
CDH(Cloudera's Distribution, including Apache Hadoop)提供Hadoop组件的安装、运维、监控等功能,您可以使用CDH6(表示CDH 6.X 版本)管理您的Hadoop集群。本文介绍如何将CDH6与LindormDFS集成,来替换底层HDFS存储。您可以基于CDH6和LindormDFS构建云原生存储计算分离的开源大数据系统。
前提条件
一、配置LDFS为默认的存储引擎
开通LDFS,具体步骤请参见开通指南。
配置相关链接。
登入CDH6系统主页,选择配置>高级配置代码段,进入高级配置代码段页面。
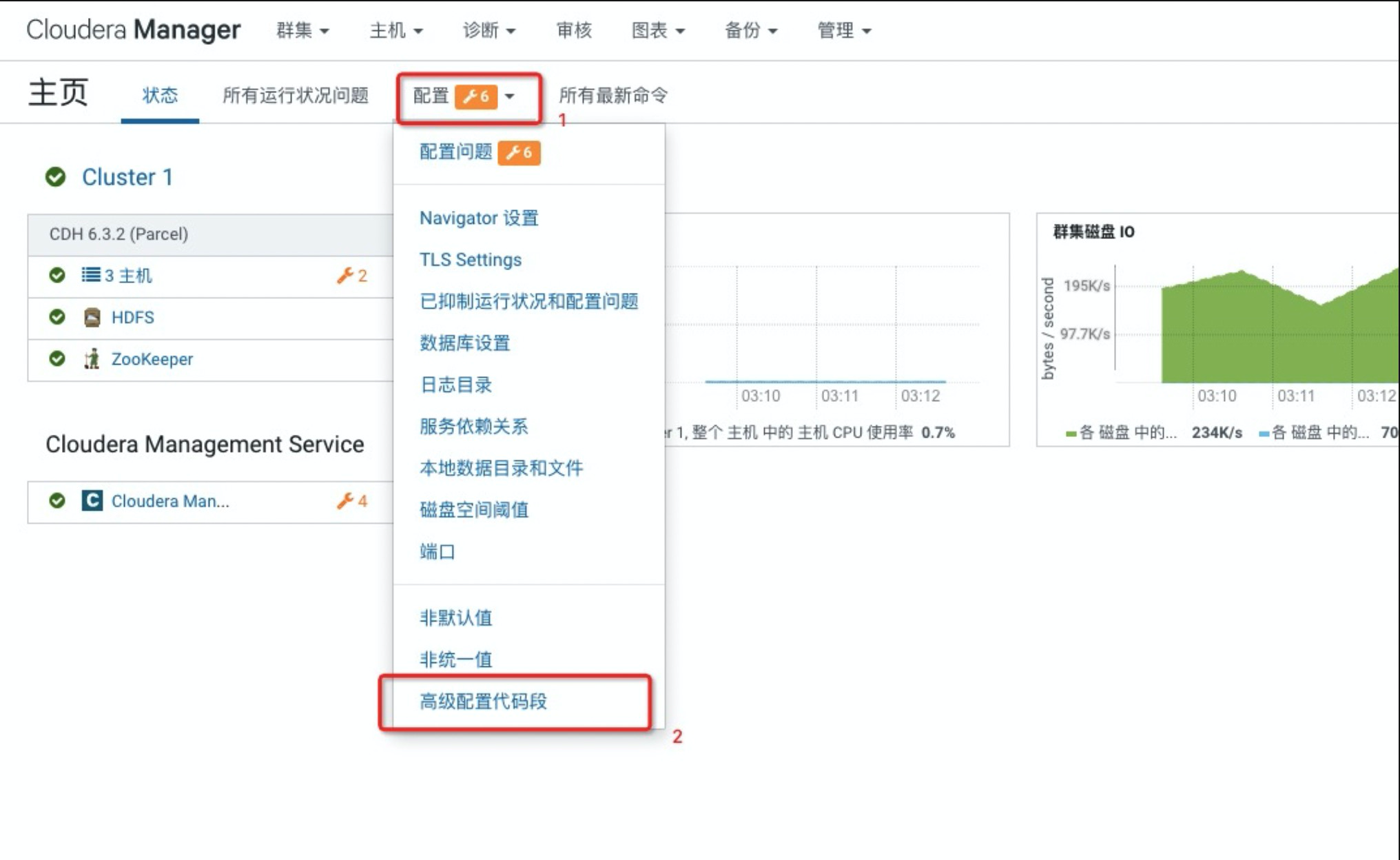
原HDFS采用HA模式(HDFS NameNode主备模式)部署,如果原HDFS非HA模式部署,请将其初始化为HA模式。
在最上面的搜索框中搜索hdfs-site.xml。
在hdfs-site.xml的HDFS客户端高级配置代码段(安全阀)区域中,添加如下LDFS配置项,如下:
名称
值
说明
是否必配
dfs.client.failover.proxy.provider.{实例ID}
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
主备切换策略配置
是
dfs.ha.namenodes.${实例ID}
nn1,nn2
HA模式下主备NameNode的服务ID名称
是
dfs.namenode.rpc-address.${实例ID}.nn1
${实例ID}-master1-001.lindorm.rds.aliyuncs.com:8020
NameNode第一个节点RPC通信地址
是
dfs.namenode.rpc-address.${实例ID}.nn2
${实例ID}-master2-001.lindorm.rds.aliyuncs.com:8020
NameNode第二个节点RPC通信地址
是
dfs.nameservices
${实例ID},nameservice1
nameservice1为原来的HDFS的服务名称
是
单击下图的按钮可以添加配置。
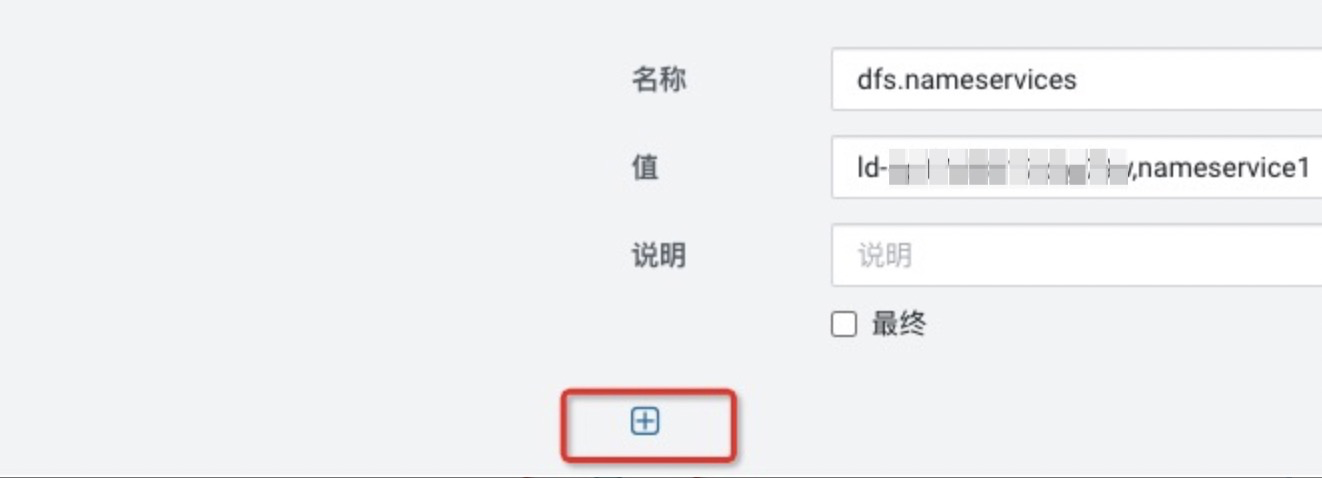
 说明
说明其中${实例ID},需要根据实际情况进行修改。
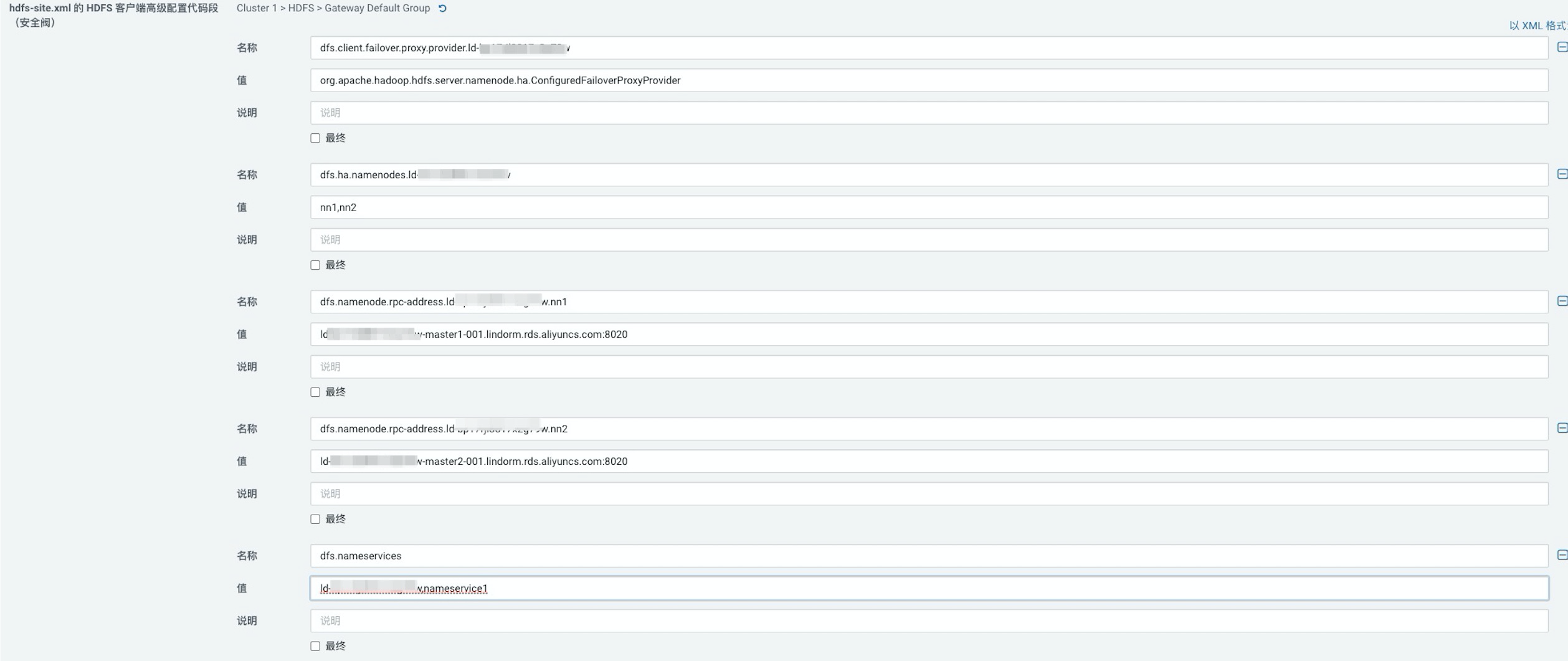
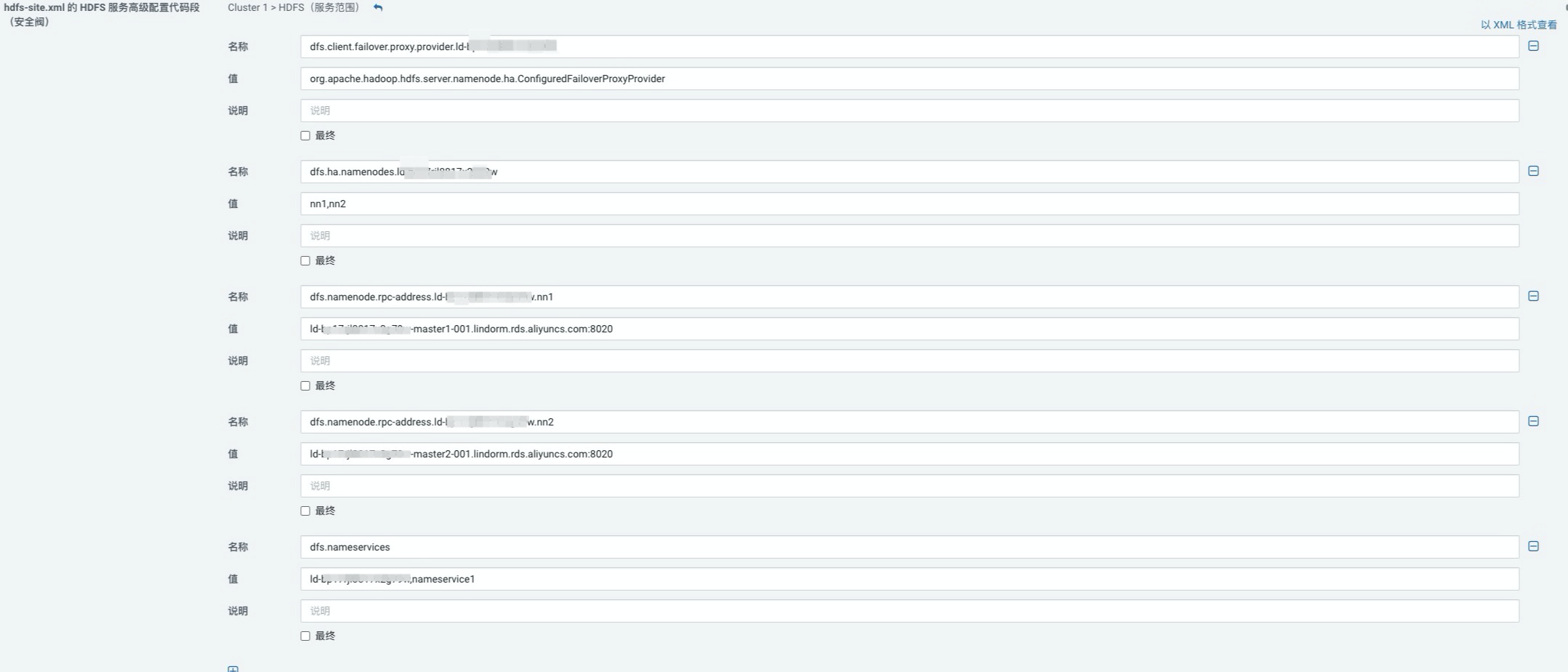
在hdfs-site.xml的HDFS服务高级配置代码段(安全阀)区域中,添加如下LDFS配置项,如下:
名称
值
说明
是否必配
dfs.client.failover.proxy.provider.{实例ID}
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
是
dfs.ha.namenodes.${实例ID}
nn1,nn2
HA模式下主备NameNode的服务ID名称
