通过PAI - 灵骏分布式训练和部署Llama 2模型
技术解决方案手动部署
235
https://www.aliyun.com/solution/tech-solution/pai_lingjun
方案概览
本方案是由阿里云PAI算法团队研发,基于智算服务PAI-灵骏(Serverless版)的大模型解决方案。旨在帮助大模型开发人员快速上手灵骏产品,完成大语言模型(LLM)的高效分布式训练、三阶段指令微调(instruct-finetuning)、模型离线推理验证以及在线服务部署等完整的开发链路。
本方案以llama-2-7b模型为例,提供了基于Huggingface&DeepSpeed和MegatronLM的两套训练流程。后者在保证模型效果和Huggingface对齐的前提下,基于Megatron-LM引擎支持了数据并行、算子拆分、流水并行、序列并行、选择性激活重算、Zero显存优化、BF16混合精度、梯度检查点、Flashattention等技术,可以大幅提升大模型训练分布式效率。
这套流程可用于开发llama-2(7B,13B,70B)系列模型。同时,灵骏还支持业界各类流行的开源LLM,比如Bloom系列、Falcon系列、GLM/ChatGLM系列,以及领域大模型galactica等的高效训练和部署。并且PAI也在不断扩展所支持的模型种类。
方案架构
技术方案架构示例如下:
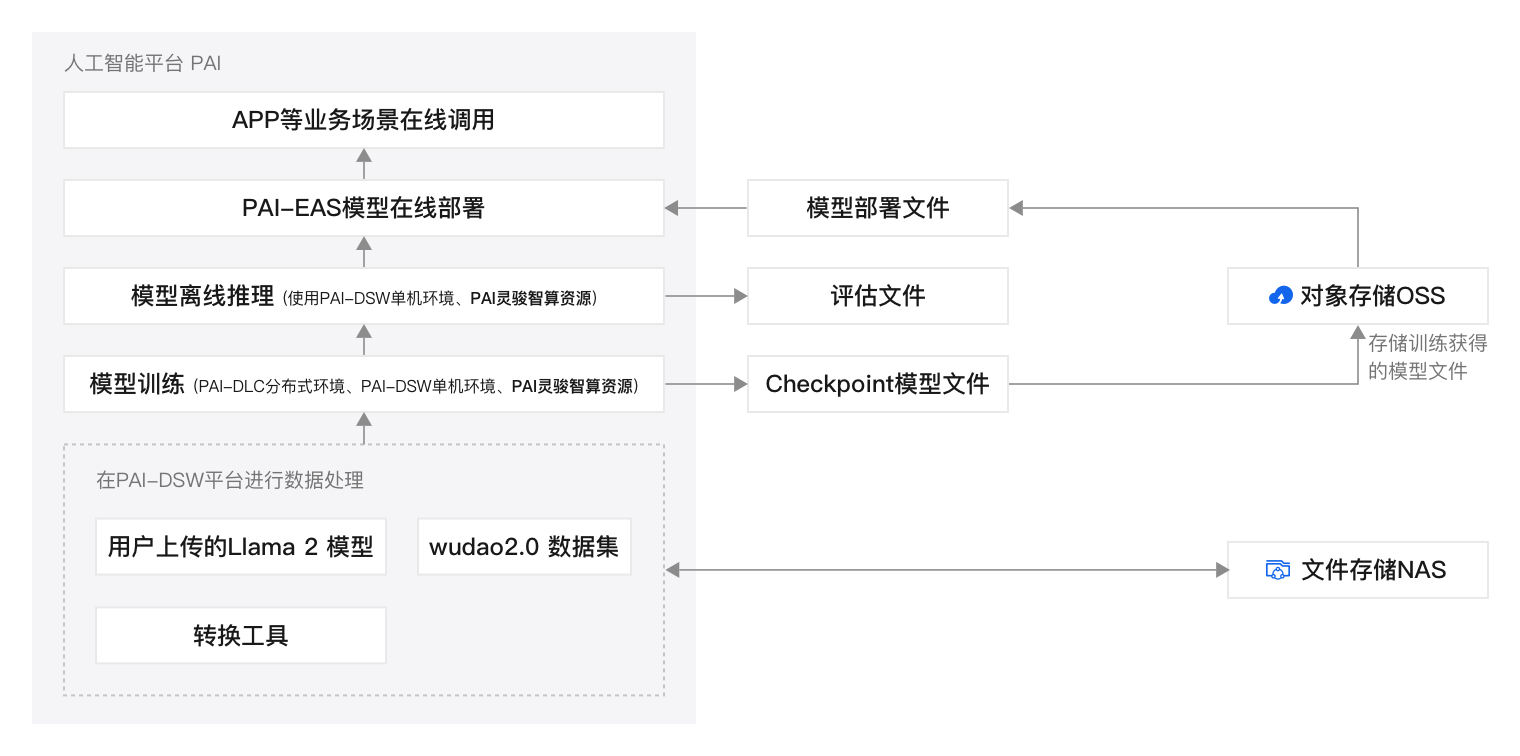
本方案包括以下功能模块:
数据准备:使用灵骏智算资源创建PAI-DSW实例,并在该实例中准备好原始模型、Huggingface&DeepSpeed或MegatronLM训练数据,供后续的模型训练使用。
模型训练和离线推理:您可以在PAI-DSW单机环境或PAI-DLC分布式环境中进行模型训练,支持Huggingface&DeepSpeed训练流程和Megatron训练流程,同时,您还可以在PAI-DSW平台离线推理模型来评估模型效果。
模型部署:模型训练完成后,将训练获得的模型部署为在线服务,然后调用模型服务验证模型推理效果。
部署准备
10
准备账号
如果您还没有阿里云账号,请访问阿里云账号注册页面,根据页面提示完成注册。阿里云账号是您使用云资源的付费实体,因此是部署方案的必要前提。
使用到智算服务PAI-灵骏(Serverless版)、智算CPFS、PAI-EAS、OSS等产品,均会产生费用,您可以通过下面链接查询到费用使用情况:
按量付费的费用包括PAI-EAS服务运行所消耗的公共资源费用和系统盘费用,以及OSS的存储费用。其中PAI-EAS的计费逻辑与单价详情请参见EAS计费说明,OSS的计费逻辑与单价详情请参见存储费用。
您可以前往AI计算资源(预付费)和智算CPFS购买页查看费用详情。
创建用于方案部署的RAM用户。
创建1个RAM用户。具体操作,请参见创建RAM用户。
为RAM用户授予以下云服务的访问权限以完成方案部署。具体操作,请参见为RAM用户授权。
云服务
需要的权限
描述
人工智能平台 PAI
AliyunPAIFullAccess
管理PAI服务的权限。
添加为PAI工作空间的成员,并授予算法开发等具有开发权限的角色。
使用PAI-DSW和PAI-DLC进行模型训练。如何为工作空间添加成员及角色,请参见管理工作空间成员。
智算服务PAI-灵骏(Serverless版)
AliyunPAIFullAccess
当前灵骏智算资源仅供白名单用户受限申请使用,如果您希望使用灵骏智算资源提交训练任务,您可先提交工单,申请添加灵骏智算资源使用白名单。
建议使用阿里云账号来购买灵骏智算资源;也可以为RAM用户添加AliyunPAIFullAccess,此时RAM用户会拥有PAI全部权限,有操作风险,请谨慎添加。
专有网络VPC
AliyunVPCFullAccess
管理专有网络VPC的权限。
云服务器ECS
AliyunECSFullAccess
管理安全组的权限。
NAS
AliyunNASFullAccess
管理NAS的权限。目前,智算CPFS还在邀测中,您可以提交工单,申请添加智算CPFS使用白名单。
对象存储OSS
AliyunOSSFullAccess
管理对象存储OSS的权限。
费用中心BSS
AliyunBSSOrderAccess
在费用中心BSS查看订单、支付订单及取消订单的权限。
开通服务
登录PAI控制台,单击开通PAI并创建默认工作空间,在弹出的开通页面中配置订单详情,配置要点如下,更多详细内容,请参见开通PAI并创建默认工作空间。
本方案地域选择:华北6(乌兰察布)。
组合开通:本方案需要使用对象存储OSS,勾选开通OSS产品,去勾选其他产品即可。
服务角色授权:单击去授权,根据界面提示为PAI完成授权,然后返回开通页面,刷新页面,继续开通操作。
开通成功后,单击进入PAI控制台。
规划网络和资源
5
规划云资源
请参考表格中的说明和方案默认示例值为每个规划项做详细规划,并在实际部署时将默认示例值修改为您的实际规划。未提及的规划项请保持默认值。
规划项 | 说明 | 方案默认示例 |
PAI | ||
地域 | 您的云服务部署的地域。 | 华北6(乌兰察布) |
镜像 | 本方案提供统一的镜像地址:
| |
数据集 | 建议配置为NAS-智算CPFS类型数据集,提升数据读写速度与性能要求。 | nas-dataset |
节点规格 | 推荐使用灵骏智算资源,资源规格为A800或A100。 | ml.gu7xf.c96m1600.8-gu108 |
对象存储OSS | ||
地域 | 您的云服务部署的地域。 | 华北6(乌兰察布) |
Bucket | 建议创建一个Bucket存储空间和目录,用来存放训练好的模型文件。 |
|
部署资源
10
规划好资源后,请按照以下步骤部署方案中的所有资源。
1、创建专有网络VPC、交换机
登录专有网络管理控制台。
在顶部菜单栏,选择华北6(乌兰察布)地域。
在左侧导航栏,单击专有网络。
在专有网络页面,单击创建专有网络。
在创建专有网络页面配置1个专有网络(VPC)和1台交换机,然后单击确定,更多详细内容,请参见创建专有网络和交换机。
2、创建安全组
3、购买灵骏智算资源(Serverless版)
创建专有资源组并购买灵骏智算资源。
登录PAI控制台。在左侧导航栏选择。
在顶部菜单栏,选择华北6(乌兰察布)地域。
单击新建资源组,在弹出的对话框中配置资源组名称后,单击确定。
单击已创建好的资源组名称,进入资源组详情页面,并单击页面右侧的新建订单。在购买页面中按照资源规划配置必要参数(本方案的节点规格选择ml.gu7xf.c96m1600.8-gu108),根据界面提示完成下单购买。
创建资源配额。
在左侧导航栏选择。
在灵骏智算资源页签,单击新增资源配额,并在新增资源配额页面配置以下关键参数,参数配置完成后,单击提交。
参数
描述
关联工作空间
选择已创建的工作空间。
来源类型
选择专有资源组。
来源
选择已创建的专有资源组。
规格/资源
单击添加,选择规格后,单击确认。
专有网络
选择已创建的专有网络、交换机和安全组。
安全组
交换机
4、创建OSS Bucket存储目录
登录OSS管理控制,在左侧导航栏,选择Bucket列表。
在Bucket列表,单击创建Bucket来创建Bucket存储空间,本方案命名为:bucket_llm。

单击已创建的Bucket名称,在Bucket详情页面单击新建目录,来创建存储目录。

5、创建智算CPFS类型数据集
创建智算CPFS文件系统。
登录PAI控制台。在左侧导航栏选择。
在资源池页面右侧,单击新建CPFS。
在文件存储概览页面,单击CPFS智算版区域的创建,然后再创建CPFS智算版对话框中,单击确认创建。
在智算CPFS(按量计费)页面中选择集群编号和配置容量后,根据界面提示完成购买。
新建智算CPFS数据集。
单击左侧导航中的工作空间列表,单击待提交任务的工作空间名称进入工作空间后,在AI资产管理>数据集页面单击创建数据集,其中:
选择数据存储:请选择为阿里云文件存储(智算CPFS)。
选择文件系统:请在下拉框中选择智算CPFS的文件系统(bmcpfs开头的文件系统)。
其他参数的配置与通用数据集创建一致,详情请参见创建及管理数据集。
6、创建PAI-DSW实例
在默认工作空间中创建DSW实例,其中关键参数配置如下,其他参数取默认配置即可。更多详细内容,请参见创建DSW实例。
参数 | 描述 |
地域及可用区 | 本方案选择:华北6(乌兰察布)。 |
实例名称 | 您可以自定义实例名称,本方案示例为:dsw_test_01。 |
资源配额 | 本方案选择已创建的资源配额,并配置以下参数:
|
存储配置 | 单击共享数据集,选择已创建的CPFS类型数据集。 |
选择镜像 | 在镜像URL页签配置镜像地址,您可以任意选择一个镜像地址:
|
准备模型
20
本方案给出了以下三种下载模型的方式,您可以根据需要选择其中一种。
从ModelScope社区下载模型
进入PAI-DSW开发环境。
登录PAI控制台。
在左侧导航栏单击工作空间列表,在工作空间列表页面中单击待操作的工作空间名称,进入对应工作空间内。
在页面左上方,选择使用服务的地域:华北6(乌兰察布)。
在左侧导航栏,选择。
单击目标实例操作列下的打开。
在JupyterLab页签的Launcher页面,单击快速开始区域Notebook下的Python3。
下载llama-2模型。
在Notebook中执行以下命令,安装ModelScope。
pip install modelscope==1.7.1系统输出的结果中出现的类似如下WARNING信息和ERROR信息可以忽略。
WARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts. tensorboard 2.12.2 requires protobuf>=3.19.6, but you have protobuf 3.18.3 which is incompatible.执行命令,下载llama-2模型。您可以根据下表中的模型名称、版本信息并通过如下代码下载模型文件。
模型
模型链接
模型名称
版本
Llama-2-7b
modelscope/Llama-2-7b-ms
v1.0.1
Llama-2-7b-chat
modelscope/Llama-2-7b-chat-ms
v1.0.1
Llama-2-13b
modelscope/Llama-2-13b-ms
v1.0.0
Llama-2-13b-chat
modelscope/Llama-2-13b-chat-ms
v1.0.0
# ### Loading Model and Tokenizer from modelscope.hub.snapshot_download import snapshot_download model_dir = snapshot_download('modelscope/Llama-2-7b-ms', 'v1.0.1') # 获取下载路径。 print(model_dir) # /root/.cache/modelscope/hub/modelscope/Llama-2-7b-ms在顶部菜单栏,单击Terminal页签,在欢迎使用DSW Terminal页面中单击创建Terminal。
执行以下命令,将已下载的Checkpoint文件移动到对应文件夹下。
mkdir -p /mnt/workspace/llama2-ckpts/${后缀为hf的ckpt文件夹} # mkdir -p /mnt/workspace/llama2-ckpts/Llama-2-7b-hf cp -r ${在此处填写获取的模型路径}/* /mnt/workspace/llama2-ckpts/${后缀为hf的ckpt文件夹} # cp -r /root/.cache/modelscope/hub/modelscope/Llama-2-7b-ms/* /mnt/workspace/llama2-ckpts/Llama-2-7b-hf
从Huggingface社区下载模型
在PAI-DSW的Terminal中执行以下命令下载模型文件。
mkdir /mnt/workspace/llama2-ckpts
cd /mnt/workspace/llama2-ckpts
git clone https://huggingface.co/meta-llama/Llama-2-7b
git clone https://huggingface.co/meta-llama/Llama-2-13b
git clone https://huggingface.co/meta-llama/Llama-2-70b准备数据
20
建议您在使用灵骏智算资源创建的DSW实例中准备预训练数据。本方案以WuDao2.0数据集(该数据集仅供研究使用)为例,介绍数据预处理流程。
下载WuDaoCorpora2.0开源数据集到
/mnt/workspace/llama2-datasets工作目录下。PAI提供了部分样例数据作为示例,您可以在PAI-DSW的Terminal中执行以下命令下载并解压数据集。假设解压后的文件夹命名为wudao_200g。mkdir /mnt/workspace/llama2-datasets/ cd /mnt/workspace/llama2-datasets/ wget https://atp-modelzoo.oss-cn-hangzhou.aliyuncs.com/release/datasets/WuDaoCorpus2.0_base_sample.tgz tar zxvf WuDaoCorpus2.0_base_sample.tgz预处理数据。PAI为HuggingFace&DeepSpeed训练和MegatronLM训练分别准备了数据预处理流程,您可以根据自己的需要选择不同的处理方式。
准备Huggingface&DeepSpeed训练数据
在Terminal中执行以下脚本,对Wudao数据执行数据集清洗并进行文件格式转换,最终生成汇总的merged_wudao_cleaned.json文件。
#! /bin/bash set -ex # 请在此处设置原始数据所在路径。 data_dir=/mnt/workspace/llama2-datasets/wudao_200g # 开始数据清洗流程。 dataset_dir=$(dirname $data_dir) mkdir -p ${dataset_dir}/cleaned_wudao_dataset cd ${dataset_dir}/cleaned_wudao_dataset wget https://atp-modelzoo-wlcb-pai.oss-cn-wulanchabu.aliyuncs.com/release/models/pai-megatron-patch/llama2-codes/preprocess_wudao2.py python preprocess_wudao2.py -i ${data_dir} -o ${dataset_dir}/cleaned_wudao_dataset -p 32 # 合并清洗后的数据,移除过程数据。 mkdir ${dataset_dir}/wudao cd ${dataset_dir}/wudao find ${dataset_dir}/cleaned_wudao_dataset -name "*.json" -exec cat {} + > ${dataset_dir}/wudao/merged_wudao_cleaned.json rm -rf ${dataset_dir}/cleaned_wudao_dataset脚本执行完成后,llama2-datasets目录的文件结构如下。新增了一个wudao文件夹:
llama2-datasets ├── wudao_200g └── wudao └── merged_wudao_cleaned.json在Terminal中执行以下命令,利用生成的merged_wudao_cleaned.json文件生成预训练所需的训练集和验证集。您需要在下面的脚本中设置训练集占比,比如设置TRAIN_RATE=90,表示训练集占比为90%。
# 请在此处设置训练集的占比。 TRAIN_RATE=90 # 开始拆分训练集、测试集,移除过程数据。 NUM=$(sed -n '$=' ${dataset_dir}/wudao/merged_wudao_cleaned.json) TRAIN_NUM=$(($(($NUM/100))*$TRAIN_RATE)) echo "total line of dataset is $NUM, data will be split into 2 parts, $TRAIN_NUM samples for training, $(($NUM-$TRAIN_NUM)) for validation" split -l $TRAIN_NUM --numeric-suffixes --additional-suffix=.json ${dataset_dir}/wudao/merged_wudao_cleaned.json ${dataset_dir}/wudao/ mkdir ${dataset_dir}/wudao_huggingface cd ${dataset_dir}/wudao_huggingface mv ${dataset_dir}/wudao/00.json ${dataset_dir}/wudao_huggingface/wudao200g_train.json mv ${dataset_dir}/wudao/01.json ${dataset_dir}/wudao_huggingface/wudao200g_valid.json rm -rf ${dataset_dir}/wudao/命令执行完成后,llama2-datasets目录的文件结构如下,新增了两个JSON文件。
llama2-datasets ├── wudao_200g ├── wudao_train.json └── wudao_valid.json
完成以上操作步骤后Huggingface的数据已准备完成。您可以执行后续章节中的Huggingface&Deepspeed训练流程,详情请参见Huggingface&DeepSpeed训练流程章节。
准备MegatronLM训练数据
MMAP数据是一种预先执行tokenize的数据格式,可以减少训练微调过程中等待数据读入的时间,当数据量较大时优势更显著。您可以按照以下操作步骤准备数据。
执行准备Huggingface&DeepSpeed训练数据的操作步骤生成JSON文件。
在Terminal中执行以下命令,对Wudao数据执行数据集清洗并进行文件格式转换,最终生成汇总的merged_wudao_cleaned.json。
#! /bin/bash set -ex # 请在此处设置原始数据所在路径。 data_dir=/mnt/workspace/llama2-datasets/wudao_200g # 开始数据清洗流程。 dataset_dir=$(dirname $data_dir) mkdir -p ${dataset_dir}/cleaned_wudao_dataset cd ${dataset_dir}/cleaned_wudao_dataset wget https://atp-modelzoo-wlcb-pai.oss-cn-wulanchabu.aliyuncs.com/release/models/pai-megatron-patch/llama2-codes/preprocess_wudao2.py # 此处与上一节不同,增加了key参数设为text。 python preprocess_wudao2.py -i ${data_dir} -o ${dataset_dir}/cleaned_wudao_dataset -k text -p 32 # 合并清洗后的数据。 mkdir ${dataset_dir}/wudao cd ${dataset_dir}/wudao find ${dataset_dir}/cleaned_wudao_dataset -name "*.json" -exec cat {} + > ${dataset_dir}/wudao/merged_wudao_cleaned.json rm -rf ${dataset_dir}/cleaned_wudao_dataset命令执行完成后,llama2-datasets目录的文件结构如下,新增一个wudao文件夹:
llama2-datasets ├── wudao_200g └── wudao └── merged_wudao_cleaned.json在Terminal中执行以下命令,利用生成的merged_wudao_cleaned.json文件将数据拆分成若干组并进行压缩,以便于后续实现多线程处理。
apt-get update apt-get install zstd # 此处设置分块数为10,如数据处理慢可设置稍大。 NUM_PIECE=10 # 对merged_wudao_cleaned.json文件进行处理。 mkdir -p ${dataset_dir}/cleaned_zst/ # 查询数据总长度,对数据进行拆分。 NUM=$(sed -n '$=' ${dataset_dir}/wudao/merged_wudao_cleaned.json) echo "total line of dataset is $NUM, data will be split into $NUM_PIECE pieces for processing" NUM=`expr $NUM / $NUM_PIECE` echo "each group is processing $NUM sample" split_dir=${dataset_dir}/split mkdir $split_dir split -l $NUM --numeric-suffixes --additional-suffix=.jsonl ${dataset_dir}/wudao/merged_wudao_cleaned.json $split_dir/ # 数据压缩。 o_path=${dataset_dir}/cleaned_zst/ mkdir -p $o_path files=$(ls $split_dir/*.jsonl) for filename in $files do f=$(basename $filename) zstd -z $filename -o $o_path/$f.zst & done rm -rf $split_dir rm ${dataset_dir}/wudao/merged_wudao_cleaned.json命令执行完成后,llama2-datasets目录的文件结构如下。新增了一个cleaned_zst文件夹,每个子文件夹里有10个压缩文件。
llama2-datasets ├── wudao_200g ├── wudao └── cleaned_zst ├── 00.jsonl.zst │ ... └── 09.jsonl.zst制作MMAP格式的预训练数据集。
前往PAI-Megatron-Patch页面获取Megatron模型训练工具PAI-Megatron-Patch源代码。
在DSW实例页面,按照下图操作指引,将已获取的工具和源代码上传到
/mnt/workspace/下,并分别解压到当前目录。
在Terminal中执行命令将数据转换成MMAP格式。命令执行成功后,在
/mnt/workspace/llama2-datasets/wudao目录下生成.bin和.idx文件。# 请在此处设置数据集路径和工作路径。 export dataset_dir=/mnt/workspace/llama2-datasets export WORK_DIR=/mnt/workspace # 分别为训练集、验证集生成mmap格式预训练数据集。 cd ${WORK_DIR}/PAI-Megatron-Patch/toolkits/pretrain_data_preprocessing bash run_make_pretraining_dataset.sh \ /root/Megatron-LM-23.04 \ ${WORK_DIR}/PAI-Megatron-Patch/ \ ${dataset_dir}/cleaned_zst/ \ llamabpe \ ${dataset_dir}/wudao/ \ ${WORK_DIR}/llama2-ckpts/llama-2-7b-hf rm -rf ${dataset_dir}/cleaned_zst其中运行run_make_pretraining_dataset.sh脚本输入的五个启动参数说明如下:
参数
描述
MEGATRON_PATH=$1
设置开源Megatron的代码路径。
MEGATRON_PATCH_PATH=$2
设置Megatron Patch的代码路径。
input_data_dir=$3
打包后的wudao数据集的文件夹路径。
tokenizer=$4
指定分词器的类型为llamabpe。
output_data_dir=$5
指定输出结果的保存路径。
load_dir=$6
tokenizer_config.json文件路径。
脚本执行完成后,llama2-datasets目录的文件结构如下。
llama2-datasets ├── wudao_200g └── wudao ├── wudao_llamabpe_text_document.bin └── wudao_llamabpe_text_document.idx
完成以上操作步骤后MegatronLM的数据已准备完成。您可以执行后续章节中的Megatron训练流程,详情请参见Megatron训练流程章节。
为了方便您试用该方案,PAI也提供了已经处理好的小规模样本数据,您可以在PAI-DSW的Terminal中执行以下命令下载样本数据。
cd /mnt/workspace/llama2-datasets
wget https://atp-modelzoo-wlcb-pai.oss-cn-wulanchabu.aliyuncs.com/release/models/pai-megatron-patch/llama2-datasets/wudao_train.json
wget https://atp-modelzoo-wlcb-pai.oss-cn-wulanchabu.aliyuncs.com/release/models/pai-megatron-patch/llama2-datasets/wudao_valid.json
mkdir -p /mnt/workspace/llama2-datasets/wudao
cd /mnt/workspace/llama2-datasets/wudao
wget https://atp-modelzoo-wlcb-pai.oss-cn-wulanchabu.aliyuncs.com/release/models/pai-megatron-patch/llama2-datasets/wudao_llamabpe_text_document.bin
wget https://atp-modelzoo-wlcb-pai.oss-cn-wulanchabu.aliyuncs.com/release/models/pai-megatron-patch/llama2-datasets/wudao_llamabpe_text_document.idxHuggingface&DeepSpeed训练流程
60
基于上述章节已下载好的模型和训练数据,您可以在PAI-DSW环境中调试预训练模型,也可以在PAI-DLC环境中配置多机多卡分布式任务。
使用DSW调试训练模型
在PAI-DSW单机环境的Terminal中下载并运行run_ds_train_huggingface_llama.sh脚本。DSW单机运行示例如下:
cd /mnt/workspace
mkdir test_llama2_hf
cd test_llama2_hf
export WORK_DIR=/mnt/workspace/
wget https://atp-modelzoo-wlcb-pai.oss-cn-wulanchabu.aliyuncs.com/release/models/pai-megatron-patch/llama2-codes/ds_config_TEMPLATE.json
wget https://atp-modelzoo-wlcb-pai.oss-cn-wulanchabu.aliyuncs.com/release/models/pai-megatron-patch/llama2-codes/ds_train_huggingface_llama.py
wget https://atp-modelzoo-wlcb-pai.oss-cn-wulanchabu.aliyuncs.com/release/models/pai-megatron-patch/llama2-codes/run_ds_train_huggingface_llama.sh
bash run_ds_train_huggingface_llama.sh \
dsw \
7B \
1 \
2 \
1e-5 \
2048 \
bf16 \
2 \
true \
${WORK_DIR}/llama2-datasets/wudao_train.json \
${WORK_DIR}/llama2-datasets/wudao_valid.json \
${WORK_DIR}/llama2-ckpts/Llama-2-7b-hf \
2 \
${WORK_DIR}/output_llama2需要传入的参数列表如下:
参数 | 描述 |
ENV=$1 | 配置运行环境:
|
MODEL_SIZE=$2 | 模型结构参数量级:7B、13B或70B。 |
BATCH_SIZE=$3 | 每卡训练一次迭代样本数:4或8。 |
GA_STEPS=$4 | 梯度累积step数。 |
LR=$5 | 学习率:1e-5或5e-5。 |
SEQ_LEN=$6 | 序列长度:2048。 |
PR=$7 | 训练精度:fp16或bf16。 |
ZERO=$8 | DeepSpeed ZERO降显存:1、2、3。 |
GC=$9 | 是否使用gradient-checkpointing:
|
TRAIN_DATASET_PATH=${10} | 训练集路径,支持单一文件或者文件夹形式输入。 |
VALID_DATASET_PATH=${11} | 验证集路径,支持单一文件或者文件夹形式输入。 |
PRETRAIN_CHECKPOINT_PATH=${12} | 预训练模型路径。 |
EPOCH=${13} | 训练epoch数。 |
OUTPUT_BASEPATH=${14} | 训练输出文件路径。 |
DLC分布式训练模型
