
如果您在使用PolarDB MySQL遇到查询慢的问题时,可以通过数据传输服务DTS将企业线上的PolarDB MySQL中的生产数据实时同步到阿里云Elasticsearch(简称ES)中进行搜索分析。DTS同步适用于对实时同步要求较高的关系型数据库中数据的同步场景。
背景信息
本文涉及以下三个云产品,相关介绍如下:
数据传输服务DTS(Data Transmission Service):一种集数据迁移、数据订阅及数据实时同步于一体的数据传输服务。DTS支持同步的SQL操作包括:Insert、Delete、Update。 详情请参见数据传输服务DTS、同步方案概览。
PolarDB:阿里云自研的下一代关系型云数据库,有三个独立的引擎,分别可以100%兼容MySQL、100%兼容PostgreSQL、高度兼容Oracle语法。存储容量最高可达100TB,单库最多可扩展到16个节点,适用于企业多样化的数据库应用场景。详情请参见PolarDB MySQL概述。
Elasticsearch:一个基于Lucene的实时分布式的搜索与分析引擎,它提供了一个分布式服务,可以使您快速的近乎于准实时的存储、查询和分析超大数据集,通常被用来作为构建复杂查询特性和需求强大应用的基础引擎或技术。详情请参见什么是阿里云Elasticsearch。
注意事项
DTS不支持同步DDL操作,如果源库中待同步的表在同步的过程中已经执行了DDL操作,您需要先移除同步对象,然后在ES实例中移除该表对应的索引,最后新增同步对象。详情请参见移除同步对象和新增同步对象。
如果源库中待同步的表需要执行增加列的操作,您只需先在ES实例中修改对应表的mapping,然后在源库中执行相应的DDL操作,最后暂停并启动DTS增量数据同步任务。
DTS在执行全量数据初始化时将占用源库和目标库一定的读写资源,可能会导致数据库的负载上升,在数据库性能较差、规格较低或业务量较大的情况下(例如源库有大量慢SQL、存在无主键表或目标库存在死锁等),可能会加重数据库压力,甚至导致数据库服务不可用。因此您需要在执行数据同步前评估源库和目标库的性能,同时建议您在业务低峰期执行数据同步(例如源库和目标库的CPU负载在30%以下)。
在业务高峰期全量同步数据,可能造成全量数据同步失败,重启全量同步任务即可。
在业务高峰期增量同步数据,可能出现数据同步延迟的情况。
操作步骤
完成数据同步主要包括两个步骤:
准备环境:在源库PolarDB MySQL中准备待同步数据,然后创建目标库ES实例,并为ES实例开启自动创建索引功能。
创建数据同步任务:在DTS控制台创建源库到目标库的数据同步链路,购买并启动同步链路任务后数据会自动进行全量和增量同步。
步骤一:环境准备
文本以将PolarDB MySQL 8.0.1企业版集群中的数据同步到阿里云ES 7.10版本实例中为例。
准备源库待同步数据
创建PolarDB MySQL 8.0.1企业版集群。具体操作,请参见购买企业版集群。
为PolarDB MySQL集群开启Binlog功能。具体操作,请参见开启Binlog。
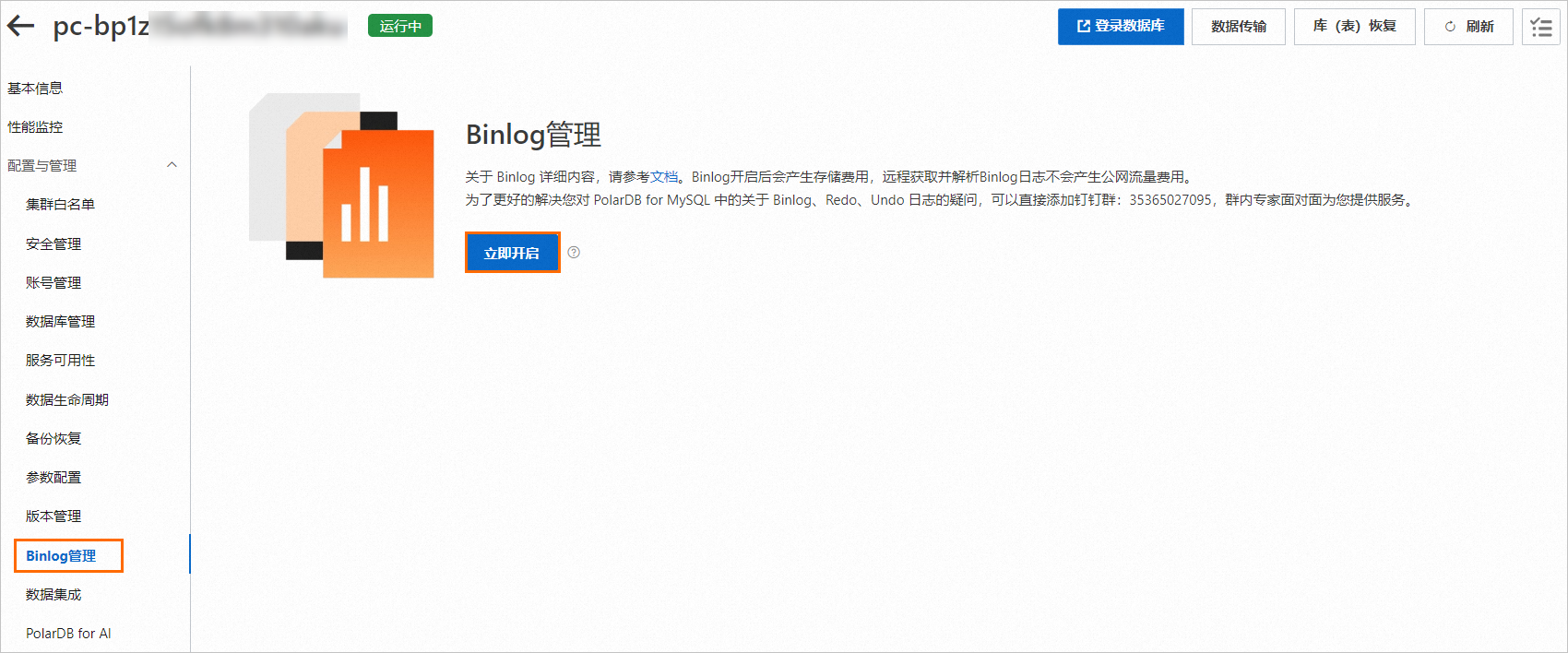
创建账号和数据库
test_polardb。 具体操作,请参见创建和管理数据库账号、管理数据库。在数据库
