
如果您在使用阿里云百炼应用的 RAG 功能时遇到知识召回不完整或内容不准确的问题,可以参考本文的建议和示例以提升 RAG 效果。
1. RAG 流程简介
RAG(Retrieval Augmented Generation,检索增强生成)是一种结合了信息检索和文本生成的技术,能够在大模型生成答案时利用外部知识库中的相关信息。其效果由三个核心阶段决定:
建立索引:知识的解析、切片与向量化。
检索召回:根据用户查询(Prompt),从向量存储中匹配并召回相关的知识片段。
生成答案:大模型根据召回的知识片段和用户查询,生成最终答案。
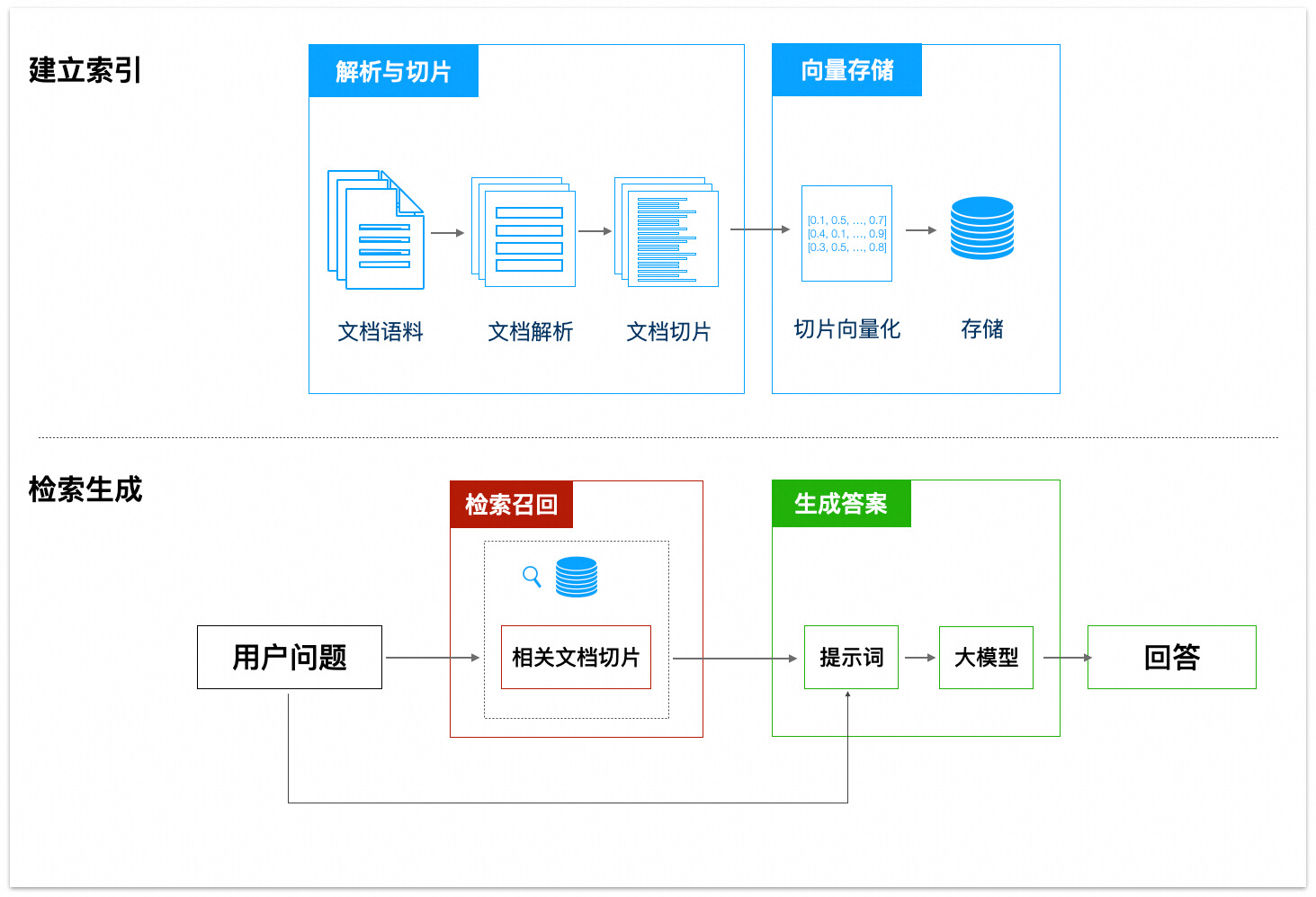
本文将围绕以上三个阶段,介绍多个优化策略,帮助您提升 RAG 的效果。
2. 建立评估基线
在优化前,须建立一套可量化的评估基准,用于客观衡量后续改进措施的效果。
创建评测集
目的:定义一套标准、可重复执行的测试用例。每个用例应包含一个问题和对应的预期结果。
操作:借助阿里云百炼提供的自动评测功能,创建至少包含 100 组问题的评测集,须覆盖核心真实提问场景,建议包含以下类型:
事实型:“产品X”的保修期是多久?