在DSW单机环境调试完成后,您可以在DLC环境中配置多机多卡分布式任务。具体操作步骤如下。
登录PAI控制台。
在左侧导航栏单击工作空间列表,在工作空间列表页面中单击待操作的工作空间名称,进入对应工作空间内。
在工作空间页面的左侧导航栏选择,在分布式训练任务页面中单击新建任务,进入新建任务页面。
在新建任务页面,配置以下关键参数,其他参数取默认配置即可。更多详细内容,请参见创建训练任务。
参数
描述
任务名称
自定义任务名称。本方案配置为:test_megatron_dlc。
节点镜像
选中镜像地址并在文本框中输入镜像地址,您可以任意选择一种镜像地址:
torch1.12版本镜像:
pai-image-manage-registry.cn-wulanchabu.cr.aliyuncs.com/pai/pytorch-training:1.12-ubuntu20.04-py3.10-cuda11.3-megatron-patch-llm
torch2.0版本镜像:
pai-image-manage-registry.cn-wulanchabu.cr.aliyuncs.com/pai/pytorch-training:2.0-ubuntu20.04-py3.10-cuda11.8-megatron-patch-llm
数据集配置
与DSW配置同一个CPFS类型数据集。
执行命令
配置以下命令,其中run_pretrain_megatron_bloom.sh脚本输入的启动参数与DSW单机训练模型一致。
cd /mnt/workspace mkdir test_llama2_hf cd test_llama2_hf export WORK_DIR=/mnt/workspace/ wget https://atp-modelzoo-wlcb-pai.oss-cn-wulanchabu.aliyuncs.com/release/models/pai-megatron-patch/llama2-codes/ds_config_TEMPLATE.json wget https://atp-modelzoo-wlcb-pai.oss-cn-wulanchabu.aliyuncs.com/release/models/pai-megatron-patch/llama2-codes/ds_train_huggingface_llama.py wget https://atp-modelzoo-wlcb-pai.oss-cn-wulanchabu.aliyuncs.com/release/models/pai-megatron-patch/llama2-codes/run_ds_train_huggingface_llama.sh sed -i 's|mm = mmap.mmap(fid.fileno(), bytes, access=acc, offset=start)|mm = mmap.mmap(fid.fileno(), bytes, flags=mmap.MAP_PRIVATE, offset=start)|g' /opt/conda/lib/python3.8/site-packages/numpy/core/memmap.py sed -i "s|barrier_timeout: float = 300|barrier_timeout: float = 36000|g" /opt/conda/lib/python3.8/site-packages/torch/distributed/elastic/utils/store.py bash run_ds_train_huggingface_llama.sh \ dlc \ 7B \ 1 \ 2 \ 1e-5 \ 2048 \ fp16 \ 2 \ true \ ${WORK_DIR}/llama2-datasets/wudao_train.json \ ${WORK_DIR}/llama2-datasets/wudao_valid.json \ ${WORK_DIR}/llama2-ckpts/Llama-2-7b-hf \ 2 \ ${WORK_DIR}/output_llama2资源配额
本方案选择已创建的灵骏智算资源配额。
框架
选择PyTorch。
任务资源
为Worker节点配置以下参数:
节点数量:2,如果需要多机训练,配置节点数量为需要的机器数即可。
CPU(核数):90
说明CPU核数不能大于96。
GPU(卡数):8
内存(GiB):1024
共享内存(GiB):1024
单击提交,页面自动跳转到容器训练任务页面。您可以单击任务名称,在任务详情页面查看任务执行状态。当状态变为已成功时,表明训练任务执行成功。
Megatron训练流程
60
将Huggingface格式的模型文件转换为Megatron格式。
自行将Huggingface版本模型转换成Megatron模型
前往PAI-Megatron-Patch页面获取Megatron模型训练工具PAI-Megatron-Patch源代码,在Terminal中执行以下命令,使用PAI提供的下载地址来获取Huggingface版本的模型权重,并按照如下流程完成格式转换。
cd /mnt/workspace/ mkdir llama2-ckpts cd llama2-ckpts wget https://atp-modelzoo-wlcb-pai.oss-cn-wulanchabu.aliyuncs.com/release/models/pai-megatron-patch/llama2-ckpts/Llama-2-7b-hf.tgz tar -zxf Llama-2-7b-hf.tgz mv Llama-2-7b-hf llama2-7b-hf cd /mnt/workspace/PAI-Megatron-Patch/toolkits/model_checkpoints_convertor/llama sh model_convertor.sh \ /root/Megatron-LM-23.04 \ /mnt/workspace/llama2-ckpts/llama2-7b-hf \ /mnt/workspace/llama2-ckpts/llama2-7b-hf-to-megatron-tp1-pp1 \ 1 \ 1 \ llama-7b \ 0 \ false下载转换好的Megatron模型
为方便您试用该方案,PAI提供了转换好格式的模型。您可以在DSW实例页面顶部菜单栏,单击Terminal页签,并在Terminal中执行以下命令下载模型即可。
cd /mnt/workspace/ mkdir llama2-ckpts cd llama2-ckpts wget https://atp-modelzoo-wlcb-pai.oss-cn-wulanchabu.aliyuncs.com/release/models/pai-megatron-patch/llama2-ckpts/llama-2-7b-hf-to-megatron-tp1-pp1.tgz tar -zxf llama-2-7b-hf-to-megatron-tp1-pp1.tg继续预训练模型。您可以在PAI-DSW单机环境中训练模型,后续您也可以在PAI-DLC环境中提交多机多卡分布式任务。任务执行成功后,将模型文件输出到
/mnt/workspace/output_megatron_llama2/目录下。DSW单机预训练模型
DSW单机运行示例如下:
export WORK_DIR=/mnt/workspace cd ${WORK_DIR}/PAI-Megatron-Patch/examples/llama2 sh run_pretrain_megatron_llama.sh \ dsw \ /root/Megatron-LM-23.04 \ ${WORK_DIR}/PAI-Megatron-Patch \ 7B \ 1 \ 8 \ 1e-5 \ 1e-6 \ 2048 \ 80 \ 0 \ fp16 \ 1 \ 1 \ sel \ true \ false \ false \ 100000 \ ${WORK_DIR}/llama2-datasets/wudao/wudao_llamabpe_text_document \ ${WORK_DIR}/llama2-ckpts/llama2-7b-hf-to-megatron-tp1-pp1 \ 100000000 \ 10000 \ ${WORK_DIR}/output_megatron_llama2/其中运行run_pretrain_megatron_llama.sh脚本需要传入的参数说明如下:
参数
描述
ENV=$1
配置运行环境:
dsw
dlc
MEGATRON_PATH=$2
设置开源Megatron的代码路径。
MEGATRON_PATCH_PATH=$3
设置Megatron Patch的代码路径。
MODEL_SIZE=$4
模型结构参数量级:7B、13B或70B。
BATCH_SIZE=$5
每卡训练一次迭代样本数:4或8。
GLOBAL_BATCH_SIZE=$6
全局Batch Size。
LR=$7
学习率:1e-5或5e-5。
MIN_LR=$8
最小学习率:1e-6或5e-6。
SEQ_LEN=$9
序列长度。
PAD_LEN=${10}
Padding长度:100。
EXTRA_VOCAB_SIZE=${11}
词表扩充大小。
PR=${12}
训练精度:fp16或bf16。
TP=${13}
模型并行度。
PP=${14}
流水并行度。
AC=${15}
激活检查点模式:
full
sel
DO=${16}
是否使用Megatron版Zero-1降显存优化器:
true
false
FL=${17}
是否打开Flash Attention:
true
false
SP=${18}
是使用序列并行:
true
false
SAVE_INTERVAL=${19}
保存CheckPoint文件的间隔。
DATASET_PATH=${20}
训练数据集路径。
PRETRAIN_CHECKPOINT_PATH=${21}
预训练模型路径。
TRAIN_TOKENS=${22}
训练Tokens。
WARMUP_TOKENS=${23}
预热Token数。
OUTPUT_BASEPATH=${24}
训练输出文件路径。
DLC分布式预训练模型
在DSW单机环境调试完成后,您可以在DLC环境中配置多机多卡分布式任务。其中执行命令配置如下,使用和DSW相同的训练脚本run_pretrain_megatron_llama.sh。其他参数配置详情,请参见Huggingface&DeepSpeed训练流程。
export WORK_DIR=/mnt/workspace cd ${WORK_DIR}/PAI-Megatron-Patch/examples/llama2 bash run_pretrain_megatron_llama.sh \ dlc \ /root/Megatron-LM-23.04 \ ${WORK_DIR}/PAI-Megatron-Patch \ 7B \ 1 \ 16 \ 1e-5 \ 1e-6 \ 2048 \ 80 \ 0 \ fp16 \ 1 \ 1 \ sel \ true \ false \ false \ 100000 \ ${WORK_DIR}/llama2-datasets/wudao/wudao_llamabpe_text_document \ ${WORK_DIR}/llama2-ckpts/llama2-7b-hf-to-megatron-tp1-pp1 \ 100000000 \ 10000 \ ${WORK_DIR}/output_megatron_llama2/有监督微调模型。您可以在PAI-DSW单机环境中训练模型,后续您也可以在PAI-DLC环境中提交多机多卡分布式任务。任务执行成功后,将模型文件输出到
/mnt/workspace/output_megatron_llama2/目录下。DSW单机微调模型
DSW单机运行示例如下:
export WORK_DIR=/mnt/workspace cd ${WORK_DIR}/PAI-Megatron-Patch/examples/llama2 sh run_finetune_megatron_llama.sh \ dsw \ /root/Megatron-LM-23.04 \ ${WORK_DIR}/PAI-Megatron-Patch \ 7B \ 1 \ 1e-5 \ 1e-6 \ 2048 \ 80 \ 0 \ bf16 \ 1 \ 1 \ sel \ true \ false \ false \ ${WORK_DIR}/llama2-datasets/wudao_train.json \ ${WORK_DIR}/llama2-datasets/wudao_valid.json \ ${WORK_DIR}/llama2-ckpts/llama2-7b-hf-to-megatron-tp1-pp1 \ 2 \ ${WORK_DIR}/output_megatron_llama2/其中运行run_finetune_megatron_llama.sh脚本需要传入的参数说明如下:
参数
描述
ENV=$1
运行环境:
dlc
dsw
MEGATRON_PATH=$2
设置开源Megatron的代码路径。
MEGATRON_PATCH_PATH=$3
设置Megatron Patch的代码路径。
MODEL_SIZE=$4
模型结构参数量级:7B、13B或70B。
BATCH_SIZE=$5
每卡训练一次迭代样本数:4、8。
LR=$6
学习率:1e-5、5e-5。
MIN_LR=$7
最小学习率:1e-6、5e-6。
SEQ_LEN=$8
序列长度。
PAD_LEN=$9
Padding序列长度:100。
EXTRA_VOCAB_SIZE=${10}
词表扩充大小。
PR=${11}
训练精度:fp16、bf16。
TP=${12}
模型并行度。
PP=${13}
流水并行度。
AC=${14}
激活检查点模式:full或sel。
DO=${15}
是否使用Megatron版Zero-1降显存优化器:
true
false
FL=${16}
是否打开Flash Attention:
true
false
SP=${17}
是否使用序列并行:
true
false
TRAIN_DATASET_PATH=${18}
训练数据集路径。
VALID_DATASET_PATH=${19}
验证数据集路径。
PRETRAIN_CHECKPOINT_PATH=${20}
预训练模型路径。
EPOCH=${21}
训练迭代轮次。
OUTPUT_BASEPATH=${22}
训练输出文件路径。
DLC分布式微调模型
在DSW单机环境调试完成后,您可以在DLC环境中配置多机多卡分布式任务。其中执行命令配置如下,使用和DSW相同的训练脚本run_finetune_megatron_llama.sh。其他参数配置详情,请参见Huggingface&DeepSpeed训练流程。