test_polardb中,新建表product并插入数据。建表语句
CREATE TABLE `product` ( `id` bigint(32) NOT NULL AUTO_INCREMENT, `name` varchar(32) NULL, `price` varchar(32) NULL, `code` varchar(32) NULL, `color` varchar(32) NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARACTER SET=utf8;插入测试数据
INSERT INTO `test_polardb`.`product` (`id`,`name`,`price`,`code`,`color`) VALUES (1,'mobile phone A','2000','amp','golden'); INSERT INTO `test_polardb`.`product` (`id`,`name`,`price`,`code`,`color`) VALUES (2,'mobile phone B','2200','bmp','white'); INSERT INTO `test_polardb`.`product` (`id`,`name`,`price`,`code`,`color`) VALUES (3,'mobile phone C','2600','cmp','black'); INSERT INTO `test_polardb`.`product` (`id`,`name`,`price`,`code`,`color`) VALUES (4,'mobile phone D','2700','dmp','red'); INSERT INTO `test_polardb`.`product` (`id`,`name`,`price`,`code`,`color`) VALUES (5,'mobile phone E','2800','emp','silvery');
准备目标库ES实例
创建阿里云ES 7.10版本实例。具体操作,请参见创建阿里云Elasticsearch实例。
ES实例开启自动创建索引功能。具体操作,请参见配置YML参数。

步骤二:创建数据同步任务
单击创建任务。
按照页面提示配置数据同步任务。
以下步骤中涉及的参数的说明,请参见PolarDB MySQL为源的数据同步。
配置源库及目标库,在页面下方单击测试连接以进行下一步。
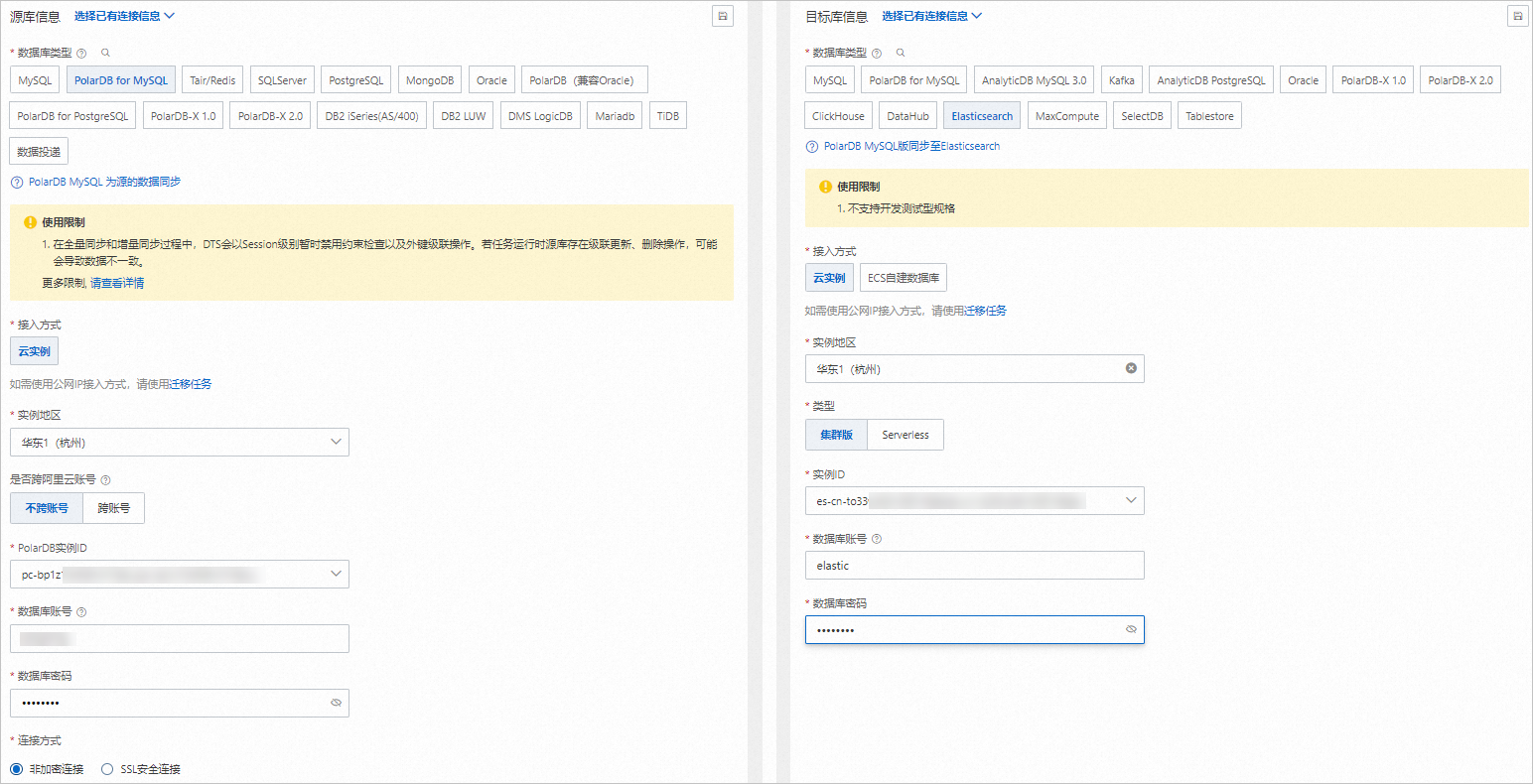
配置任务对象。
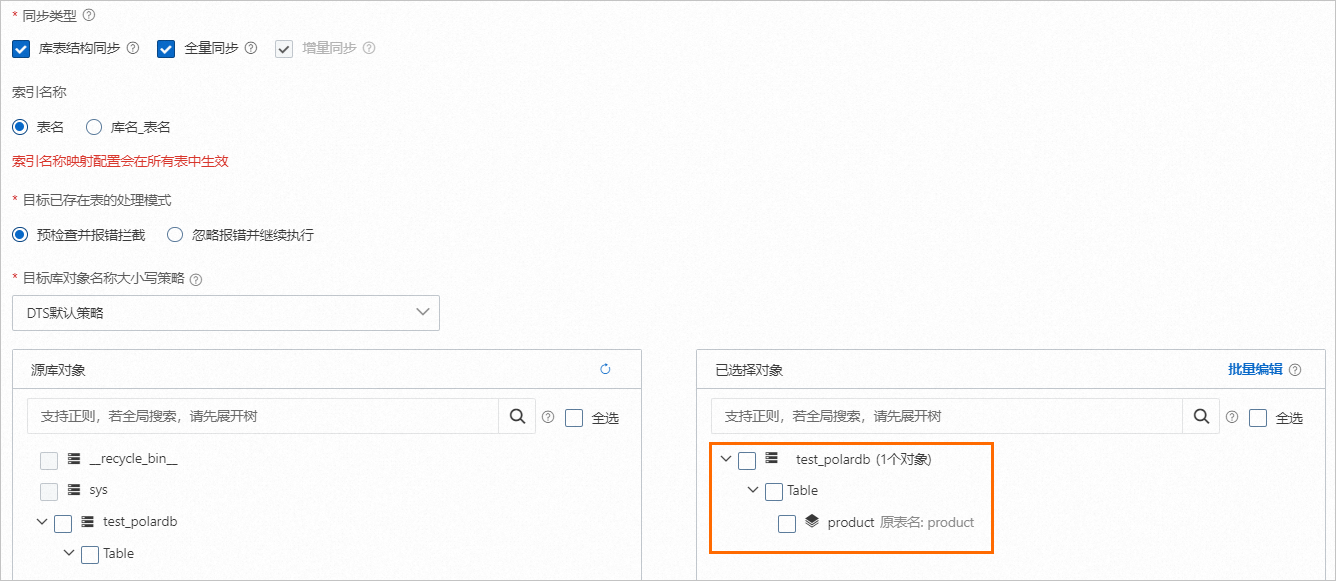
配置高级设置,本文高级配置保持默认。
在库表列配置页面,单击全部设置为非_routing策略,将全部表设置为非_routing策略。
说明目标库ES实例为7.x版本时,全部表必须设置为非_routing策略。
配置完成后,根据页面提示保存并预检查任务、购买并启动任务。
购买并启动任务成功后,同步任务正式开始。您可在数据同步界面查看具体任务进度,待全量同步完成后,您即可在ES实例中查看同步成功的数据。

步骤三(可选):验证数据同步结果
登录目标ES实例的Kibana控制台。
登录Kibana控制台,请参见登录Kibana控制台。
