人气模型是什么
人气模型属于离线计算的模型,是淘宝搜索最基础的排序算法模型。人气模型会计算量化出每个商品的静态质量及受欢迎的程度的值,这个值称之为商品人气分。虽然人气模型来自淘宝搜索业务,但其实这个模型对于其他的搜索场景也有普适性,在非商品搜索场景中通过人气模型也可以计算出被索引的文档的受欢迎程度。
模型训练使用的特征
实体维度:商品/doc、品牌、商家、叶子类目、一级类目等。
时间维度:1天、3天、7天、14天、30天、时间衰减加权等。
行为维度:曝光、点击、收藏、加购、购买、评论、点赞等。
统计维度:数量、人数、频率、点击率、转化率等。
每个特征从以上4个维度中各取一到两个进行组合,再从历史数据中统计该组合特征最终的特征值。比如,商品(实体)最近1天(时间)的曝光(行为)量(统计指标);商品所在店铺(实体)最近30天(时间)的销量(行为类型+统计维度)等等。由以上方法产生的特征数量级相当于4个维度的笛卡尔积。
使用步骤
创建模型
训练模型并检查数据报告
应用到排序配置-策略管理中
【温馨提示】:单个应用最多创建5个人气模型。
创建具体流程
1.创建人气模型,控制台-->搜索算法中心-->排序配置-->人气模型,点击创建。
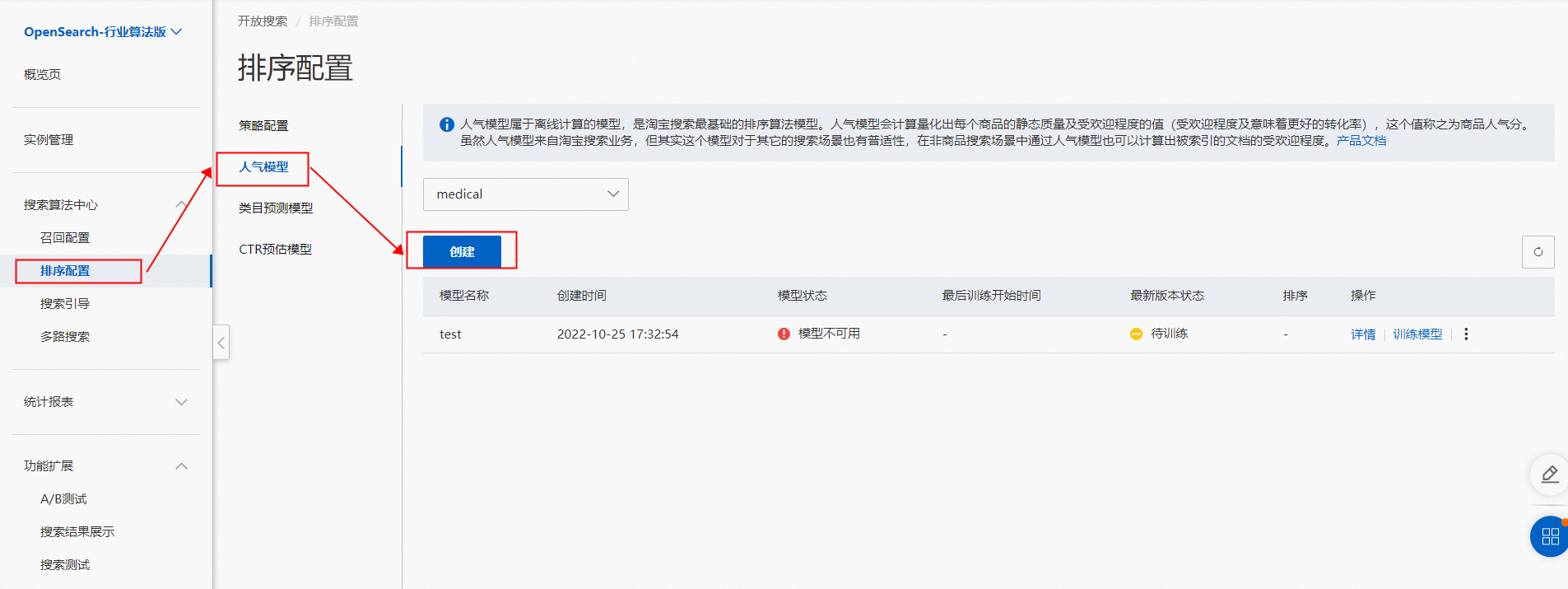
按要求填写模型名点击确定
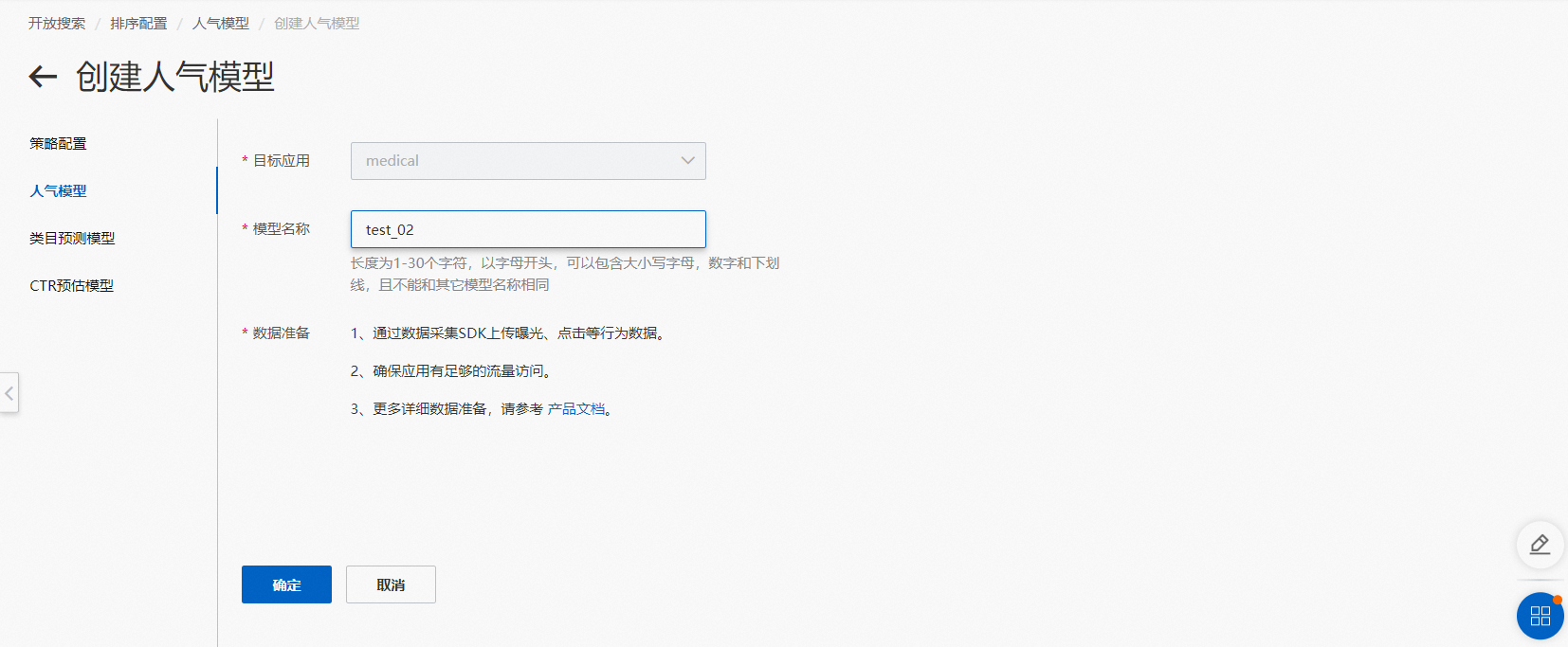
2.点击确认后,创建完成页面如下图所示。
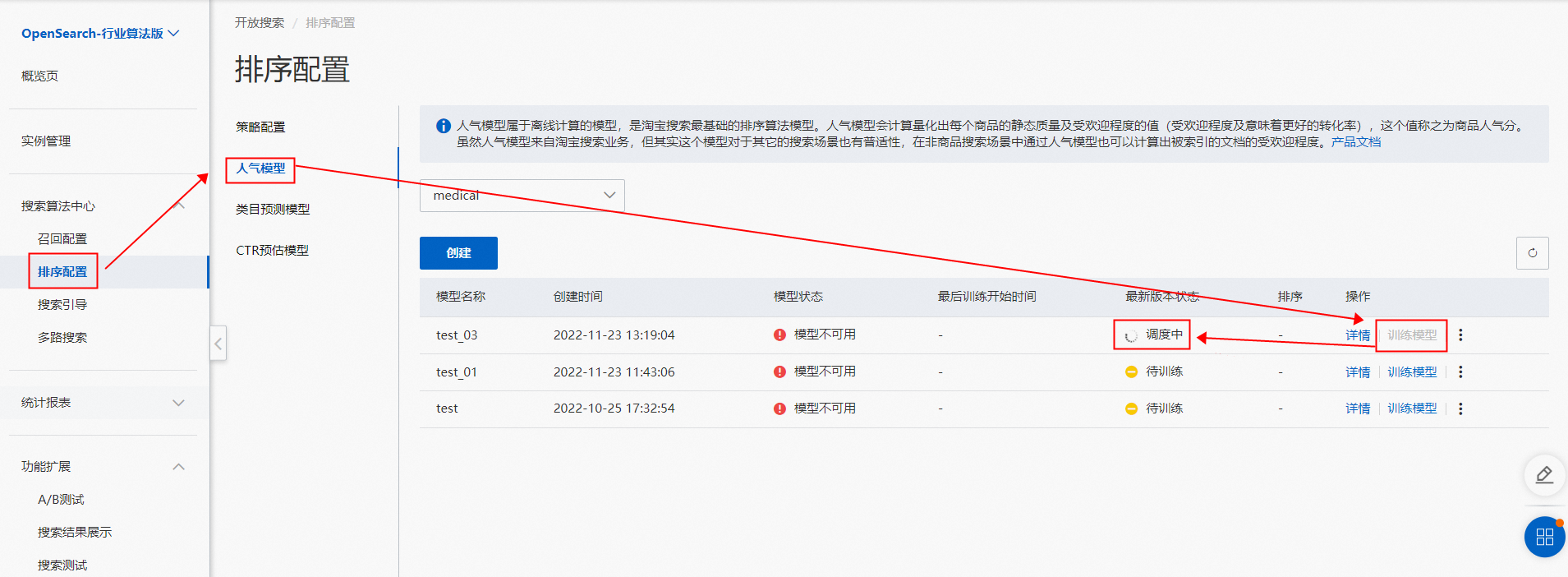
3.点击排序配置>人气模型>训练模型此时状态会被更新成调度中,等待模型训练完毕即可。
