Flink是流式计算引擎。本文为您介绍如何在Zeppelin中使用Flink。
背景信息
Zeppelin支持Flink的3种主流语言,包括Scala、PyFlink和SQL。Zeppelin中所有语言共用一个Flink Application,即共享一个ExecutionEnvironment和StreamExecutionEnvironment。例如,您在Scala里注册的table和UDF是可以被其他语言使用的。
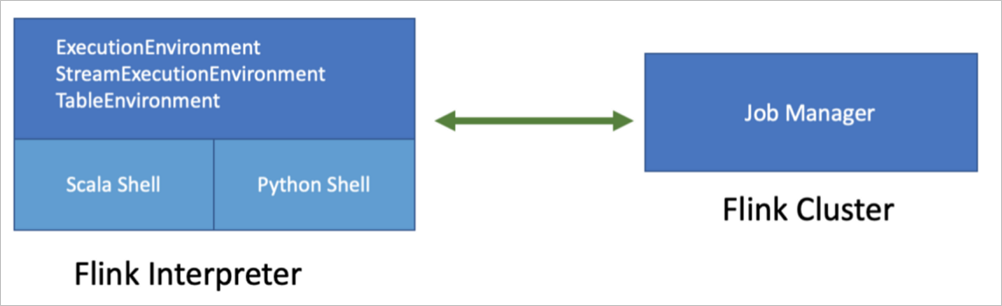
Zeppelin支持Flink,您可以在Zeppelin里使用Flink的所有功能。
- 同时支持Batch SQL和Streaming SQL
Zeppelin中同时支持Batch SQL和Streaming SQL,%flink.ssql用来执行Streaming SQL,%flink.bsql用来执行Batch SQL。
- 支持多条语句
您可以在Zeppelin的每一个Paragraph中写多条SQL语句,每条SQL语句以分号(;)间隔。
- 支持Comment
您可以在SQL中添加Comment,
--开头的表示单行Comment,/* */包围的表示多行Comment。 - 支持Job并行度配置
您可以设置每个Paragraph的parallelism来控制Flink SQL Job的并行度。

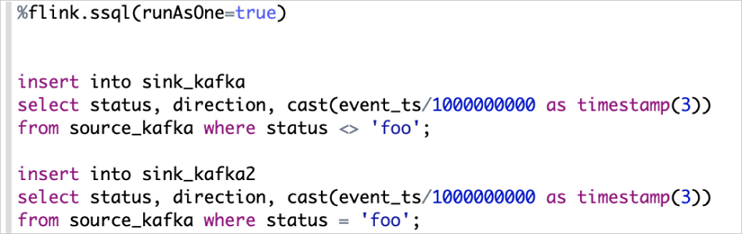
- 支持Multiple insert
例如,当您有多条INSERT语句读同一个Source时,结果会写到不同的Sink,默认情况下每条SQL语句都会独立运行一个Flink Job,如果您想合并多条语句到同一个Flink Job的话,您就需要设置runAsOne为true。
- JobName的设置
对于INSERT语句的Flink Job,您可以通过设置jobName的方式来指定Job名称。注意 只有INSERT语句才支持设置jobName,SELECT语句不支持。此方式只适用于单条INSERT语句,不支持Multiple insert。

