本文为您介绍Spark-2.x依赖的配置以及Spark-2.x示例说明。
配置Spark-2.x的依赖
通过MaxCompute提供的Spark客户端提交应用时,需要在pom.xml文件中添加以下依赖。pom.xml文件请参见pom.xml。
<properties>
<spark.version>2.3.0</spark.version>
<cupid.sdk.version>3.3.8-public</cupid.sdk.version>
<scala.version>2.11.8</scala.version>
<scala.binary.version>2.11</scala.binary.version>
</properties>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.aliyun.odps</groupId>
<artifactId>cupid-sdk</artifactId>
<version>${cupid.sdk.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.aliyun.odps</groupId>
<artifactId>hadoop-fs-oss</artifactId>
<version>${cupid.sdk.version}</version>
</dependency>
<dependency>
<groupId>com.aliyun.odps</groupId>
<artifactId>odps-spark-datasource_${scala.binary.version}</artifactId>
<version>${cupid.sdk.version}</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-actors</artifactId>
<version>${scala.version}</version>
</dependency>上述代码中Scope的定义如下:
spark-core、spark-sql等所有Spark社区发布的包,设置Scope为provided。
odps-spark-datasource设置Scope为compile。
WordCount示例(Scala)
代码示例
提交方式
cd /path/to/MaxCompute-Spark/spark-2.x mvn clean package # 环境变量spark-defaults.conf的配置请参见搭建开发环境。 cd $SPARK_HOME bin/spark-submit --master yarn-cluster --class \ com.aliyun.odps.spark.examples.WordCount \ /path/to/MaxCompute-Spark/spark-2.x/target/spark-examples_2.11-1.0.0-SNAPSHOT-shaded.jar
MaxCompute Table读写示例(Scala)
代码示例
提交方式
cd /path/to/MaxCompute-Spark/spark-2.x mvn clean package # 环境变量spark-defaults.conf的配置请参见搭建开发环境。 cd $SPARK_HOME bin/spark-submit --master yarn-cluster --class com.aliyun.odps.spark.examples.sparksql.SparkSQL \ /path/to/MaxCompute-Spark/spark-2.x/target/spark-examples_2.11-1.0.0-SNAPSHOT-shaded.jar
GraphX PageRank示例(Scala)
代码示例
提交方式
cd /path/to/MaxCompute-Spark/spark-2.x mvn clean package # 环境变量spark-defaults.conf的配置请参见搭建开发环境。 cd $SPARK_HOME bin/spark-submit --master yarn-cluster --class com.aliyun.odps.spark.examples.graphx.PageRank \ /path/to/MaxCompute-Spark/spark-2.x/target/spark-examples_2.11-1.0.0-SNAPSHOT-shaded.jar
Mllib Kmeans-ON-OSS示例(Scala)
spark.hadoop.fs.oss.ststoken.roleArn和spark.hadoop.fs.oss.endpoint的填写请参见Oss-Access文档说明。
代码示例
提交方式
# 编辑代码。 val modelOssDir = "oss://bucket/kmeans-model" // 填写具体的OSS Bucket路径。 val spark = SparkSession .builder() .config("spark.hadoop.fs.oss.credentials.provider", "org.apache.hadoop.fs.aliyun.oss.AliyunStsTokenCredentialsProvider") .config("spark.hadoop.fs.oss.ststoken.roleArn", "acs:ram::****:role/aliyunodpsdefaultrole") .config("spark.hadoop.fs.oss.endpoint", "oss-cn-hangzhou-zmf.aliyuncs.com") .appName("KmeansModelSaveToOss") .getOrCreate() cd /path/to/MaxCompute-Spark/spark-2.x mvn clean package # 环境变量spark-defaults.conf的配置请参见搭建开发环境。 cd $SPARK_HOME bin/spark-submit --master yarn-cluster --class com.aliyun.odps.spark.examples.mllib.KmeansModelSaveToOss \ /path/to/MaxCompute-Spark/spark-2.x/target/spark-examples_2.11-1.0.0-SNAPSHOT-shaded.jar
OSS UnstructuredData示例(Scala)
