
本文介绍如何搭建Stable Diffusion的WebUI框架以实现2秒内文本生成图片、如何使用Deepytorch加速图片生成速度,以及如何使用不同模型进行推理。
背景信息
Stable Diffusion是一个可通过文本生成图像的扩散模型,基于CLIP模型从文字中提取隐变量,并通过UNet模型生成图片;最后通过逐步扩散、逐步处理图像,优化图像质量。
Deepytorch Inference是阿里云自研的AI推理加速器,专注于为Torch模型提供高性能的推理加速。通过对模型的计算图进行切割、执行层融合以及高性能OP的实现,大幅度提升PyTorch的推理性能。更多信息,请参见什么是Deepytorch Inference(推理加速)。
本文基于阿里云GPU服务器和Stable Diffusion的WebUI框架,指导您如何基于Deepytorch加速器快速实现AIGC绘画。

阿里云不对第三方模型的合法性、安全性、准确性进行任何保证,阿里云不对由此引发的任何损害承担责任。
您应自觉遵守第三方模型的用户协议、使用规范和相关法律法规,并就使用第三方模型的合法性、合规性自行承担相关责任。
操作步骤
创建ECS实例
本文使用的ai-inference-solution市场镜像中,内置了以下三个模型及运行环境。
v1-5-pruned-emaonly.safetensors:Stable Diffusion v1.5模型,一种潜在的text-to-image(文本到图像)的扩散模型,能够在给定任何文本输入的情况下生成逼真的图像。
说明该模型中文提示词效果不好,建议使用英文提示词。
Taiyi-Stable-Diffusion-1B-Chinese-v0.1:太乙-中文模型,基于0.2亿筛选过的中文图文对训练,可以使用中文进行AI绘画。
Taiyi-Stable-Diffusion-1B-Anime-Chinese-v0.1:太乙-动漫风格模型,首个开源的中文Stable Diffusion动漫模型,该模型是基于Taiyi-Stable-Diffusion-1B-Chinese-v0.1进行继续训练,经过100万筛选过的动漫中文图文对训练得到的。太乙-动漫风格模型不仅能够生成精美的动漫图像,还保留了太乙-中文模型对中文概念强大的理解能力。