是
dfs.namenode.rpc-address.${实例ID}.nn1
${实例ID}-master1-001.lindorm.rds.aliyuncs.com:8020
是
dfs.namenode.rpc-address.${实例ID}.nn2
${实例ID}-master2-001.lindorm.rds.aliyuncs.com:8020
是
dfs.nameservices
${实例ID},nameservice1
nameservice1为原来的hdfs的服务名称
是
单击下图的按钮可以添加配置。
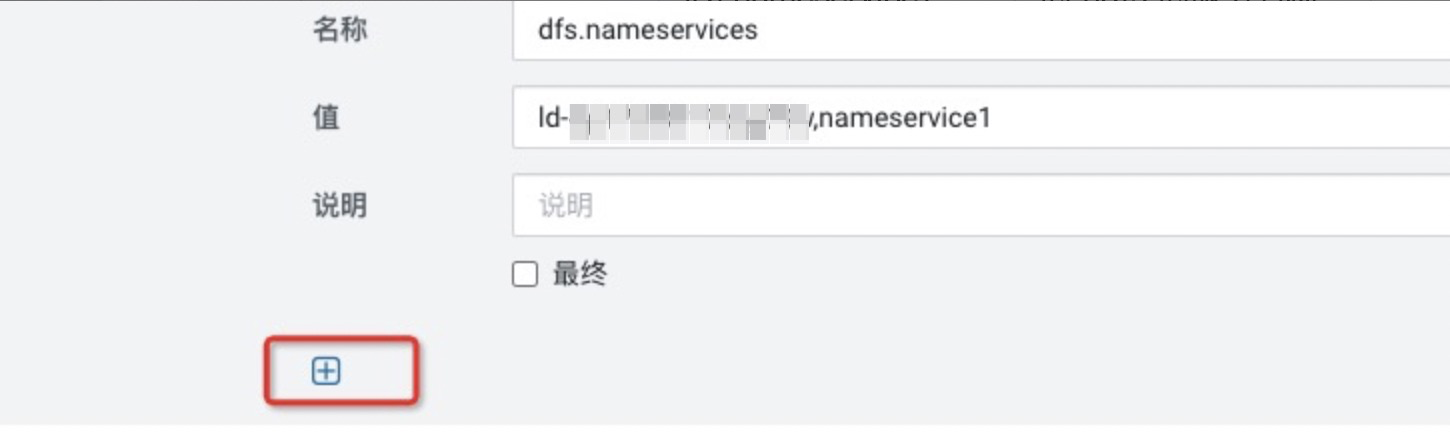
 说明
说明其中${实例ID},需要根据实际情况进行修改。
在搜索框中搜索 core-site.xml 。
在 core-site.xml 的群集范围高级配置代码段(安全阀)区域中,添加 fs.defaultFS,其值:hdfs://${实例ID} ,含义是将LDFS设置为默认的存储引擎。
单击保存更改。
返回CDH6系统主页,找到HDFS,单击图标进入HDFS控制台,然后再单击操作>部署客户端配置。

验证CDH6集群是否默认访问LDFS。
在CDH6集群中的任意一个节点上执行如下指令。
$ hadoop fs -ls /执行结果如下,表示链接配置成功。

二 、安装Yarn服务
修改Yarn的安装脚本。
登入您准备作为ResourceManager(Yarn服务中资源的管控节点)。
执行如下的指令修改安装脚本。
# sudo su - root@cdhlindorm001 /opt/cloudera/cm-agent/service $ vim /opt/cloudera/cm-agent/service/yarn/yarn.sh # 找到 DEFAULT_FS , 并在其下面添加如下配置信息。 DEFAULT_FS="$3" DEFAULT_FS="hdfs://{实例ID} # 其中${实例ID},需要根据实际情况进行修改。说明该脚本是Yarn 在安装的时候,用于配置环境的脚本。
登录CDH6管理系统,单击集群名称右边的
,然后单击添加服务,进入安装向导界面。选择YRAN服务,单击继续,根据安装指南配置YARN服务,配置都可以按照默认配置。
等服务安装完成之后,需要修改mapred-site.xml配置。
登入 CDH6 系统主页,选择配置>高级配置代码段,进入高级配置代码段页面。
在最上面的搜索框中搜索mapred-site.xml。
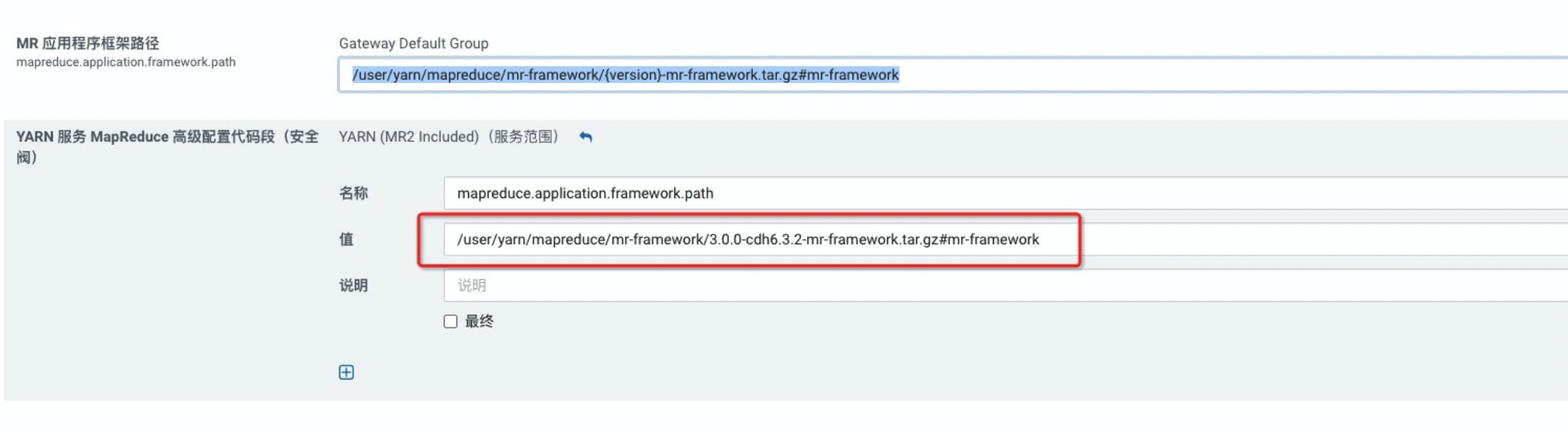
在YARN 服务 MapReduce 高级配置代码段(安全阀)中,添加如下配置项。
配置项mapreduce.application.framework.path,其值:/user/yarn/mapreduce/mr-framework/{version}-mr- framework.tar.gz#mr-framework
