
在数据准备阶段,您需要同步原始数据至MaxCompute。
前提条件
已完成准备环境。
已新增MaxCompute数据源。详情请参见创建MaxCompute数据源。
准备数据源
通过RDS创建MySQL实例,获取RDS实例ID。详情请参见快速创建RDS MySQL实例。
在RDS控制台添加白名单。
说明通过Serverless资源组调度RDS的数据同步任务时需注意:
通过内网访问,请将资源组绑定的交换机网段IP添加到数据源的白名单列表。
通过公网访问,将Serverless资源组绑定VPC配置的EIP添加至数据源的白名单列表。
详情请参见:网络连通方案。
下载本教程使用的原始数据indicators_data、steal_flag_data和trend_data。
上传原始数据至RDS数据源,详情请参见将Excel的数据导入数据库。
新增数据源
本次实验需要创建MySQL数据源。
进入管理中心页面。
登录DataWorks控制台,切换至目标地域后,单击左侧导航栏的,在下拉框中选择对应工作空间后单击进入管理中心。
创建MySQL数据源。
单击左侧导航栏的,进入数据源列表页面。
单击新增数据源,在新增数据源对话框中选择数据源类型为MySQL。
配置数据源信息。
在创建MySQL数据源对话框,配置各项参数。本文以创建阿里云实例模式类型为例。
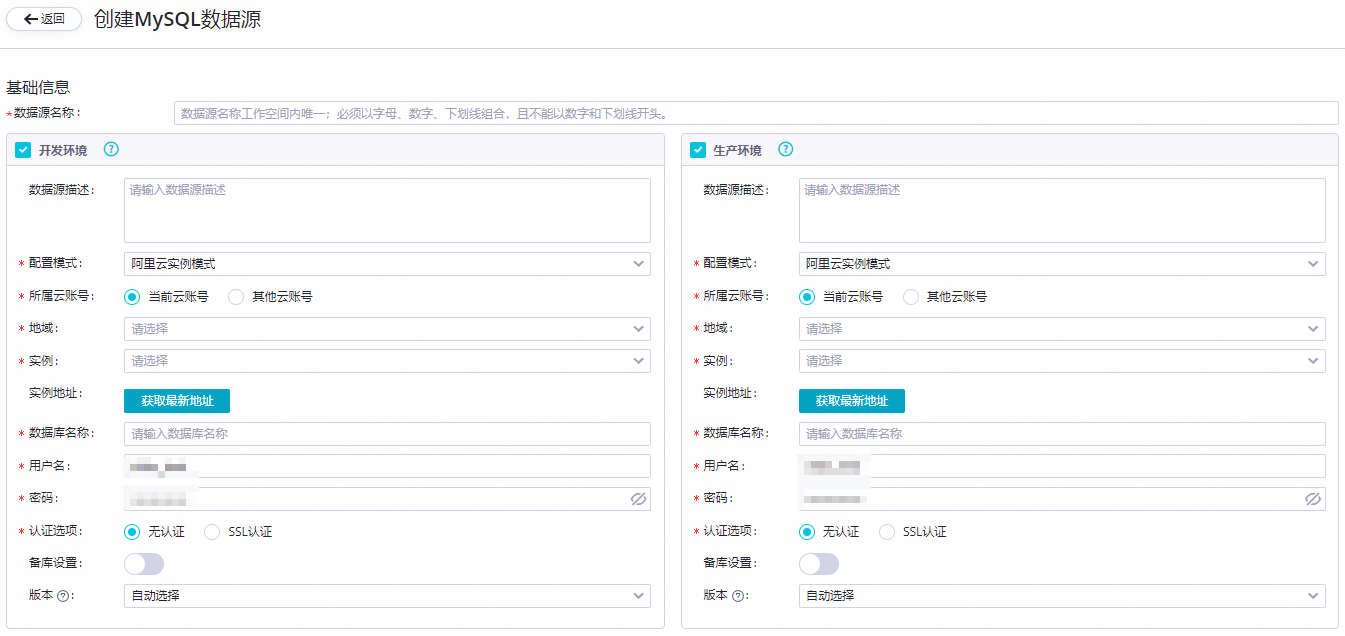
核心参数说明如下。
参数
描述
适用环境
分别配置开发环境及生产环境的数据源。
配置模式
选择阿里云实例模式。
所属云账号
选择当前云账号。
地域
选择相应地域。
实例
选择已创建的RDS MySQL实例。选择实例后,可单击获取最新地址,查看实例相关信息。