前往实例创建页。
按照界面提示完成参数配置,创建一台ECS实例。
需要注意的参数如下,其他参数的配置,请参见自定义购买实例。
实例:选择实例规格为ecs.gn7i-c16g1.4xlarge。
镜像:本文使用已部署好推理所需环境的云市场镜像,名称为ai-inference-solution。
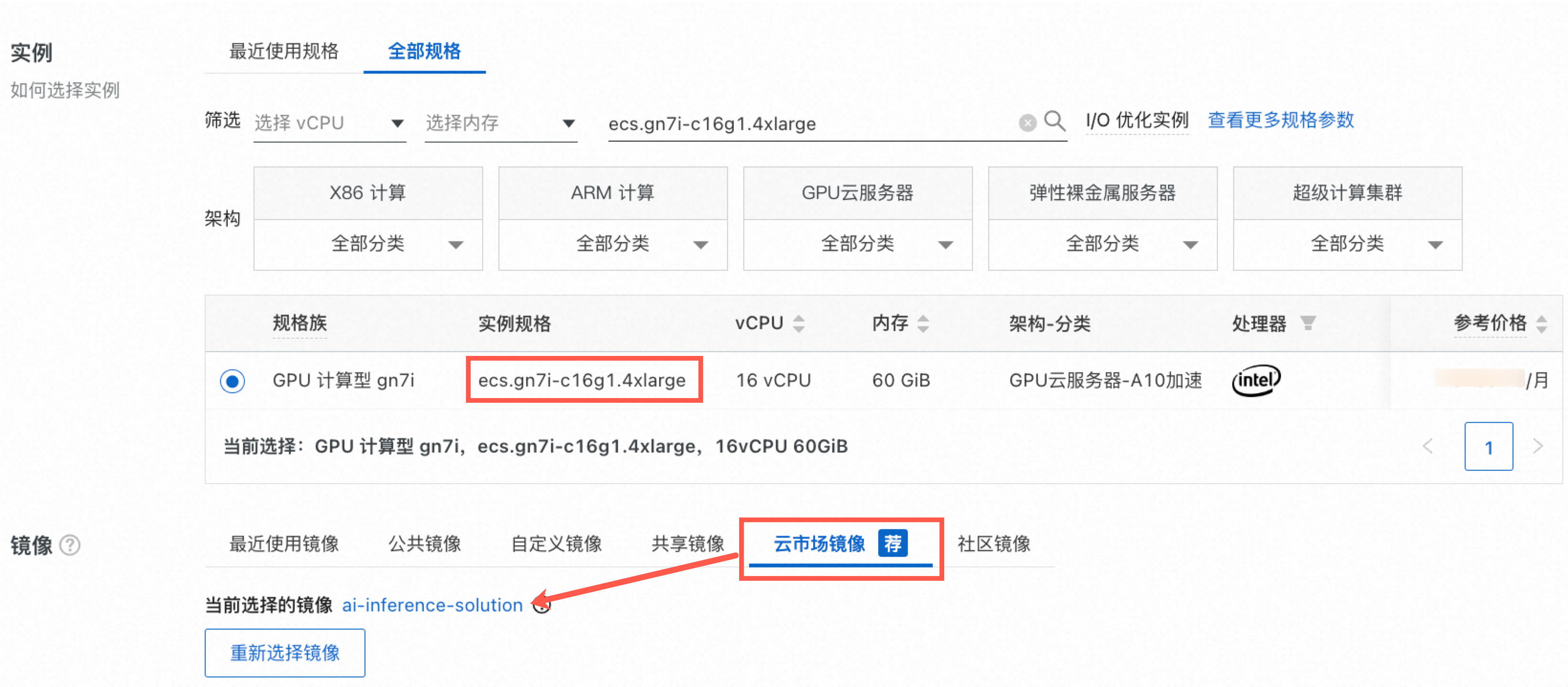
公网IP:选中分配公网IPv4地址,带宽计费模式选择按使用流量,带宽峰值设置为10 Mbps。
说明如果您需要自行下载模型测试,建议将带宽峰值设置为100 Mbps,以加快模型下载速度。
为当前ECS实例添加安全组规则,具体操作,请参见添加安全组规则。
安全组规则所属的方向:入方向,端口范围:5000/5000,授权对象:访问WebUI服务的本地客户端公网IP地址(非实例公网IP地址)。例如本地客户端公网IP为101.200.XX.XX,则授权对象为101.200.XX.XX/32。

创建完成后,在ECS实例页面,获取公网IP地址。