比较型:对比“产品X”和“产品Y”的主要差异。
教程型:如何安装“产品X”。
分析型:为什么近3个月“产品X”的销量在不断上升?
执行评测并记录结果
目的:记录初始配置下的 RAG 应用的表现,作为后续优化的对照组。
操作:完整运行一次评测集,并记录每个用例的召回内容与诊断结果。
完成此步骤后,你将获得一份完整的RAG基线性能报告,标明了当前配置在各测试用例上的成功与失败情况,以及诊断结果。
3. 诊断与改进
对照基线测试报告中失败的用例(大模型打分 < 4),根据诊断结果针对性改进。
3.1 检索无效:没有找到相关知识
解决方案:
包含相关知识:若知识库中没有相关知识,那么大模型大概率无法回答相关问题。解决方案就是更新知识库,补充相关知识。
优化源文件内容与排版:检查并修正源文件,避免因格式问题导致关键内容在解析时丢失。推荐实践如下:
确保各级标题层次分明,内容结构清晰。
移除页面水印。
避免使用结构复杂的表格,如包含合并或跨页单元格的表格。
优先使用 Markdown 格式。对于 PDF/DOCX 等格式,建议先转换为 Markdown 再导入。
将PDF转成Markdown:可借助阿里云百炼的DashScopeParse工具。具体使用方法详见阿里云大模型ACP课程的 RAG 章节。
与提示词语言一致:若用户的提示词/问题更多使用外语(如英语),建议源文件内容也使用相应语言。对于专业术语,可进行多语言处理。
消除实体歧义:对相同实体的表述进行统一。例如,“ML”、“Machine Learning”和“机器学习”可以统一规范为“机器学习”。
可尝试使用大模型统一规范(若内容较长,可先将其拆为多个部分,再逐一输入)。
启用“多轮对话改写”:根据历史对话自动补全用户查询,确保大模型能正确理解多轮对话中的指代和上下文省略。
3.2 检索无效:召回知识不相关
典型问题:知识库中含多个“类别”的文件。希望在A类文件中检索时,召回结果中却包含其他类别(比如B类)的文本切片。
解决方案:为文件添加标签,知识库会在向量检索前根据标签筛选相关文件。
典型问题:知识库中含多个结构内容相同/相近的文件,如文件A和文件B的内容都包含“功能概述”章节,只希望在A文件的“功能概述”中检索。
解决方案:为文件定义元数据,知识库会在检索前使用元数据进行结构化搜索,从而精准定位目标文件并提取相关信息。
3.3 切片不完整
导入知识库的文件会被解析和切片,以减少后续向量化过程中干扰信息影响,同时保持语义的完整性。切片方式选取不当会导致以下问题:
文本切片过短 | 文本切片过长 | 明显的语义截断 |