若无可用实例,您可进入RDS控制台创建新的实例。
数据库登录信息
此处配置为该数据源对应的默认数据库名称,您需要输入登录数据库的用户名称及密码,密码中避免使用@符号。
后续配置同步任务的说明如下:
配置整库同步(包含实时和离线),您可以选择相应RDS实例下所有具有权限的数据库。
配置离线同步任务,当您选择使用多个数据库时,则每个数据库均需要配置一个数据源。
认证选项
选择无认证。
备库设置
如果数据源具备只读实例(备库),可以在配置任务时开启备库设置,并选择备库ID。设置备库的优势是防止干扰主库,不影响主库性能。如果有多个只读实例,则会任选一个可用的来读取。
说明此功能仅支持独享资源组。
测试资源组连通性。
在数据集成和数据调度页签下,分别单击相应资源组后的测试连通性,连通状态为可连通时,表示连通成功。
说明数据同步时,一个任务只能使用一种资源组。
您需要测试每种资源组的连通性,以保证同步任务使用的资源组能够与数据源连通,否则将无法正常执行数据同步任务。
测试连通性通过后,单击完成创建,数据源创建完成。
新建业务流程
单击当前页面左上角的
 图标,选择。
图标,选择。右键单击业务流程,选择新建业务流程。
在新建业务流程对话框中,输入业务名称和描述。
说明业务名称的长度不能超过128个字符,且必须是大小写字母、中文、数字、下划线(_)以及小数点(.)。
单击新建。
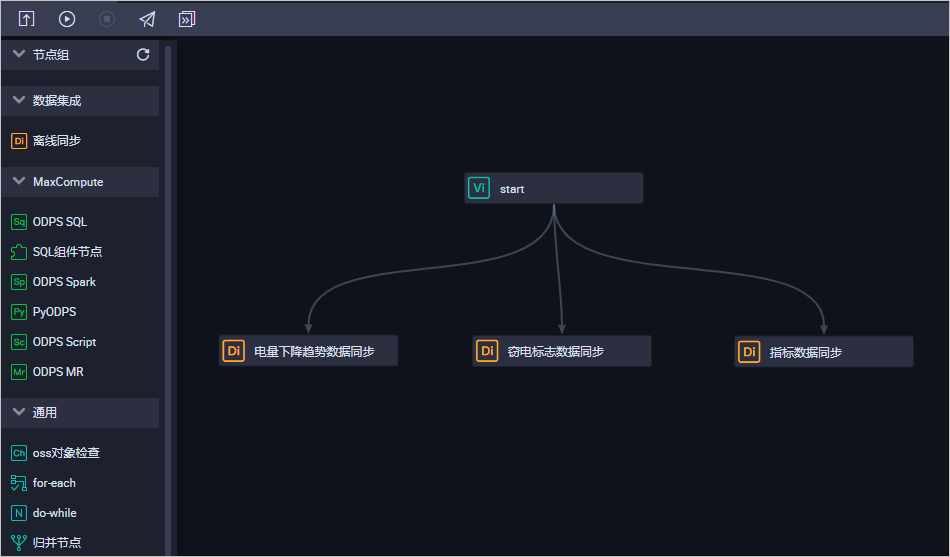
进入业务流程开发面板,并向面板中拖入一个虚拟节点(start)和三个离线同步节点(电量下降趋势数据同步、窃电标志数据同步和指标数据同步)分别填写相应的配置后,单击提交。
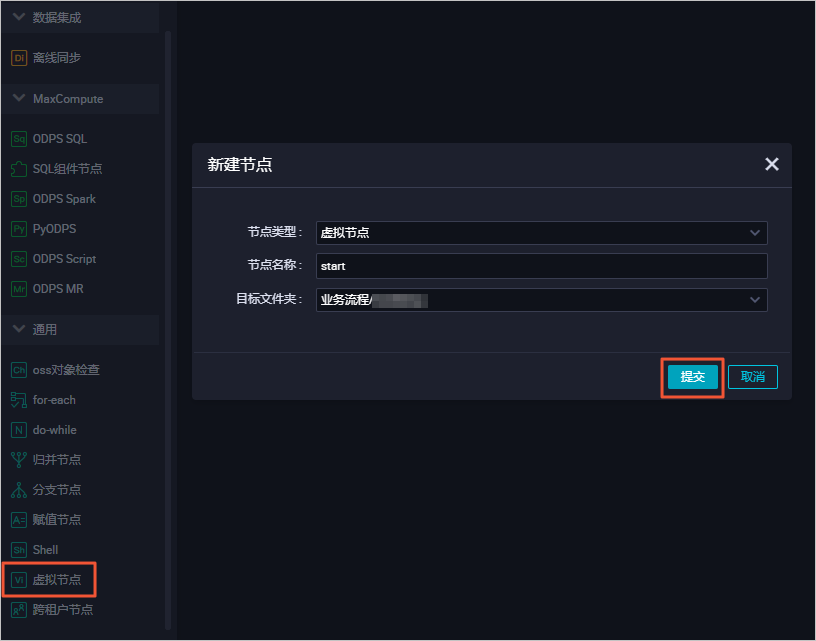