说明公网IP地址用于生成图片测试时访问WebUI服务。
为Nginx添加用户登录验证
本文所使用的镜像中预装了Nginx软件,用于登录鉴权,以防止非授权用户登录。
执行如下命令,创建登录用户和密码。
说明${UserName}请替换为您自定义的用户名,例如admin;'${Password}'请替换为您自定义的密码,例如ECS@test1234。htpasswd -bc /etc/nginx/password ${UserName} '${Password}'执行如下命令,重启Nginx。
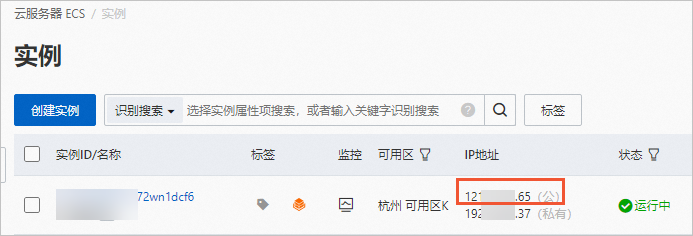
systemctl restart nginx执行如下命令,查看Nginx状态。
systemctl status nginx当显示如下图所示的回显信息时,说明Nginx处于运行中。
执行如下命令,设置Nginx开机自启动。
systemctl enable nginx
开始文本生成图片
步骤一:启动WebUI服务
执行如下命令,启动WebUI服务。