单击保存更改。
配置Yarn可以分配的内存容量(因为在我们完成Spark安装之后需要通过Yarn启动程序)。
返回 CDH6 系统主页,找到YARN,单击进入Yarn控制台。
找到配置,单击进入。
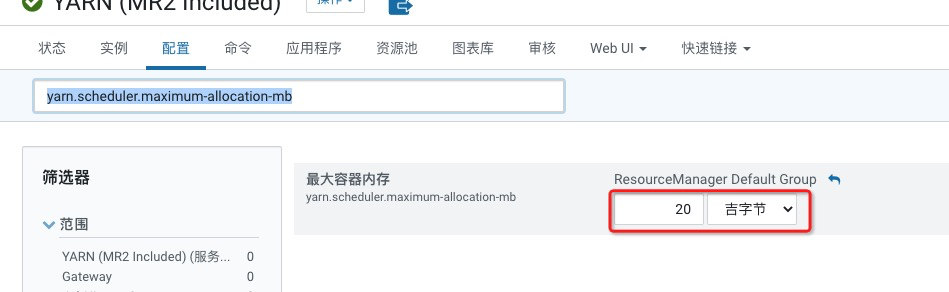
在最上面的搜索框中输入yarn.scheduler.maximum-allocation-mb,将其值设置为20 G(该值根据您实际的情况配置)。
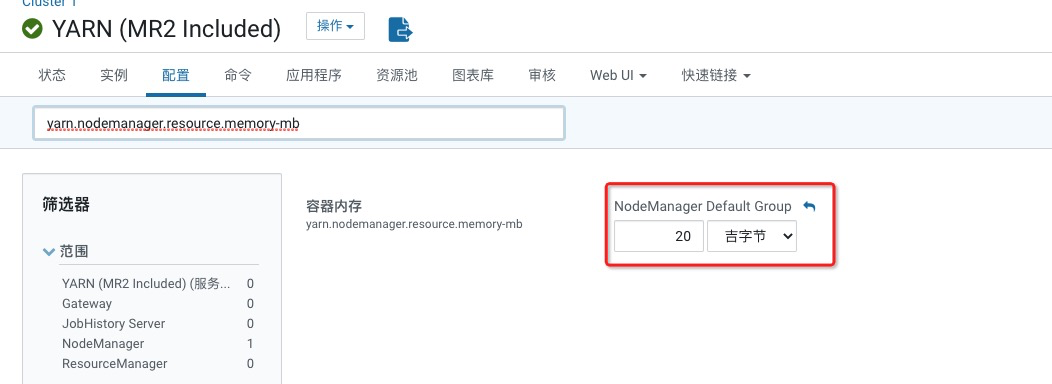
在最上面的搜索框中输入yarn.nodemanager.resource.memory-mb,将其值设置为20 G(该值根据您实际的情况配置)。
单击保存更改。
部署新配置并重启服务。
返回CDH6管理系统界面,找到YARN,单击重新部署图标,进行重新部署。
在过期配置页面,单击重启过时服务。
在重启过时服务页面,选择需要重启的服务,单击立即重启。
等待服务全部重启完成,并重新部署客户端配置后,单击完成。
验证hive服务是否启动成功。
使用CDH6 Hadoop中自带的测试包hadoop-mapreduce-examples-3.0.0-cdh6.3.2.jar (版本号以客户自带的版本为准)进行测试。在CDH6中,该测试包在/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/jars 下。
登入CDH6任意一台机器,执行以下命令,在/tmp/randomtextwriter目录下生成128M大小的文件。
yarn jar /opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/jars/hadoop-mapreduce-examples-3.0.0-cdh6.3.2.jar randomtextwriter -D mapreduce.randomtextwriter.totalbytes=134217728 -D mapreduce.job.maps=4 -D mapreduce.job.reduces=4 /tmp/randomtextwriter其中hadoop-mapreduce-examples-3.1.1.3.1.4.0-315.jar为CDH6中的测试包,请根据实际情况修改。
检查任务是否已经提交到Yarn上执行。
在 CDH6任意一台机器上,执行以下命令。
$ yarn application -list如果执行结果如下,表示YARN正常运行。
检查文件是否正常生成。
在CDH6任意一台机器上,执行以下命令。
$ hadoop fs -ls /tmp/randomtextwriter如果执行结果如下,正常运行。
 ,然后单击添加服务,进入安装向导界面。
,然后单击添加服务,进入安装向导界面。




三、安装HIVE服务
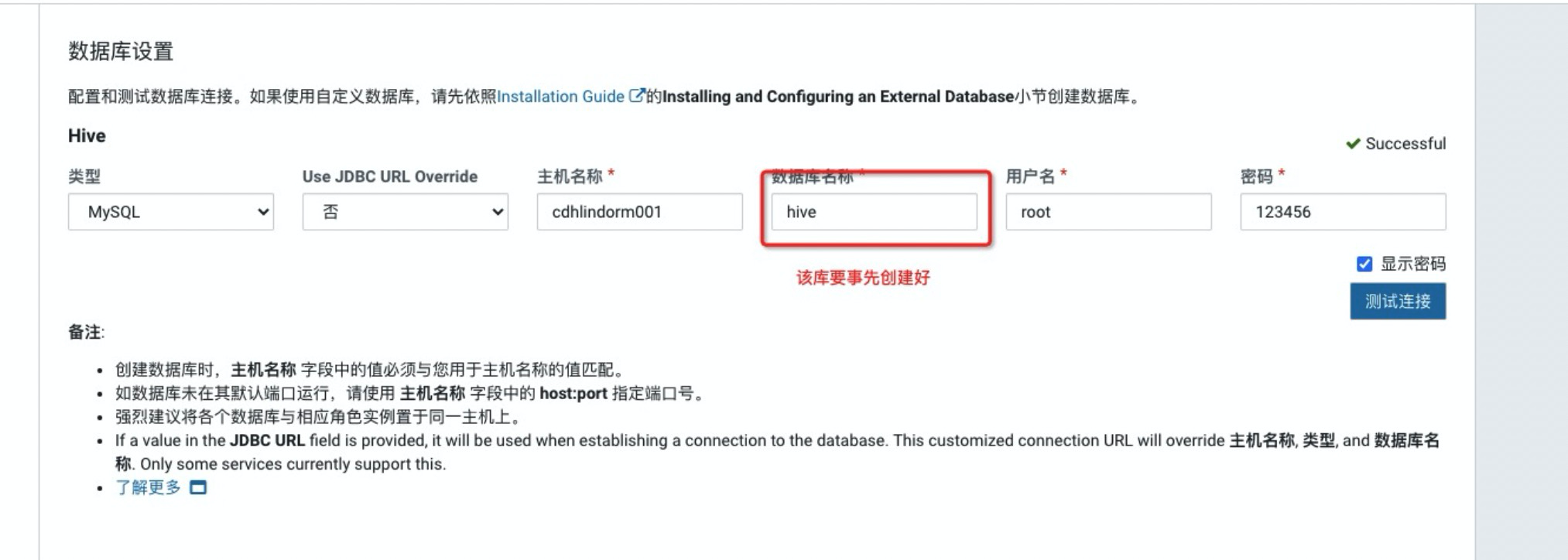