在Kibana页面的左上角,选择
 > Management > 开发工具(Dev Tools),在控制台(Console)中执行以下命令。
> Management > 开发工具(Dev Tools),在控制台(Console)中执行以下命令。验证全量数据同步结果。
执行以下命令,查看全量数据同步结果。
GET /product/_search预期结果如下:
{ "took" : 3, "timed_out" : false, "_shards" : { "total" : 5, "successful" : 5, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 5, "relation" : "eq" }, "max_score" : 1.0, "hits" : [ { "_index" : "product", "_type" : "product", "_id" : "3", "_score" : 1.0, "_source" : { "id" : 3, "name" : "mobile phone C", "price" : "2600", "code" : "cmp", "color" : "black" } }, { "_index" : "product", "_type" : "product", "_id" : "5", "_score" : 1.0, "_source" : { "id" : 5, "name" : "mobile phone E", "price" : "2800", "code" : "emp", "color" : "silvery" } }, { "_index" : "product", "_type" : "product", "_id" : "4", "_score" : 1.0, "_source" : { "id" : 4, "name" : "mobile phone D", "price" : "2700", "code" : "dmp", "color" : "red" } }, { "_index" : "product", "_type" : "product", "_id" : "2", "_score" : 1.0, "_source" : { "id" : 2, "name" : "mobile phone B", "price" : "2200", "code" : "bmp", "color" : "white" } }, { "_index" : "product", "_type" : "product", "_id" : "1", "_score" : 1.0, "_source" : { "id" : 1, "name" : "mobile phone A", "price" : "2000", "code" : "amp", "color" : "golden" } } ] } }验证增量数据同步结果。
通过以下SQL语句,在PolarDB MySQL集群中插入一条数据。
INSERT INTO `test_polardb`.`product` (`id`,`name`,`price`,`code`,`color`) VALUES (6,'mobile phone F','2750','fmp','white');等待增量同步完成后,再次执行命令
