本文介绍如何在数据湖分析控制台创建和执行Spark作业。
准备事项
您需要在提交作业之前先创建虚拟集群。
说明创建虚拟集群时注意选择引擎类型为Spark。
如果您是子账号登录,需要配置子账号提交作业的权限,具体请参考细粒度配置RAM子账号权限。由于SparkPi不需要访问外部数据源,您只需要配置文档中的前两个步骤:”DLA子账号关联RAM子账号“和”为子账号授予访问DLA的权限“。
操作步骤
页面左上角,选择DLA所在地域。
单击左侧导航栏中的Serverless Spark -> 作业管理。
在作业编辑页面,单击创建作业模板。
在创建作业模板页面,按照页面提示进行参数配置。
参数名称
参数说明
文件名称
设置文件或者文件夹的名字。文件名称不区分大小写。
文件类型
可以设置为文件或者文件夹。
父级
设置文件或者文件夹的上层目录。
作业列表相当于根目录,所有的作业都在作业列表下创建。
您可以在作业列表下创建文件夹,然后在文件夹下创建作业;也可以直接在作业列表根目录下创建作业。
作业类型
您可以选择为SparkJob或SparkSQL。
SparkJob:Python/Java/Scala类型的Spark作业,需要填写JSON配置作业。
SparkSQL:SQL类型的Spark配置, 通过set命令配置作业,详情请就参见Spark SQL。
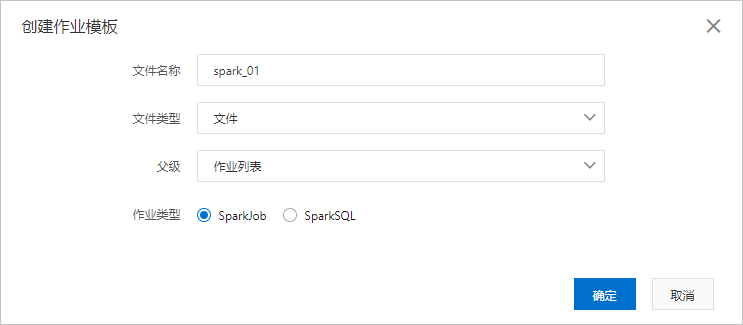
完成上述参数配置后,单击确定创建Spark作业。
创建Spark作业后,您可以根据作业配置指南编写Spark作业。
Spark作业编写完成后,您可以进行以下操作:
单击保存,保存Spark作业,便于后续复用作业。
单击执行,执行Spark作业,作业列表实时显示作业的执行状态。
单击示例,右侧作业编辑框显示DLA为您提供的SparkPi示例作业,单击执行,执行SparkPi示例。
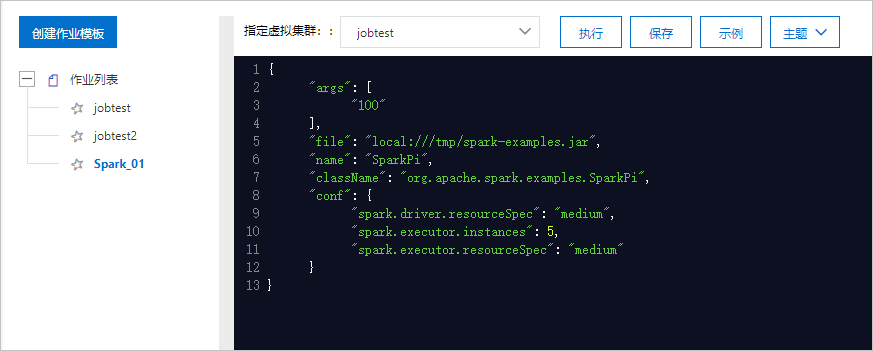
(可选)在作业列表中,查看作业状态或对作业执行操作。

配置
说明
作业ID
Spark任务ID,由系统生成。
状态
Spark任务的运行状态。
STARTING:任务正在提交。
RUNNING:任务运行中。
SUCCESS:Spark作业执行成功。
DEAD:任务出错,可通过查看日志进行排错处理。
KILLED:任务被主动终止。
作业名称
创建Spark作业时设置的作业名称,由name参数指定。
提交时间
当前Spark作业的提交时间。
启动时间
当前Spark作业的启动时间。
更新时间
当前Spark作业状态发生变化时的更新时间。
持续时间
运行当前Spark作业所花费的时间。
操作
操作中有5个参数,分别为:
日志,当前作业的日志,只获取最新的300行日志。
SparkUI,当前作业的Spark Job UI 地址,如果Token过期需要单击刷新获取最新的地址。
详情,当前作业提交时填写的JSON脚本。
kill,终止当前的作业。
历史,查看当前作业的作业尝试列表。
监控,查看当前作业的监控数据。
(可选)单击作业尝试列表,查看所有作业的作业尝试。
说明默认情况下,一个作业只会进行一次作业尝试。如需进行多次作业尝试,请配置作业重置参数。更多信息,请参见。
在作业尝试列表中,选中单个作业,单击,可以查看该作业的尝试列表。

附录
数据湖分析提供了开发Spark作业的Demo,您可以参考开源项目Aliyun DLA Demo。您可以直接进行下载,执行mvn进行打包。建议您参考本项目进行pom配置和开发。
使用DMS进行Spark作业编排和任务周期调度,请参考文档DMS任务编排调度Spark任务训练机器学习模型。
DLA Spark作业配置,请参考文档作业配置指南。