
完成了数据集的构建,就可以开始模型的训练了。回到创建的项目,切换至“模型中心”并点击“创建模型”。
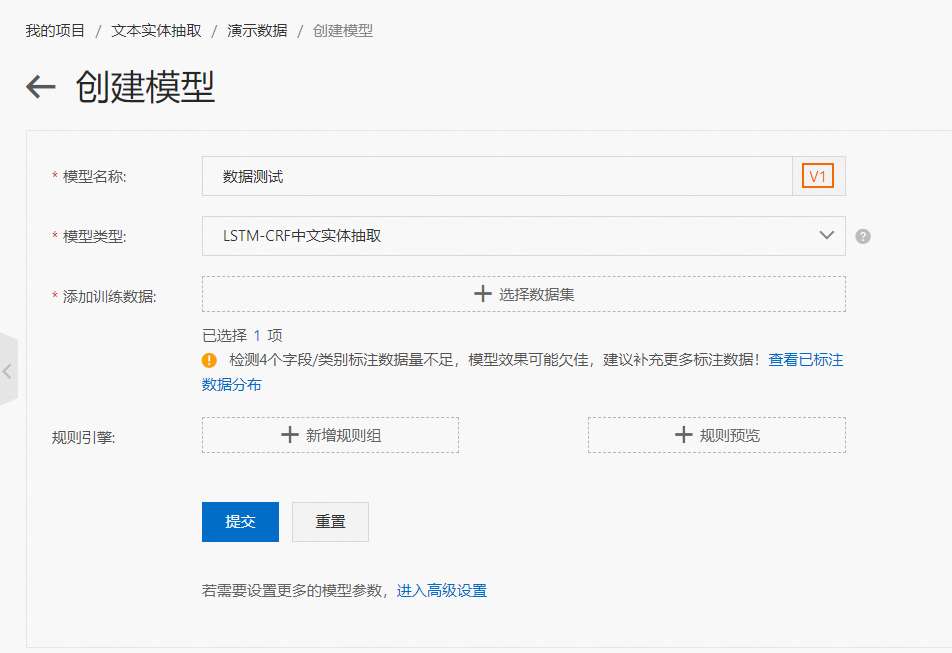
进入创建模型后,通过自学习平台,您无需关心任何模型的实现细节,只要选择相应的模型就可以开始训练。首先请填入模型的名称。
在模型类型处,我们提供了多个类型的模型供您选择,支持中文实体抽取或是英文实体抽取服务。您可以在模型说明中查看详情。
系统默认会选择中文的LSTM-CRF 模型。点击添加训练数据的按钮,可以找到您已经标注或上传好的数据集。至此,您就可以点击提交,模型将会自动开始训练。在创建模型这里我们还会看到几个选项,比如专业词表上传和正则表达式设置,以及高级设置。这些内容将在“规则引擎和高级设置一章”详细阐述。
在模型完成初始化后,自动进入模型训练阶段。点击“查看”,可以进入模型详情页面,查看训练日志和具体的评测指标。
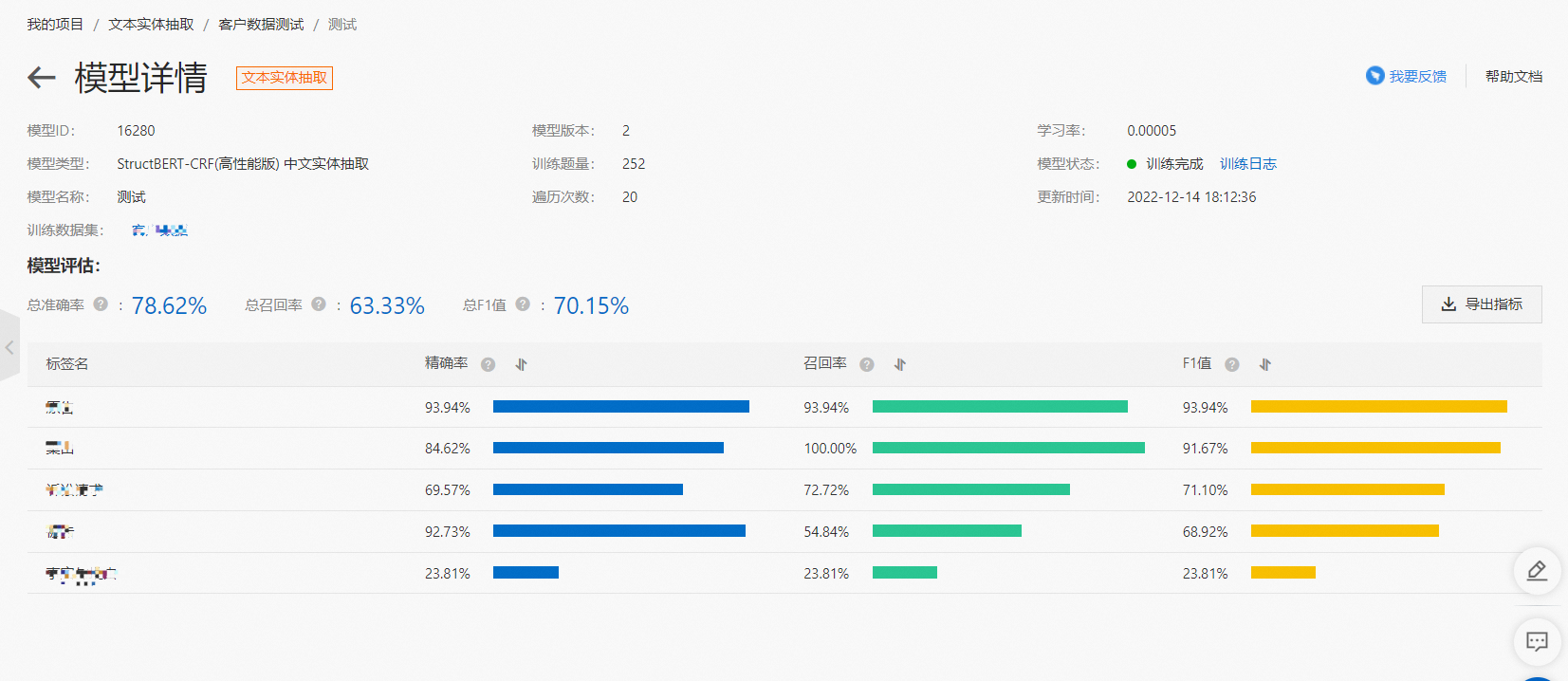
我们提供了精确率(Precision),召回率(Recall),F1值作为实体抽取的评测指标。这三个值得取值范围都在 0~1 之间。简单来说,这三个值越大说明模型的性能越好。
精确率(Precision):对某一类别而言为正确预测为该类别的样本数与预测为该类别的总样本数之比。对于整体而言为正确预测的样本数与预测的总样本数之比。
召回率(Recall):对某一类别而言为正确预测为该类别的样本数与该类别的总样本数之比,对于整体而言为正确预测的样本数与所有类别的总样本数之比。
F1值:为精确率和召回率的调和平均数。
该文章对您有帮助吗?