GET /product/_search,查看增量数据同步结果。预期结果如下:
{ "took" : 439, "timed_out" : false, "_shards" : { "total" : 5, "successful" : 5, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 6, "relation" : "eq" }, "max_score" : 1.0, "hits" : [ { "_index" : "product", "_type" : "product", "_id" : "3", "_score" : 1.0, "_source" : { "id" : 3, "name" : "mobile phone C", "price" : "2600", "code" : "cmp", "color" : "black" } }, { "_index" : "product", "_type" : "product", "_id" : "5", "_score" : 1.0, "_source" : { "id" : 5, "name" : "mobile phone E", "price" : "2800", "code" : "emp", "color" : "silvery" } }, { "_index" : "product", "_type" : "product", "_id" : "4", "_score" : 1.0, "_source" : { "id" : 4, "name" : "mobile phone D", "price" : "2700", "code" : "dmp", "color" : "red" } }, { "_index" : "product", "_type" : "product", "_id" : "2", "_score" : 1.0, "_source" : { "id" : 2, "name" : "mobile phone B", "price" : "2200", "code" : "bmp", "color" : "white" } }, { "_index" : "product", "_type" : "product", "_id" : "6", "_score" : 1.0, "_source" : { "code" : "fmp", "color" : "white", "price" : "2750", "name" : "mobile phone F", "id" : 6 } }, { "_index" : "product", "_type" : "product", "_id" : "1", "_score" : 1.0, "_source" : { "id" : 1, "name" : "mobile phone A", "price" : "2000", "code" : "amp", "color" : "golden" } } ] } }
 > Management > 开发工具
> Management > 开发工具