
本文主要介绍JindoFS的配置使用方式,以及一些典型的应用场景。
概述
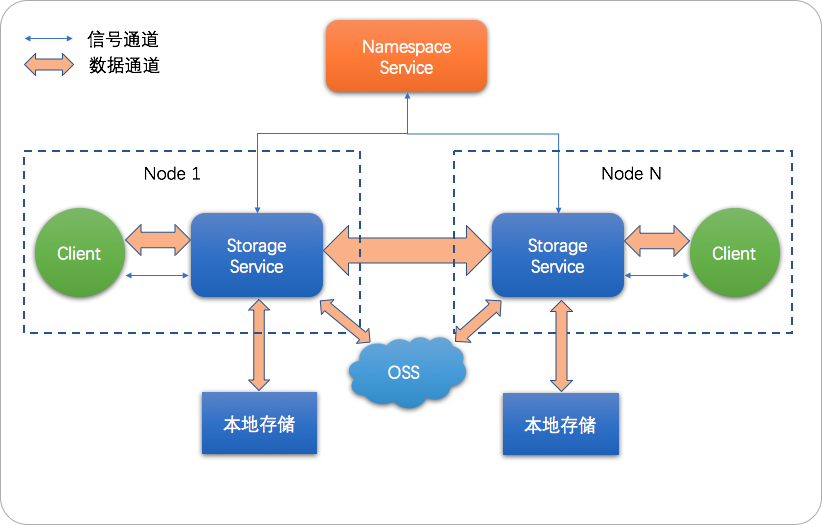
JindoFS是一种云原生的文件系统,结合OSS和本地存储,成为E-MapReduce产品的新一代存储系统,为上层计算提供了高效可靠的存储。
JindoFS提供了块存储模式(Block)和缓存模式(Cache)的存储模式。
JindoFS 采用了本地存储和OSS的异构多备份机制,Storage Service提供了数据存储能力,首先使用OSS作为存储后端,保证数据的高可靠性,同时利用本地存储实现冗余备份,利用本地的备份,可以加速数据读取;另外,JindoFS 的元数据通过本地服务Namespace Service管理,从而保证了元数据操作的性能(和HDFS元数据操作性能相似)。
- E-MapReduce-3.20.0及以上版本支持Jindo FS,您可以在创建集群时勾选相关服务来使用JindoFS。
- 本文主要是E-MapReduce-3.20.0及以上版本至E-MapReduce-3.22.0(但不包括)版本的介绍;E-MapReduce-3.22.0 及以上版本的JindoFS 使用说明,请参见SmartData使用说明(EMR-3.22.0~3.25.1版本)。
应用场景
E-MapReduce目前提供了三种大数据存储系统,E-MapReduce OssFileSystem、E-MapReduce HDFS和E-MapReduce JindoFS,其中OssFileSystem和JindoFS都是云上存储的解决方案,下表为这三种存储系统和开源OSS各自的特点。
| 特点 | 开源OSS | E-MapReduce OssFileSystem | E-MapReduce HDFS | E-MapReduce JindoFS |