export WORK_DIR=/mnt/workspace cd ${WORK_DIR}/PAI-Megatron-Patch/examples/llama2 sh run_finetune_megatron_llama.sh \ dlc \ /root/Megatron-LM-23.04 \ ${WORK_DIR}/PAI-Megatron-Patch \ 7B \ 1 \ 1e-5 \ 1e-6 \ 2048 \ 80 \ 0 \ fp16 \ 1 \ 1 \ sel \ true \ false \ false \ ${WORK_DIR}/llama2-datasets/wudao_train.json \ ${WORK_DIR}/llama2-datasets/wudao_valid.json \ ${WORK_DIR}/llama2-ckpts/llama2-7b-hf-to-megatron-tp1-pp1 \ 2 \ ${WORK_DIR}/output_megatron_llama2/
离线推理模型
15
模型训练完成后,您可以离线推理模型来评估模型效果。根据上面不同的训练流程,PAI也提供了对应的HuggingFace&DeepSpeed和MegatronLM两种格式的推理链路。
使用HuggingFace&DeepSpeed离线推理模型
对于使用Huggingface&DeepSpeed训练流程获得的模型,可以使用HuggingFace进行离线推理。您可以参考如下文档进行离线推理:
在Terminal中的任意目录下创建infer.py文件,文件内容如下。执行infer.py文件进行模型离线推理,根据推理结果来评估模型效果。
import torch
import transformers
from transformers import LlamaTokenizer, LlamaForCausalLM
model = "/mnt/workspace/output_llama2/checkpoint/dswXXX/checkpoinXXX/"
print(model)
tokenizer = LlamaTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map="auto",
)
sequences = pipeline(
"The weather today is",
max_length=200,
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
)
print(sequences)
for seq in sequences:
print(f"Result: {seq['generated_text']}")其中:model配置为Huggingface&DeepSpeed训练流程生成的模型路径。
使用MegatronLM离线推理模型
对于使用MegatronLM训练流程获得的模型,可以直接使用MegatronLM框架进行离线推理。
下载测试样本:pred_input.jsonl,并上传到DSW的
/mnt/workspace目录下。【说明】推理的数据组织形式需要与微调时的保持一致。
由于模型保存的路径下缺少tokenizer依赖的文件,您需要将微调前模型路径下的所有JSON文件和tokenizer.model文件拷贝到保存模型的路径(位于
{OUTPUT_BASEPATH }/checkpoint的下一级目录下,与latest_checkpointed_iteration.txt同级。命令中的路径需替换为您的实际路径。cd /mnt/workspace/llama2-ckpts/llama2-7b-hf-to-megatron-tp1-pp1 cp *.json /mnt/workspace/output_megatron_llama2/checkpoint/dswXXX/在Terminal中执行命令完成模型离线推理,推理结果输出到
/mnt/workspace/llama2_pred.txt文件,您可以根据推理结果来评估模型效果。【说明】:您需要将run_text_generation_megatron_llama.sh脚本中的参数CUDA_VISIBLE_DEVICES设置为0;参数GPUS_PER_NODE设置为1。
export WORK_DIR=/mnt/workspace cd ${WORK_DIR}/PAI-Megatron-Patch/examples/llama2 bash run_text_generation_megatron_llama.sh \ dsw \ /root/Megatron-LM-23.04 \ ${WORK_DIR}/PAI-Megatron-Patch \ /mnt/workspace/output_megatron_llama2/checkpoint/dswXXX \ 7B \ 1 \ 1 \ 1024 \ 1024 \ 0 \ fp16 \ 10 \ 512 \ 512 \ ${WORK_DIR}/pred_input.jsonl \ ${WORK_DIR}/llama2_pred.txt \ 0 \ 1.0 \ 1.2其中运行run_text_generation_bloom.sh脚本输入的启动参数说明如下:
参数
描述
ENV=$1
运行环境:
dlc
dsw
MEGATRON_PATH=$2
设置开源Megatron的代码路径。
MEGATRON_PATCH_PATH=$3
设置Megatron Patch的代码路径。
CHECKPOINT_PATH=$5
模型微调阶段的模型保存路径。
【注意】该路径需要替换为您自己的模型路径。
MODEL_SIZE=$6
模型结构参数量级:7B、13B或70B。
TP=$7
模型并行度。
【注意】该参数配置为1,可以使用单卡进行推理;如果该参数值大于1,则需要使用相应的卡数进行推理。
BS=$8
每卡推理一次迭代样本数:1、4、8。
SEQ_LEN=$9
序列长度:256、512、1024。
PAD_LEN=$9
PAD长度:需要将文本拼接的长度。
EXTRA_VOCAB_SIZE=${10}
模型转换时增加的token数量。
PR=${11}
推理采用的精度:fp16,bf16。
TOP_K=${12}
采样策略中选择排在前面的候选词数量(0-n): 0、5、10、20。
INPUT_SEQ_LEN=${13}
输入序列长度:512。
OUTPUT_SEQ_LEN=${14}
输出序列长度:256。
INPUT_FILE=${15}
需要推理的文本文件:input.txt,每行为一个样本。
OUTPUT_FILE=${16}
推理输出的文件:output.txt。
TOP_P=${17}
采样策略中选择排在前面的候选词百分比(0,1):0、0.85、0.95。
【说明】TOP_K和TOP_P必须有一个为0。
TEMPERATURE=${18}
采样策略中温度惩罚:1-n。
REPETITION_PENALTY=${19}
避免生成是产生大量重复,可以设置为(1-2)。默认为1.2。
将模型上传到OSS Bucket存储空间
本方案以Megatron训练流程获得的模型为例,来说明如何将模型文件上传到OSS存储空间:
10
在Terminal中执行以下命令将原始模型目录文件替换成训练获得的模型文件,您的模型地址以实际为准。
cp /mnt/workspace/output_megatron_llama2/checkpoint/dswXXX/iter_XXX/mp_rank_00/model_rng.pt /mnt/workspace/llama2-ckpts/llama2-7b-hf-to-megatron-tp1-pp1/release/mp_rank_00/model_rng.pt在DSW中安装ossutil并完成配置,详情请参见安装ossutil。
在DSW的Terminal中,执行以下命令将模型文件上传到OSS Bucket存储空间,更多详细内容,请参见命令行工具ossutil命令参考。
cd /mnt/workspace/llama2-ckpts ossutil64 cp -r llama2-7b-hf-to-megatron-tp1-pp1/ oss://examplebucket/exampledirectory/
如果需要部署使用Huggingface&DeepSpeed训练流程获得的模型文件,您需要将/mnt/workspace/output_llama2/checkpoint/dswXXX/checkpointXXX/global_stepXXX/mp_rank_00_model_states.pt文件拷贝到上一层包含config.json文件的目录中,并重命名为pytorch_model.bin。然后参照上述操作步骤将/mnt/workspace/output_llama2/checkpoint/dswXXX/checkpointXXX/目录下的文件上传到OSS Bucket存储空间。
部署模型服务
15
BladeLLM是阿里云PAI平台提供的大模型部署框架,支持主流LLM模型结构,并内置模型量化压缩、BladeDISC编译等优化技术用于加速模型推理。 使用BladeLLM的预构建镜像,能够便捷地在PAI-EAS平台部署大模型推理服务。本方案以使用Megatron训练流程获得的模型为例,来说明如何部署模型服务,具体操作步骤如下:
任意选择一种方式部署服务。
方式一:使用PAI控制台
前往部署服务页面,在华北6(乌兰察布)地域部署模型服务,其中关键参数配置如下,其他参数取默认配置即可。
参数
描述
服务名称
自定义模型服务名称,同地域内唯一。本方案配置为:blade_llm_llama2_server。
部署方式
本方案选择:镜像部署服务。
镜像选择
选择镜像地址,在本文框中配置镜像地址:
eas-registry-vpc.cn-wulanchabu.cr.aliyuncs.com/pai-eas/blade-llm:0.1.2。填写模型配置
单击填写模型配置,配置模型地址。
模型配置选择OSS挂载,将OSS路径配置为模型文件所在的OSS Bucket路径,例如:
oss://examplebucket/exampledirectory/。挂载路径:指定挂载后的路径,本方案配置为:
/mnt/model/llama2_7b。
运行命令
运行命令配置为:
Huggingface格式的模型:
blade_llm_server --port 8081 --model_type llama --from_hf /mnt/model/llama2_7b/ --fp16 --use_hf_generateMegatronLM格式的模型:
blade_llm_server --port 8081 --model_type llama --from_megatron /mnt/model/llama2_7b/ --ignore_unknown_type_in_checkpoint --use_hf_generate --fp16
参数说明如下:
--from_hf:加载hf格式的模型。该目录下需要包含符合Huggingface格式的配置文件和模型文件,例如config.json、pytorch_model.bin等。
--from_megatron:加载Megatron格式的模型。该目录下需要包含从hf转换为Megatron格式时自动拷贝的config.json等文件,以及Megatron格式的Checkpoint,比如
release/mp_rank_00/model_rng.pt)。
端口号配置为:8081。
【说明】运行命令的端口号需要与服务配置的端口号一致。
资源组种类
本方案选择公共资源组。
资源配置选择
根据模型情况配置实例规格,本方案配置为:ecs.gn7i-c32g1.8xlarge。
系统盘配置
单击系统盘配置,配置额外系统盘为100 GB。
单击部署。当服务状态变为运行中时,表明服务部署成功。
方式二:使用EASCMD客户端工具
在本地环境下载并认证客户端,本方案以Windows 64版本为例。
在客户端工具下载后的当前目录创建以下JSON脚本文件,命名为service.json。
{ "name": "blade_llm_llama2_server", "containers": [ { "image": "eas-registry-vpc.cn-wulanchabu.cr.aliyuncs.com/pai-eas/blade-llm:0.1.2", "script": "blade_llm_server --port 8081 --model_type llama --from_megatron /mnt/model/llama2_7b/ --ignore_unknown_type_in_checkpoint --use_hf_generate --fp16", "port": 8081 } ], "storage": [ { "mount_path": "/mnt/model/llama2_7b/", "oss": { "endpoint": "oss-cn-wulanchabu-internal.aliyuncs.com", "path": "oss://examplebucket/exampledirectory/" } } ], "features": { "eas.aliyun.com/extra-ephemeral-storage": "100Gi" }, "metadata": { "instance": 1 }, "cloud": { "computing": { "instance_type": "ecs.gn7i-c32g1.8xlarge", "instances": null } } }其中关键参数配置如下:
参数
描述
name
自定义模型名称,同地域内唯一。本方案配置为:blade_llm_bloom_server。
storage.oss.path
配置为模型文件所在的OSS Bucket路径。
containers.script
Huggingface格式的模型:
blade_llm_server --port 8081 --model_type llama --from_hf /mnt/model/llama2_7b/ --fp16 --use_hf_generateMegatronLM格式的模型:
blade_llm_server --port 8081 --model_type llama --from_megatron /mnt/model/llama2_7b/ --ignore_unknown_type_in_checkpoint --use_hf_generate --fp16
在本地命令行工具,进入JSON脚本文件所在目录,并执行以下命令创建EAS服务。
eascmdwin64.exe create service.json
完成及清理
10
方案验证
完成以上操作后,您已经成功完成了大模型LLM的训练及部署操作。在Notebook中输入如下Python代码发送服务请求,验证模型效果。
#!/usr/bin/env python
import json
from websockets.sync.client import connect
def hello():
headers = {"Authorization": "<token>"}
# URL 也从EAS控制台 - 查看调用信息处获取,把 http:// 换成 ws:// 即可。
url = "ws://xxxxx.cn-wulanchabu.pai-eas.aliyuncs.com/api/predict/<service_name>"
with connect(url, additional_headers=headers) as websocket:
prompts = ["What's the capital of Canada?"]
