Delta Lake 快速入门
Delta Lake快速入门概述了使用Delta Lake的基础知识。此快速入门演示如何生成管道,以便将JSON数据读入Delta表、修改表、读取表、显示表历史记录,以及优化表。
有关演示这些功能的Databricks笔记本,请参阅入门笔记本。
创建表
若要创建一个delta表,可以使用现有的Apache Spark SQL代码,也可以将parquet、csv、json等数据格式转换为delta。
对于所有文件类型,您将文件读入DataFrame并将格式转为delta:
Python
%pyspark
events = spark.read.json("/xz/events_data.json")
events.write.format("delta").save("/xz/delta/events")
spark.sql("CREATE TABLE events USING DELTA LOCATION '/xz/delta/events/'")
SQL
%sql
CREATE TABLE events
USING delta
AS SELECT *
FROM json.`/data/events/`这些操作使用从JSON数据推断出的架构创建一个新的非托管表。有关创建新Delta表时可用的全套选项的信息,请参见创建表和写入表。
如果源文件是Parquet格式,则可以使用SQL Convert to Delta语句就地转换文件,以创建非托管表
SQL
%sql
CONVERT TO DELTA parquet.`/mnt/delta/events`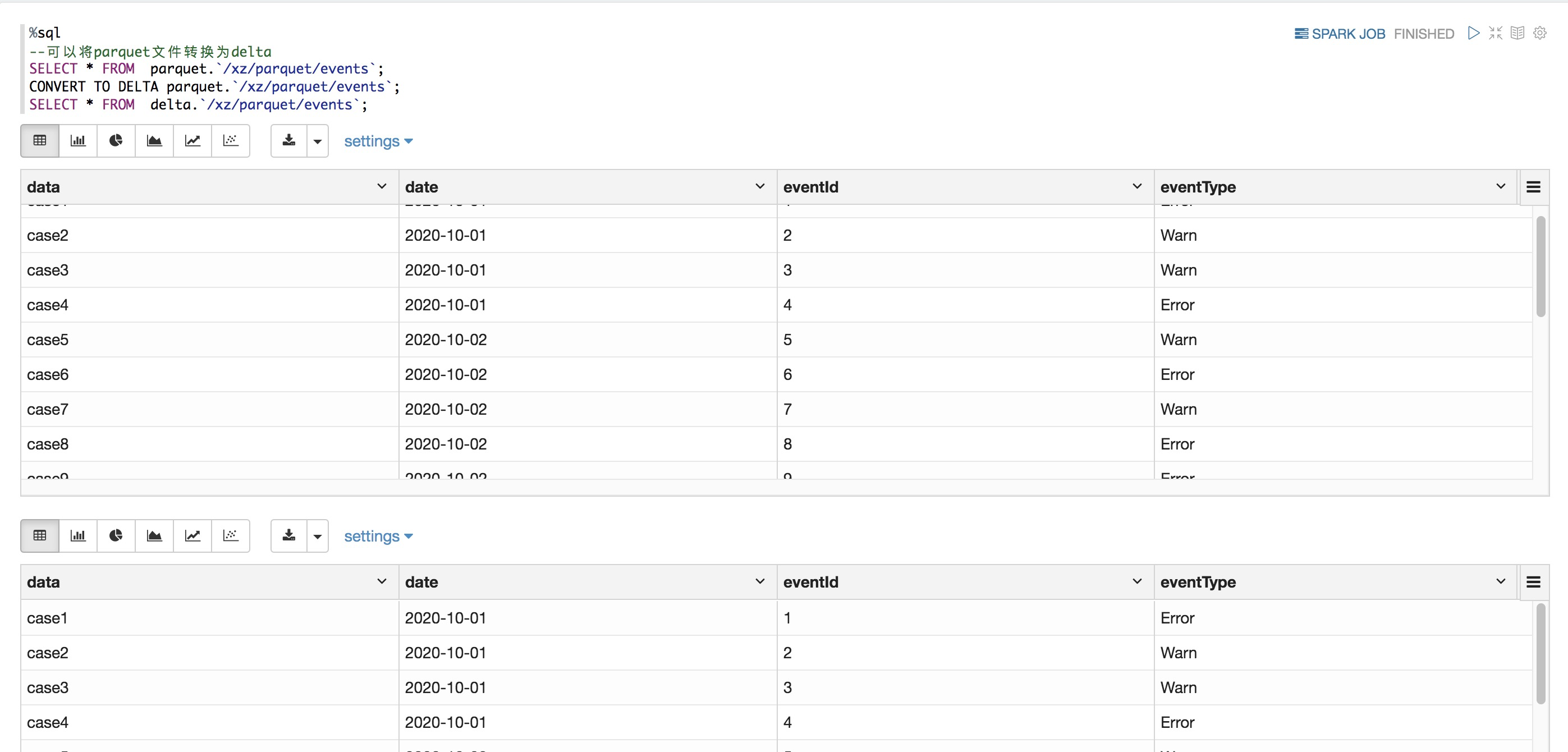
分区数据
要加快包含涉及分区列的谓词查询,可以对数据进行分区。
Python
%pyspark
events = spark.read.json("/databricks-datasets/structured-streaming/events/")
events.write.partitionBy("date").format("delta").save("/mnt/delta/events")
spark.sql("CREATE TABLE events USING DELTA LOCATION '/mnt/delta/events/'")SQL
%sql
CREATE TABLE events (
date DATE,
eventId STRING,
eventType STRING,
data STRING)
USING delta
PARTITIONED BY (date)修改表格
Delta Lake支持一组丰富的操作来修改表。
对流写入表
您可以使用结构化流式处理将数据写入Delta表。即使有其他流或批查询同时运行表,Delta Lake事务日志也可以保证一次性处理。默认情况下,流在附加模式下运行,这会将新记录添加到表中。
Python