注意事项
Zeppelin的Flink解释器已经为您创建好了所有Environment变量,您无需创建。
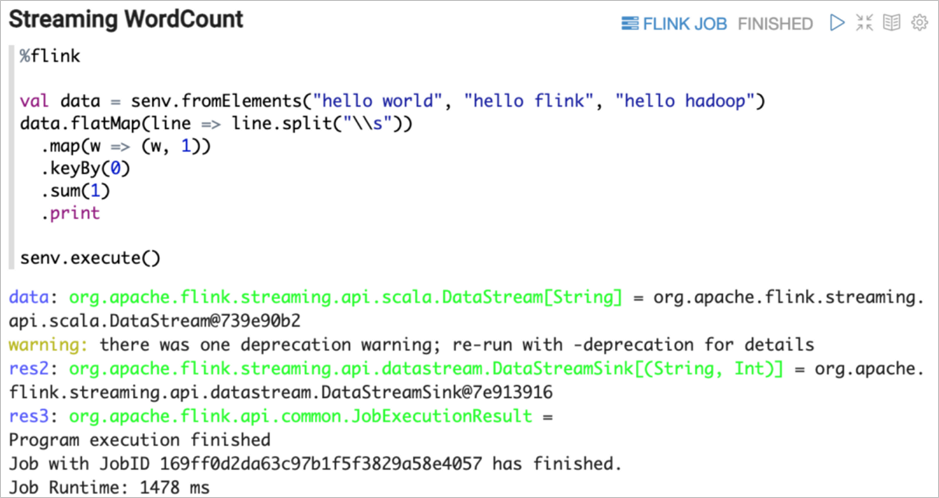
Scala(%flink)
Flink on Zeppelin支持的默认语言是Scala(%flink),也是整个Flink Interpreter内部实现的入口。Flink Interpreter内部会创建Flink Scala Shell, 在Flink Scala里会创建Flink的各种Environment。您在Zeppelin上写的Scala代码就会提交到这个Flink Scala Shell里去执行。
- senv(StreamExecutionEnvironment)
- benv(ExecutionEnvironment)
- stenv(StreamTableEnvironment for blink planner)
- btenv(BatchTableEnvironment for blink planner)
- stenv_2(StreamTableEnvironment for flink planner)
- btenv_2(BatchTableEnvironment for flink planner)
- z(ZeppelinContext)
PyFlink (%flink.pyflink)
PyFlink是Flink on Zeppelin上Python语言的入口,Flink Interpreter内部会创建Python Shell。Python Shell内部会创建Flink的各种Environment,但是PyFlink里的各种Environment变量对应的Java变量都是Scala Shell创建的。您在Zeppelin上写的Python代码会提交到这个Python Shell里去执行。
