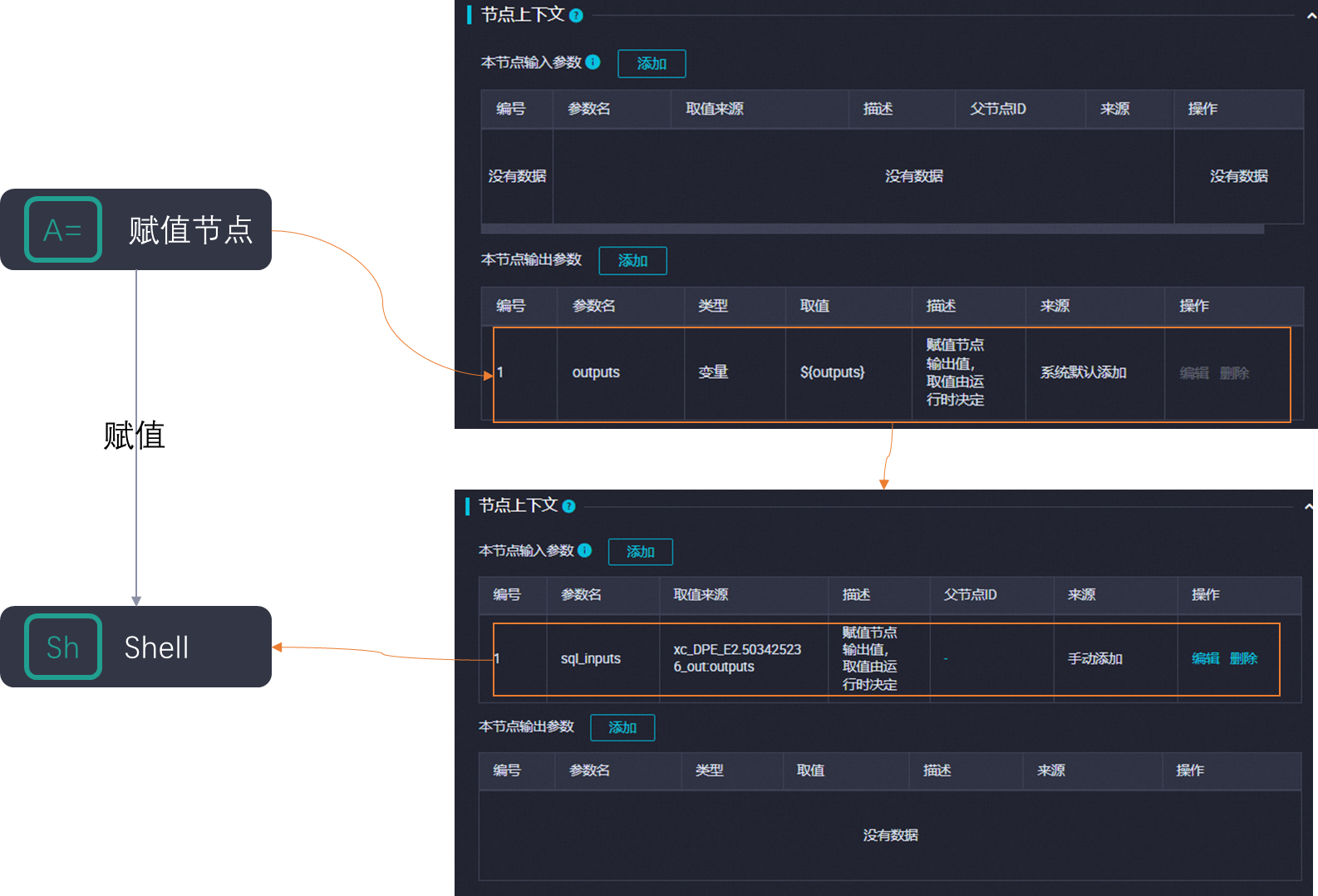
传递参数格式说明
赋值语言 | 传递参数范围 | 传递参数格式 |
ODPS SQL | 获取最后一行 | 将输出结果作为一个二维数组传递至下游。 |
Python 2 | 获取最后一行 | 将输出结果转化成字符串基于逗号( |
Shell | 获取最后一行 |
操作步骤
下面以将 ODPS SQL 赋值节点的结果传递给 Shell 节点为例,介绍通用的操作流程。
创建并配置上游赋值节点。
登录 DataWorks 控制台,在左侧导航栏单击数据开发与运维 > 数据开发,进入数据开发页面。
在业务流程中,创建并编辑一个赋值节点。在代码编辑页面,选择赋值语言为 ODPS_SQL,并编写代码以产生需要传递给下游的结果。
select * from xc_dpe_e2.xc_rpt_user_info_d where dt='20191008' limit 10;(可选)单击页面右侧的调度配置,在节点上下文中可以查看到,系统已自动为该节点创建了名为
outputs的本节点输出参数。
配置下游 Shell 节点。
说明仅以Shell节点为例,支持任意节点作为下游节点。
创建 Shell 节点,并将其设置为赋值节点的下游(即在工作流中从赋值节点拉线连接到 Shell 节点)。
在 Shell 节点的编辑页面,单击右侧的调度配置,选择节点上下文页签。
在本节点输入参数区域,单击添加参数。
在弹出的对话框中,选择上游赋值节点的输出参数
outputs,并为当前节点的输入参数自定义一个参数名称(例如:sql_inputs)。配置完成后,下游节点会自动与上游赋值节点建立依赖关系。
完成参数配置后,即可在下游 Shell 节点的代码中通过
${sql_inputs}的格式来使用上游传递过来的值。echo '${sql_inputs}'; echo '取上游sql节点输出第1行数据'${sql_inputs[0]}; echo '取上游sql节点输出第1行第2个字段'${sql_inputs[0][1]};工作原理说明:请注意,您在代码中使用的
${...}变量访问语法(包括数组索引)是由 DataWorks 在任务执行前进行预处理和静态替换的。例如,${sql_inputs[0][1]}会被 DataWorks 引擎直接替换为从上游节点获取到的具体值,然后才将最终的脚本提交给 Shell 执行。这并非标准 Shell 的数组操作方式。
运行验证。
双击业务流程名称,在业务流程编辑页面单击工具栏的运行图标,运行业务流程,查看引用结果是否正确。您也可以将节点提交至开发环境后,进入开发环境运维中心执行补数据操作,测试运行结果。
DataWorks提供ETL工作流模板(赋值节点应用)供您快速体验赋值节点能力,详情请参见ETL工作流快速体验。
注意事项
传递层级:赋值节点参数只能传递给直接下游的一层子节点,不支持跨层级的节点传递。
传递大小限制:传递值最大为 2MB。如果赋值语句的输出结果超过该限制,赋值节点会运行失败。
语法限制:
赋值节点代码中不支持添加注释,否则可能导致运行结果异常。
ODPS SQL 模式下暂不支持 with 语法。
使用示例:分语言详解
不同语言的赋值节点,其输出结果(outputs)的数据格式和下游节点的引用方式略有不同。下面以Shell节点为下游节点,分别举例说明。
示例一:传递 ODPS SQL 查询结果
SQL 的查询结果会作为一个二维数组传递给下游。
上游节点(赋值节点-ODPS SQL)配置
假设 SQL 代码如下,查询返回多行多列的数据:
select * from xc_dpe_e2.xc_rpt_user_info_d where dt='20191008' limit 2;下游节点(Shell 节点)配置
在 Shell 节点中添加名为
sql_inputs的输入参数,并引用上游 SQL 节点的outputs。然后可以使用如下代码读取数据:# 直接输出整个二维数组 echo "整个结果集: ${sql_inputs}"; # 输出第一行数据(一个一维数组) echo "第一行: ${sql_inputs[0]}"; # 输出第一行第二个字段的值 echo "第一行第二个字段: ${sql_inputs[0][1]}";预期输出结果
DataWorks 将直接解析参数,并做静态替换,运行输出(具体值取决于您的表数据):
整个结果集: value1_1,value1_2 value2_1,value2_2 第一行: value1_1,value1_2 第一行第二个字段: value1_2
示例二:传递 Python 2 输出结果
Python 2的 print 语句输出结果会基于逗号(,)分割,并作为一个一维数组传递给下游。
上游节点(赋值节点-Python 2)配置
Python 2代码如下:
print "a,b,c";下游节点(Shell 节点)配置
在 Shell 节点中添加名为
python_inputs的输入参数,并引用上游赋值节点的outputs。然后可以使用如下代码读取数据:# 直接输出整个一维数组 echo "整个结果集: ${python_inputs}"; # 按索引输出数组中的元素 echo "第一个元素: ${python_inputs[0]}"; echo "第二个元素: ${python_inputs[1]}";预期输出结果
DataWorks 将直接解析参数,并做静态替换,运行输出如下:
整个结果集: "a","b","c" 第一个元素: a 第二个元素: b
示例三:传递 Shell 输出结果
Shell 的 echo 语句输出结果会基于逗号(,)分割,并作为一个一维数组传递给下游。
上游节点(赋值节点-Shell)配置
Shell 代码如下:
echo "hello,world";下游节点(Shell 节点)配置
在 Shell 节点中添加名为
Shell_inputs的输入参数,并引用上游 Shell 节点的outputs。然后可以使用如下代码读取数据:# 直接输出整个一维数组 echo "整个结果集: ${Shell_inputs}"; # 按索引输出数组中的元素 echo "第一个元素: ${Shell_inputs[0]}"; echo "第二个元素: ${Shell_inputs[1]}";预期输出结果
DataWorks 将直接解析参数,并做静态替换,运行输出如下:
整个结果集: "hello","world" 第一个元素: hello 第二个元素: world
高级应用
与循环节点配合使用
当下游是遍历节点(for-each)或循环节点(do-while)时,赋值节点可以为其提供循环的初始值或遍历列表。详情请参见for-each节点、do-while节点。
在其他节点类型中使用赋值参数
部分节点(如 EMR Hive、EMR Spark SQL、ODPS Script、Hologres SQL、AnalyticDB for PostgreSQL、Click House SQL 和 MySQL 节点等)自身支持在节点上下文中开启赋值参数功能,实现与赋值节点相同的效果。