cd ~/stable-diffusion-webui/
nohup ./run_taiyi.sh &建议您等待1分钟,等待WebUI加载完成。
步骤二:开启AI绘画并测试Deepytorch加速效果
在浏览器地址栏输入
http://<ECS公网IP地址>:5000,在弹出的登录对话框,输入上章节第1步中创建的用户和密码,单击登录。
开始AI绘画。
说明首次应用Deepytorch进行图片生成,或者切换模型后的首次图片生成,会多占用约30s时间,以进行Deepytorch模型加载。
开启Deepytorch加速时进行AI绘画(默认已开启)
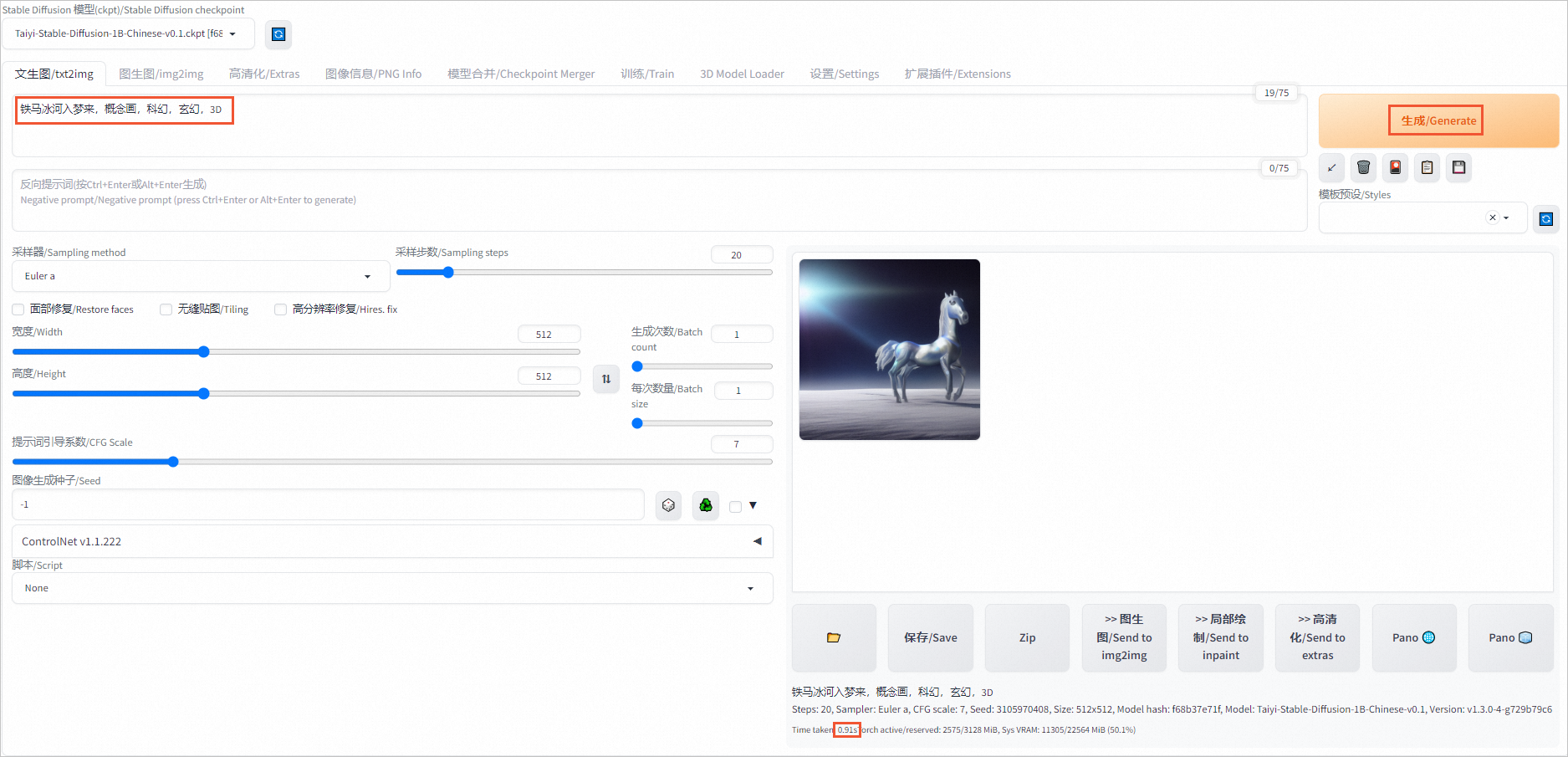
在对话框中输入关键字,如铁马冰河入梦来,概念画,科幻,玄幻,3D,单击生成/Generate(您可以尝试多次Generate,生成更符合需求的图片)。
页面右侧将会展示生成的图片和推理时间,本示例中单张图片推理时间为0.91s。
禁用Deepytorch时进行AI绘画