spark.hadoop.fs.oss.ststoken.roleArn和spark.hadoop.fs.oss.endpoint的填写请参见Oss-Access文档说明。
代码示例
提交方式
# 编辑代码。 val pathIn = "oss://bucket/inputdata/" // 填写具体的OSS Bucket路径。 val spark = SparkSession .builder() .config("spark.hadoop.fs.oss.credentials.provider", "org.apache.hadoop.fs.aliyun.oss.AliyunStsTokenCredentialsProvider") .config("spark.hadoop.fs.oss.ststoken.roleArn", "acs:ram::****:role/aliyunodpsdefaultrole") .config("spark.hadoop.fs.oss.endpoint", "oss-cn-hangzhou-zmf.aliyuncs.com") .appName("SparkUnstructuredDataCompute") .getOrCreate() cd /path/to/MaxCompute-Spark/spark-2.x mvn clean package # 环境变量spark-defaults.conf的配置请参见搭建开发环境。 cd $SPARK_HOME bin/spark-submit --master yarn-cluster --class com.aliyun.odps.spark.examples.oss.SparkUnstructuredDataCompute \ /path/to/MaxCompute-Spark/spark-2.x/target/spark-examples_2.11-1.0.0-SNAPSHOT-shaded.jar
SparkPi示例(Scala)
代码示例
提交方式
cd /path/to/MaxCompute-Spark/spark-2.x mvn clean package # 环境变量spark-defaults.conf的配置请参见搭建开发环境。 cd $SPARK_HOME bin/spark-submit --master yarn-cluster --class com.aliyun.odps.spark.examples.SparkPi \ /path/to/MaxCompute-Spark/spark-2.x/target/spark-examples_2.11-1.0.0-SNAPSHOT-shaded.jar
支持Spark Streaming LogHub示例(Scala)
代码示例
提交方式
# 环境变量spark-defaults.conf的配置请参见搭建开发环境。 cd $SPARK_HOME bin/spark-submit --master yarn-cluster --class com.aliyun.odps.spark.examples.streaming.loghub.LogHubStreamingDemo \ /path/to/MaxCompute-Spark/spark-2.x/target/spark-examples_2.11-1.0.0-SNAPSHOT-shaded.jar
支持Spark Streaming LogHub写MaxCompute示例(Scala)
代码示例
提交方式
# 环境变量spark-defaults.conf的配置请参见搭建开发环境。 cd $SPARK_HOME bin/spark-submit --master yarn-cluster --class com.aliyun.odps.spark.examples.streaming.loghub.LogHub2OdpsDemo \ /path/to/MaxCompute-Spark/spark-2.x/target/spark-examples_2.11-1.0.0-SNAPSHOT-shaded.jar
支持Spark Streaming DataHub示例(Scala)
代码示例
提交方式
# 环境变量spark-defaults.conf的配置请参见搭建开发环境。 cd $SPARK_HOME bin/spark-submit --master yarn-cluster --class com.aliyun.odps.spark.examples.streaming.datahub.DataHubStreamingDemo \ /path/to/MaxCompute-Spark/spark-2.x/target/spark-examples_2.11-1.0.0-SNAPSHOT-shaded.jar
支持Spark Streaming DataHub写MaxCompute示例(Scala)
代码示例
提交方式
# 环境变量spark-defaults.conf的配置请参见搭建开发环境。 cd $SPARK_HOME bin/spark-submit --master yarn-cluster --class com.aliyun.odps.spark.examples.streaming.datahub.DataHub2OdpsDemo \ /path/to/MaxCompute-Spark/spark-2.x/target/spark-examples_2.11-1.0.0-SNAPSHOT-shaded.jar
支持Spark Streaming Kafka示例(Scala)
代码示例
提交方式
# 环境变量spark-defaults.conf的配置请参见搭建开发环境。 cd $SPARK_HOME bin/spark-submit --master yarn-cluster --class com.aliyun.odps.spark.examples.streaming.kafka.KafkaStreamingDemo \ /path/to/MaxCompute-Spark/spark-2.x/target/spark-examples_2.11-1.0.0-SNAPSHOT-shaded.jar
更多信息请参见MaxCompute-Spark。
支持Spark StructuredStreaming DataHub示例(Scala)
代码示例
提交方式