拖拽连线将start节点设置为三个离线同步节点的上游节点。
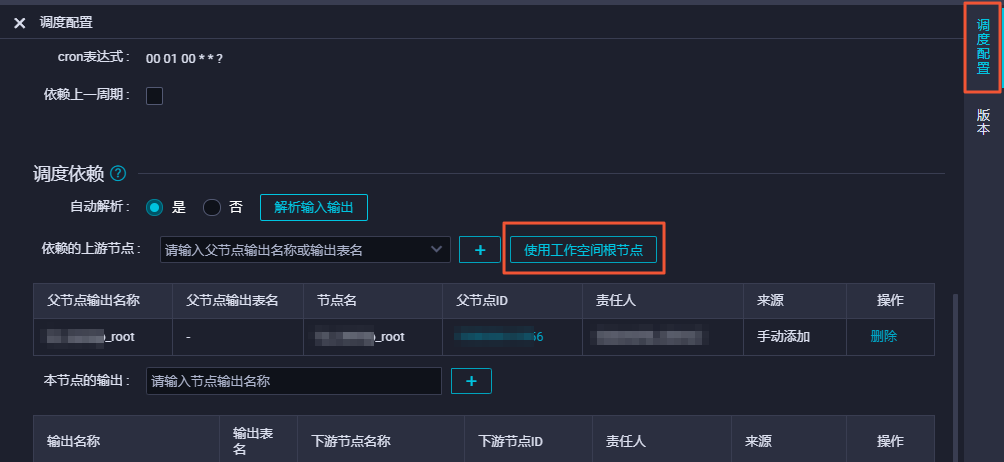
配置start节点
双击虚拟节点,单击右侧的调度配置。
设置start节点的上游节点为工作空间根节点。
由于新版本给每个节点都设置了输入输出节点,所以需要给start节点设置一个输入。此处设置其上游节点为工作空间根节点,通常命名为工作空间名_root。
配置完成后,单击左上角的
 图标。
图标。
新建表
右键单击新建的业务流程,选择。
在新建表对话框中,选择引擎实例、路径,输入表名称,单击新建。
此处需要创建3张表,分别存储同步过来的电量下降趋势数据、指标数据和窃电标志数据(trend_data、indicators_data和steal_flag_data)。
说明表名不能超过64个字符,且必须以字母开头,不能包含中文或特殊字符。
打开创建的表,单击DDL模式,分别输入以下相应的建表语句。
--电量下降趋势表 CREATE TABLE trend_data ( uid BIGINT, trend BIGINT ) PARTITIONED BY (dt string);--指标数据 CREATE TABLE indicators_data ( uid BIGINT, xiansun BIGINT, warnindicator BIGINT ) COMMENT '*' PARTITIONED BY (ds string) LIFECYCLE 36000;--窃电标志数据 CREATE TABLE steal_flag_data ( uid BIGINT, flag BIGINT ) COMMENT '*' PARTITIONED BY (ds string) LIFECYCLE 36000;建表语句输入完成后,单击生成表结构并确认覆盖当前操作。