单击设置/Settings页签,左侧导航选择AiaccTorch,取消选中Apply Aiacctorch in Unet to speedup the whole network inference when loading models后,单击应用设置/Apply settings,再单击重新加载WebUI/Reload UI。
在对话框中输入关键字,单击生成/Generate,重新生成图片,查看推理时间(本示例为2.02s)。
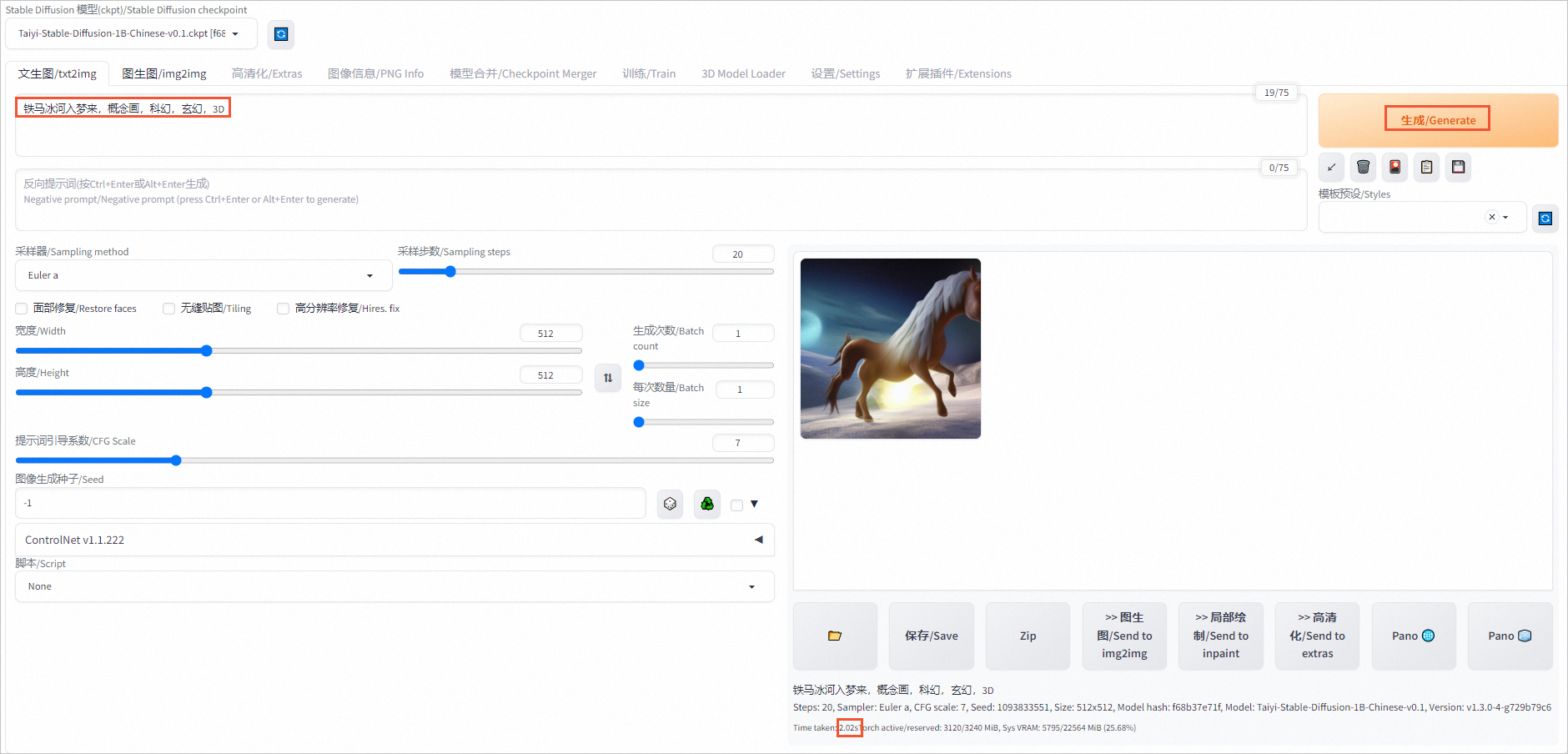
对比发现,开启Deepytorch后,单张图片的推理时间要远少于禁用Deepytorch时的推理时间。
查看不同模型的推理效果
本文使用的镜像中内置了3个模型,您可根据需求切换模型,查看不同模型的推理效果。
在页面左上角,切换模型,例如切换为Taiyi-Stable-Diffusion-1B-Anime-Chinese-v0.1模型。
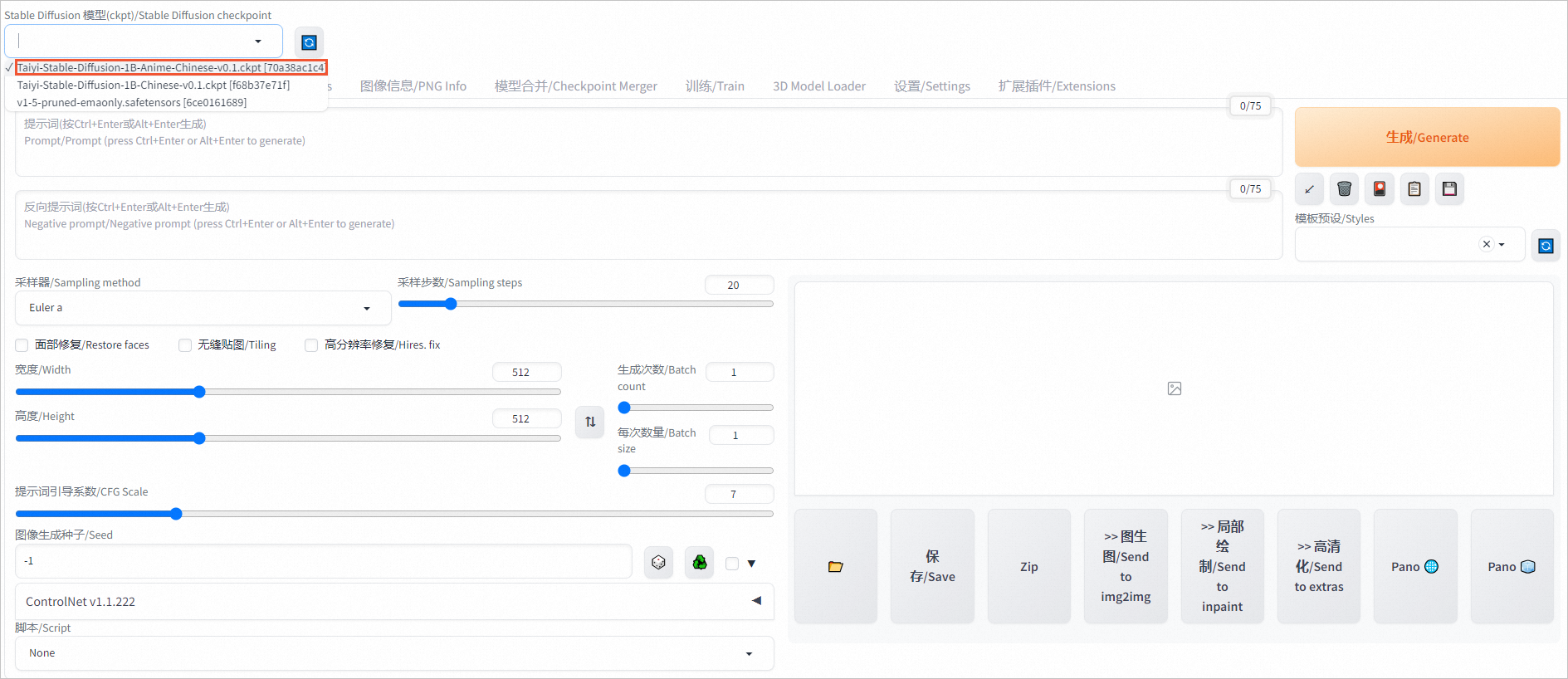
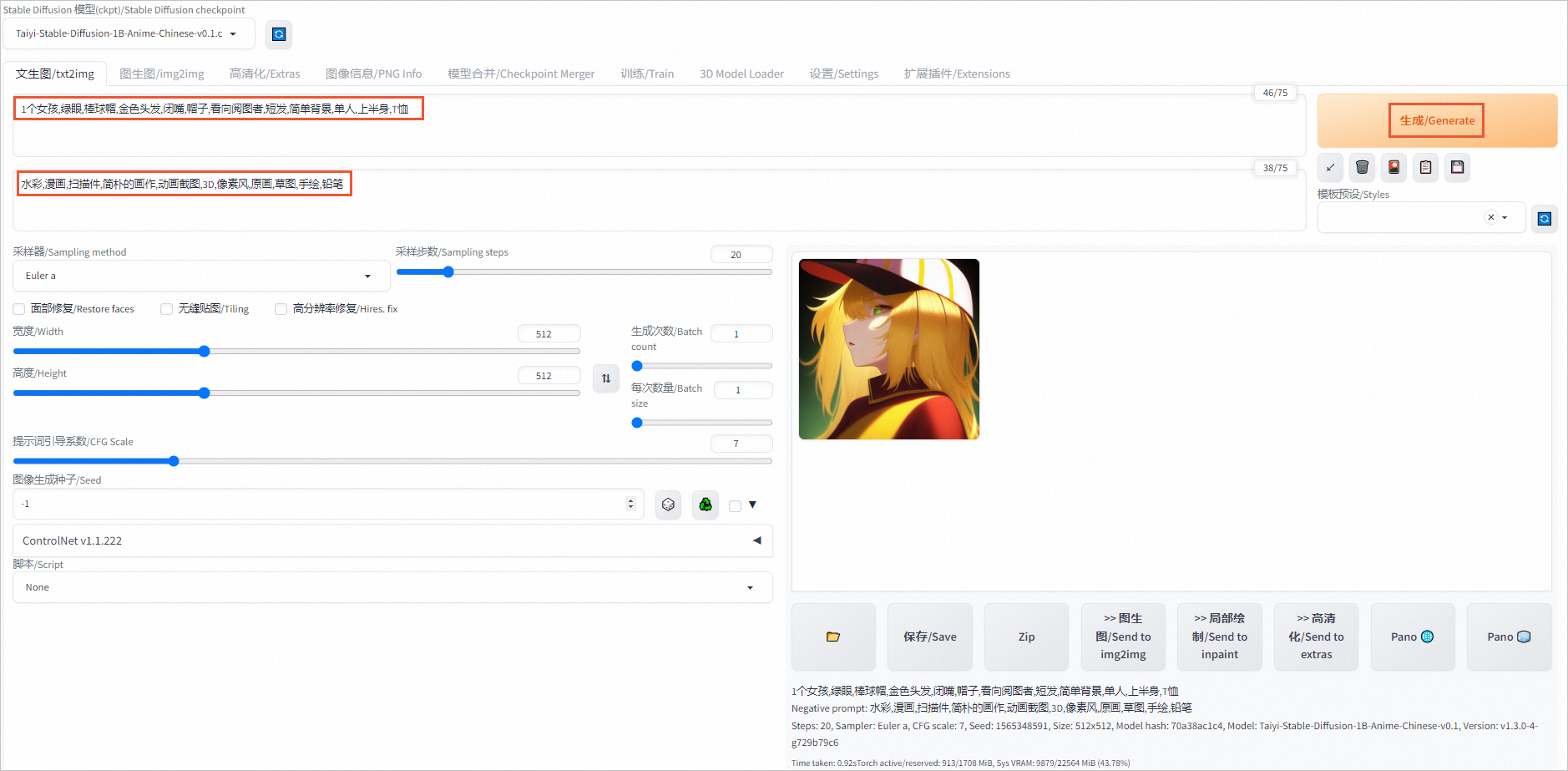
在对话框中输入提示词和反向提示词。