# 环境变量spark-defaults.conf的配置请参见搭建开发环境。 cd $SPARK_HOME bin/spark-submit --master yarn-cluster --class com.aliyun.odps.spark.examples.structuredstreaming.datahub.DatahubStructuredStreamingDemo \ /path/to/MaxCompute-Spark/spark-2.x/target/spark-examples_2.11-1.0.0-SNAPSHOT-shaded.jar
支持Spark StructuredStreaming Kafka示例(Scala)
代码示例
提交方式
# 环境变量spark-defaults.conf的配置请参见搭建开发环境。 cd $SPARK_HOME bin/spark-submit --master yarn-cluster --class com.aliyun.odps.spark.examples.structuredstreaming.kafka.KafkaStructuredStreamingDemo \ /path/to/MaxCompute-Spark/spark-2.x/target/spark-examples_2.11-1.0.0-SNAPSHOT-shaded.jar
支持Spark StructuredStreaming LogHub示例(Scala)
代码示例
提交方式
# 环境变量spark-defaults.conf的配置请参见搭建开发环境。 cd $SPARK_HOME bin/spark-submit --master yarn-cluster --class com.aliyun.odps.spark.examples.structuredstreaming.loghub.LoghubStructuredStreamingDemo \ /path/to/MaxCompute-Spark/spark-2.x/target/spark-examples_2.11-1.0.0-SNAPSHOT-shaded.jar
MaxCompute Table读写PySpark示例(Python)
代码示例
提交方式
# 环境变量spark-defaults.conf的配置请参见搭建开发环境。 cd $SPARK_HOME bin/spark-submit --master yarn-cluster --jars /path/to/odps-spark-datasource_2.11-3.3.8-public.jar \ /path/to/MaxCompute-Spark/spark-2.x/src/main/python/spark_sql.py
PySpark写OSS示例(Python)
代码示例
提交方式
# 环境变量spark-defaults.conf的配置请参见搭建开发环境。 # OSS相关配置请参见OSS Access文档说明。 cd $SPARK_HOME bin/spark-submit --master yarn-cluster --jars /path/to/spark-examples_2.11-1.0.0-SNAPSHOT-shaded.jar \ /path/to/MaxCompute-Spark/spark-2.x/src/main/python/spark_oss.py # spark-examples_2.11-1.0.0-SNAPSHOT-shaded.jar可以通过Spark-2.x编译得到。
Spark-SQL示例(Java)
Spark-SQL Java示例代码请参见JavaSparkSQL.java。
从MaxCompute中读取数据写入HBase
通过IntelliJ IDEA工具编写代码,实现从MaxCompute中读取数据写入HBase。
代码示例
object McToHbase { def main(args: Array[String]) { val spark = SparkSession .builder() .appName("spark_sql_ddl") .config("spark.sql.catalogImplementation", "odps") .config("spark.hadoop.odps.end.point","http://service.cn.maxcompute.aliyun.com/api") .config("spark.hadoop.odps.runtime.end.point","http://service.cn.maxcompute.aliyun-inc.com/api") .getOrCreate() val sc = spark.sparkContext val config = HBaseConfiguration.create() val zkAddress = "" config.set(HConstants.ZOOKEEPER_QUORUM, zkAddress); val jobConf = new JobConf(config) jobConf.setOutputFormat(classOf[TableOutputFormat]) jobConf.set(TableOutputFormat.OUTPUT_TABLE,"test") try{ import spark._ spark.sql("select '7', 'long'").rdd.map(row => { val id = row(0).asInstanceOf[String] val name = row(1).asInstanceOf[String] val put = new Put(Bytes.toBytes(id)) put.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("a"), Bytes.toBytes(name)) (new ImmutableBytesWritable, put) }).saveAsHadoopDataset(jobConf) } finally { sc.stop() } } }提交方式:通过IntelliJ IDEA提交并运行示例代码。更多操作信息,请参见Spark在MaxCompute的运行方式。
读写OSS文件
通过IntelliJ IDEA工具或DataWorks,实现读写OSS文件。
代码示例
示例1:Local模式下的代码示例。