切片样例:单个切片仅包含『参考售价:5999』一句,缺失产品名称等关键上下文信息。 | 切片样例:单个切片同时混合了百炼 Ace Ultra、百炼 Zephyr Z9、百炼 Flex Fold+ 等多款手机的完整介绍,主题相互干扰。 | 切片样例:切片01 末尾停在『内置10GB RAM 与』,后续配置信息被强制截断,导致语义不完整。 |
文本切片过短会出现语义缺失,导致检索时无法匹配。 | 文本切片过长会包含不相关主题,导致召回时返回无关信息。 | 文本切片出现了强制性的语义截断,导致召回时缺失内容。 |
在实际应用中,应尽量让文本切片包含的信息完整,同时避免包含过多的干扰信息。
解决方案:
采用“智能切分”策略:基于语义相关性进行切分,有助于保留语义完整性。
人工检查和修正文本切片内容:确保文件被正确地解析和切分。
3.4 重排不佳
在知识库找到和用户提示词相关的文本切片后,会先将它们发送给重排模型(Rank模型)进行重排序,而相似度阈值则用于筛选经过Rank模型重排序后返回的文本切片,只有相似度分数超过此阈值的文本切片才有可能被提供给大模型。
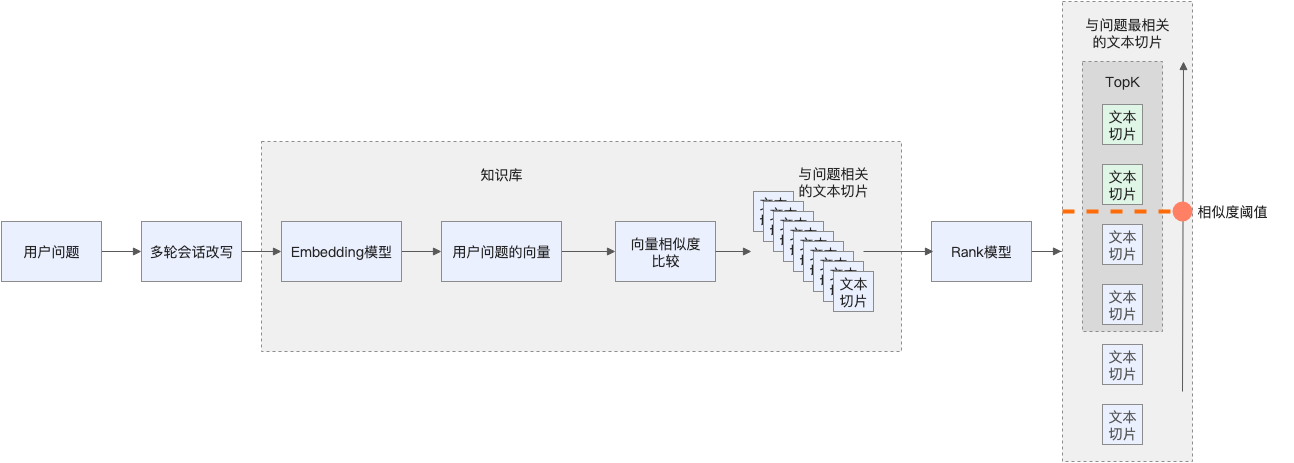
调低此阈值,预期会召回更多文本切片,但也可能召回一些相关度较低的文本切片;提高此阈值,预期会减少召回的文本切片。
若该值设置得过高,知识库可能会丢弃所有相关的文本切片,这将限制大模型获取足够背景信息生成回答。
例如,将相似度阈值调高至 0.60 后对查询进行命中测试,系统会返回无召回结果,导致所有相关切片均被丢弃。
解决方案:
提高“相似度阈值”:放宽召回条件,避免因过滤标准过于严格而导致漏召回。
没有最好的阈值,只有最适合您场景的阈值。您需要通过命中测试反复试验不同的相似度阈值,观察召回结果,找到最适合您需求的方案。
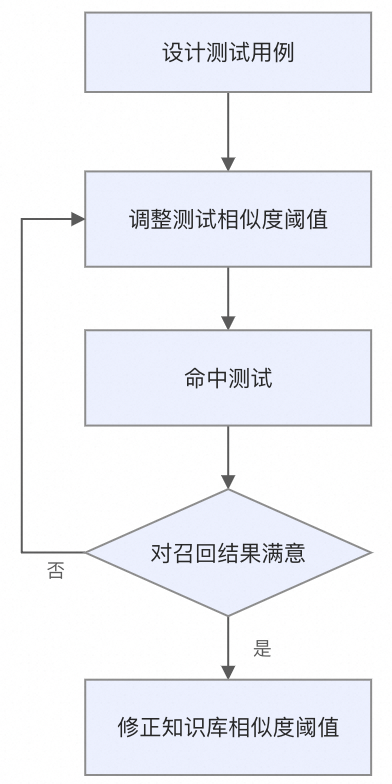
命中测试建议步骤
设计能够覆盖客户常见问题的测试用例;
根据知识库的具体应用场景和前期导入文档的质量,选择一个合适的相似度阈值;
执行命中测试,查看知识库召回结果;
基于召回结果,重新调整您的知识库的相似度阈值,具体操作请参见编辑知识库。
提高“召回片段数”:对于需要总结、列举或比较的复杂问题,适当增加该值有助于大模型生成更完整的答案。
召回片段数即多路召回策略中的K值。经过前面的相似度阈值筛选后,如果文本切片数量超过K,系统最终会选取相似度分数最高的 K 个文本切片提供给大模型。也正因为此,不合适的K值也可能会导致 RAG 漏掉正确的文本切片,从而影响大模型生成完整的回答。