for p in prompts:
print(f"Prompt : {p}")
websocket.send(json.dumps({"prompt": p}))
while True:
msg = websocket.recv()
msg = json.loads(msg)
if msg['is_end']:
break
print(msg['text'], end="", flush=True)
print()
print("-" * 40)
hello()其中关键参数说明如下:
headers:将<token>替换为服务Token。您可以前往PAI-EAS模型在线服务页面,单击目标服务服务方式列下的调用信息,在公网地址调用页签获取。
url:配置为已部署服务的访问地址。您可以在公网地址调用页签获取,将服务地址中的http替换为ws即可。
输出如下类似结果,您的结果以实际为准。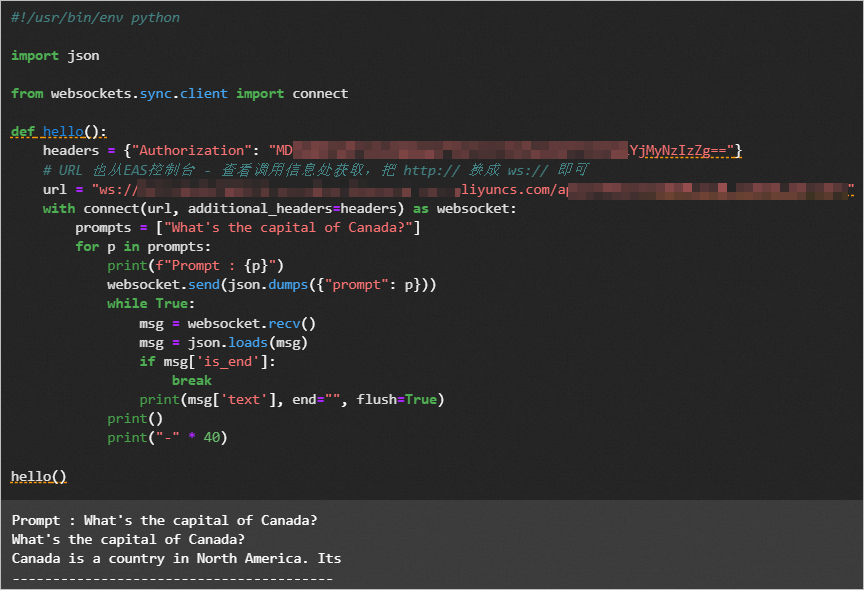
清理资源
如果无需继续使用DSW实例和EAS服务,您可以按照以下操作步骤停止DSW实例和EAS服务。
停止DSW实例
登录PAI控制台。
在页面左上方,选择DSW实例的地域。
在左侧导航栏单击工作空间列表,在工作空间列表页面中单击默认工作空间名称,进入对应工作空间内。
在工作空间页面的左侧导航栏选择模型开发与训练>交互式建模(DSW),进入交互式建模(DSW)页面。
单击目标实例操作列下的停止,成功停止后即停止资源消耗。
停止EAS服务

前往PAI-EAS模型在线服务页面,在页面左上角选择华北6(乌兰察布)地域。
在推理服务页签,单击目标服务操作列下的停止。成功停止后即停止资源消耗。
删除对象存储OSS Bucket。
登录OSS管理控制台,在左侧导航栏,选择Bucket列表,单击目标Bucket,在文件列表,选择目标文件,然后单击彻底删除。在左侧导航栏,选择删除Bucket,然后单击删除Bucket,根据页面提示删除Bucket。
删除智算CPFS文件系统。
登录NAS控制台。
在左侧导航栏,选择文件系统>文件系统列表。
在顶部菜单栏,选择地域。
在文件系统列表页面,找到目标文件系统,在操作列单击
 图标 > 删除。并按照界面操作指引删除智算CPFS文件系统。
图标 > 删除。并按照界面操作指引删除智算CPFS文件系统。
一键部署
235
https://www.aliyun.com/solution/tech-solution/pai_lingjun
方案概览
本方案是由阿里云PAI算法团队研发,基于智算服务PAI-灵骏(Serverless版)的大模型解决方案。旨在帮助大模型开发人员快速上手灵骏产品,完成大语言模型(LLM)的高效分布式训练、三阶段指令微调(instruct-finetuning)、模型离线推理验证以及在线服务部署等完整的开发链路。
本方案以llama-2-7b模型为例,提供了基于Huggingface&DeepSpeed和MegatronLM的两套训练流程。后者在保证模型效果和Huggingface对齐的前提下,基于Megatron-LM引擎支持了数据并行、算子拆分、流水并行、序列并行、选择性激活重算、Zero显存优化、BF16混合精度、梯度检查点、Flashattention等技术,可以大幅提升大模型训练分布式效率。
这套流程可用于开发llama-2(7B,13B,70B)系列模型。同时,灵骏还支持业界各类流行的开源LLM,比如Bloom系列、Falcon系列、GLM/ChatGLM系列,以及领域大模型galactica等的高效训练和部署。并且PAI也在不断扩展所支持的模型种类。
方案架构
技术方案架构示例如下:
本方案包括以下功能模块:
数据准备:使用灵骏智算资源创建PAI-DSW实例,并在该实例中准备好原始模型、Huggingface&DeepSpeed或MegatronLM训练数据,供后续的模型训练使用。
模型训练和离线推理:您可以在PAI-DSW单机环境或PAI-DLC分布式环境中进行模型训练,支持Huggingface&DeepSpeed训练流程和Megatron训练流程,同时,您还可以在PAI-DSW平台离线推理模型来评估模型效果。
模型部署:模型训练完成后,将训练获得的模型部署为在线服务,然后调用模型服务验证模型推理效果。
部署准备
10
准备账号
如果您还没有阿里云账号,请访问阿里云账号注册页面,根据页面提示完成注册。阿里云账号是您使用云资源的付费实体,因此是部署方案的必要前提。
使用到智算服务PAI-灵骏(Serverless版)、智算CPFS、PAI-EAS、OSS等产品,均会产生费用,您可以通过下面链接查询到费用使用情况:
按量付费的费用包括PAI-EAS服务运行所消耗的公共资源费用和系统盘费用,以及OSS的存储费用。其中PAI-EAS的计费逻辑与单价详情请参见EAS计费说明,OSS的计费逻辑与单价详情请参见存储费用。
您可以前往AI计算资源(预付费)和智算CPFS购买页查看费用详情。
创建用于方案部署的RAM用户。
创建1个RAM用户。具体操作,请参见创建RAM用户。
为RAM用户授予以下云服务的访问权限以完成方案部署。具体操作,请参见为RAM用户授权。
云服务
需要的权限
描述
人工智能平台 PAI
AliyunPAIFullAccess
管理PAI服务的权限。
添加为PAI工作空间的成员,并授予算法开发等具有开发权限的角色。
使用PAI-DSW和PAI-DLC进行模型训练。如何为工作空间添加成员及角色,请参见管理工作空间成员。
智算服务PAI-灵骏(Serverless版)
AliyunPAIFullAccess
当前灵骏智算资源仅供白名单用户受限申请使用,如果您希望使用灵骏智算资源提交训练任务,您可先提交工单,申请添加灵骏智算资源使用白名单。
建议使用阿里云账号来购买灵骏智算资源;也可以为RAM用户添加AliyunPAIFullAccess,此时RAM用户会拥有PAI全部权限,有操作风险,请谨慎添加。
专有网络VPC
AliyunVPCFullAccess
管理专有网络VPC的权限。
云服务器ECS
AliyunECSFullAccess
管理安全组的权限。
NAS
AliyunNASFullAccess
管理NAS的权限。目前,智算CPFS还在邀测中,您可以提交工单,申请添加智算CPFS使用白名单。
对象存储OSS
AliyunOSSFullAccess
管理对象存储OSS的权限。
费用中心BSS
AliyunBSSOrderAccess
在费用中心BSS查看订单、支付订单及取消订单的权限。
开通服务
登录PAI控制台,单击开通PAI并创建默认工作空间,在弹出的开通页面中配置订单详情,配置要点如下,更多详细内容,请参见开通PAI并创建默认工作空间。
本方案地域选择:华北6(乌兰察布)。
组合开通:本方案需要使用对象存储OSS,勾选开通OSS产品,去勾选其他产品即可。
服务角色授权:单击去授权,根据界面提示为PAI完成授权,然后返回开通页面,刷新页面,继续开通操作。
开通成功后,单击进入PAI控制台。
一键部署
5
ROS一键部署
资源编排(ROS)可以让您通过YAML或JSON文件清晰简洁地描述所需的云资源及其依赖关系,然后自动化地创建和配置这些资源。您可以通过下方提供的ROS一键部署链接,来自动化地完成这些资源的创建和配置:
创建1个专有网络VPC。
创建1台交换机。
创建1个安全组。
部署1个对象存储OSS Bucket。
打开一键配置模板链接前往ROS控制台,系统自动打开使用新资源创建资源栈的面板,并在模板内容区域展示YAML文件的详细信息。
确认好地域后,然后单击创建。
当资源栈信息页面的状态显示为创建成功时,表示一键配置完成。
部署资源
5
1、购买灵骏智算资源(Serverless版)
创建专有资源组并购买灵骏智算资源。
登录PAI控制台。在左侧导航栏选择。
在顶部菜单栏,选择华北6(乌兰察布)地域。
单击新建资源组,在弹出的对话框中配置资源组名称后,单击确定。
单击已创建好的资源组名称,进入资源组详情页面,并单击页面右侧的新建订单。在购买页面中按照资源规划配置必要参数(本方案的节点规格选择ml.gu7xf.c96m1600.8-gu108),根据界面提示完成下单购买。
创建资源配额。
在左侧导航栏选择。
在灵骏智算资源页签,单击新增资源配额,并在新增资源配额页面配置以下关键参数,参数配置完成后,单击提交。
参数
描述
关联工作空间
选择已创建的工作空间。
来源类型
选择专有资源组。
来源
选择已创建的专有资源组。
规格/资源
单击添加,选择规格后,单击确认。
专有网络
选择已创建的专有网络、交换机和安全组。
安全组
交换机
2、创建CPFS类型数据集
创建智算CPFS文件系统。
登录PAI控制台。在左侧导航栏选择。
在资源池页面右侧,单击新建CPFS。
在文件存储概览页面,单击CPFS智算版区域的创建,然后再创建CPFS智算版对话框中,单击确认创建。
在智算CPFS(按量计费)页面中选择集群编号和配置容量后,根据界面提示完成购买。
新建智算CPFS数据集。
单击左侧导航中的工作空间列表,单击待提交任务的工作空间名称进入工作空间后,在AI资产管理>数据集页面单击创建数据集,其中:
选择数据存储:请选择为阿里云文件存储(智算CPFS)。
选择文件系统:请在下拉框中选择智算CPFS的文件系统(bmcpfs开头的文件系统)。
其他参数的配置与通用数据集创建一致,详情请参见创建及管理数据集。
3、创建PAI-DSW实例
在默认工作空间中创建DSW实例,其中关键参数配置如下,其他参数取默认配置即可。更多详细内容,请参见创建DSW实例。
参数 | 描述 |
地域及可用区 | 本方案选择:华北6(乌兰察布)。 |
实例名称 | 您可以自定义实例名称,本方案示例为:dsw_test_01。 |
资源配额 | 本方案选择已创建的资源配额,并配置以下参数:
|
存储配置 | 单击共享数据集,选择已创建的CPFS类型数据集。 |
选择镜像 | 在镜像URL页签配置镜像地址,您可以任意选择一个镜像地址:
|
准备模型
20
本方案给出了以下三种下载模型的方式,您可以根据需要选择其中一种。
从ModelScope社区下载模型
进入PAI-DSW开发环境。
登录PAI控制台。
在左侧导航栏单击工作空间列表,在工作空间列表页面中单击待操作的工作空间名称,进入对应工作空间内。
在页面左上方,选择使用服务的地域:华北6(乌兰察布)。
在左侧导航栏,选择。
单击目标实例操作列下的打开。
在JupyterLab页签的Launcher页面,单击快速开始区域Notebook下的Python3。
下载llama-2模型。
在Notebook中执行以下命令,安装ModelScope。
pip install modelscope==1.7.1系统输出的结果中出现的类似如下WARNING信息和ERROR信息可以忽略。
WARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts. tensorboard 2.12.2 requires protobuf>=3.19.6, but you have protobuf 3.18.3 which is incompatible.执行命令,下载llama-2模型。您可以根据下表中的模型名称、版本信息并通过如下代码下载模型文件。
模型
模型链接
模型名称
版本
Llama-2-7b
modelscope/Llama-2-7b-ms
v1.0.1
Llama-2-7b-chat
modelscope/Llama-2-7b-chat-ms
v1.0.1
Llama-2-13b
modelscope/Llama-2-13b-ms
v1.0.0
Llama-2-13b-chat
modelscope/Llama-2-13b-chat-ms
v1.0.0
# ### Loading Model and Tokenizer from modelscope.hub.snapshot_download import snapshot_download model_dir = snapshot_download('modelscope/Llama-2-7b-ms', 'v1.0.1') # 获取下载路径。 print(model_dir) # /root/.cache/modelscope/hub/modelscope/Llama-2-7b-ms在顶部菜单栏,单击Terminal页签,在欢迎使用DSW Terminal页面中单击创建Terminal。
执行以下命令,将已下载的Checkpoint文件移动到对应文件夹下。
mkdir -p /mnt/workspace/llama2-ckpts/${后缀为hf的ckpt文件夹} # mkdir -p /mnt/workspace/llama2-ckpts/Llama-2-7b-hf cp -r ${在此处填写获取的模型路径}/* /mnt/workspace/llama2-ckpts/${后缀为hf的ckpt文件夹} # cp -r /root/.cache/modelscope/hub/modelscope/Llama-2-7b-ms/* /mnt/workspace/llama2-ckpts/Llama-2-7b-hf
从Huggingface社区下载模型
在PAI-DSW的Terminal中执行以下命令下载模型文件。
mkdir /mnt/workspace/llama2-ckpts
cd /mnt/workspace/llama2-ckpts
git clone https://huggingface.co/meta-llama/Llama-2-7b
git clone https://huggingface.co/meta-llama/Llama-2-13b
git clone https://huggingface.co/meta-llama/Llama-2-70b准备数据
20
建议您在使用灵骏智算资源创建的DSW实例中准备预训练数据。本方案以WuDao2.0数据集(该数据集仅供研究使用)为例,介绍数据预处理流程。
下载WuDaoCorpora2.0开源数据集到
/mnt/workspace/llama2-datasets工作目录下。PAI提供了部分样例数据作为示例,您可以在PAI-DSW的Terminal中执行以下命令下载并解压数据集。假设解压后的文件夹命名为wudao_200g。mkdir /mnt/workspace/llama2-datasets/ cd /mnt/workspace/llama2-datasets/ wget https://atp-modelzoo.oss-cn-hangzhou.aliyuncs.com/release/datasets/WuDaoCorpus2.0_base_sample.tgz tar zxvf WuDaoCorpus2.0_base_sample.tgz预处理数据。PAI为HuggingFace&DeepSpeed训练和MegatronLM训练分别准备了数据预处理流程,您可以根据自己的需要选择不同的处理方式。
准备Huggingface&DeepSpeed训练数据
在Terminal中执行以下脚本,对Wudao数据执行数据集清洗并进行文件格式转换,最终生成汇总的merged_wudao_cleaned.json文件。
#! /bin/bash set -ex # 请在此处设置原始数据所在路径。 data_dir=/mnt/workspace/llama2-datasets/wudao_200g # 开始数据清洗流程。 dataset_dir=$(dirname $data_dir) mkdir -p ${dataset_dir}/cleaned_wudao_dataset cd ${dataset_dir}/cleaned_wudao_dataset wget https://atp-modelzoo-wlcb-pai.oss-cn-wulanchabu.aliyuncs.com/release/models/pai-megatron-patch/llama2-codes/preprocess_wudao2.py python preprocess_wudao2.py -i ${data_dir} -o ${dataset_dir}/cleaned_wudao_dataset -p 32 # 合并清洗后的数据,移除过程数据。 mkdir ${dataset_dir}/wudao cd ${dataset_dir}/wudao find ${dataset_dir}/cleaned_wudao_dataset -name "*.json" -exec cat {} + > ${dataset_dir}/wudao/merged_wudao_cleaned.json rm -rf ${dataset_dir}/cleaned_wudao_dataset脚本执行完成后,llama2-datasets目录的文件结构如下。新增了一个wudao文件夹:
llama2-datasets ├── wudao_200g └── wudao └── merged_wudao_cleaned.json在Terminal中执行以下命令,利用生成的merged_wudao_cleaned.json文件生成预训练所需的训练集和验证集。您需要在下面的脚本中设置训练集占比,比如设置TRAIN_RATE=90,表示训练集占比为90%。
# 请在此处设置训练集的占比。 TRAIN_RATE=90 # 开始拆分训练集、测试集,移除过程数据。 NUM=$(sed -n '$=' ${dataset_dir}/wudao/merged_wudao_cleaned.json) TRAIN_NUM=$(($(($NUM/100))*$TRAIN_RATE)) echo "total line of dataset is $NUM, data will be split into 2 parts, $TRAIN_NUM samples for training, $(($NUM-$TRAIN_NUM)) for validation" split -l $TRAIN_NUM --numeric-suffixes --additional-suffix=.json ${dataset_dir}/wudao/merged_wudao_cleaned.json ${dataset_dir}/wudao/ mkdir ${dataset_dir}/wudao_huggingface cd ${dataset_dir}/wudao_huggingface mv ${dataset_dir}/wudao/00.json ${dataset_dir}/wudao_huggingface/wudao200g_train.json mv ${dataset_dir}/wudao/01.json ${dataset_dir}/wudao_huggingface/wudao200g_valid.json rm -rf ${dataset_dir}/wudao/命令执行完成后,llama2-datasets目录的文件结构如下,新增了两个JSON文件。
llama2-datasets ├── wudao_200g ├── wudao_train.json └── wudao_valid.json
完成以上操作步骤后Huggingface的数据已准备完成。您可以执行后续章节中的Huggingface&Deepspeed训练流程,详情请参见Huggingface&DeepSpeed训练流程章节。
准备MegatronLM训练数据
MMAP数据是一种预先执行tokenize的数据格式,可以减少训练微调过程中等待数据读入的时间,当数据量较大时优势更显著。您可以按照以下操作步骤准备数据。
执行准备Huggingface&DeepSpeed训练数据的操作步骤生成JSON文件。
在Terminal中执行以下命令,对Wudao数据执行数据集清洗并进行文件格式转换,最终生成汇总的merged_wudao_cleaned.json。
#! /bin/bash set -ex # 请在此处设置原始数据所在路径。 data_dir=/mnt/workspace/llama2-datasets/wudao_200g # 开始数据清洗流程。 dataset_dir=$(dirname $data_dir) mkdir -p ${dataset_dir}/cleaned_wudao_dataset cd ${dataset_dir}/cleaned_wudao_dataset wget https://atp-modelzoo-wlcb-pai.oss-cn-wulanchabu.aliyuncs.com/release/models/pai-megatron-patch/llama2-codes/preprocess_wudao2.py # 此处与上一节不同,增加了key参数设为text。 python preprocess_wudao2.py -i ${data_dir} -o ${dataset_dir}/cleaned_wudao_dataset -k text -p 32 # 合并清洗后的数据。 mkdir ${dataset_dir}/wudao cd ${dataset_dir}/wudao find ${dataset_dir}/cleaned_wudao_dataset -name "*.json" -exec cat {} + > ${dataset_dir}/wudao/merged_wudao_cleaned.json rm -rf ${dataset_dir}/cleaned_wudao_dataset命令执行完成后,llama2-datasets目录的文件结构如下,新增一个wudao文件夹:
llama2-datasets ├── wudao_200g └── wudao └── merged_wudao_cleaned.json在Terminal中执行以下命令,利用生成的merged_wudao_cleaned.json文件将数据拆分成若干组并进行压缩,以便后续实现多线程处理。
apt-get update apt-get install zstd # 此处设置分块数为10,如数据处理慢可设置稍大。 NUM_PIECE=10 # 对merged_wudao_cleaned.json文件进行处理。 mkdir -p ${dataset_dir}/cleaned_zst/ # 查询数据总长度,对数据进行拆分。 NUM=$(sed -n '$=' ${dataset_dir}/wudao/merged_wudao_cleaned.json) echo "total line of dataset is $NUM, data will be split into $NUM_PIECE pieces for processing" NUM=`expr $NUM / $NUM_PIECE` echo "each group is processing $NUM sample" split_dir=${dataset_dir}/split mkdir $split_dir split -l $NUM --numeric-suffixes --additional-suffix=.jsonl ${dataset_dir}/wudao/merged_wudao_cleaned.json $split_dir/ # 数据压缩。 o_path=${dataset_dir}/cleaned_zst/ mkdir -p $o_path files=$(ls $split_dir/*.jsonl) for filename in $files do f=$(basename $filename) zstd -z $filename -o $o_path/$f.zst & done rm -rf $split_dir rm ${dataset_dir}/wudao/merged_wudao_cleaned.json命令执行完成后,llama2-datasets目录的文件结构如下。新增了一个cleaned_zst文件夹,每个子文件夹里有10个压缩文件。
llama2-datasets ├── wudao_200g ├── wudao └── cleaned_zst ├── 00.jsonl.zst │ ... └── 09.jsonl.zst制作MMAP格式的预训练数据集。
前往PAI-Megatron-Patch页面获取Megatron模型训练工具PAI-Megatron-Patch源代码。
在DSW实例页面,按照下图操作指引,将已获取的工具和源代码上传到
/mnt/workspace/下,并分别解压到当前目录。在Terminal中执行命令将数据转换成MMAP格式。命令执行成功后,在
/mnt/workspace/llama2-datasets/wudao目录下生成.bin和.idx文件。# 请在此处设置数据集路径和工作路径。 export dataset_dir=/mnt/workspace/llama2-datasets export WORK_DIR=/mnt/workspace # 分别为训练集、验证集生成mmap格式预训练数据集。 cd ${WORK_DIR}/PAI-Megatron-Patch/toolkits/pretrain_data_preprocessing bash run_make_pretraining_dataset.sh \ /root/Megatron-LM-23.04 \ ${WORK_DIR}/PAI-Megatron-Patch/ \ ${dataset_dir}/cleaned_zst/ \ llamabpe \ ${dataset_dir}/wudao/ \ ${WORK_DIR}/llama2-ckpts/llama-2-7b-hf rm -rf ${dataset_dir}/cleaned_zst其中运行run_make_pretraining_dataset.sh脚本输入的五个启动参数说明如下:
参数
描述
MEGATRON_PATH=$1
设置开源Megatron的代码路径。
MEGATRON_PATCH_PATH=$2
设置Megatron Patch的代码路径。
input_data_dir=$3
打包后的wudao数据集的文件夹路径。
tokenizer=$4
指定分词器的类型为llamabpe。
output_data_dir=$5
指定输出结果的保存路径。
load_dir=$6
tokenizer_config.json文件路径。
脚本执行完成后,llama2-datasets目录的文件结构如下。
llama2-datasets ├── wudao_200g └── wudao ├── wudao_llamabpe_text_document.bin └── wudao_llamabpe_text_document.idx
完成以上操作步骤后MegatronLM的数据已准备完成。您可以执行后续章节中的Megatron训练流程,详情请参见Megatron训练流程章节。
为了方便您试用该方案,PAI也提供了已经处理好的小规模样本数据,您可以在PAI-DSW的Terminal中执行以下命令下载样本数据。
cd /mnt/workspace/llama2-datasets
wget https://atp-modelzoo-wlcb-pai.oss-cn-wulanchabu.aliyuncs.com/release/models/pai-megatron-patch/llama2-datasets/wudao_train.json
wget https://atp-modelzoo-wlcb-pai.oss-cn-wulanchabu.aliyuncs.com/release/models/pai-megatron-patch/llama2-datasets/wudao_valid.json
mkdir -p /mnt/workspace/llama2-datasets/wudao
cd /mnt/workspace/llama2-datasets/wudao
wget https://atp-modelzoo-wlcb-pai.oss-cn-wulanchabu.aliyuncs.com/release/models/pai-megatron-patch/llama2-datasets/wudao_llamabpe_text_document.bin
wget https://atp-modelzoo-wlcb-pai.oss-cn-wulanchabu.aliyuncs.com/release/models/pai-megatron-patch/llama2-datasets/wudao_llamabpe_text_document.idxHuggingface&DeepSpeed训练流程
60
基于上述章节已下载好的模型和训练数据,您可以在PAI-DSW环境中调试预训练模型,也可以在PAI-DLC环境中配置多机多卡分布式任务。
使用DSW调试训练模型
在PAI-DSW单机环境的Terminal中下载并运行run_ds_train_huggingface_llama.sh脚本。DSW单机运行示例如下:
cd /mnt/workspace
mkdir test_llama2_hf
cd test_llama2_hf
export WORK_DIR=/mnt/workspace/
wget https://atp-modelzoo-wlcb-pai.oss-cn-wulanchabu.aliyuncs.com/release/models/pai-megatron-patch/llama2-codes/ds_config_TEMPLATE.json
wget https://atp-modelzoo-wlcb-pai.oss-cn-wulanchabu.aliyuncs.com/release/models/pai-megatron-patch/llama2-codes/ds_train_huggingface_llama.py
wget https://atp-modelzoo-wlcb-pai.oss-cn-wulanchabu.aliyuncs.com/release/models/pai-megatron-patch/llama2-codes/run_ds_train_huggingface_llama.sh
bash run_ds_train_huggingface_llama.sh \
dsw \
7B \
1 \
2 \
1e-5 \
2048 \
bf16 \
2 \
true \
${WORK_DIR}/llama2-datasets/wudao_train.json \
${WORK_DIR}/llama2-datasets/wudao_valid.json \
${WORK_DIR}/llama2-ckpts/Llama-2-7b-hf \
2 \
${WORK_DIR}/output_llama2需要传入的参数列表如下:
参数 | 描述 |
ENV=$1 | 配置运行环境:
|
MODEL_SIZE=$2 | 模型结构参数量级:7B、13B或70B。 |
BATCH_SIZE=$3 | 每卡训练一次迭代样本数:4或8。 |
GA_STEPS=$4 | 梯度累积step数。 |
LR=$5 | 学习率:1e-5或5e-5。 |
SEQ_LEN=$6 | 序列长度:2048。 |
PR=$7 | 训练精度:fp16或bf16。 |
ZERO=$8 | DeepSpeed ZERO降显存:1、2、3。 |
GC=$9 | 是否使用gradient-checkpointing:
|
TRAIN_DATASET_PATH=${10} | 训练集路径,支持单一文件或者文件夹形式输入。 |
VALID_DATASET_PATH=${11} | 验证集路径,支持单一文件或文件夹形式输入。 |
PRETRAIN_CHECKPOINT_PATH=${12} | 预训练模型路径。 |
EPOCH=${13} | 训练epoch数。 |
OUTPUT_BASEPATH=${14} | 训练输出文件路径。 |
DLC分布式训练模型
在DSW单机环境调试完成后,您可以在DLC环境中配置多机多卡分布式任务。具体操作步骤如下。
登录PAI控制台。
在左侧导航栏单击工作空间列表,在工作空间列表页面中单击待操作的工作空间名称,进入对应工作空间内。
在工作空间页面的左侧导航栏选择,在分布式训练任务页面中单击新建任务,进入新建任务页面。
在新建任务页面,配置以下关键参数,其他参数取默认配置即可。更多详细内容,请参见创建训练任务。
参数
描述
任务名称
自定义任务名称。本方案配置为:test_megatron_dlc。