package com.aliyun.odps.spark.examples import java.io.ByteArrayInputStream import org.apache.spark.sql.SparkSession object SparkOSS { def main(args: Array[String]) { val spark = SparkSession .builder() .config("spark.master", "local[4]") // 需要设置spark.master为local[N]才能直接运行,N为并发数。 .config("spark.hadoop.fs.oss.accessKeyId", "") .config("spark.hadoop.fs.oss.accessKeySecret", "") .config("spark.hadoop.fs.oss.endpoint", "oss-cn-beijing.aliyuncs.com") .appName("SparkOSS") .getOrCreate() val sc = spark.sparkContext try { //OSS文件的读取。 val pathIn = "oss://spark-oss/workline.txt" val inputData = sc.textFile(pathIn, 5) //RDD写入。 inputData.repartition(1).saveAsTextFile("oss://spark-oss/user/data3") } finally { sc.stop() } } }说明执行该代码前,请您务必检查是否已添加了
hadoop-fs-oss依赖,否则会报错。示例2:Local模式下的代码示例。
package com.aliyun.odps.spark.examples import java.io.ByteArrayInputStream import com.aliyun.oss.{OSSClientBuilder,OSSClient} import org.apache.spark.sql.SparkSession object SparkOSS { def main(args: Array[String]) { val spark = SparkSession .builder() .config("spark.master", "local[4]") // 需要设置spark.master为local[N]才能直接运行,N为并发数。 .config("spark.hadoop.fs.oss.accessKeyId", "") .config("spark.hadoop.fs.oss.accessKeySecret", "") .config("spark.hadoop.fs.oss.endpoint", "oss-cn-beijing.aliyuncs.com") .appName("SparkOSS") .getOrCreate() val sc = spark.sparkContext try { //OSS文件的读取。 val pathIn = "oss://spark-oss/workline.txt" val inputData = sc.textFile(pathIn, 5) val cnt = inputData.count inputData.count() println(s"count: $cnt") //OSS文件的写入。 // 阿里云账号AccessKey拥有所有API的访问权限,风险很高。强烈建议您创建并使用RAM用户进行API访问或日常运维,请登录RAM控制台创建RAM用户 // 此处以把AccessKey 和 AccessKeySecret 保存在环境变量为例说明。您也可以根据业务需要,保存到配置文件里 // 强烈建议不要把 AccessKey 和 AccessKeySecret 保存到代码里,会存在密钥泄漏风险 val ossClient = new OSSClientBuilder().build("oss-cn-beijing.aliyuncs.com", System.getenv("ALIBABA_CLOUD_ACCESS_KEY_ID"), System.getenv("ALIBABA_CLOUD_ACCESS_KEY_SECRET")) val filePath="user/data" ossClient.putObject("spark-oss",filePath , new ByteArrayInputStream(cnt.toString.getBytes())) ossClient.shutdown() } finally { sc.stop() } } }示例3:Cluster模式下的代码示例。
package com.aliyun.odps.spark.examples import java.io.ByteArrayInputStream import com.aliyun.oss.{OSSClientBuilder,OSSClient} import org.apache.spark.sql.SparkSession object SparkOSS { def main(args: Array[String]) { val spark = SparkSession .builder() .appName("SparkOSS") .getOrCreate() val sc = spark.sparkContext try { //OSS文件的读取。 val pathIn = "oss://spark-oss/workline.txt" val inputData = sc.textFile(pathIn, 5) val cnt = inputData.count inputData.count() println(s"count: $cnt") // inputData.repartition(1).saveAsTextFile("oss://spark-oss/user/data3") //OSS文件的写入。 // 阿里云账号AccessKey拥有所有API的访问权限,风险很高。强烈建议您创建并使用RAM用户进行API访问或日常运维,请登录RAM控制台创建RAM用户 // 此处以把AccessKey 和 AccessKeySecret 保存在环境变量为例说明。您也可以根据业务需要,保存到配置文件里 // 强烈建议不要把 AccessKey 和 AccessKeySecret 保存到代码里,会存在密钥泄漏风险 val ossClient = new OSSClientBuilder().build("oss-cn-beijing.aliyuncs.com", System.getenv("ALIBABA_CLOUD_ACCESS_KEY_ID"), System.getenv("ALIBABA_CLOUD_ACCESS_KEY_SECRET")) val filePath="user/data" ossClient.putObject("spark-oss",filePath , new ByteArrayInputStream(cnt.toString.getBytes())) ossClient.shutdown() } finally { sc.stop() } } }