提示词示例:
1个女孩,绿眼,棒球帽,金色头发,闭嘴,帽子,看向阅图者,短发,简单背景,单人,上半身,T恤反向提示词示例:
水彩,漫画,扫描件,简朴的画作,动画截图,3D,像素风,原画,草图,手绘,铅笔生成的动漫风格图像如下图所示。
使用LoRA插件
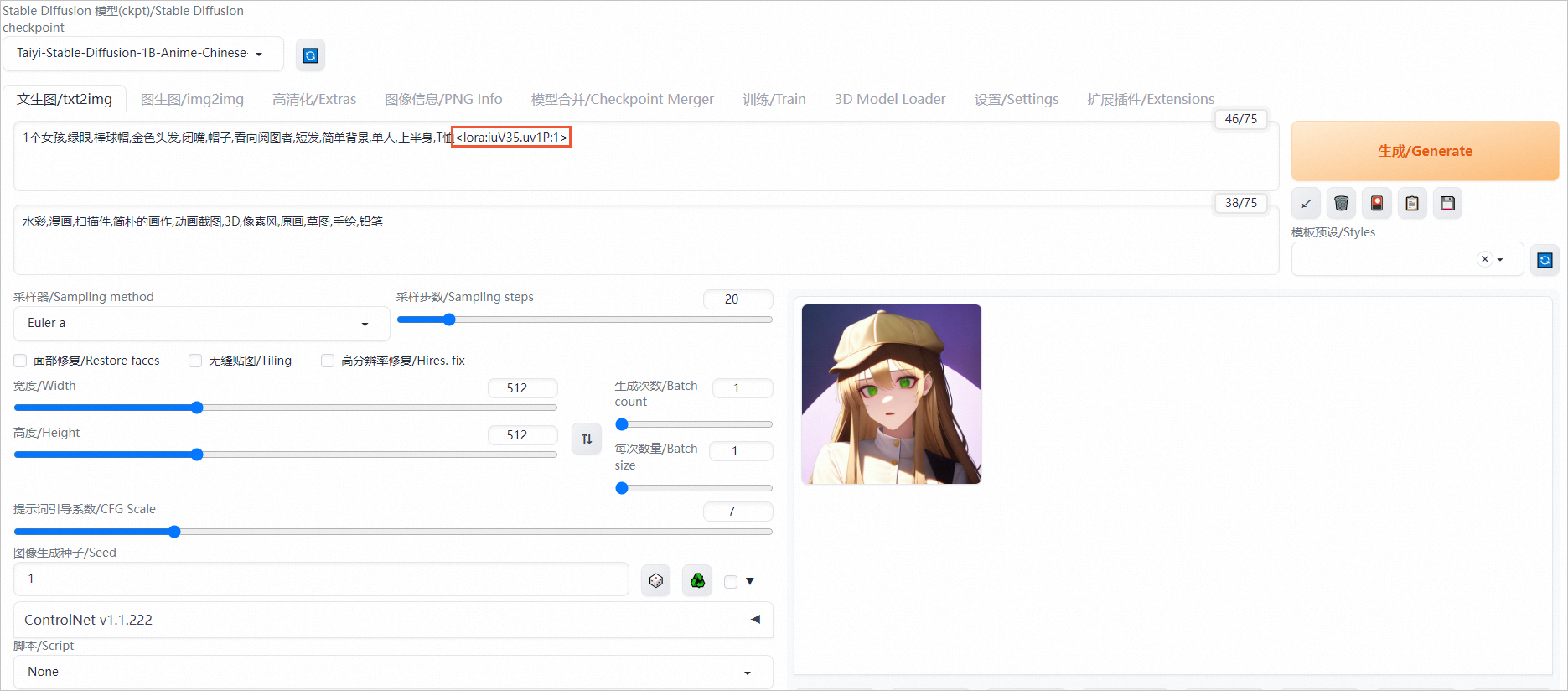
LoRA是Stable Diffusion模型的一种插件,它允许在不修改Stable Diffusion模型的情况下,使用少量数据训练出一种画风、IP或人物,以实现定制化需求。相较于训练Stable Diffusion,使用LoRA所需的训练资源更少,非常适合社区用户和个人开发者使用。
您可以在提示词(Prompt)中添加LoRA支持文本<lora:iuV35.uv1P:1>以启用该功能。
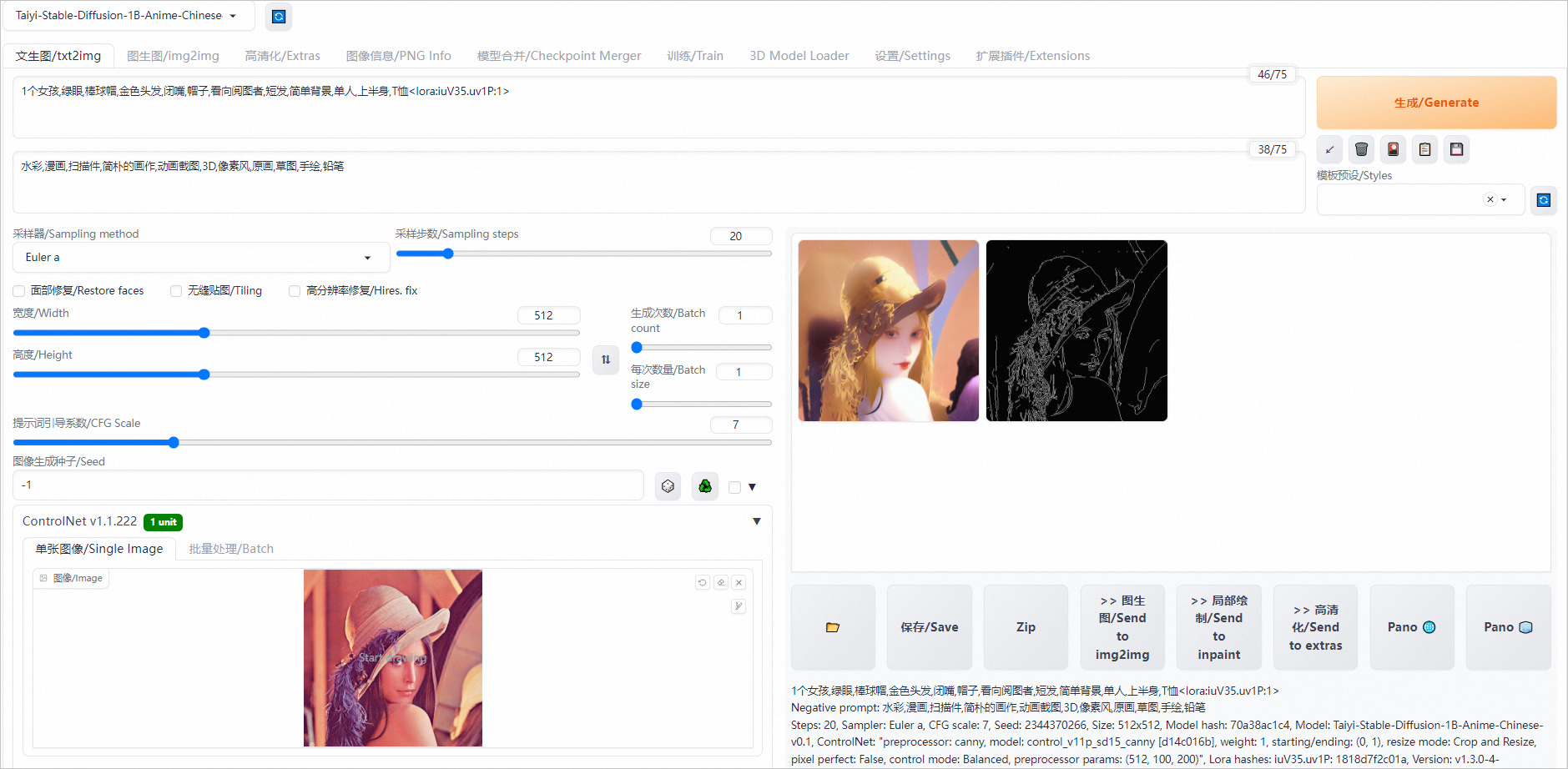
使用Controlnet插件
ControlNet是一个用于控制AI图像生成的插件,它可以利用输入图片中的边缘特征、深度特征或人体姿势的骨架特征,与文字提示一起精准地控制AI图像的生成,以获得更好的视觉效果。