安装MySQL数据库,并创建用来存储hive元数据信息的数据库。
登入CDH6任意的一台机器,执行如下指令,进行安装。
# 切换到 root sudo su - # 下载 MySQL的rpm 源 root@cdhlindorm001 ~/tool $ wget http://repo.mysql.com/mysql-community-release-el7-5.noarch.rpm #安装 MySQL server和MySQL客户端 root@cdhlindorm001 ~/tool $ yum install mysql-server mysql -y启动MySQL服务,并且创建用户,设置用户的权限。
执行如下指令进行操作。
# 启动 MySQL服务 root@cdhlindorm001 ~/tool $ systemctl start mysqld.service # 登入MySQL终端,创建用户,并且设置权限 root@cdhlindorm001 ~/tool $ mysql Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 2 Server version: 5.6.50 MySQL Community Server (GPL) Copyright (c) 2000, 2020, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql> CREATE USER 'hive'@'%' IDENTIFIED BY '123456'; Query OK, 0 rows affected (0.00 sec) mysql> create DATABASE hive; Query OK, 1 row affected (0.00 sec) mysql> use mysql; Query OK, 0 rows affected (0.00 sec) mysql> delete from user; Query OK, 9 rows affected (0.00 sec) mysql> grant all privileges on *.* to 'root'@'%' identified by '123456' with grant option; # 刷新权限 mysql> flush privileges; Query OK, 0 rows affected (0.01 sec)验证MySQL是否配置成功。
# 登入成功,配置完成 root@cdhlindorm001 ~/tool $ mysql -uroot -p Warning: Using a password on the command line interface can be insecure. Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 10 Server version: 5.6.50 MySQL Community Server (GPL) Copyright (c) 2000, 2020, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
登录CDH6管理系统,单击集群名称右边的