|---|---|---|---|---|
| 存储空间 | 海量 | 海量 | 取决于集群规模 | 海量 |
| 可靠性 | 高 | 高 | 高 | 高 |
| 吞吐率因素 | 服务端 | 集群内磁盘缓存 | 集群内磁盘 | 集群内磁盘 |
| 元数据效率 | 慢 | 中 | 快 | 快 |
| 扩容操作 | 容易 | 容易 | 容易 | 容易 |
| 缩容操作 | 容易 | 容易 | 需Decommission | 容易 |
| 数据本地化 | 无 | 弱 | 强 | 较强 |
JindoFS块存储模式具有以下几个特点:
- 海量弹性的存储空间,基于OSS作为存储后端,存储不受限于本地集群,而且本地集群能够自由弹性伸缩。
- 能够利用本地集群的存储资源加速数据读取,适合具有一定本地存储能力的集群,能够利用有限的本地存储提升吞吐率,特别对于一写多读的场景效果显著。
- 元数据操作效率高,能够与HDFS相当,能够有效规避OSS文件系统元数据操作耗时以及高频访问下可能引发不稳定的问题。
- 能够最大限度保证执行作业时的数据本地化,减少网络传输的压力,进一步提升读取性能。
环境准备
- 创建集群
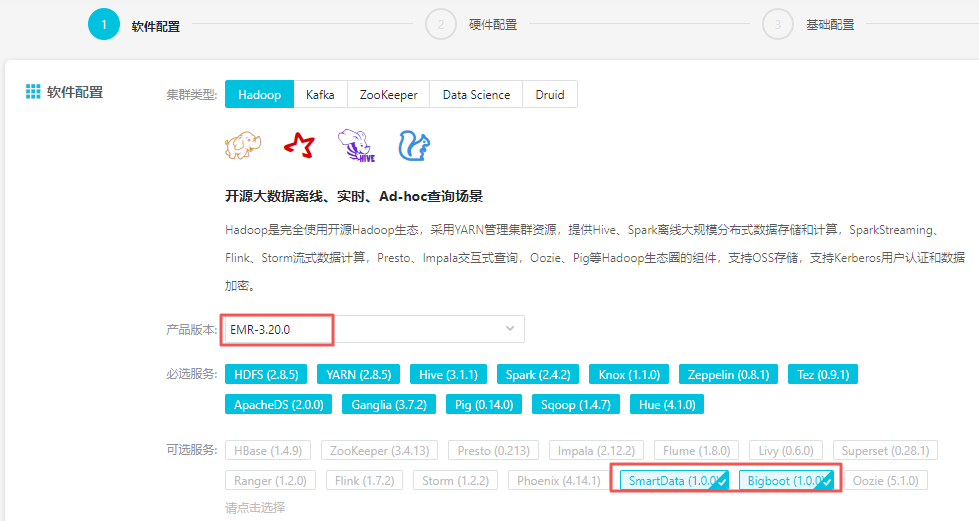
选择E-MapReduce-3.20.0及以上版本至E-MapReduce-3.22.0(但不包括)版本,勾选可选服务中的SmartData和Bigboot,创建集群详情请参见创建集群。Bigboot 服务提供了E-MapReduce平台上的基础的分布式数据管理交互服务以及一些组件管理监控和支持性服务,SmartData服务基于Bigboot之上对应用层提供了JindoFS文件系统。
- 配置集群