提交方式:
Local模式下的代码通过IntelliJ IDEA开发、测试并提交。更多操作信息,请参见Spark在MaxCompute的运行方式。
在DataWorks上通过ODPS Spark节点提交并运行。详情请参见创建ODPS Spark节点。
读MaxCompute写OSS
通过IntelliJ IDEA工具或DataWorks,实现读取MaxCompute数据并写入OSS。
代码示例
Local模式下的示例代码。
package com.aliyun.odps.spark.examples.userpakage import org.apache.spark.sql.{SaveMode, SparkSession} object SparkODPS2OSS { def main(args: Array[String]): Unit = { val spark = SparkSession .builder() .appName("Spark2OSS") .config("spark.master", "local[4]")// 需设置spark.master为local[N]才能直接运行,N为并发数 .config("spark.hadoop.odps.project.name", "") .config("spark.hadoop.odps.access.id", "") .config("spark.hadoop.odps.access.key", "") .config("spark.hadoop.odps.end.point", "http://service.cn.maxcompute.aliyun.com/api") .config("spark.sql.catalogImplementation", "odps") .config("spark.hadoop.fs.oss.accessKeyId","") .config("spark.hadoop.fs.oss.accessKeySecret","") .config("spark.hadoop.fs.oss.endpoint","oss-cn-beijing.aliyuncs.com") .getOrCreate() try{ //通过SparkSql查询表 val data = spark.sql("select * from user_detail") //展示查询数据 data.show(10) //将查询到的数据存储到一个OSS的文件中 data.toDF().coalesce(1).write.mode(SaveMode.Overwrite).csv("oss://spark-oss/user/data3") }finally { spark.stop() } } }Cluster模式下的示例代码。
package com.aliyun.odps.spark.examples.userpakage import org.apache.spark.sql.{SaveMode, SparkSession} object SparkODPS2OSS { def main(args: Array[String]): Unit = { val spark = SparkSession .builder() .appName("SparkODPS2OSS") .getOrCreate() try{ //通过SparkSql查询表 val data = spark.sql("select * from user_detail") //展示查询数据 data.show(10) //将查询到的数据存储到一个OSS的文件中 data.toDF().coalesce(1).write.mode(SaveMode.Overwrite).csv("oss://spark-oss/user/data3") }finally { spark.stop() } } }
提交方式:
Local模式下的代码通过IntelliJ IDEA开发、测试并提交。
在DataWorks上通过ODPS Spark节点提交并运行。详情请参见创建ODPS Spark节点。
说明Spark开发环境的配置请参见Spark在MaxCompute的运行方式。
读OSS外部表
MaxCompute Spark支持读PARQUET、TEXTFILE、 ORC、AVRO和SEQUENCEFILE格式的OSS外部表,创建OSS外部表详情请参见创建OSS外部表。
当Spark版本为2.x版本时,需要添加如下参数:
spark.sql.odps.enableExternalTable=true spark.sql.odps.enableExternalProject=true当Spark版本为3.x版本时,需要添加如下参数:
spark.sql.catalog.odps.enableExternalTable=true spark.sql.catalog.odps.enableExternalProject=true
读OSS外部表示例用到mc_table的MaxCompute表数据信息如下。
1,1,51,1,46.81006,-92.08174,9/14/2014 0:00,S
1,2,13,1,46.81006,-92.08174,9/14/2014 0:00,NE
1,3,48,1,46.81006,-92.08174,9/14/2014 0:00,NE
1,4,30,1,46.81006,-92.08174,9/14/2014 0:00,W
1,5,47,1,46.81006,-92.08174,9/14/2014 0:00,S
1,6,9,1,46.81006,-92.08174,9/15/2014 0:00,S
1,7,53,1,46.81006,-92.08174,9/15/2014 0:00,N
1,8,63,1,46.81006,-92.08174,9/15/2014 0:00,SW
1,9,4,1,46.81006,-92.08174,9/15/2014 0:00,NE
1,10,31,1,46.81006,-92.08174,9/15/2014 0:00,N读PARQUET格式的OSS外部表示例