,然后单击添加服务,进入安装向导界面。选择 HIVE 服务,单击继续,根据安装指南配置HIVE服务,根据向导配置对应的参数。
配置数据库信息。
开始安装,并且等待安装完成。
验证是否启动成功。
登入CDH6任意一台机器上,执行以下命令。
# 登入 hive 客户端 [root@cdhlindorm001 ~]# hive WARNING: Use "yarn jar" to launch YARN applications. SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/jars/log4j-slf4j-impl-2.8.2.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/jars/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory] Logging initialized using configuration in jar:file:/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/jars/hive-common-2.1.1-cdh6.3.2.jar!/hive-log4j2.properties Async: false WARNING: Hive CLI is deprecated and migration to Beeline is recommended. hive> create table foo (id int, name string); OK Time taken: 1.409 seconds hive> insert into table foo select * from (select 12,"xyz")a; Query ID = root_20201126162112_59e6a5fc-99c2-45a4-bf84-73c16c39de8a Total jobs = 3 Launching Job 1 out of 3 Number of reduce tasks is set to 0 since there's no reduce operator 20/11/26 16:21:12 INFO client.RMProxy: Connecting to ResourceManager at cdhlindorm001/192.168.0.218:8032 20/11/26 16:21:13 INFO client.RMProxy: Connecting to ResourceManager at cdhlindorm001/192.168.0.218:8032 Starting Job = job_1606364936355_0003, Tracking URL = http://cdhlindorm001:8088/proxy/application_1606364936355_0003/ Kill Command = /opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/hadoop/bin/hadoop job -kill job_1606364936355_0003 Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0 2020-11-26 16:21:20,758 Stage-1 map = 0%, reduce = 0% 2020-11-26 16:21:25,864 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.17 sec MapReduce Total cumulative CPU time: 1 seconds 170 msec Ended Job = job_1606364936355_0003 Stage-4 is selected by condition resolver. Stage-3 is filtered out by condition resolver. Stage-5 is filtered out by condition resolver. Moving data to directory hdfs://ld-xxxxxxxxxxx/user/hive/warehouse/foo/.hive-staging_hive_2020-11-26_16-21-12_133_7009525880995260840-1/-ext-10000 Loading data to table default.foo MapReduce Jobs Launched: Stage-Stage-1: Map: 1 Cumulative CPU: 1.17 sec HDFS Read: 5011 HDFS Write: 74 HDFS EC Read: 0 SUCCESS Total MapReduce CPU Time Spent: 1 seconds 170 msec OK Time taken: 15.429 seconds通过Hive的终端,查询写入的数据,如果正确查询出数据,表示Hive安装完成。
hive> select * from foo; OK 12 xyz Time taken: 0.091 seconds, Fetched: 1 row(s) hive>查看文件是否正常生成 。
通过下面的执行,查询文件信息。
[root@cdhlindorm001 ~]# hadoop fs -ls /user/hive/warehouse/foo如果结果如下图,表示Hive对接LDFS正常。


四 、 安装HBASE服务
登录CDH6管理系统,单击集群名称右边的