节点镜像
选中镜像地址并在文本框中输入镜像地址,您可以任意选择一种镜像地址:
torch1.12版本镜像:
pai-image-manage-registry.cn-wulanchabu.cr.aliyuncs.com/pai/pytorch-training:1.12-ubuntu20.04-py3.10-cuda11.3-megatron-patch-llm
torch2.0版本镜像:
pai-image-manage-registry.cn-wulanchabu.cr.aliyuncs.com/pai/pytorch-training:2.0-ubuntu20.04-py3.10-cuda11.8-megatron-patch-llm
数据集配置
与DSW配置同一个CPFS类型数据集。
执行命令
配置以下命令,其中run_pretrain_megatron_bloom.sh脚本输入的启动参数与DSW单机训练模型一致。
cd /mnt/workspace mkdir test_llama2_hf cd test_llama2_hf export WORK_DIR=/mnt/workspace/ wget https://atp-modelzoo-wlcb-pai.oss-cn-wulanchabu.aliyuncs.com/release/models/pai-megatron-patch/llama2-codes/ds_config_TEMPLATE.json wget https://atp-modelzoo-wlcb-pai.oss-cn-wulanchabu.aliyuncs.com/release/models/pai-megatron-patch/llama2-codes/ds_train_huggingface_llama.py wget https://atp-modelzoo-wlcb-pai.oss-cn-wulanchabu.aliyuncs.com/release/models/pai-megatron-patch/llama2-codes/run_ds_train_huggingface_llama.sh sed -i 's|mm = mmap.mmap(fid.fileno(), bytes, access=acc, offset=start)|mm = mmap.mmap(fid.fileno(), bytes, flags=mmap.MAP_PRIVATE, offset=start)|g' /opt/conda/lib/python3.8/site-packages/numpy/core/memmap.py sed -i "s|barrier_timeout: float = 300|barrier_timeout: float = 36000|g" /opt/conda/lib/python3.8/site-packages/torch/distributed/elastic/utils/store.py bash run_ds_train_huggingface_llama.sh \ dlc \ 7B \ 1 \ 2 \ 1e-5 \ 2048 \ fp16 \ 2 \ true \ ${WORK_DIR}/llama2-datasets/wudao_train.json \ ${WORK_DIR}/llama2-datasets/wudao_valid.json \ ${WORK_DIR}/llama2-ckpts/Llama-2-7b-hf \ 2 \ ${WORK_DIR}/output_llama2资源配额
本方案选择已创建的灵骏智算资源配额。
框架
选择PyTorch。
任务资源
为Worker节点配置以下参数:
节点数量:2,如果需要多机训练,配置节点数量为需要的机器数即可。
CPU(核数):90
说明CPU核数不能大于96。
GPU(卡数):8
内存(GiB):1024
共享内存(GiB):1024
单击提交,页面自动跳转到容器训练任务页面。您可以单击任务名称,在任务详情页面查看任务执行状态。当状态变为已成功时,表明训练任务执行成功。
Megatron训练流程
60
将Huggingface格式的模型文件转换为Megatron格式。
自行将Huggingface版本模型转换成Megatron模型
前往PAI-Megatron-Patch页面获取Megatron模型训练工具PAI-Megatron-Patch源代码,在Terminal中执行以下命令,使用PAI提供的下载地址来获取Huggingface版本的模型权重,并按照如下流程完成格式转换。
cd /mnt/workspace/ mkdir llama2-ckpts cd llama2-ckpts wget https://atp-modelzoo-wlcb-pai.oss-cn-wulanchabu.aliyuncs.com/release/models/pai-megatron-patch/llama2-ckpts/Llama-2-7b-hf.tgz tar -zxf Llama-2-7b-hf.tgz mv Llama-2-7b-hf llama2-7b-hf cd /mnt/workspace/PAI-Megatron-Patch/toolkits/model_checkpoints_convertor/llama sh model_convertor.sh \ /root/Megatron-LM-23.04 \ /mnt/workspace/llama2-ckpts/llama2-7b-hf \ /mnt/workspace/llama2-ckpts/llama2-7b-hf-to-megatron-tp1-pp1 \ 1 \ 1 \ llama-7b \ 0 \ false下载转换好的Megatron模型
为方便您试用该方案,PAI提供了转换好格式的模型。您可以在DSW实例页面顶部菜单栏,单击Terminal页签,并在Terminal中执行以下命令下载模型即可。
cd /mnt/workspace/ mkdir llama2-ckpts cd llama2-ckpts wget https://atp-modelzoo-wlcb-pai.oss-cn-wulanchabu.aliyuncs.com/release/models/pai-megatron-patch/llama2-ckpts/llama-2-7b-hf-to-megatron-tp1-pp1.tgz tar -zxf llama-2-7b-hf-to-megatron-tp1-pp1.tg继续预训练模型。您可以在PAI-DSW单机环境中训练模型,后续您也可以在PAI-DLC环境中提交多机多卡分布式任务。任务执行成功后,将模型文件输出到
/mnt/workspace/output_megatron_llama2/目录下。DSW单机预训练模型
DSW单机运行示例如下:
export WORK_DIR=/mnt/workspace cd ${WORK_DIR}/PAI-Megatron-Patch/examples/llama2 sh run_pretrain_megatron_llama.sh \ dsw \ /root/Megatron-LM-23.04 \ ${WORK_DIR}/PAI-Megatron-Patch \ 7B \ 1 \ 8 \ 1e-5 \ 1e-6 \ 2048 \ 80 \ 0 \ fp16 \ 1 \ 1 \ sel \ true \ false \ false \ 100000 \ ${WORK_DIR}/llama2-datasets/wudao/wudao_llamabpe_text_document \ ${WORK_DIR}/llama2-ckpts/llama2-7b-hf-to-megatron-tp1-pp1 \ 100000000 \ 10000 \ ${WORK_DIR}/output_megatron_llama2/其中运行run_pretrain_megatron_llama.sh脚本需要传入的参数说明如下:
参数
描述
ENV=$1
配置运行环境:
dsw
dlc
MEGATRON_PATH=$2
设置开源Megatron的代码路径。
MEGATRON_PATCH_PATH=$3
设置Megatron Patch的代码路径。
MODEL_SIZE=$4
模型结构参数量级:7B、13B或70B。
BATCH_SIZE=$5
每卡训练一次迭代样本数:4或8。
GLOBAL_BATCH_SIZE=$6
全局Batch Size。
LR=$7
学习率:1e-5或5e-5。
MIN_LR=$8
最小学习率:1e-6或5e-6。
SEQ_LEN=$9
序列长度。
PAD_LEN=${10}
Padding长度:100。
EXTRA_VOCAB_SIZE=${11}
词表扩充大小。
PR=${12}
训练精度:fp16或bf16。
TP=${13}
模型并行度。
PP=${14}
流水并行度。
AC=${15}
激活检查点模式:
full
sel
DO=${16}
是否使用Megatron版Zero-1降显存优化器:
true
false
FL=${17}
是否打开Flash Attention:
true
false
SP=${18}
是使用序列并行:
true
false
SAVE_INTERVAL=${19}
保存CheckPoint文件的间隔。
DATASET_PATH=${20}
训练数据集路径。
PRETRAIN_CHECKPOINT_PATH=${21}
预训练模型路径。
TRAIN_TOKENS=${22}
训练Tokens。
WARMUP_TOKENS=${23}
预热Token数。
OUTPUT_BASEPATH=${24}
训练输出文件路径。
DLC分布式预训练模型
在DSW单机环境调试完成后,您可以在DLC环境中配置多机多卡分布式任务。其中执行命令配置如下,使用和DSW相同的训练脚本run_pretrain_megatron_llama.sh。其他参数配置详情,请参见Huggingface&DeepSpeed训练流程。
export WORK_DIR=/mnt/workspace cd ${WORK_DIR}/PAI-Megatron-Patch/examples/llama2 bash run_pretrain_megatron_llama.sh \ dlc \ /root/Megatron-LM-23.04 \ ${WORK_DIR}/PAI-Megatron-Patch \ 7B \ 1 \ 16 \ 1e-5 \ 1e-6 \ 2048 \ 80 \ 0 \ fp16 \ 1 \ 1 \ sel \ true \ false \ false \ 100000 \ ${WORK_DIR}/llama2-datasets/wudao/wudao_llamabpe_text_document \ ${WORK_DIR}/llama2-ckpts/llama2-7b-hf-to-megatron-tp1-pp1 \ 100000000 \ 10000 \ ${WORK_DIR}/output_megatron_llama2/有监督微调模型。您可以在PAI-DSW单机环境中训练模型,后续您也可以在PAI-DLC环境中提交多机多卡分布式任务。任务执行成功后,将模型文件输出到
/mnt/workspace/output_megatron_llama2/目录下。DSW单机微调模型
DSW单机运行示例如下:
export WORK_DIR=/mnt/workspace cd ${WORK_DIR}/PAI-Megatron-Patch/examples/llama2 sh run_finetune_megatron_llama.sh \ dsw \ /root/Megatron-LM-23.04 \ ${WORK_DIR}/PAI-Megatron-Patch \ 7B \ 1 \ 1e-5 \ 1e-6 \ 2048 \ 80 \ 0 \ bf16 \ 1 \ 1 \ sel \ true \ false \ false \ ${WORK_DIR}/llama2-datasets/wudao_train.json \ ${WORK_DIR}/llama2-datasets/wudao_valid.json \ ${WORK_DIR}/llama2-ckpts/llama2-7b-hf-to-megatron-tp1-pp1 \ 2 \ ${WORK_DIR}/output_megatron_llama2/其中运行run_finetune_megatron_llama.sh脚本需要传入的参数说明如下:
参数
描述
ENV=$1
运行环境:
dlc
dsw
MEGATRON_PATH=$2
设置开源Megatron的代码路径。
MEGATRON_PATCH_PATH=$3
设置Megatron Patch的代码路径。
MODEL_SIZE=$4
模型结构参数量级:7B、13B或70B。
BATCH_SIZE=$5
每卡训练一次迭代样本数:4、8。
LR=$6
学习率:1e-5、5e-5。
MIN_LR=$7
最小学习率:1e-6、5e-6。
SEQ_LEN=$8
序列长度。
PAD_LEN=$9
Padding序列长度:100。
EXTRA_VOCAB_SIZE=${10}
词表扩充大小。
PR=${11}
训练精度:fp16、bf16。
TP=${12}
模型并行度。
PP=${13}
流水并行度。
AC=${14}
激活检查点模式:full或sel。
DO=${15}
是否使用Megatron版Zero-1降显存优化器:
true
false
FL=${16}
是否打开Flash Attention:
true
false
SP=${17}
是否使用序列并行:
true
false
TRAIN_DATASET_PATH=${18}
训练数据集路径。
VALID_DATASET_PATH=${19}
验证数据集路径。
PRETRAIN_CHECKPOINT_PATH=${20}
预训练模型路径。
EPOCH=${21}
训练迭代轮次。
OUTPUT_BASEPATH=${22}
训练输出文件路径。
DLC分布式微调模型
在DSW单机环境调试完成后,您可以在DLC环境中配置多机多卡分布式任务。其中执行命令配置如下,使用和DSW相同的训练脚本run_finetune_megatron_llama.sh。其他参数配置详情,请参见Huggingface&DeepSpeed训练流程。
export WORK_DIR=/mnt/workspace cd ${WORK_DIR}/PAI-Megatron-Patch/examples/llama2 sh run_finetune_megatron_llama.sh \ dlc \ /root/Megatron-LM-23.04 \ ${WORK_DIR}/PAI-Megatron-Patch \ 7B \ 1 \ 1e-5 \ 1e-6 \ 2048 \ 80 \ 0 \ fp16 \ 1 \ 1 \ sel \ true \ false \ false \ ${WORK_DIR}/llama2-datasets/wudao_train.json \ ${WORK_DIR}/llama2-datasets/wudao_valid.json \ ${WORK_DIR}/llama2-ckpts/llama2-7b-hf-to-megatron-tp1-pp1 \ 2 \ ${WORK_DIR}/output_megatron_llama2/
离线推理模型
15
模型训练完成后,您可以离线推理模型来评估模型效果。根据上面不同的训练流程,PAI也提供了对应的HuggingFace&DeepSpeed和MegatronLM两种格式的推理链路。
使用HuggingFace&DeepSpeed离线推理模型
对于使用Huggingface&DeepSpeed训练流程获得的模型,可以使用HuggingFace进行离线推理。您可以参考如下文档进行离线推理:
在Terminal中的任意目录下创建infer.py文件,文件内容如下。执行infer.py文件进行模型离线推理,根据推理结果来评估模型效果。
import torch
import transformers
from transformers import LlamaTokenizer, LlamaForCausalLM