%pyspark from pyspark.sql.types import * inputPath = "/databricks-datasets/structured-streaming/events/" jsonSchema = StructType([ StructField("time", TimestampType(), True), StructField("action", StringType(), True) ]) eventsDF = ( spark .readStream .schema(jsonSchema) # Set the schema of the JSON data .option("maxFilesPerTrigger", 1) # Treat a sequence of files as a stream by picking one file at a time .json(inputPath) ) (eventsDF.writeStream .outputMode("append") .option("checkpointLocation", "/mnt/delta/events/_checkpoints/etl-from-json") .table("events") )有关Delta Lake与结构化流式处理集成的更多信息,请参阅表流式处理读写。
批处理更新
要将一组更新和插入合并到现有表中,请使用merge-into语句。例如,以下语句获取更新流并将其合并到表中。当已经存在具有相同事件ID的事件时,Delta Lake将使用给定的表达式更新数据列。如果没有匹配事件时,Delta Lake将添加一个新行。
SQL
%sql MERGE INTO events USING updates ON events.eventId = updates.eventId WHEN MATCHED THEN UPDATE SET events.data = updates.data WHEN NOT MATCHED THEN INSERT (date, eventId, data) VALUES (date, eventId, data)执行INSERT时(例如,当现有数据集中没有匹配的行时),必须为表中的每一列指定一个值。但是,您不需要更新所有值。
读一个表
在这个部分:
显示表格历史记录
查询表的早期版本(时间行程)
您可以通过在DBFS("/mnt/delta/events")或表名("event")上指定路径来访问Delta表中的数据:
Scala
%spark SELECT * FROM delta.`/mnt/delta/events`或
%spark val events = spark.table("events")SQL
%sql SELECT * FROM delta.`/mnt/delta/events`或
%sql SELECT * FROM events
显示表的历史记录
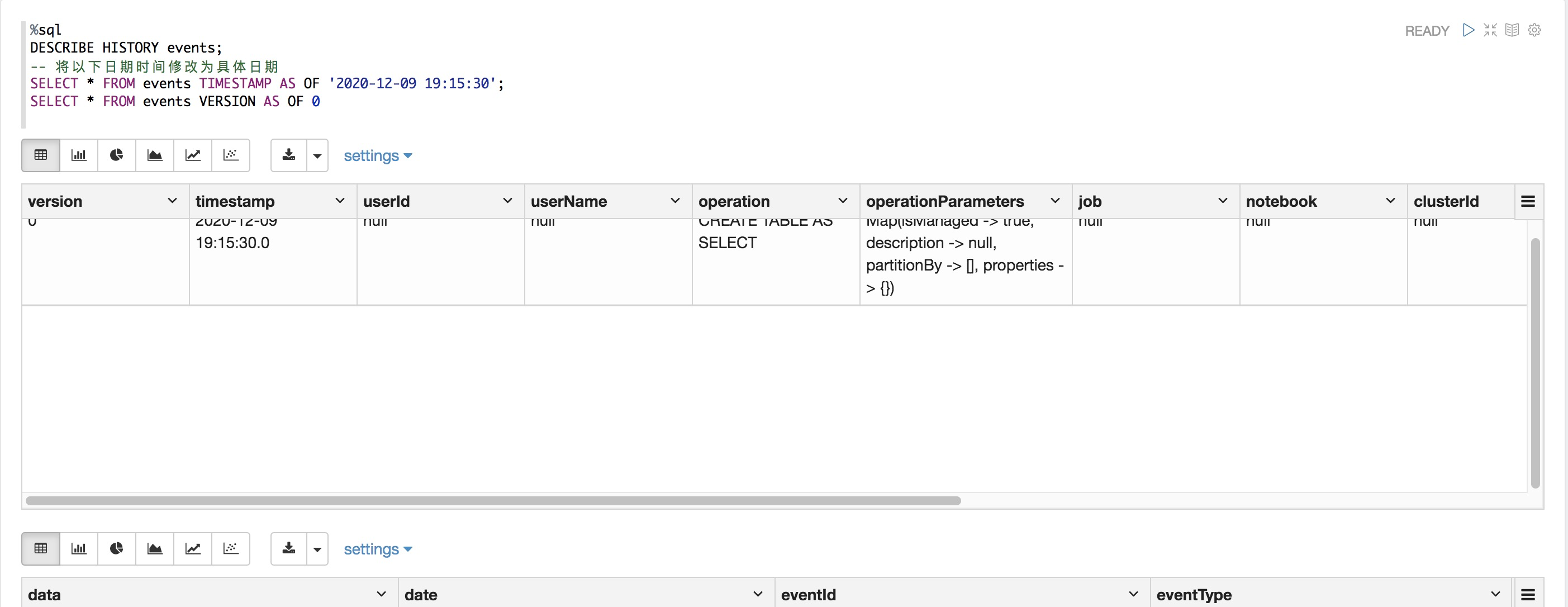