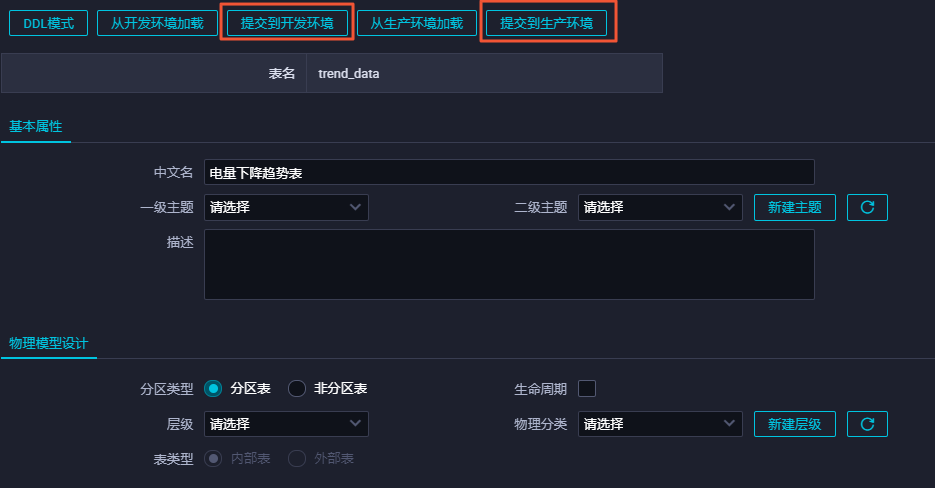
返回建表页面后,在基本属性中输入表的中文名。
完成设置后,分别单击提交到开发环境和提交到生产环境。
配置离线同步节点
配置电量下降趋势数据同步节点。
双击电量下降趋势数据同步节点,进入节点配置页面。
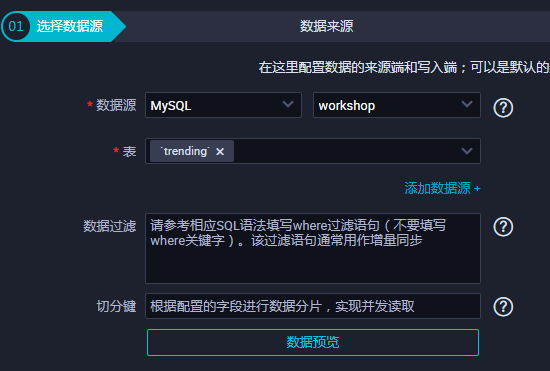
选择数据来源。
参数
描述
数据源
选择。
表
选择MySQL数据源中的表trending。
数据过滤
您将要同步数据的筛选条件,暂时不支持limit关键字过滤。SQL语法与选择的数据源一致,此处可以不填。
切分键
读取数据时,根据配置的字段进行数据分片,实现并发读取,可以提升数据同步效率。此处可以不填。
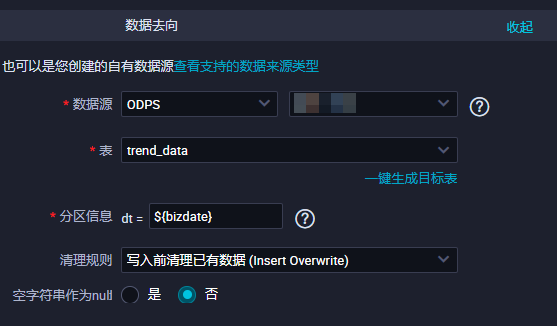
选择数据去向。
参数
描述
数据源
选择ODPS,然后选择MaxCompute数据源名称。
表
选择ODPS数据源中的表trend_data。
分区信息
输入要同步的分区列,此处默认为
dt=${bdp.system.bizdate}。清理规则
选择写入前清理已有数据。
空字符串作为null
选择否。
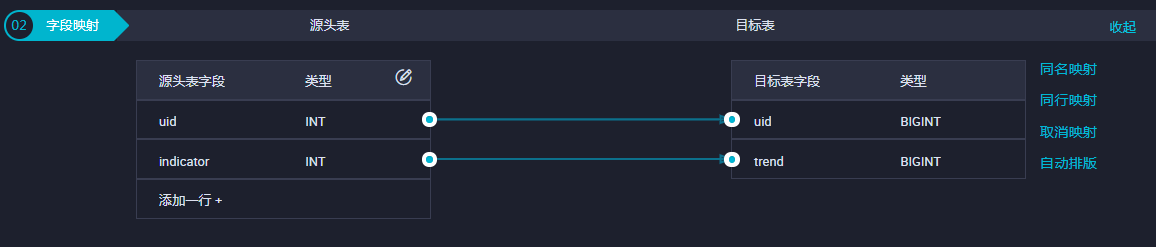
配置字段映射。
配置通道控制。
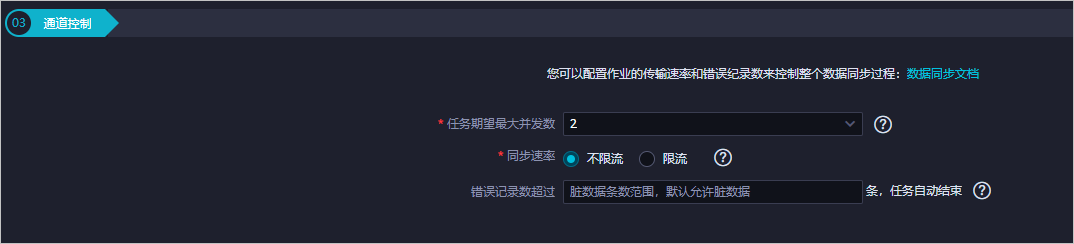
参数
描述
任务期望最大并发数
数据同步任务内,可以从源并行读取或并行写入数据存储端的最大线程数。向导模式通过界面化配置并发数,指定任务所使用的并行度。
