案例:搭建以图搜图系统
本文将介绍如何通过AnalyticDB PostgreSQL版向量数据库快速搭建一套以图搜图系统。
背景信息
以图搜图在生活中有着广泛的应用,当您想拥有在电视中看到的一件美丽裙子或者帅气球鞋时,可以拍张照片,然后打开淘宝上传照片,就可以快速地找到这个商品。或者,想知道一张电影截图的出处时,只要将图片粘贴到搜索引擎的图搜框中,就可以找到相关电影的信息。以图搜图还可以通过照片在海量的人物相册中快速地找到目标。当您在使用搜索引擎的以图搜图功能时,是否觉得这种“黑科技”遥不可及呢?其实通过AnalyticDB PostgreSQL版向量数据库提供的高效向量检索功能,您只需要使用SQL就可以轻松地搭建一套以图搜图系统。
以图搜图原理介绍
以图搜图又称为反向图搜 (Reverse Image Search),是一种基于内容的图像检索 (Content-based Image Retrieval) 技术。以图片作为查询的对象,以图搜图系统会在大量的图像记录中返回与查询图像内容最接近的记录。例如,商品以图搜图会返回与查询图片中主体物品相同或相似的图片信息;人脸以图搜图会根据图片中人脸特征返回目标人物的图片记录。
以图搜图应用的核心模块有两个:
特征提取模块:负责从图像中提取视觉特征,从而获得一个高维的特征向量,在这个高维特征空间中越相似的图像距离越近。
向量检索模块:负责在海量的图像特征向量集中快速地查找与查询图片特征最接近的前k个记录,并返回。
以图搜图的流程图如下所示。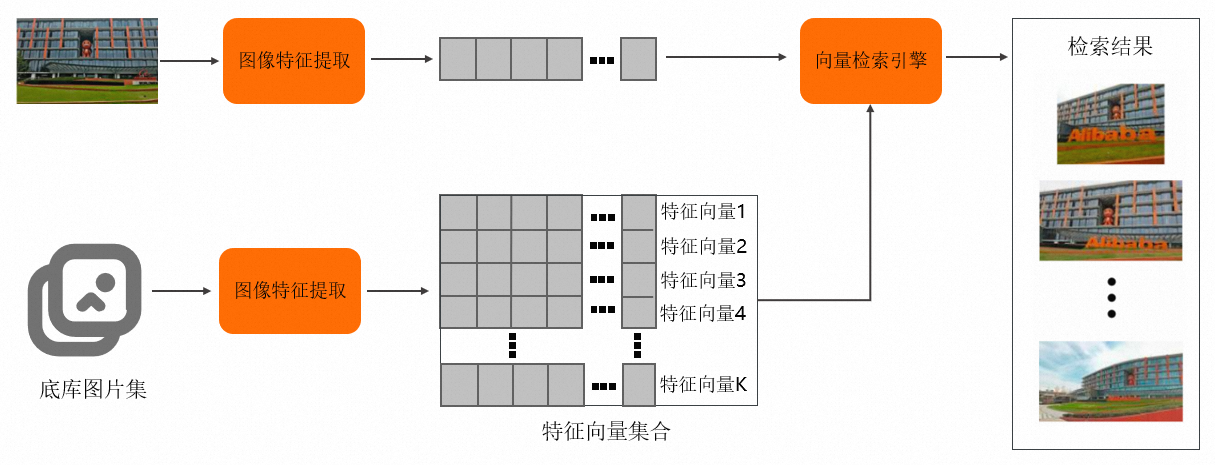
图像特征提取
当前主流的特征提取算法主要是使用深度学习模型,例如VGG、ResNet、Transformer等模型作为主干网络,然后使用不同的方法生成特征。生成特征常用的方法有三种:
最简单的方法,直接将分类模型(如VGG模型)分类层的前一层输出作为图像的特征,这种算法在以图搜图场景中往往召回率不是很高。
第二种方法,将模型中间层的特征经过特殊的方法池化(如RMAC和GeM)和降维从而得到。
第三种方法,将预训练模型在目标数据集上使用专门设计的损失函数进行迁移训练,以提取特征。例如,商品以图搜图特征提取模型通常需要在商品数据集上进行迁移学习,以便能更加准确地提取不同商品的视觉特征。
您可以选择适合当前使用场景的方法,提取图像的特征,生成特征向量。
向量检索
向量检索又称为最近邻 (Nearest Neighbor Search,NNS) 检索,主要负责在海量特征向量中快速地查找与查询向量距离最近的k个记录。虽然可以通过遍历的方法,依次计算查询向量与数据库中所有向量的距离,然后排序,得到结果,但是这种方法的时间复杂度在大规模数据场景下基本无法满足要求。
在实际的应用场景中,通常使用近似最近邻检索 (Approximate Nearest Neighbor,ANN) 的方法,ANN主要利用向量数据分布的特性以牺牲一定检索精度为代价,快速地返回可能是查询目标最近邻的数据。
常见ANN的方法有三种:
基于局部敏感哈希 (LSH) 的方法。
基于乘积量化的方法。
基于图的方法。
使用AnalyticDB PostgreSQL向量数据库实现以图搜图
步骤一:特征向量提取
本文使用的工具如下:
编程语言为Python 3.8。
深度学习框架为Pytorch。
数据集为CIFAR100,包含了100类图像,每类包含600张图片。
用于提取特征的网络为已经预训练的SqueezeNet。SqueezeNet网络很轻量,输出的特征向量为1000维。
建议使用Jupyter Notebook依次运行以下代码。
创建Python环境。
# 建议使用Anaconda创建新的Python环境。 conda create -n adbpg_env python=3.8 conda activate adbpg_env pip install torchvision pip install matplotlib pip install psycopg2cffi下载CIFAR100数据集并进行预处理。
import torch import torchvision from torchvision.transforms import ( Compose, Resize, CenterCrop, ToTensor, Normalize ) preprocess = Compose([ Resize(256), CenterCrop(224), ToTensor(), Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]), ]) DATA_DIRECTORY = "/Users/XXX/Desktop/vector/CIFAR" datasets = { "CIFAR100": torchvision.datasets.CIFAR100(DATA_DIRECTORY, transform=preprocess, download=True) }(可选)查看下载的数据集。