- s_env(StreamExecutionEnvironment)
- b_env(ExecutionEnvironment)
- st_env(StreamTableEnvironment for blink planner)
- bt_env(BatchTableEnvironment for blink planner)
- st_env_2(StreamTableEnvironment for flink planner)
- bt_env_2(BatchTableEnvironment for flink planner)
- z(ZeppelinContext)
SQL (%flink.ssql和%flink.bsql)
- %flink.ssql:Streaming SQL,使用StreamTableEnvironment来执行SQL。
- %flink.bsql:Batch SQL, 使用BatchTableEnvironment来执行SQL。
- DDL(Data Definition Language)
- DML(Data Manipulation Language)
- DQL(Data Query Language)
- Flink定制语句
例如,SET和HELP语句。
Streaming SQL结果可视化
Zeppelin对于Select语句的结果以流式的方式可视化。
- Single模式
Single模式适合当输出结果是一行的情况,不适合用图形化的方式展现,使用文本的方式更适合。
例如,下面的Select语句,这条SQL语句只有一行数据,但这行数据会持续不断的更新。%flink.ssql(type=single, parallelism=1, refreshInterval=3000, template=<h1>{1}</h1> until <h2>{0}</h2>) select max(event_ts), count(1) from sink_kafka此模式的数据输出格式是HTML形式,您可以用template来指定输出模板,{i}是第i列的placeholder。