SmartData提供的JindoFS文件系统使用OSS作为存储后端,因此在使用JindoFS之前需配置一些OSS相关参数。下面提供两种配置方式,第一种是先创建好集群,修改Bigboot相关参数,需重启SmartData服务生效;第二种是创建集群过程中添加自定义配置,这样集群创建好后相关服务就能按照自定义参数启动。
- 集群创建好后参数初始化
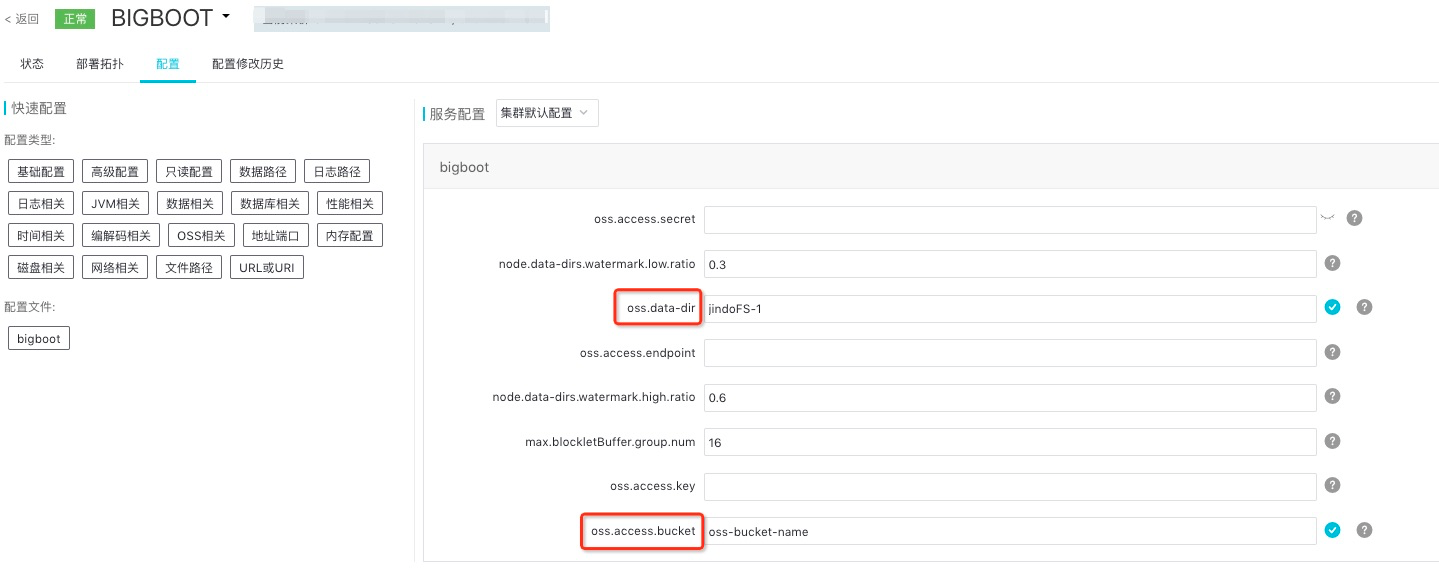
oss.access.bucket为OSS bucket的名称。oss.data-dir为JindoFS在OSS bucket中所使用的目录(注:该目录为 JindoFS后端存储目录,生成的数据不能人为破坏,并且保证该目录仅用于JindoFS后端存储,JindoFS在写入数据时会自动创建用户所配置的目录,无需在OSS上事先创建)。oss.access.endpoint为bucket所在的区域。oss.access.key为存储后端OSS的AccessKey ID。oss.access.secret为存储后端OSS的AccessKey Secret。
考虑到性能和稳定性,推荐使用同region下的OSS bucket作为存储后端,此时,E-MapReduce集群能够免密访问OSS,无需配置AccessKey ID和AccessKey Secret。
所有JindoFS相关配置都在Bigboot组件中,配置如下图所示,红框中为必填的配置项。
 说明 JindoFS支持多命名空间,本文命名空间以test为例。
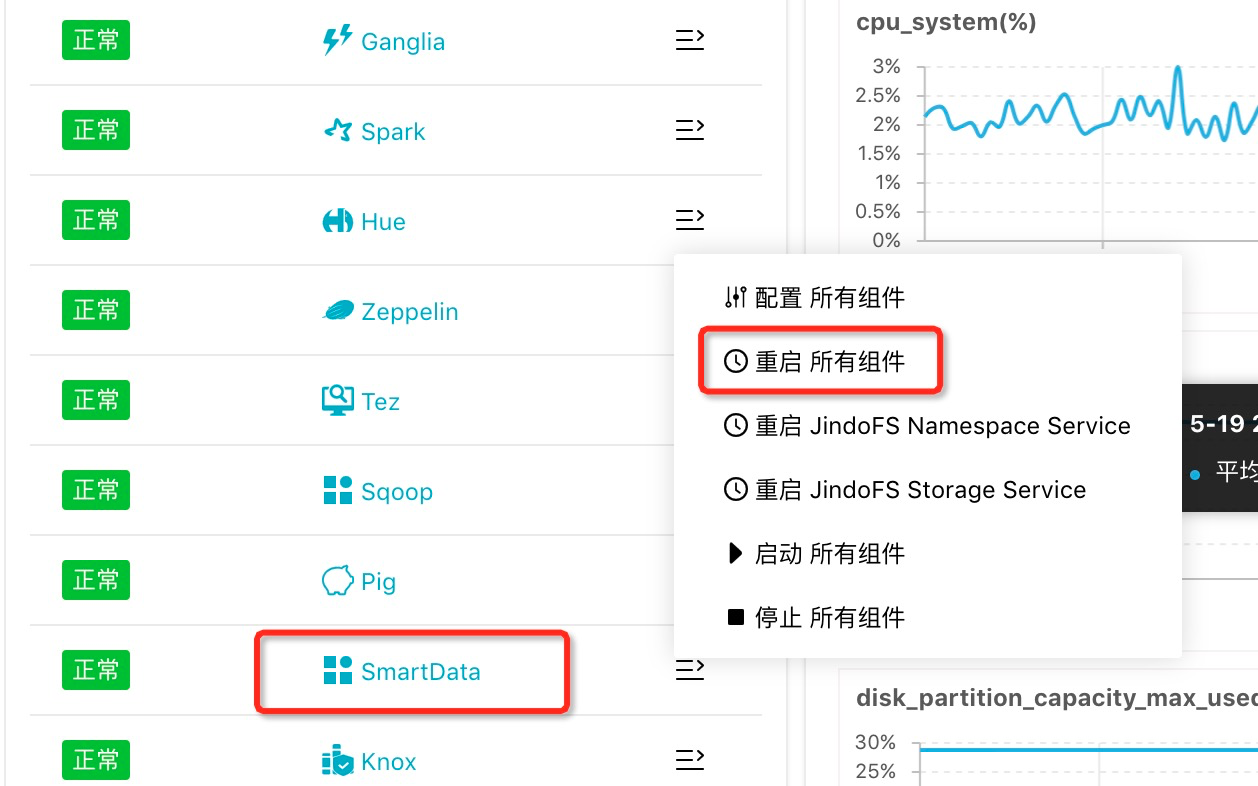
说明 JindoFS支持多命名空间,本文命名空间以test为例。配置完成后保存并部署,然后在SmartData服务中重启所有组件,即开始使用JindoFS。