,然后单击添加服务,进入安装向导界面。选择HBase服务,单击继续,根据安装指南配置HBase服务,配置都可以按照默认配置。
开始安装。
出现下面的截图,表示安装成功,单击完成。
修改 hbase-site.xml 配置。
在CDH6 系统主页,选择配置>高级配置代码段,进入高级配置代码段页面。
在最上面的搜索框中搜索hbase-site.xml。
在hbase-site.xml 的HBase服务高级配置代码段(安全阀)和 hbase-site.xml 的 HBase 客户端高级配置代码段(安全阀)中,都要添加如下配置项。
配置项hbase.rootdir,其值:/hbase。
配置项hbase.unsafe.stream.capability.enforce,其值:false。
单击保存更改。
部署新配置并启动服务。
返回CDH6管理系统界面,找到YARN,单击重新部署图标,进行重新部署。
在过期配置页面,单击重启过时服务。
在重启过时服务页面,选择需要重启的服务,单击立即重启。
等待服务全部重启完成,并重新部署客户端配置后,单击完成。
验证 HBase 是否运行正常,登入CDH6任意一台机器执行下面的命令。
执行以下命令进入hbase Shell命令界面。
[root@cdhlindorm001 ~]# hbase shell HBase Shell Use "help" to get list of supported commands. Use "exit" to quit this interactive shell. For Reference, please visit: http://hbase.apache.org/2.0/book.html#shell Version 2.1.0-cdh6.3.2, rUnknown, Fri Nov 8 05:44:07 PST 2019 Took 0.0009 seconds hbase(main):001:0>在HBase中创建测试表,并且写入一些数据。
[root@cdhlindorm001 ~]# hbase shell HBase Shell Use "help" to get list of supported commands. Use "exit" to quit this interactive shell. For Reference, please visit: http://hbase.apache.org/2.0/book.html#shell Version 2.1.0-cdh6.3.2, rUnknown, Fri Nov 8 05:44:07 PST 2019 Took 0.0009 seconds hbase(main):001:0> create 'hbase_test','info' Created table hbase_test Took 1.0815 seconds => Hbase::Table - hbase_test hbase(main):002:0> put 