结果如下图所示。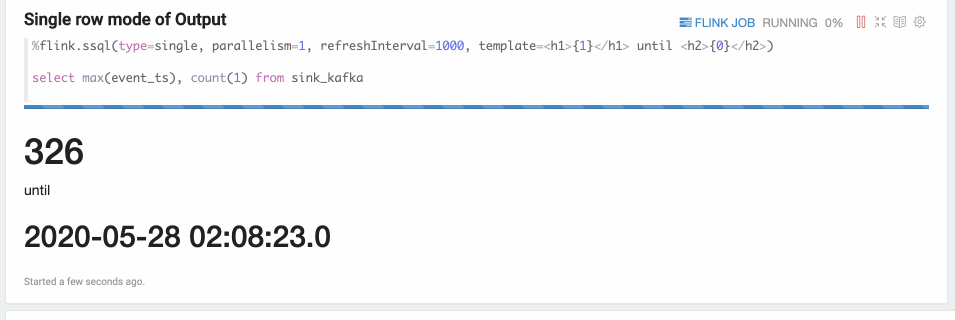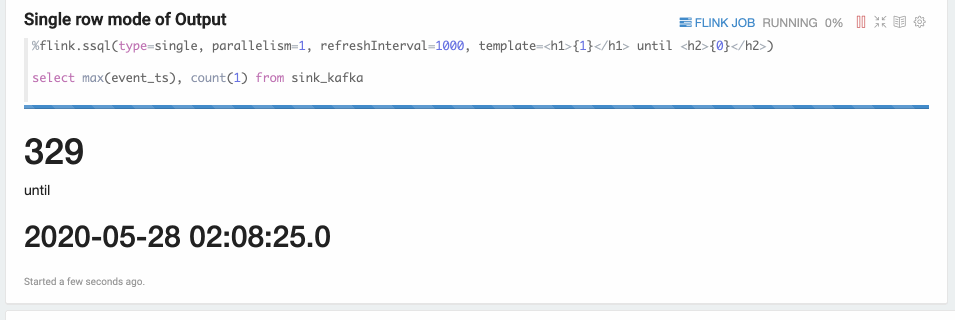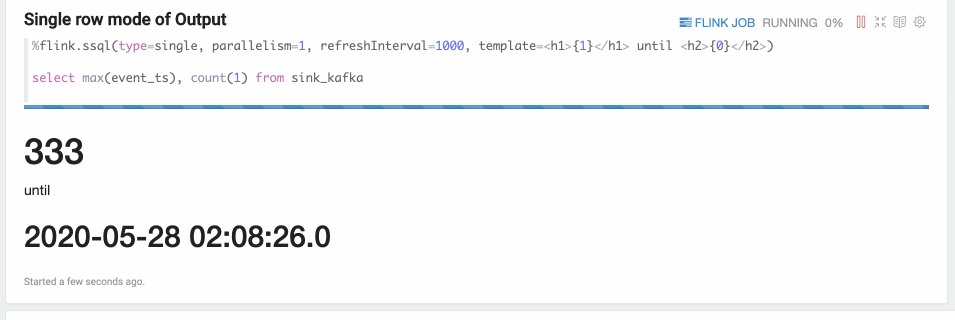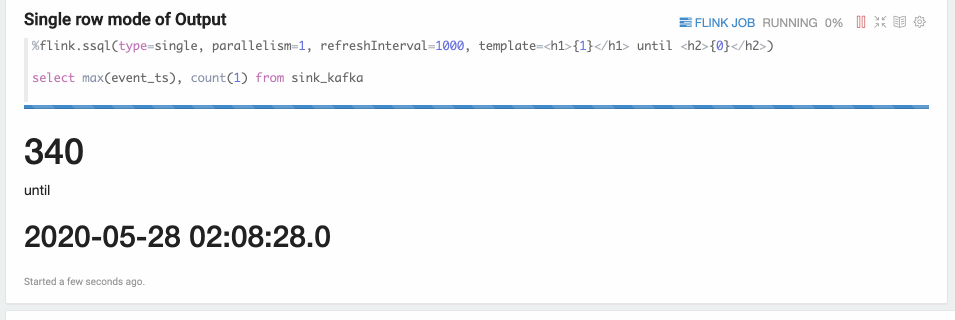
- Update模式
Update模式适合多行输出的情况,此模式会定期更新数据,输出格式是Zeppelin的table格式。例如,SELECT GROUP BY语句。
%flink.ssql(type=update, refreshInterval=2000, parallelism=1) select status, count(1) as pv from sink_kafka group by status结果如下图所示。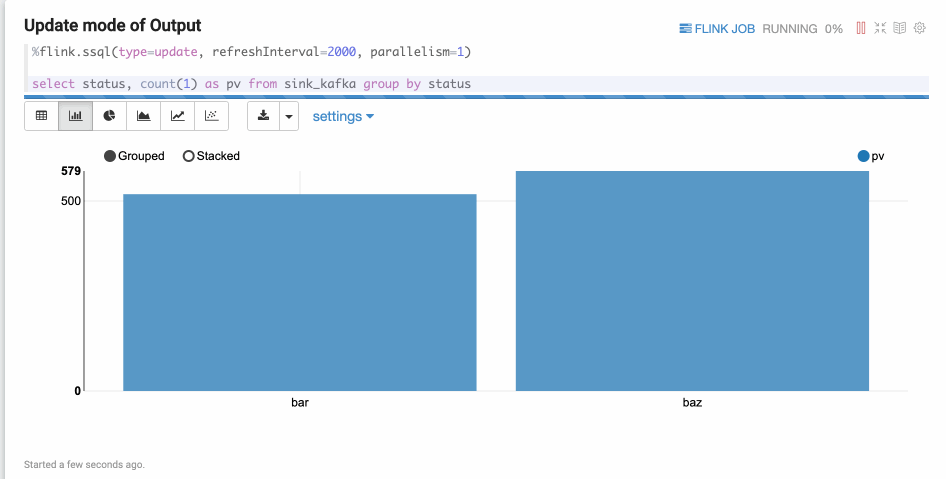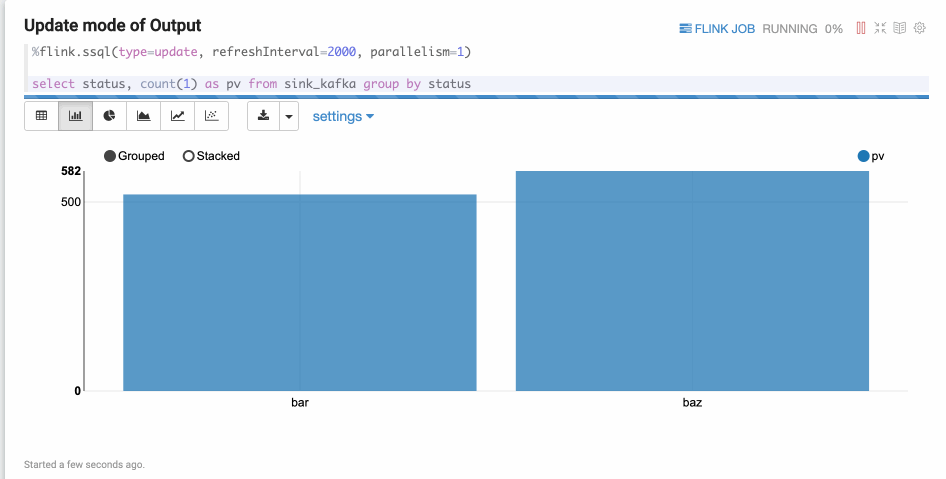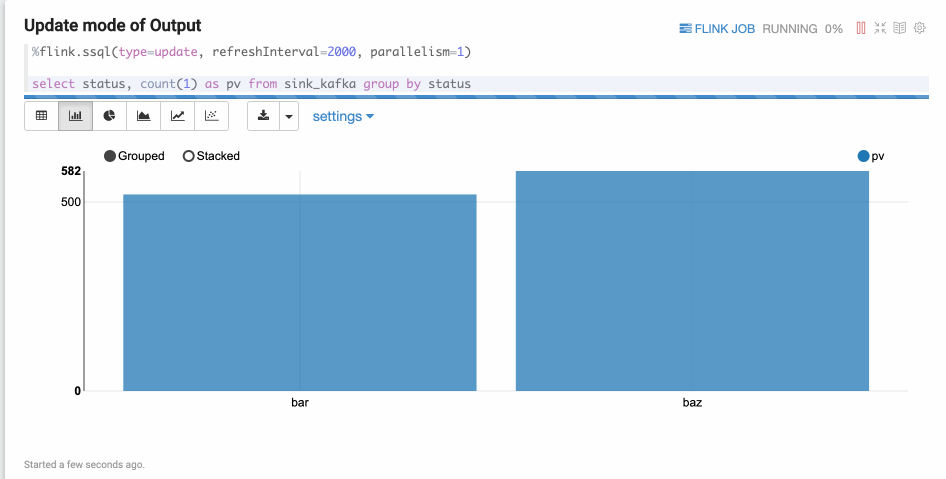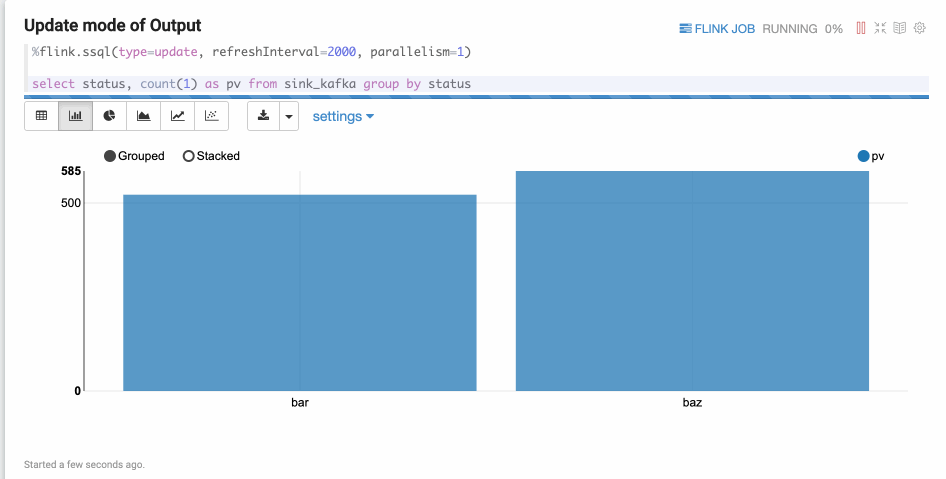
- Append模式
Append模式适合时间序列数据,不断有新数据输出,但不会覆盖原有数据,只会不断Append的情况。
例如,基于窗口的GROUP BY语句。Append模式要求第一列数据类型是TIMESTAMP,代码中的start_time就是TIMESTAMP类型。%flink.ssql(type=append, parallelism=1, refreshInterval=2000, threshold=60000) select TUMBLE_START(event_ts, INTERVAL '5' SECOND) as start_time, status, count(1) from sink_kafka group by TUMBLE(event_ts, INTERVAL '5' SECOND), status结果如下图所示。