通过在E-MapReduce集群中使用Spark SQL访问表格存储。对于流计算,基于通道服务,利用CDC(数据变更捕获)技术完成Spark的mini batch流式消费和计算,同时提供了at-least-once一致性语义。
前提条件
已创建EMR集群。具体操作,请参见EMR快速入门。
创建集群时请参照选择以下配置项,其余配置项按实际情况选择即可。
业务场景:自定义集群。
可选服务:Spark2、Hive、YARN、Hadoop-Common、HDFS。
元数据:内置MySQL。
同时确保打开Master节点组下的挂载公网开关,其余配置项使用默认值即可。
重要不开启挂载公网,创建后只能通过内网访问。创建后如果您需要公网访问,请前往ECS挂载EIP。
已使用阿里云账号对EMR服务授权。具体操作,请参见阿里云账号角色授权。
已创建RAM用户,并授予RAM用户管理表格存储服务的权限(AliyunOTSFullAccess)。具体操作,请参见配置RAM用户权限。
重要由于配置时需要填写访问密钥AccessKey(AK)信息来执行授权,为避免阿里云账号泄露AccessKey带来的安全风险,建议您通过RAM用户来完成授权和AccessKey的创建。
已获取AccessKey(包括AccessKey ID和AccessKey Secret),用于进行签名认证。具体操作,请参见创建AccessKey。
步骤一:在表格存储侧创建数据表和通道
创建Source表和Sink表。具体操作,请参见创建数据表。
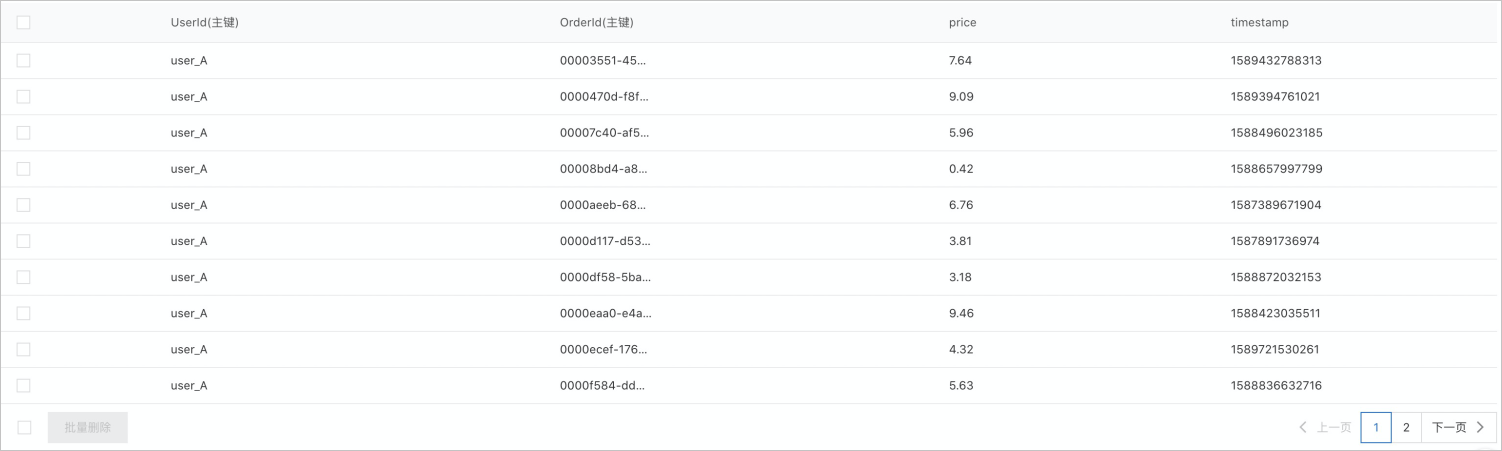
Source表名称为OrderSource,主键列分别为UserId和OrderId,属性列分别为price和timestamp,如下图所示。
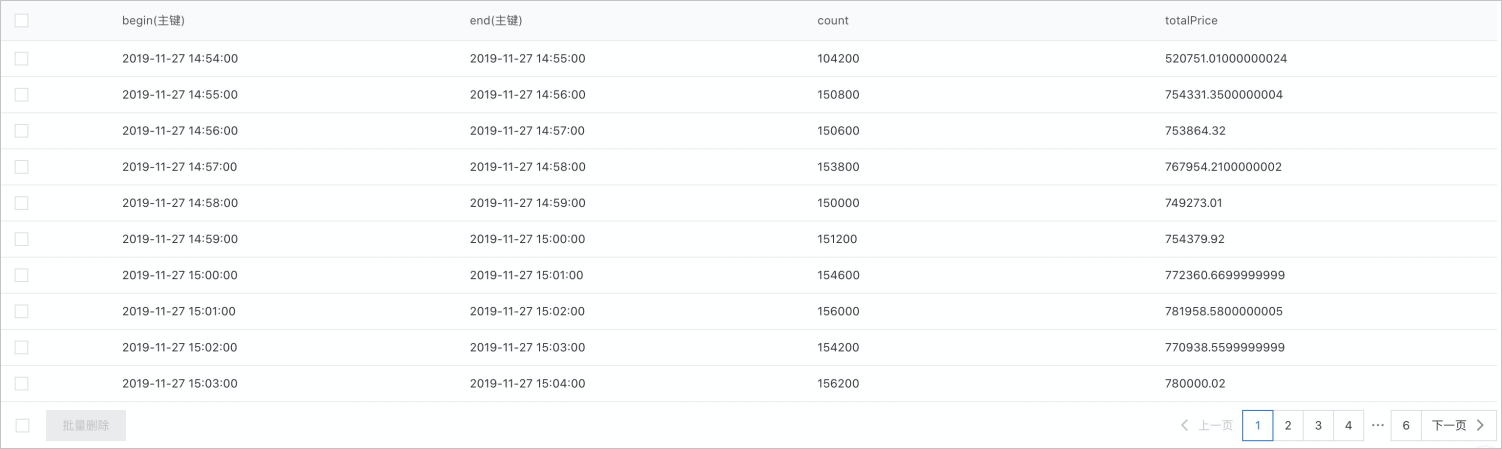
Sink表名称为OrderStreamSink,主键列分别为begin、end,属性列分别为count和totalPrice。其中begin和end的格式为“yyyy-MM-dd HH:mm:ss”,例如“2019-11-27 14:54:00”。
在Source表上创建通道。具体操作,请参见通道服务快速入门。
通道列表中会显示该通道的通道名、通道ID、通道类型等信息。其中通道ID用于后续的流式处理。

步骤二:在EMR集群侧创建Spark外表
远程登录EMR集群的Master节点。具体操作,请参见登录集群。
执行如下命令启动Spark SQL CLI,用于Spark表创建和后续的SQL操作。
spark-sql --jars /opt/apps/SPARK-EXTENSION/spark-extension-current/spark2-emrsdk/*创建Source外表order_source(对应表格存储的OrderSource表)。
参数
参数
说明
endpoint
表格存储实例访问地址,EMR集群中使用VPC地址。
access.key.id
阿里云账号或者RAM用户的AccessKey ID和AccessKey Secret。获取方式请参见创建AccessKey。
access.key.secret
instance.name
表格存储实例名称。
table.name
表格存储的数据表名称。
catalog
表格存储数据表的Schema定义。
示例