model = "/mnt/workspace/output_llama2/checkpoint/dswXXX/checkpoinXXX/"
print(model)
tokenizer = LlamaTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map="auto",
)
sequences = pipeline(
"The weather today is",
max_length=200,
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
)
print(sequences)
for seq in sequences:
print(f"Result: {seq['generated_text']}")其中:model配置为Huggingface&DeepSpeed训练流程生成的模型路径。
使用MegatronLM离线推理模型
对于使用MegatronLM训练流程获得的模型,可以直接使用MegatronLM框架进行离线推理。
下载测试样本:pred_input.jsonl,并上传到DSW的
/mnt/workspace目录下。【说明】推理的数据组织形式需要与微调时的保持一致。
由于模型保存的路径下缺少tokenizer依赖的文件,您需要将微调前模型路径下的所有JSON文件和tokenizer.model文件拷贝到保存模型的路径(位于
{OUTPUT_BASEPATH }/checkpoint的下一级目录下,与latest_checkpointed_iteration.txt同级。命令中的路径需替换为您的实际路径。cd /mnt/workspace/llama2-ckpts/llama2-7b-hf-to-megatron-tp1-pp1 cp *.json /mnt/workspace/output_megatron_llama2/checkpoint/dswXXX/在Terminal中执行命令完成模型离线推理,推理结果输出到
/mnt/workspace/llama2_pred.txt文件,您可以根据推理结果来评估模型效果。【说明】:您需要将run_text_generation_megatron_llama.sh脚本中的参数CUDA_VISIBLE_DEVICES设置为0;参数GPUS_PER_NODE设置为1。
export WORK_DIR=/mnt/workspace cd ${WORK_DIR}/PAI-Megatron-Patch/examples/llama2 bash run_text_generation_megatron_llama.sh \ dsw \ /root/Megatron-LM-23.04 \ ${WORK_DIR}/PAI-Megatron-Patch \ /mnt/workspace/output_megatron_llama2/checkpoint/dswXXX \ 7B \ 1 \ 1 \ 1024 \ 1024 \ 0 \ fp16 \ 10 \ 512 \ 512 \ ${WORK_DIR}/pred_input.jsonl \ ${WORK_DIR}/llama2_pred.txt \ 0 \ 1.0 \ 1.2其中运行run_text_generation_bloom.sh脚本输入的启动参数说明如下:
参数
描述
ENV=$1
运行环境:
dlc
dsw
MEGATRON_PATH=$2
设置开源Megatron的代码路径。
MEGATRON_PATCH_PATH=$3
设置Megatron Patch的代码路径。
CHECKPOINT_PATH=$5
模型微调阶段的模型保存路径。
【注意】该路径需要替换为您自己的模型路径。
MODEL_SIZE=$6
模型结构参数量级:7B、13B或70B。
TP=$7
模型并行度。
【注意】该参数配置为1,可以使用单卡进行推理;如果该参数值大于1,则需要使用相应的卡数进行推理。
BS=$8
每卡推理一次迭代样本数:1、4、8。
SEQ_LEN=$9
序列长度:256、512、1024。
PAD_LEN=$9
PAD长度:需要将文本拼接的长度。
EXTRA_VOCAB_SIZE=${10}
模型转换时增加的token数量。
PR=${11}
推理采用的精度:fp16,bf16。
TOP_K=${12}
采样策略中选择排在前面的候选词数量(0-n): 0、5、10、20。
INPUT_SEQ_LEN=${13}
输入序列长度:512。
OUTPUT_SEQ_LEN=${14}
输出序列长度:256。
INPUT_FILE=${15}
需要推理的文本文件:input.txt,每行为一个样本。
OUTPUT_FILE=${16}
推理输出的文件:output.txt。
TOP_P=${17}
采样策略中选择排在前面的候选词百分比(0,1):0、0.85、0.95。
【说明】TOP_K和TOP_P必须有一个为0。
TEMPERATURE=${18}
采样策略中温度惩罚:1-n。
REPETITION_PENALTY=${19}
避免生成时产生大量重复,可以设置为(1-2)。默认为1.2。
将模型上传到OSS Bucket存储空间
本方案以Megatron训练流程获得的模型为例,来说明如何将模型文件上传到OSS存储空间:
10
在Terminal中执行以下命令将原始模型目录文件替换成训练获得的模型文件,您的模型地址以实际为准。
cp /mnt/workspace/output_megatron_llama2/checkpoint/dswXXX/iter_XXX/mp_rank_00/model_rng.pt /mnt/workspace/llama2-ckpts/llama2-7b-hf-to-megatron-tp1-pp1/release/mp_rank_00/model_rng.pt在DSW中安装ossutil并完成配置,详情请参见安装ossutil。
在DSW的Terminal中,执行以下命令将模型文件上传到OSS Bucket存储空间,更多详细内容,请参见命令行工具ossutil命令参考。
cd /mnt/workspace/llama2-ckpts ossutil64 cp -r llama2-7b-hf-to-megatron-tp1-pp1/ oss://examplebucket/exampledirectory/
如果需要部署使用Huggingface&DeepSpeed训练流程获得的模型文件,您需要将/mnt/workspace/output_llama2/checkpoint/dswXXX/checkpointXXX/global_stepXXX/mp_rank_00_model_states.pt文件拷贝到上一层包含config.json文件的目录中,并重命名为pytorch_model.bin。然后参照上述操作步骤将/mnt/workspace/output_llama2/checkpoint/dswXXX/checkpointXXX/目录下的文件上传到OSS Bucket存储空间。
部署模型服务
15
BladeLLM是阿里云PAI平台提供的大模型部署框架,支持主流LLM模型结构,并内置模型量化压缩、BladeDISC编译等优化技术用于加速模型推理。 使用BladeLLM的预构建镜像,能够便捷地在PAI-EAS平台部署大模型推理服务。本方案以使用Megatron训练流程获得的模型为例,来说明如何部署模型服务,具体操作步骤如下:
任意选择一种方式部署服务。
方式一:使用PAI控制台
前往部署服务页面,在华北6(乌兰察布)地域部署模型服务,其中关键参数配置如下,其他参数取默认配置即可。
参数
描述
服务名称
自定义模型服务名称,同地域内唯一。本方案配置为:blade_llm_llama2_server。
部署方式
本方案选择:镜像部署服务。
镜像选择
选择镜像地址,在本文框中配置镜像地址:
eas-registry-vpc.cn-wulanchabu.cr.aliyuncs.com/pai-eas/blade-llm:0.1.2。填写模型配置
单击填写模型配置,配置模型地址。
模型配置选择OSS挂载,将OSS路径配置为模型文件所在的OSS Bucket路径,例如:
oss://examplebucket/exampledirectory/。挂载路径:指定挂载后的路径,本方案配置为:
/mnt/model/llama2_7b。
运行命令
运行命令配置为:
Huggingface格式的模型:
blade_llm_server --port 8081 --model_type llama --from_hf /mnt/model/llama2_7b/ --fp16 --use_hf_generateMegatronLM格式的模型:
blade_llm_server --port 8081 --model_type llama --from_megatron /mnt/model/llama2_7b/ --ignore_unknown_type_in_checkpoint --use_hf_generate --fp16
参数说明如下:
--from_hf:加载hf格式的模型。该目录下需要包含符合Huggingface格式的配置文件和模型文件,例如config.json、pytorch_model.bin等。
--from_megatron:加载Megatron格式的模型。该目录下需要包含从hf转换为Megatron格式时自动拷贝的config.json等文件,以及Megatron格式的Checkpoint,比如
release/mp_rank_00/model_rng.pt。
端口号配置为:8081。
【说明】运行命令的端口号需要与服务配置的端口号一致。
资源组种类
本方案选择公共资源组。
资源配置选择
根据模型情况配置实例规格,本方案配置为:ecs.gn7i-c32g1.8xlarge。
系统盘配置
单击系统盘配置,配置额外系统盘为100 GB。
单击部署。当服务状态变为运行中时,表明服务部署成功。
方式二:使用EASCMD客户端工具
在本地环境下载并认证客户端,本方案以Windows 64版本为例。
在客户端工具下载后的当前目录创建以下JSON脚本文件,命名为service.json。
{ "name": "blade_llm_llama2_server", "containers": [ { "image": "eas-registry-vpc.cn-wulanchabu.cr.aliyuncs.com/pai-eas/blade-llm:0.1.2", "script": "blade_llm_server --port 8081 --model_type llama --from_megatron /mnt/model/llama2_7b/ --ignore_unknown_type_in_checkpoint --use_hf_generate --fp16", "port": 8081 } ], "storage": [ { "mount_path": "/mnt/model/llama2_7b/", "oss": { "endpoint": "oss-cn-wulanchabu-internal.aliyuncs.com", "path": "oss://examplebucket/exampledirectory/" } } ], "features": { "eas.aliyun.com/extra-ephemeral-storage": "100Gi" }, "metadata": { "instance": 1 }, "cloud": { "computing": { "instance_type": "ecs.gn7i-c32g1.8xlarge", "instances": null } } }其中关键参数配置如下:
参数
描述
name
自定义模型名称,同地域内唯一。本方案配置为:blade_llm_bloom_server。
storage.oss.path
配置为模型文件所在的OSS Bucket路径。
containers.script
Huggingface格式的模型:
blade_llm_server --port 8081 --model_type llama --from_hf /mnt/model/llama2_7b/ --fp16 --use_hf_generateMegatronLM格式的模型:
blade_llm_server --port 8081 --model_type llama --from_megatron /mnt/model/llama2_7b/ --ignore_unknown_type_in_checkpoint --use_hf_generate --fp16
在本地命令行工具,进入JSON脚本文件所在目录,并执行以下命令创建EAS服务。
eascmdwin64.exe create service.json
完成及清理
15
方案验证
完成以上操作后,您已经成功完成了大模型LLM的训练及部署操作。在Notebook中输入如下Python代码发送服务请求,验证模型效果。
#!/usr/bin/env python
import json
from websockets.sync.client import connect
def hello():
headers = {"Authorization": "<token>"}
# URL 也从EAS控制台 - 查看调用信息处获取,把 http:// 换成 ws:// 即可。
url = "ws://xxxxx.cn-wulanchabu.pai-eas.aliyuncs.com/api/predict/<service_name>"
with connect(url, additional_headers=headers) as websocket:
prompts = ["What's the capital of Canada?"]
for p in prompts:
print(f"Prompt : {p}")
websocket.send(json.dumps({"prompt": p}))
while True:
msg = websocket.recv()
msg = json.loads(msg)
if msg['is_end']:
break
print(msg['text'], end="", flush=True)
print()
print("-" * 40)
hello()其中关键参数说明如下:
headers:将<token>替换为服务Token。您可以前往PAI-EAS模型在线服务页面,单击目标服务服务方式列下的调用信息,在公网地址调用页签获取。
url:配置为已部署服务的访问地址。您可以在公网地址调用页签获取,将服务地址中的http替换为ws即可。
输出如下类似结果,您的结果以实际为准。
清理资源
测试完方案后,您可以参考以下规则处理对应产品的实例,避免继续产生费用。
停止DSW实例
登录PAI控制台。
在页面左上方,选择DSW实例的地域。
在左侧导航栏单击工作空间列表,在工作空间列表页面中单击默认工作空间名称,进入对应工作空间内。
在工作空间页面的左侧导航栏选择模型开发与训练>交互式建模(DSW),进入交互式建模(DSW)页面。
单击目标实例操作列下的停止,成功停止后即停止资源消耗。
停止EAS服务
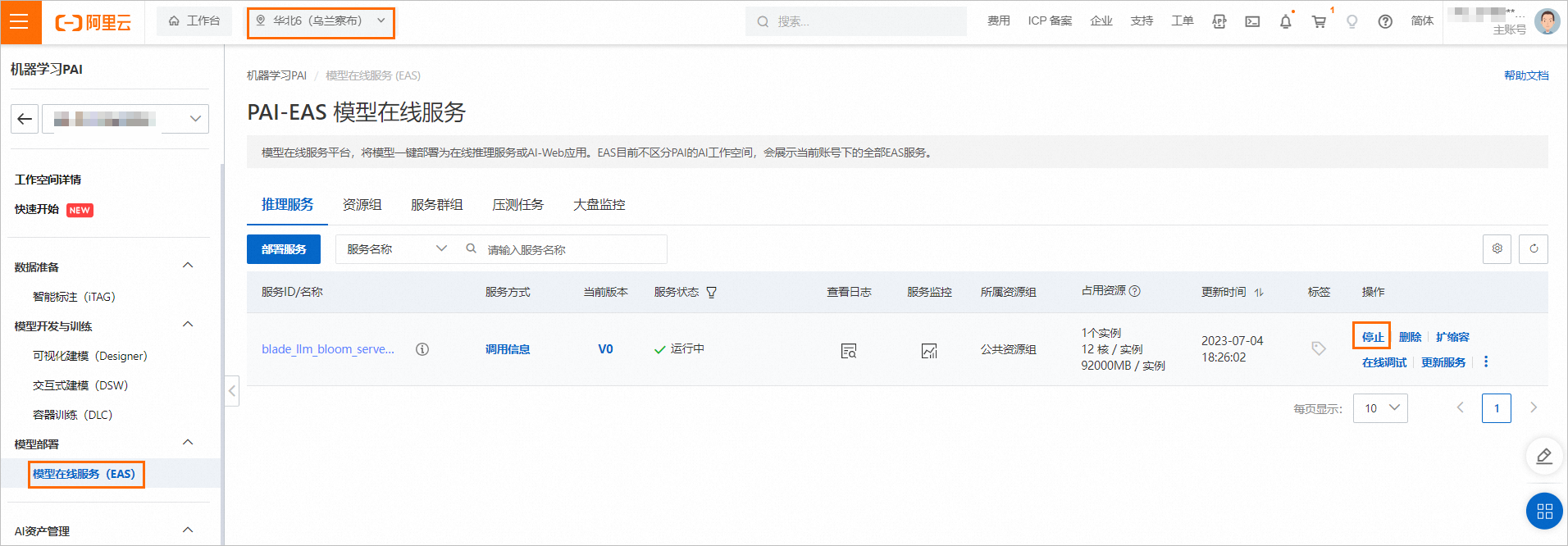
前往PAI-EAS模型在线服务页面,在页面左上角选择华北6(乌兰察布)地域。
在推理服务页签,单击目标服务操作列下的停止。成功停止后即停止资源消耗。
释放资源栈下的资源,即1个交换机、1个专有网络VPC和1个OSS Bucket。
登录ROS控制台。
在左侧导航栏,选择资源栈。
在资源栈页面的顶部选择部署的资源栈所在地域,找到资源栈,然后在其右侧操作列,单击删除。
在删除资源栈对话框,选择删除方式为释放资源,然后单击确定,根据提示完成资源释放。
删除智算CPFS文件系统。
登录NAS控制台。
在左侧导航栏,选择文件系统>文件系统列表。
在顶部菜单栏,选择地域。
在文件系统列表页面,找到目标文件系统,在操作列单击
图标 > 删除。并按照界面操作指引删除智算CPFS文件系统。