- 创建集群时添加自定义配置
E-MapReduce集群在创建集群时支持添加自定义配置,以同region下免密访问OSS为例,如下图勾选软件自定义配置,添加如下配置,配置
oss.data-dir和oss.access.bucket。[ { "ServiceName":"BIGBOOT", "FileName":"bigboot", "ConfigKey":"oss.data-dir", "ConfigValue":"jindoFS-1" }, { "ServiceName":"BIGBOOT", "FileName":"bigboot", "ConfigKey":"oss.access.bucket", "ConfigValue":"oss-bucket-name" } ]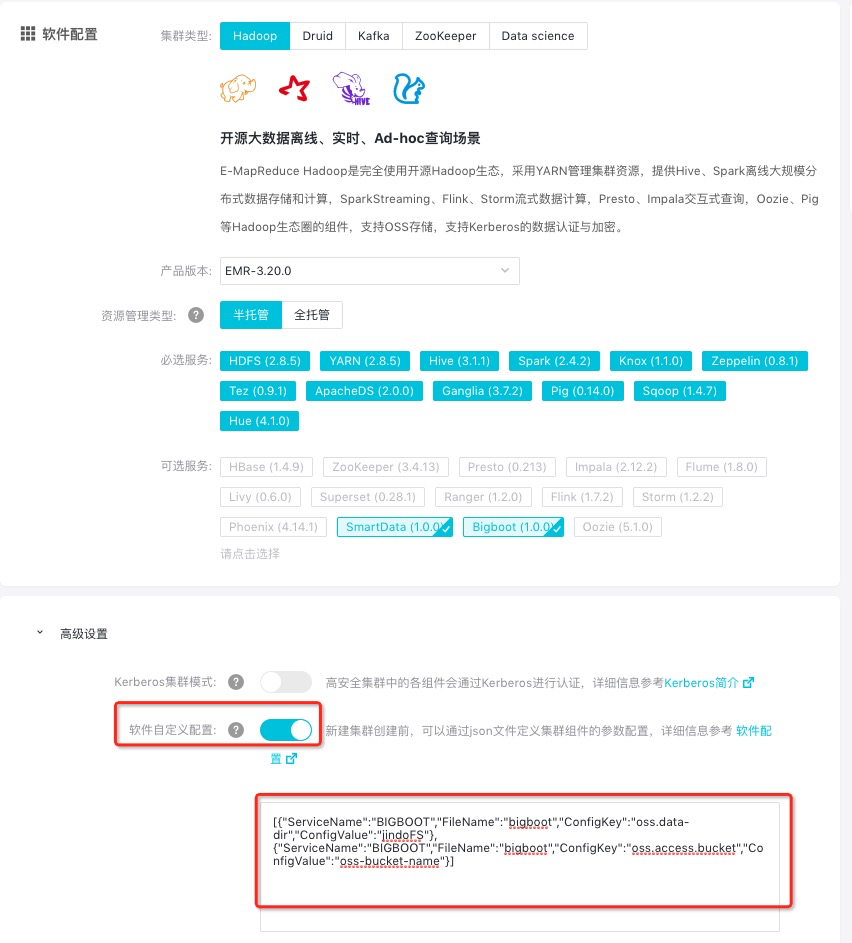
- 集群创建好后参数初始化
使用JindoFS
hadoop fs -ls jfs:/// hadoop fs -mkdir jfs:///test-dirhadoop fs -put test.log jfs:///test-dir/磁盘空间水位控制
JindoFS后端基于OSS,可以提供海量的存储,但是本地盘的容量是有限的,因此JindoFS会自动淘汰本地较冷的数据备份。我们提供了node.data-dirs.watermark.high.ratio和node.data-dirs.watermark.low.ratio这两个参数用来调节本地存储的使用容量,值均为0~1的小数表示使用比例,JindoFS默认使用所有数据盘,每块盘的使用容量默认即为数据盘大小。前者表示使用量上水位比例,每块数据盘的JindoFS占用的空间到达上水位即会开始清理淘汰;后者表示使用量下水位比例,触发清理后会将JindoFS的占用空间清理到下水位。用户可以通过设置上水位比例调节期望分给JindoFS的磁盘空间,下水位必须小于上水位,设置合理的值即可。