在MaxCompute中使用如下命令通过内置开源解析器创建PARQUET格式OSS外部表。
create external table if not exists mc_oss_parquet_external( vehicleId STRING , recordId STRING, patientId STRING, calls STRING, locationLatitute STRING, locationLongtitue STRING, recordTime string, direction string) stored as parquet location '<oss_location>' ;导入数据。
insert into table mc_oss_parquet_external select * from mc_table;使用MaxCompute Spark查询数据。
import org.apache.spark.sql.SparkSession object externalTable_rds { def main(args: Array[String]): Unit = { val spark = SparkSession .builder() .appName("external_TableL-on-MaxCompute") .getOrCreate() // 访问外部表parquet print("=====读parquet表=====") spark.sql("select * from <project_name>.mc_oss_parquet_external").show(1000) } }查询结果如下。
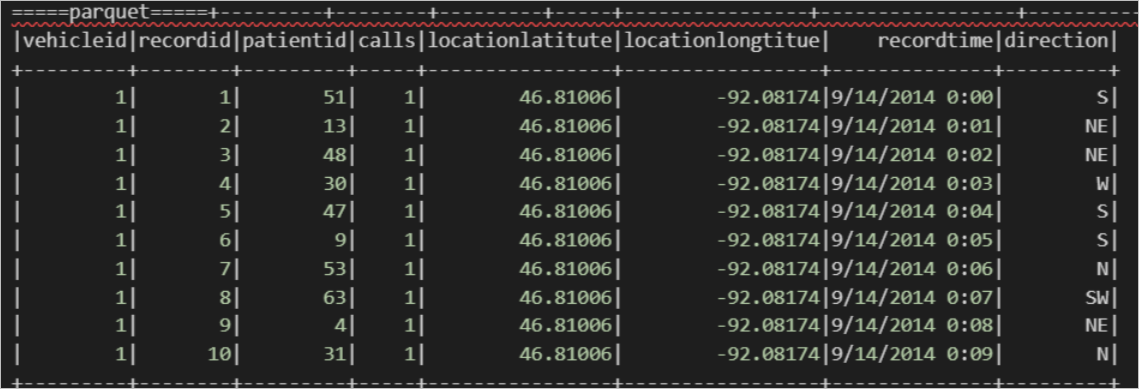
读TEXTFILE格式的OSS外部表示例。
关联TEXT数据。
在MaxCompute中使用如下命令通过内置开源解析器创建TEXTFILE(TEXT)格式OSS外部表。
create external table if not exists mc_oss_textfile_external( vehicleId STRING , recordId STRING, patientId STRING, calls STRING, locationLatitute STRING, locationLongtitue STRING, recordTime string, direction string) stored as textfile location '<oss_location>' ;导入数据。
insert into table mc_oss_textfile_external select * from mc_table;使用MaxCompute Spark查询数据。
import org.apache.spark.sql.SparkSession object externalTable_rds { def main(args: Array[String]): Unit = { val spark = SparkSession .builder() .appName("external_TableL-on-MaxCompute") .getOrCreate() // 访问外部表 stored as textfile; print("=====读外部表-textfile=====") spark.sql("select * from <project_name>.mc_oss_textfile_external").show(1000) } }查询结果如下。
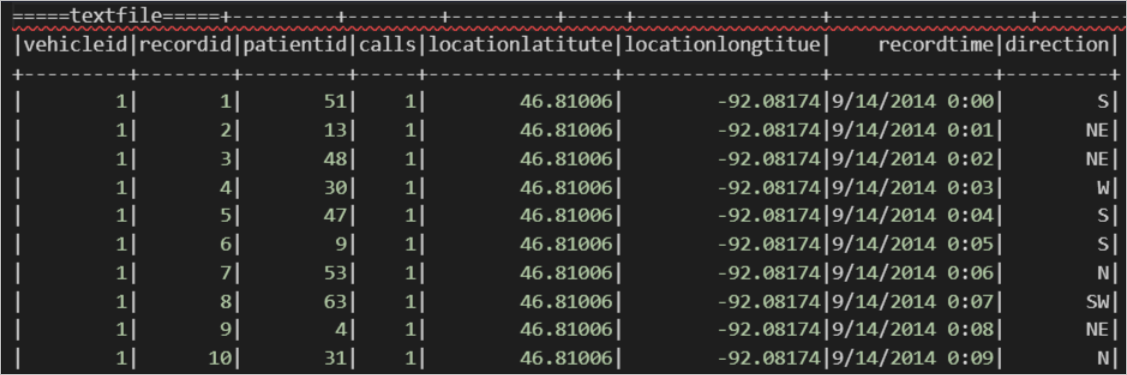
关联CSV数据。
在MaxCompute中使用如下命令通过内置开源解析器创建TEXTFILE(CSV)格式OSS外部表。
create external table if not exists mc_oss_csv_external( vehicleId STRING , recordId STRING, patientId STRING, calls STRING, locationLatitute STRING, locationLongtitue STRING, recordTime string, direction string) row format serde 'org.apache.hadoop.hive.serde2.OpenCSVSerde' with serdeproperties ( "separatorChar" = ",", "quoteChar"= '"', "escapeChar"= "\\" ) stored as textfile location '<oss_location>' tblproperties ( "skip.header.line.count"="1", "skip.footer.line.count"="1" ) ;导入数据。
insert into table mc_oss_csv_external select * from mc_table;使用MaxCompute Spark查询数据。
import org.apache.spark.sql.SparkSession object externalTable_rds { def main(args: Array[String]): Unit = { val spark = SparkSession .builder() .appName("external_TableL-on-MaxCompute") .getOrCreate() // 访问外部表 csv print("=====读 csv 外部表=====") spark.sql("select * from <project_name>.mc_oss_csv_external").show(1000) } }查询结果如下。
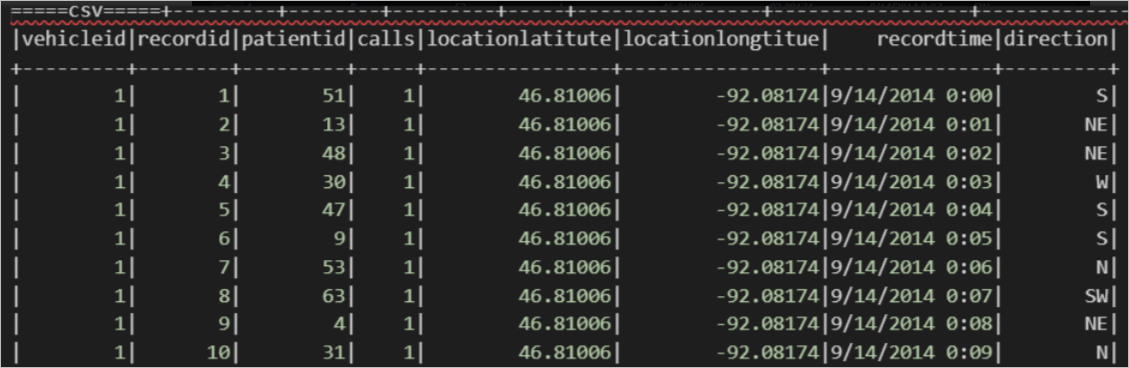
关联JSON数据。
在MaxCompute中使用如下命令通过内置开源解析器创建TEXTFILE(JSON)格式OSS外部表。
create external table if not exists mc_oss_json_external( vehicleId STRING , recordId STRING, patientId STRING, calls STRING, locationLatitute STRING, locationLongtitue STRING, recordTime string, direction string) row format serde 'org.apache.hive.hcatalog.data.JsonSerDe' stored as textfile location '<oss_location>' ;导入数据。