Canny是ControlNet中一个常见的模型,用于识别输入图像的边缘信息,从上传的图片中生成线稿,然后根据关键词生成与上传图片相似构图的画面。
单击Controlnet右侧的
 图标,选中启用/Enable,Control Type选择Canny,在单张图像/Single Image区域中,上传输入的图片(如Lena图)。
图标,选中启用/Enable,Control Type选择Canny,在单张图像/Single Image区域中,上传输入的图片(如Lena图)。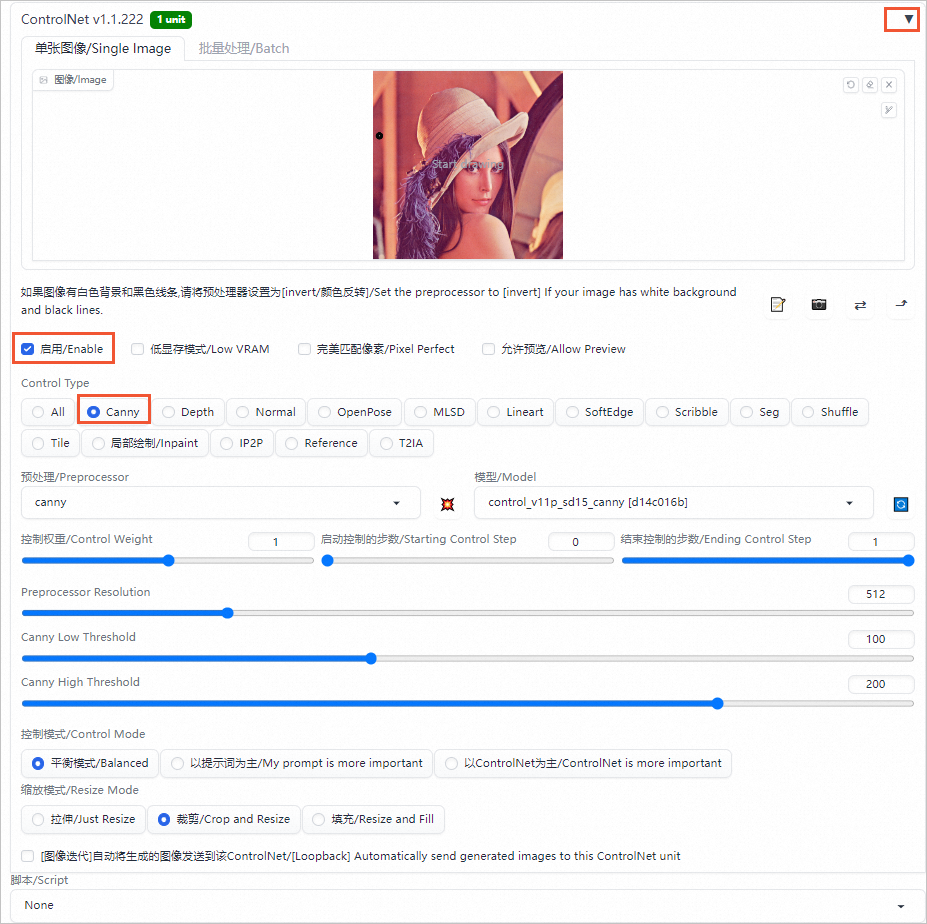
单击生成/Generate,在页面右侧即可生成使用Canny模型生成的线稿和同样构图的图片。
了解更多AIGC实践和GPU优惠
活动入口:立即开启AIGC之旅

反馈与建议
如果您在使用教程或实践过程中有任何问题或建议,可以加入客户钉钉群(钉钉群号:28335015590)与我们的工程师在线交流,将有专人跟进您的问题和建议。