人气模型详情
人气模型详情页说明
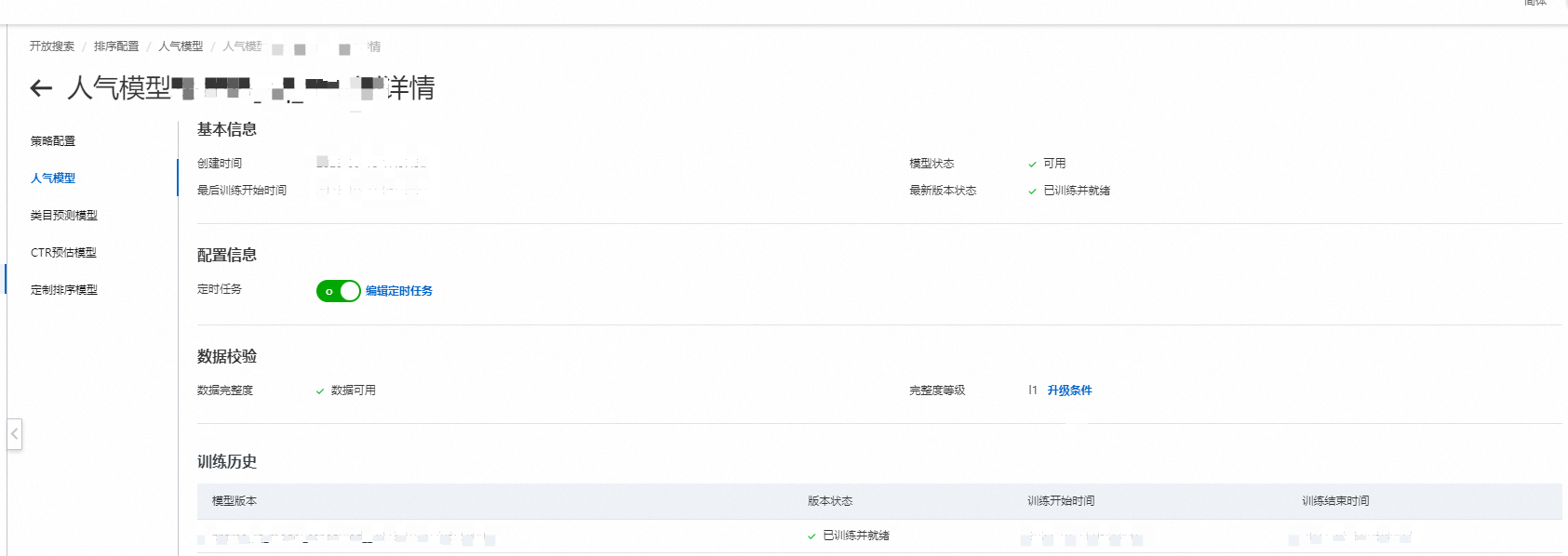
基本信息
可查看模型的创建时间、状态、最后训练开始时间以及最新版本状态。

配置信息
定时任务:默认开启并每天训练一次,也可以编辑定时任务,自定义训练周期。

数据校验
数据完整度状态包含数据可用、数据异常。

完整度报告显示当前应用的完整度等级,具体完整度等级可见:
数据完整度 | 介绍 | 晋升条件 |
l0 | 表示数据完全不可用,缺少必要的核心字段,数据量太少,后续的数据处理不能继续进行。 | l0-->l1: 最近一天ipv数大于100。 |
l1 | 表示数据的核心字段已经具备,满足模型训练条件。 | 无 |
相关API/SDK参考:算法实例
- 本页导读 (0)