insert into table mc_oss_json_external select * from mc_table;使用MaxCompute Spark查询数据。
import org.apache.spark.sql.SparkSession object externalTable_rds { def main(args: Array[String]): Unit = { val spark = SparkSession .builder() .appName("external_TableL-on-MaxCompute") .getOrCreate() // 访问外部表 stored as textfile; print("=====读外部表-json=====") spark.sql("select * from <project_name>.mc_oss_json_external").show(1000) } }查询结果如下。
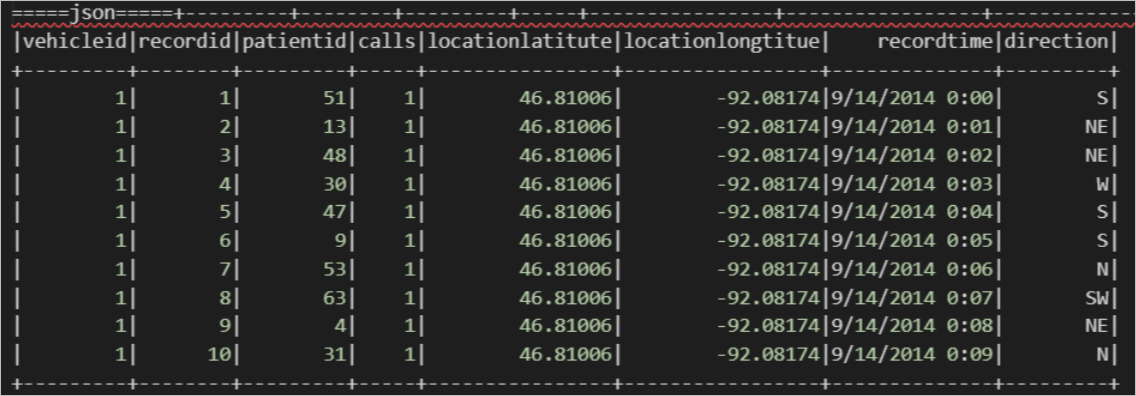
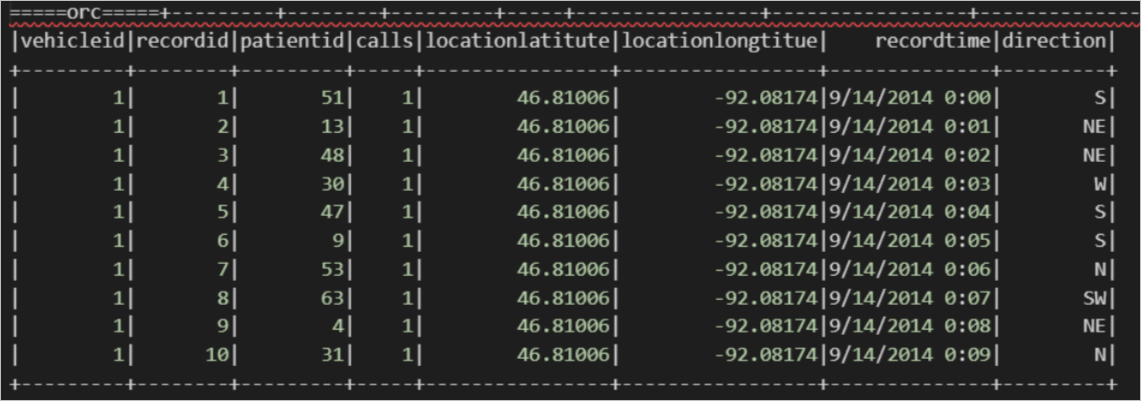
读ORC格式的OSS外部表示例。
在MaxCompute中使用如下命令通过内置开源解析器创建ORC格式OSS外部表。
create external table if not exists mc_oss_orc_external( vehicleId STRING , recordId STRING, patientId STRING, calls STRING, locationLatitute STRING, locationLongtitue STRING, recordTime string, direction string) stored as orc location '<oss_location>' ;导入数据。
insert into table mc_oss_orc_external select * from mc_table;使用MaxCompute Spark查询数据。
import org.apache.spark.sql.SparkSession object externalTable_rds { def main(args: Array[String]): Unit = { val spark = SparkSession .builder() .appName("external_TableL-on-MaxCompute") .getOrCreate() // 访问外部表 orc; print("=====读orc外部表=====") spark.sql("select * from <project_name>.mc_oss_orc_external").show(1000) } }查询结果如下。
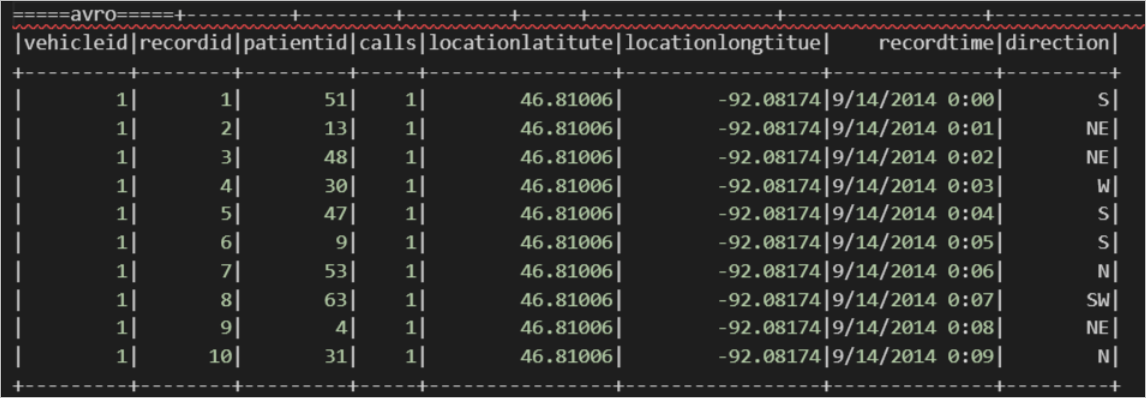
读AVRO格式的OSS外部表示例。
在MaxCompute中使用如下命令通过内置开源解析器创建AVRO格式OSS外部表。
create external table if not exists mc_oss_avro_external( vehicleId STRING , recordId STRING, patientId STRING, calls STRING, locationLatitute STRING, locationLongtitue STRING, recordTime string, direction string) stored as avro location '<oss_location>' ;导入数据。
insert into table mc_oss_avro_external select * from mc_table;使用MaxCompute Spark查询数据。
import org.apache.spark.sql.SparkSession object externalTable_rds { def main(args: Array[String]): Unit = { val spark = SparkSession .builder() .appName("external_TableL-on-MaxCompute") .getOrCreate() // 访问外部表 avro; print("=====读avro外部表=====") spark.sql("select * from <project_name>.mc_oss_avro_external").show(1000) } }查询结果如下。
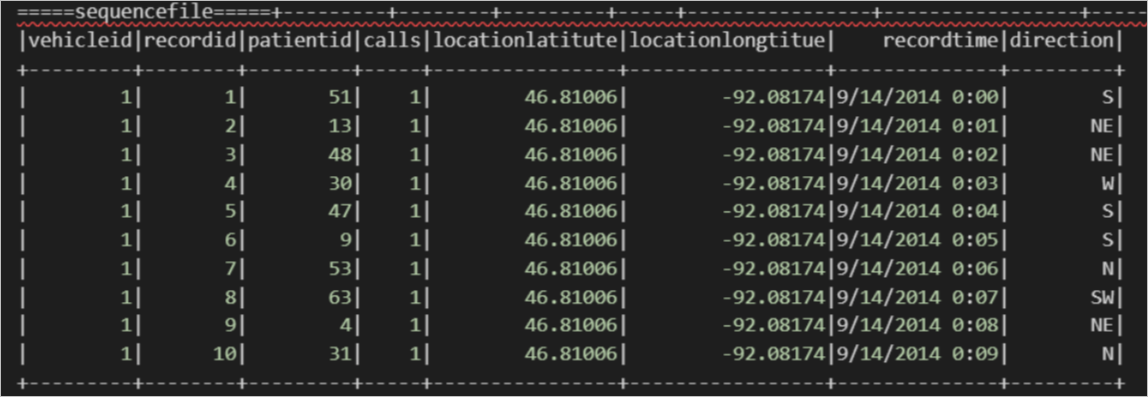
读SEQUENCEFILE格式的OSS外部表示例。
在MaxCompute中使用如下命令通过内置开源解析器创建SEQUENCEFILE格式OSS外部表。
create external table if not exists mc_oss_sequencfile_external( vehicleId STRING , recordId STRING, patientId STRING, calls STRING, locationLatitute STRING, locationLongtitue STRING, recordTime string, direction string) stored as sequencfile location '<oss_location>' ;导入数据。
insert into table mc_oss_sequencfile_external select * from mc_table;使用MaxCompute Spark查询数据。
import org.apache.spark.sql.SparkSession object externalTable_rds { def main(args: Array[String]): Unit = { val spark = SparkSession .builder() .appName("external_TableL-on-MaxCompute") .getOrCreate() // 访问外部表 sequencefile; print("=====sequencefile=====") spark.sql("select * from <project_name>.mc_oss_sequencfile_external").show(1000) } }查询结果如下。