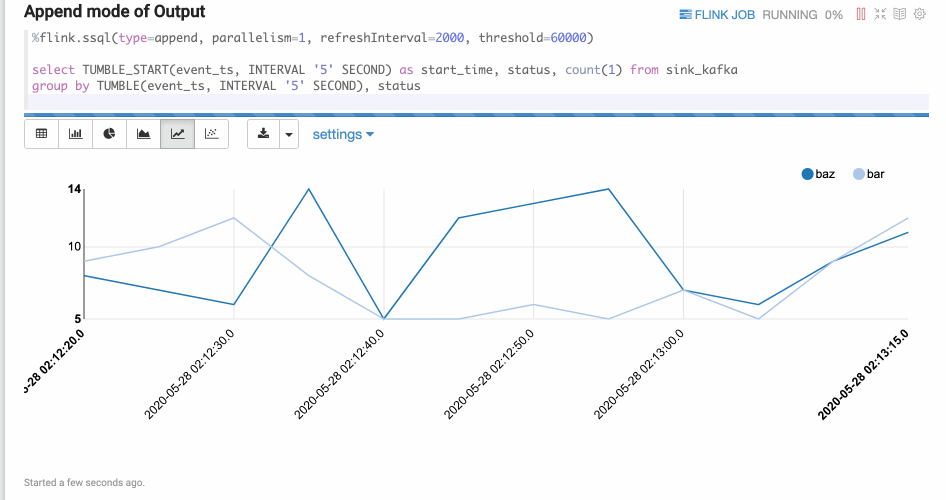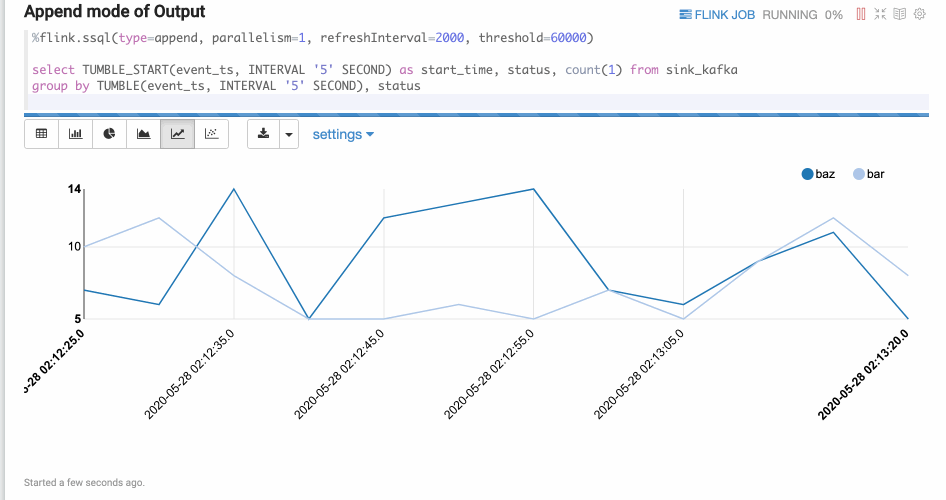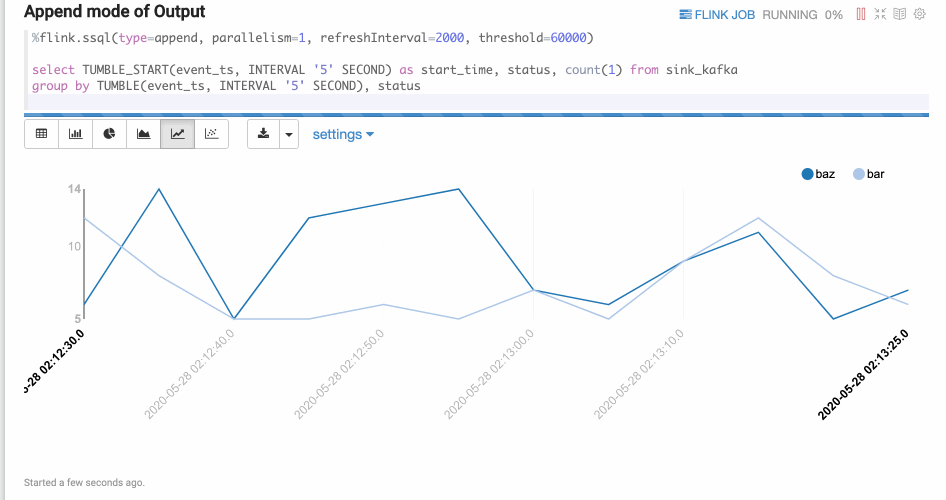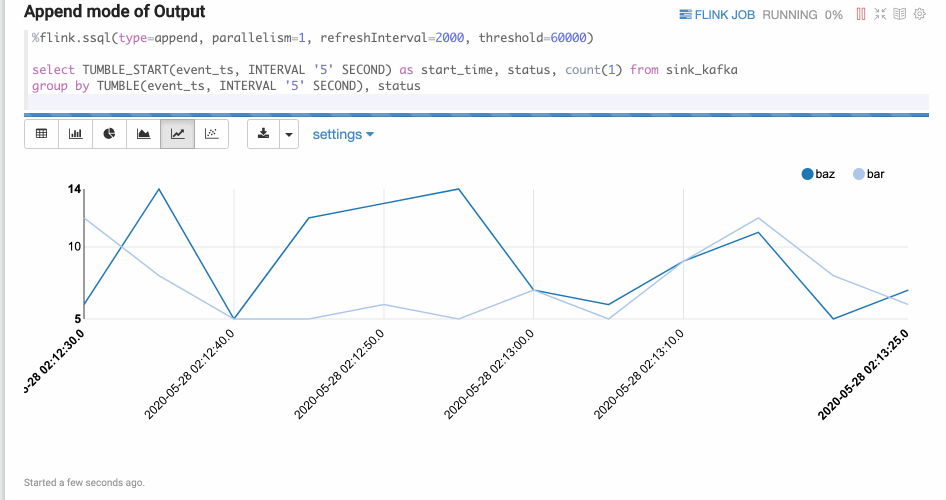
UDF
- 在Zeppelin中直接写Scala UDF。
此方式适合写比较简单的UDF。您只需定义UDF的Class,然后在btenv或stenv中注册定义的UDF。完成注册后,您可以在%flink.bsql或%flink.ssql中使用,因为%flink.bsql或%flink.ssql共享同一个Catalog。
%flink class ScalaUpper extends ScalarFunction { def eval(str: String) = str.toUpperCase } btenv.registerFunction("scala_upper", new ScalaUpper()) - 在Zeppelin中直接写PyFlink UDF。
此方式适合写比较简单的UDF。在Zeppelin中定义PyFlink UDF与Scala UDF类似。您只需定义UDF的Class,然后在btenv或stenv中注册定义的UDF。完成注册后,您可以在%flink.bsql或%flink.ssql中使用,因为%flink.bsql或%flink.ssql共享同一个Catalog。
%flink.pyflink class PythonUpper(ScalarFunction): def eval(self, s): return s.upper() bt_env.register_function("python_upper", udf(PythonUpper(), DataTypes.STRING(), DataTypes.STRING())) - 使用SQL创建UDF。