'hbase_test','1', 'info:name' ,'Sariel' Took 0.1233 seconds hbase(main):003:0> put 'hbase_test','1', 'info:age' ,'22' Took 0.0089 seconds hbase(main):004:0> put 'hbase_test','1', 'info:industry' ,'IT' Took 0.0115 seconds执行如下指令查询刚刚写入的数据,验证HBase是否正常。
hbase(main): 005:0> scan 'hbase_test'如果执行结果如下,表示Hbase 服务正常。
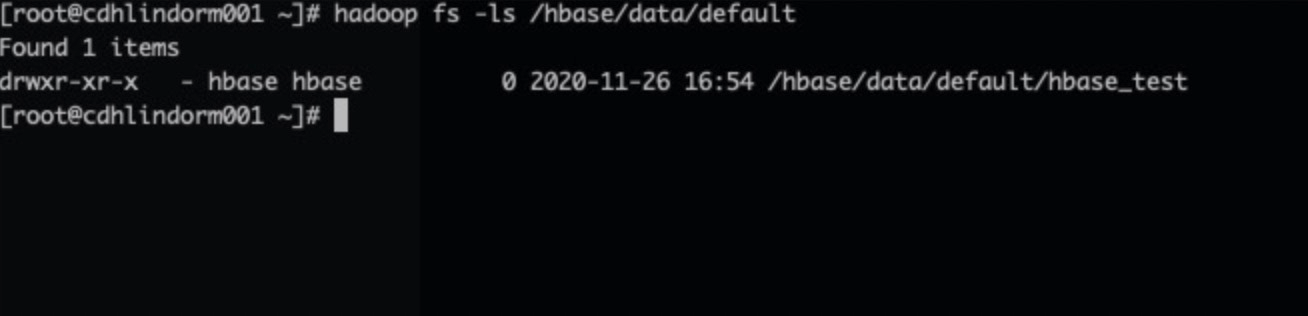
执行以下命令查看LDFS的/hbase/data/default 路径,如果/hbase/data/default 路径下有hbase_test目录,则证明配置成功。
# hadoop fs -ls /hbase/data/default
重要如果用户在部署中发现beeline或者hiveserver2无法正常服务,报不能被代理错误,这是需要开启LDFS的代理模式, 具体的方式请提交工单或者联系值班技术支持协助完成。




五 、安装Spark服务
登录CDH6管理系统,单击集群名称右边的
,然后单击添加服务,进入安装向导界面。选择Spark服务,单击继续, 根据安装指南配置Spark服务,配置都可以按照默认配置。
选择依赖, 根据您实际的情况进行选择。
开始安装。
安装完成。
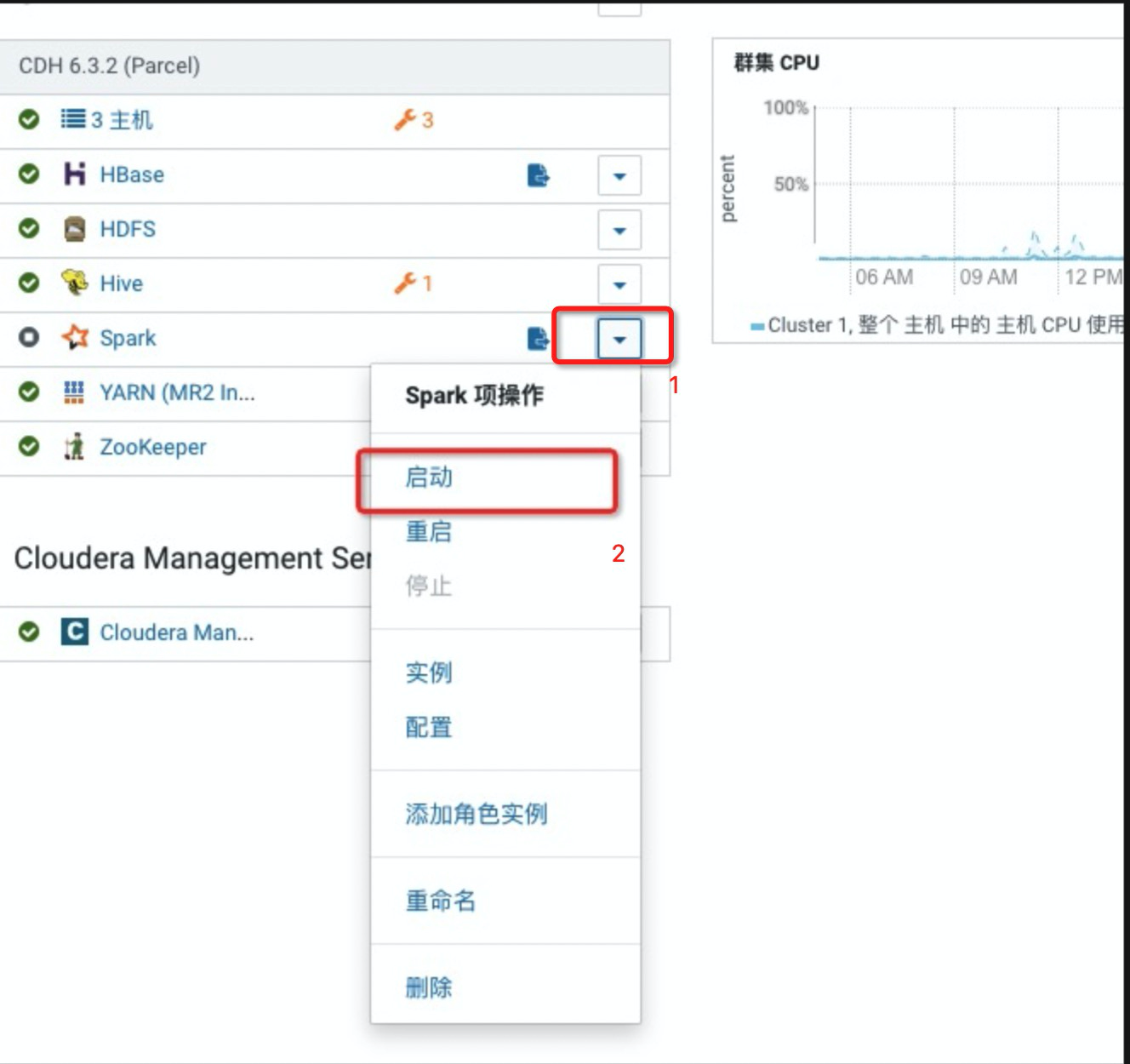
启动服务(这是因为安装完成之后,Spark并没有启动)。
返回CDH6管理系统界面,找到 Spark。
展开下拉列表,单击启动。
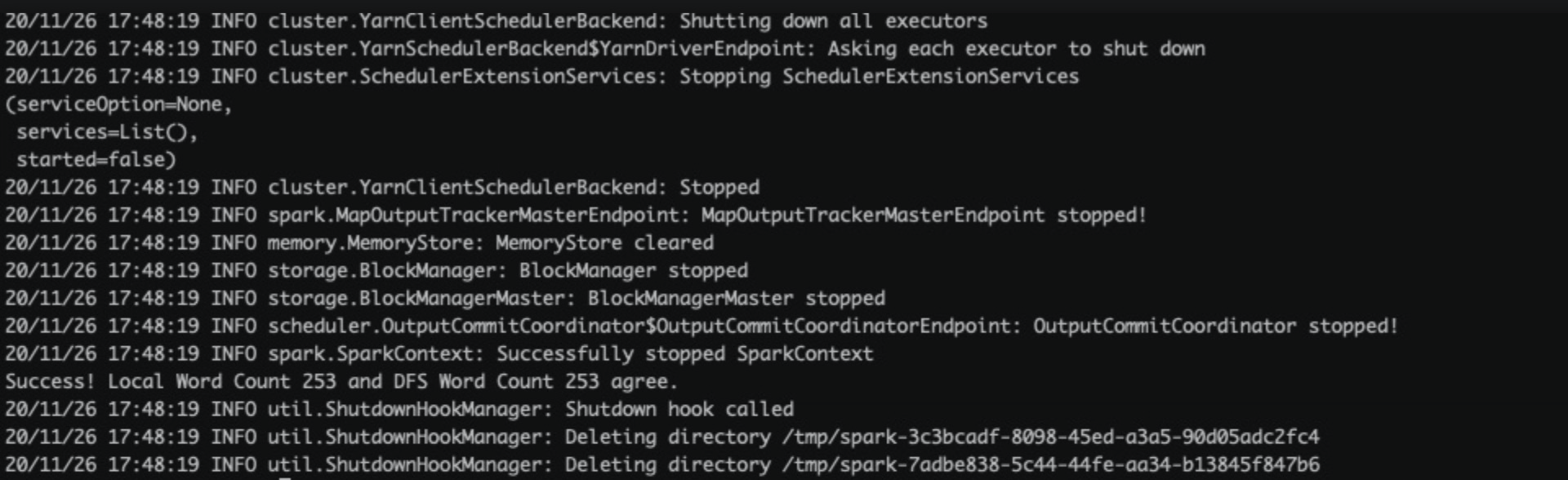
验证Spark启动是否成功。
登入CDH 6任意一台机器,使用spark测试包从LDFS上读取测试文件。
[root@cdhlindorm001 ~]# spark-submit --master yarn --executor-memory 900M --executor-cores 2 --class org.apache.spark.examples.DFSReadWriteTest /opt/cloudera/parcels/CDH/jars/spark-examples_2.11-2.4.0-cdh6.3.2.jar /etc/profile /output如果回显信息类似如下图所示,执行成功。
执行下面的指令,查看生成的结果数据。
[root@cdhlindorm001 ~]# hadoop fs -ls /output/dfs_read_write_test如果执行结果如下,表示Spark启动没有问题。

根据业务场景如果配置复杂可能有些步骤不成功,请提交工单或者联系值班。