参数说明
参数
说明
oss_location
数据文件所在OSS路径。格式为
oss://<oss_endpoint>/<Bucket名称>/<OSS目录名称>/。MaxCompute默认会读取该路径下的所有数据文件。oss_endpoint:OSS访问域名信息。建议您使用OSS提供的内网域名,否则将产生OSS流量费用。更多OSS内网域名信息,请参见访问域名和数据中心。
说明建议数据文件存放的OSS地域与MaxCompute项目所在地域保持一致。由于MaxCompute只在部分地域部署,跨地域的数据连通性可能存在问题。
Bucket名称:OSS存储空间名称,即Bucket名称。更多查看存储空间名称信息,请参见列举存储空间。
目录名称:OSS目录名称。目录后不需要指定文件名。
--正确用法。 oss://oss-cn-shanghai-internal.aliyuncs.com/oss-mc-test/Demo1/ --错误用法。 http://oss-cn-shanghai-internal.aliyuncs.com/oss-mc-test/Demo1/ -- 不支持HTTP连接。 https://oss-cn-shanghai-internal.aliyuncs.com/oss-mc-test/Demo1/ -- 不支持HTTPS连接。 oss://oss-cn-shanghai-internal.aliyuncs.com/Demo1 -- 连接地址错误。 oss://oss-cn-shanghai-internal.aliyuncs.com/oss-mc-test/Demo1/vehicle.csv -- 不需要指定文件名。
project_name
创建OSS外部表所在的MaxCompute项目名称。
读Hologres外部表
前提条件
在Hologres实例内已创建内部表,详情请参见新建内部表。
在MaxCompute实例内已创建Hologres外部表,详情请参见Hologres外部表。
说明当Spark版本为2.x版本时,需要添加如下参数:
spark.sql.odps.enableExternalTable=true spark.sql.odps.enableExternalProject=true当Spark版本为3.x版本时,需要添加如下参数:
spark.sql.catalog.odps.enableExternalTable=true spark.sql.catalog.odps.enableExternalProject=true
使用示例
-- 配置项 -- 当前默认关闭对于外表和外部project的支持 spark.sql.odps.enableExternalTable=true -- 指定spark版本 spark.hadoop.odps.spark.version=spark-2.4.5-odps0.34.0 -- 如果出现中文乱码,需要加如下配置 spark.executor.extraJavaOptions=-Dfile.encoding=UTF-8 -Dsun.jnu.encoding=UTF-8 spark.driver.extraJavaOptions=-Dfile.encoding=UTF-8 -Dsun.jnu.encoding=UTF-8 -- 代码 import org.apache.spark.sql.SparkSession object externalTable_holo { def main(args: Array[String]): Unit = { val spark = SparkSession .builder() .appName("external_TableL-on-MaxCompute") .getOrCreate() // 访问外部表 Hologres; print("=====hologres=====") spark.sql("select * from <tablename_holo_ext>").show(1000) } }tablename_holo_ext为创建的Hologres外部表名称。
读HBase外部表
前提条件
在HBase内已创建表,详情请参见HBase Shell使用介绍。
在MaxCompute实例内已创建HBase外部表,详情请参见HBase外部表(HBase标准版或增强版)。
说明当Spark版本为2.x版本时,需要添加如下参数:
spark.sql.odps.enableExternalTable=true spark.sql.odps.enableExternalProject=true当Spark版本为3.x版本时,需要添加如下参数:
spark.sql.catalog.odps.enableExternalTable=true spark.sql.catalog.odps.enableExternalProject=true
使用示例
-- 配置项 -- 当前默认关闭对于外表和外部project的支持 spark.sql.odps.enableExternalTable=true -- 指定spark版本 spark.hadoop.odps.spark.version=spark-2.4.5-odps0.34.0 -- 如果出现中文乱码,需要加如下配置 spark.executor.extraJavaOptions=-Dfile.encoding=UTF-8 -Dsun.jnu.encoding=UTF-8 spark.driver.extraJavaOptions=-Dfile.encoding=UTF-8 -Dsun.jnu.encoding=UTF-8 -- 代码 import org.apache.spark.sql.SparkSession object externalTable_hbase { def main(args: Array[String]): Unit = { val spark = SparkSession .builder() .appName("external_TableL-on-MaxCompute") .getOrCreate() // 访问外部表 HBase; print("=====HBase=====") spark.sql("select * from <tablename_hbase_ext>").show(1000) } }tablename_hbase_ext为创建的HBase外部表名称。
- 本页导读 (1)