部分简单的UDF可以在Zeppelin里直接写,但是如果是一些复杂的UDF,建议在IDE里写,然后在Zeppelin中创建注册。例如:
%flink.ssql CREATE FUNCTION myupper AS 'org.apache.zeppelin.flink.udf.JavaUpper';因为使用此方式前提是这个UDF对应的JAR包必须要在CLASSPATH里,所以您需要先配置flink.execution.jars,把这个UDF的JAR包放到CLASSPATH里。flink.execution.jars /Users/jzhang/github/flink-udf/target/flink-udf-1.0-SNAPSHOT.jar - 使用flink.udf.jars来指定含有UDF的JAR包。
如果您有多个UDF,并且UDF之间的逻辑比较复杂,您也不想注册UDF,此时您可以使用flink.udf.jars。
- 在IDE里创建Flink UDF项目,编写UDF。
示例详情,请参见Flink UDF。
- 使用flink.udf.jars指定Flink UDF项目的JAR包。
flink.udf.jars /Users/jzhang/github/flink-udf/target/flink-udf-1.0-SNAPSHOT.jarZeppelin会扫描JAR包,然后检测出所有的UDF,并且自动注册UDF,UDF的名字就是Class名字。
例如,show functions的结果如下。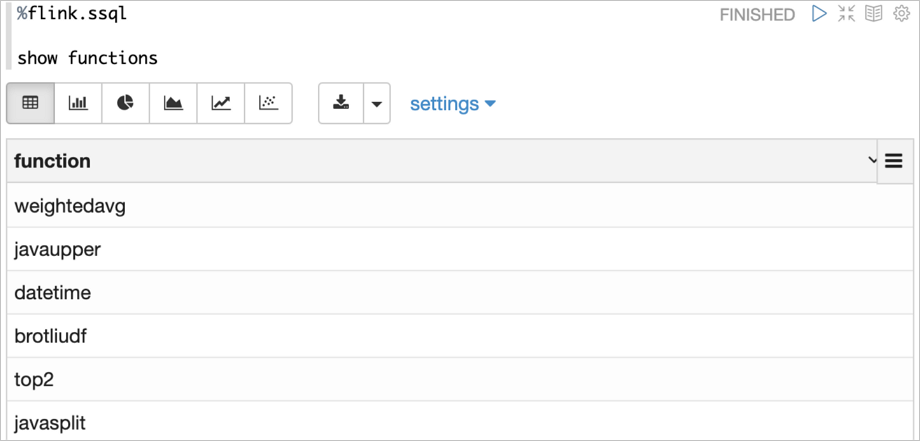 说明 默认情况下Zeppelin会扫描JAR包里的所有的Class,如果JAR包过大可能会导致性能问题。此时您可以设置flink.udf.jars.packages来指定扫描的Package,以减少扫描的Class数目。