import numpy as np import matplotlib.pyplot as plt from mpl_toolkits.axes_grid1 import ImageGrid def show_images_from_full_dataset(dset, num_rows, num_cols, indices): im_arrays = np.take(dset.data, indices, axis=0) labels = map(dset.classes.__getitem__, np.take(dset.targets, indices)) fig = plt.figure(figsize=(10, 10)) grid = ImageGrid( fig, 111, nrows_ncols=(num_rows, num_cols), axes_pad=0.3) for ax, im_array, label in zip(grid, im_arrays, labels): ax.imshow(im_array) ax.set_title(label) ax.axis("off") dataset = datasets["CIFAR100"] show_images_from_full_dataset(dataset, 4, 8, [i for i in range(0, 32)])
使用Squeezenet1_1模型批量生成所有图片的特征向量,并保存在特征向量文件中。本文特征向量文件路径为
/Users/XXX/Desktop/vector/features/CIFAR100/features。# 准备数据。 BATCH_SIZE = 100 dataloader = torch.utils.data.DataLoader(dataset, batch_size=BATCH_SIZE) # 下载模型。 model = torchvision.models.squeezenet1_1(pretrained=True).eval() # 提取特征向量,写入features_file_path。 features_file_path = "/Users/XXX/Desktop/vector/features/CIFAR100/features" feature_file = open(features_file_path, 'w') img_id = 0 for batch_number, batch in enumerate(dataloader): with torch.no_grad(): batch_imgs = batch[0] # 0: images batch_labels = batch[1] # 1: labels vector_values = model(batch_imgs).tolist() for i in range(len(vector_values)): img_label = dataset.classes[batch_labels[i].item()] # print(img_label) feature_file.write(str(img_id) + "|" + img_label + "|") vector_value = vector_values[i] assert len(vector_value) == 1000 for j in range(len(vector_value)): if j == 0: feature_file.write("{") feature_file.write(str(vector_value[j]) + ",") elif j == len(vector_value) - 1: feature_file.write(str(vector_value[j])) feature_file.write("}") else: feature_file.write(str(vector_value[j]) + ",") feature_file.write("\n") img_id = img_id + 1 print("finished extract feature vector for batch: ", batch_number) feature_file.close()单张图片得到的特征向量形式如下所示。
[2.67548513424756,2.186723470687866,2.376999616622925,2.3993351459503174,2.833254337310791, 4.141584873199463,1.0177937746047974,2.0199387073516846,2.436871512298584,1.465838789939880, 4,10.196249008178711,3.3932418823242188,6.087968826293945,7.661309242248535,7.66005373001098, 6,5.481011390686035,7.513026237487795,5.552321434020996,4.685927867889404,5.635070323944092,...]