同步速率
设置同步速率可以保护读取端数据库,以避免抽取速度过大,给源库造成太大的压力。同步速率建议限流,结合源库的配置,请合理配置抽取速率。
错误记录数
错误记录数,表示脏数据的最大容忍条数。
确认当前节点的配置无误后,单击左上角的
图标。
提交业务流程
打开业务流程配置面板,单击左上角的
 进行提交。
进行提交。选择提交对话框中需要提交的节点,输入备注,勾选忽略输入输出不一致的告警。
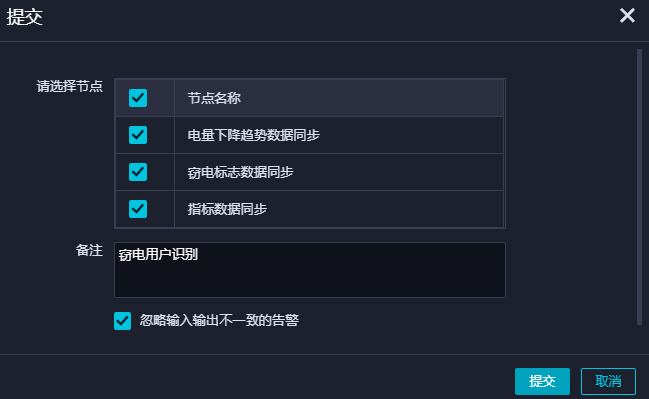
单击提交,待显示提交成功即可。
确认数据是否成功导入MaxCompute
在数据开发页面的左侧导航栏,单击临时查询,进入临时查询面板。
右键单击临时查询,选择。
编写并执行SQL语句,查看导入表trend_data、indicators_data和steal_flag_data的记录数。
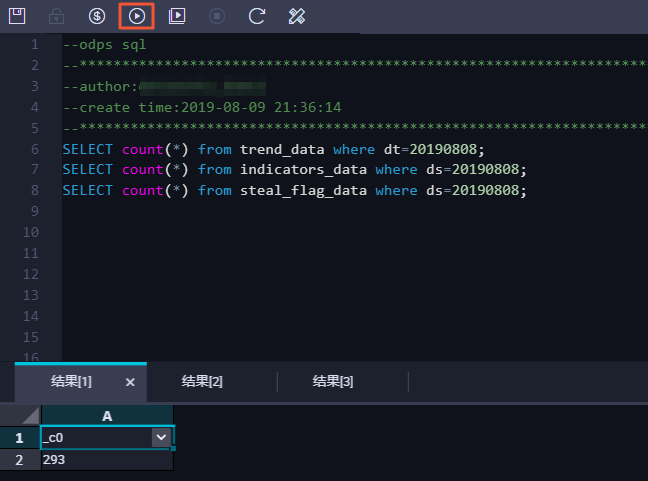
SQL语句如下所示,其中分区列需要更新为业务日期。例如,任务运行的日期为20190809,则业务日期为201900808。
--查看是否成功写入MaxCompute SELECT COUNT(*) FROM trend_data WHERE dt=业务日期; SELECT COUNT(*) FROM indicators_data WHERE ds=业务日期; SELECT COUNT(*) FROM steal_flag_data WHERE ds=业务日期;
后续步骤
现在,您已经学习了如何通过数据同步采集数据,您可以继续下一个教程。在该教程中,您将学习如何对采集的数据进行计算与分析。详情请参见加工数据。