DROP TABLE IF EXISTS order_source; CREATE TABLE order_source USING tablestore OPTIONS(endpoint="http://vehicle-test.cn-hangzhou.vpc.tablestore.aliyuncs.com", access.key.id="", access.key.secret="", instance.name="vehicle-test", table.name="OrderSource", catalog='{"columns": {"UserId": {"type": "string"}, "OrderId": {"type": "string"},"price": {"type": "double"}, "timestamp": {"type": "long"}}}' );
步骤三:实时流计算
实时流计算将实时统计一个窗口周期时间内的数据,并将聚合结果写回表格存储的数据表中。
创建流计算的Sink外表order_stream_sink(对应表格存储的OrderStreamSink表)。
创建Sink外表与创建Source外表的参数设置中只有catalog字段有差别,其他参数设置均相同。
DROP TABLE IF EXISTS order_stream_sink; CREATE TABLE order_stream_sink USING tablestore OPTIONS(endpoint="http://vehicle-test.cn-hangzhou.vpc.tablestore.aliyuncs.com", access.key.id="", access.key.secret="", instance.name="vehicle-test", table.name="OrderStreamSink", catalog='{"columns": {"begin": {"type": "string"},"end": {"type": "string"}, "count": {"type": "long"}, "totalPrice": {"type": "double"}}}' );在Source外表order_source上创建视图order_source_stream_view。
创建视图时需要设置Source表上通道的通道ID。
CREATE SCAN order_source_stream_view ON order_source USING STREAM OPTIONS(tunnel.id="4987845a-1321-4d36-9f4e-73d6db63bf0f", maxoffsetsperchannel="10000");在视图上运行Stream SQL作业进行实时聚合,且将聚合结果实时写回表格存储的OrderStreamSink表。
CREATE STREAM job1 OPTIONS(checkpointLocation='/tmp/spark/cp/job1', outputMode='update') INSERT INTO order_stream_sink SELECT CAST(window.start AS String) AS begin, CAST(window.end AS String) AS end, count(*) AS count, CAST(sum(price) AS Double) AS totalPrice FROM order_source_stream_view GROUP BY window(to_timestamp(timestamp / 1000), "30 seconds"); --按30s粒度进行聚合。运行Stream SQL后,可以实时得到聚合结果,聚合结果样例如下图所示,聚合结果保存在OrderStreamSink表中。