比如下面的这个例子,用户通过以下提示词进行检索:
阿里云百炼X1手机有什么优势?从下方示意图可以看到,目标知识库中实际与用户提示词相关,需要返回的文本切片总共有7个(下图左侧,已用绿色标出),但由于已经超出了当前设定的最大召回片段数K,因此包含优势5(超长待机)和优势6(拍照清晰)的文本切片被舍弃,没有提供给大模型。

由于 RAG 本身无法判断需要多少个文本切片才能给出“完整”的答案,因此即使最终提供的文本切片有遗漏,随后大模型仍然会基于缺失的文本切片生成不完整的回答。
大量实验结果表明:在诸如“列举...”、“总结...”,“比较一下X、Y...”等场景中,提供更多高质量的文本切片(例如K=20)给大模型,比仅提供前10个或前5个文本切片效果更好。虽然这样做可能会引入噪声信息,但如果文本切片质量较高的话,大模型通常能够有效抵消噪声信息的影响。
您可以在调试阿里云百炼应用时调整召回片段数。
调整值后,需手动点击页面右上方的保存,使设置生效。
在智能体应用编辑页面的知识模块右侧,单击调试按钮进入文档知识库调试界面。
在文档知识库调试界面的拼装策略中,拖动召回片段数(个)滑块即可调整 K 值(取值范围 1-20)。
请注意,召回片段数也并非越大越好。因为有时召回的文本切片在拼装后,其总长度会超出大模型的输入长度限制,导致部分文本切片被截断,反而影响了 RAG 的效果。
因此,推荐您选择按拼装长度。这一策略会在不超过大模型最大输入长度的前提下,尽可能多地为您召回相关的文本切片。
3.5 模型理解有误
典型问题:大模型并未理解知识和用户提示词之间的关系,感觉答案是生硬拼凑的。
解决方案:更换生成模型,从而有效地理解知识和用户的提示词之间的关系。
典型问题:返回的结果没有按照要求,或者不够全面。
解决方案:优化提示词模板。通过调整提示词来影响大模型的行为(例如怎样利用检索到的知识等),间接提升 RAG 的效果。
典型问题:返回的结果中包含了大模型自身的通用知识,并未严格基于知识库。
解决方案:开启拒识,仅限于根据知识库检索到的知识回答。
典型问题:提示词相同,希望每次返回的结果相同或不同。
解决方案:调整大模型参数。
4. 后续步骤
4.1 持续迭代
重新评估:建议每次完成配置变更后,重新运行前面步骤中创建的评测集。
对比分析:并将结果与基线报告进行对比,量化分析变更带来的效果(解决了哪些问题、是否引入了新问题)。
持续迭代:根据数据分析结果,决定下一步的优化策略。
4.2 模型调优
最后,如果上述方法均已尝试且希望进一步提升效果,可考虑针对具体场景,选择一个大模型进行模型调优。