说明 默认情况下Zeppelin会扫描JAR包里的所有的Class,如果JAR包过大可能会导致性能问题。此时您可以设置flink.udf.jars.packages来指定扫描的Package,以减少扫描的Class数目。
- 在IDE里创建Flink UDF项目,编写UDF。
第三方依赖
- flink.excuetion.packages
此方式和在pom.xml里添加依赖是类似的,会下载相应的Package和所有Transitive依赖到CLASSPATH里。
例如,添加Kafka Connector依赖。flink.execution.packages org.apache.flink:flink-connector-kafka_2.11:1.10.0,org.apache.flink:flink-connector-kafka-base_2.11:1.10.0,org.apache.flink:flink-json:1.10.0Package的格式为artifactGroup:artifactId:version,当有多个Package时,每个Package用逗号(,)分隔。说明 此方式需要Zeppelin机器可以访问外网,如果不能访问外网的话,建议您使用flink.execution.jars方式。 - flink.execution.jars
如果您的Zeppelin机器不能访问外网或者您的依赖没有发布在Maven Repository里,则您可以将依赖的JAR包放到Zeppelin机器上,然后通过flink.execution.jars来指定这些JAR包,多个JAR包时用逗号(,)分隔。
例如,添加Kafka Connector依赖。flink.execution.jars /Users/jzhang/github/flink-kafka/target/flink-kafka-1.0-SNAPSHOT.jar说明 示例中的flink-kafka-1.0-SNAPSHOT.jar是通过pom.xml文件构建的。
内置教程