存储策略
JindoFS提供了Storage Policy功能,提供更加灵活的存储策略适应不同的存储需求,可以对目录设置以下四种存储策略。
| 策略 | 策略说明 |
|---|---|
| COLD | 表示数据仅在OSS上有一个备份,没有本地备份,适用于冷数据存储。 |
| WARM |
默认策略。 表示数据在OSS和本地分别有一个备份, 本地备份能够有效的提供后续的读取加速。 |
| HOT | 表示数据在OSS上有一个备份,本地有多个备份,针对一些最热的数据提供更进一步的加速效果。 |
| TEMP | 表示数据仅有一个本地备份,针对一些临时性数据,提供高性能的读写,但降低了数据的高可靠性,适用于一些临时数据的存取。 |
JindoFS提供了Admin工具设置目录的Storage Policy(默认为 WARM),新增的文件将会以父目录所指定的Storage Policy进行存储,使用方式如下所示。
jindo dfsadmin -R -setStoragePolicy [path] [policy]通过以下命令,获取某个目录的存储策略。
jindo dfsadmin -getStoragePolicy [path]Admin工具还提供archive命令,实现对冷数据的归档。
此命令提供了一种用户显式淘汰本地数据块的方式。Hive分区表按天分区,假如业务上对一周前的分区数据认为不会再经常访问,那么就可以定期将一周前的分区目录执行archive,淘汰本地备份,文件备份将仅仅保留在后端OSS上。
Archive命令的使用方式如下:
jindo dfsadmin -archive [path]