步骤二:AnalyticDB PostgreSQL向量数据库的数据导入与查询
建表并添加向量索引。本文以使用Python的psycopg2cffi库连接数据库为例。
重要如您的数据库没有开通向量功能,请提交工单联系技术支持开通。
import os import psycopg2cffi # 注意,你可以参照以下代码设置临时环境变量。 # os.environ["PGHOST"] = "XX.XXX.XX.XXX" # os.environ["PGPORT"] = "XXXXX" # os.environ["PGDATABASE"] = "adbpg_test" # os.environ["PGUSER"] = "adbpg_test" # os.environ["PGPASSWORD"] = "adbpg_test" connection = psycopg2cffi.connect( host=os.environ.get("PGHOST", "XX.XXX.XX.XXX"), port=os.environ.get("PGPORT", "XXXXX"), database=os.environ.get("PGDATABASE", "adbpg_test"), user=os.environ.get("PGUSER", "adbpg_test"), password=os.environ.get("PGPASSWORD", "adbpg_test") ) cursor = connection.cursor() # 用于创建表的SQL语句。 create_table_sql = """ CREATE TABLE IF NOT EXISTS public.image_search ( id INTEGER NOT NULL, class TEXT, image_vector REAL[], PRIMARY KEY(id) ) DISTRIBUTED BY(id); """ # 修改向量列的存储格式为PLAIN。 alter_vector_storage_sql = """ ALTER TABLE public.image_search ALTER COLUMN image_vector SET STORAGE PLAIN; """ # 用于创建向量索引的SQL语句。 create_indexes_sql = """ CREATE INDEX ON public.image_search USING ann (image_vector) WITH (dim = '1000', hnsw_m = '100', pq_enable='0'); """ # 执行上述SQL语句。 cursor.execute(create_table_sql) cursor.execute(alter_vector_storage_sql) cursor.execute(create_indexes_sql) connection.commit()将数据集的图片特征向量导入到表中。
import io # 定义一个生成器函数,逐行处理文件中的数据。 def process_file(file_path): with open(file_path, 'r') as file: for line in file: yield line # 导入数据的SQL。 copy_command = """ COPY public.image_search (id, class, image_vector) FROM STDIN WITH (DELIMITER '|'); """ # 图片特征向量文件。 features_file_path = "/Users/XXX/Desktop/vector/features/CIFAR100/features" # 执行COPY命令。 modified_lines = io.StringIO(''.join(list(process_file(features_file_path)))) cursor.copy_expert(copy_command, modified_lines) connection.commit()选择特征向量文件中的一张图片对应的向量,进行搜索。例如,搜索ID为4999的图片。
def query_analyticdb(collection_name, vector_name, query_embedding, top_k=20): # 创建查询SQL,返回与查询向量最相近的图片,同时计算与查询向量的相似度。 query_sql = f""" SELECT id, class, l2_distance({vector_name},Array{query_embedding}::real[]) AS similarity FROM {collection_name} ORDER BY {vector_name} <-> Array{query_embedding}::real[] LIMIT {top_k}; """ # 执行查询。 connection = psycopg2cffi.connect( host=os.environ.get("PGHOST", "XX.XXX.XX.XXX"), port=os.environ.get("PGPORT", "XXXXX"), database=os.environ.get("PGDATABASE", "adbpg_test"), user=os.environ.get("PGUSER", "adbpg_test"), password=os.environ.get("PGPASSWORD", "adbpg_test") ) cursor = connection.cursor() cursor.execute(query_sql) results = cursor.fetchall() return results # 选择一条数据作为query。 def select_feature(file_path, expect_id): with open(file_path, 'r') as file: for line in file: datas = line.split('|') if datas[0] == str(expect_id): vec = '[' + datas[2][1:-2] + ']' return vec raise ValueError(f"没有对应id= {expect_id}的数据") file_path = "/Users/xxxx/Desktop/vector/features/CIFAR100/features" # 选取id为4999的图片。 query_vector = select_feature(file_path, 4999) # 查看这张图片。 # show_images_from_full_dataset(dataset, 1, 1, [4999], figsize=(1, 1)) # print(query_vector) # 执行查询。 results = query_analyticdb("image_search", "image_vector", query_vector)ID为4999的图片如下所示。

将查询结果对应的图片显示出来。
说明AnalyticDB PostgreSQL向量数据库提供的是向量近似最近邻检索功能,即加快查询的速度。
# 获取上一步返回结果中的图片id。 indices = [] for item in results: indices.append(item[0]) print(indices) # 显示图片。 show_images_from_full_dataset(dataset, 4, 5, indices)查询结果如下图所示。