使用DESCRIBE HISTORY语句,查看表的历史记录。该语句提供每次为写入表出处信息,包括表版本、操作、用户等。检索增量表历史记录
查询表的早期版本(按时间顺序查询)
使用Delta Lake时间行程,您可以查询Delta表的旧快照。
对于timestamp_string,只接受日期或时间戳字符串。例如,“2019-01-01”和“2019-01-01'T'00:00:00.000Z”。
若要查询较早版本的表,请在语句中指定版本或时间戳SELECT。例如,若要从上述历史记录中查询版本0,请使用
SQL
%sql SELECT * FROM events VERSION AS OF 0or
%sql SELECT * FROM events VERSION AS OF 0注意因为版本1的时间戳为'2019-01-29 00:38:10',要查询版本0,您可以使用范围为'2019-01-29 00:37:58'到'2019-01-29 00:38:09'的任何时间戳。
使用DataFrameReader选项,您可以通过Delta table中一个固定的特定版本表创建DataFrame。
Python
%pyspark df1 = spark.read.format("delta").option("timestampAsOf", timestamp_string).load("/mnt/delta/events") df2 = spark.read.format("delta").option("versionAsOf", version).load("/mnt/delta/events")有关详细信息,请参阅查询表的旧快照(按时间顺序查询)。
优化表
对表执行多次更改后,可能会有很多小文件。为了提高读取查询的速度,可以使用OPTIMIZE将小文件折叠为较大的文件:
SQL
%sql OPTIMIZE delta.`/mnt/delta/events`或
%sql OPTIMIZE eventsZ-order排序
为了进一步提高读取性能,可以通过Z-Ordering在同一组文件中共同定位相关信息。Delta Lake数据跳过算法会自动使用这种共区域性来显著减少需要读取的数据量。对于Z-Order数据,您可以在子句中指定要排序的列。例如:要通过共同定位,请运行:ZORDER BY Clause
SQL
%sql OPTIMIZE events ZORDER BY (eventType)清理快照
Delta Lake为读取提供快照隔离,这意味着即使其他用户或作业正在查询表时,也可以安全地运行OPTIMIZE。但是最终,您应该清理旧快照。您可以通过运行以下VACUUM命令来执行此操作
SQL
%sql VACUUM events您可以使用 RETAIN<N>HOURS 选项来控制最新快照的保留时间:
SQL
%sql VACUUM events RETAIN 24 HOURS有关VACUUM有效使用的详细信息,请参阅删除不再由Delta表引用的文件。
有关本文章详细信息,请参考官方文档:Delta快速入门
- 本页导读 (0)