调优后的模型需要经过部署才能提供推理服务。模型部署后,将提供高并发、低延迟的推理服务。
本文档仅适用于中国大陆版(北京地域)。

支持的模型
模型类别 | 支持的模型 | 为什么选择模型部署 |
预置模型 (阿里云百炼支持的标准模型) |
| 获得高并发量、高推理性能(低延迟)的推理服务。 |
自定义模型 (阿里云百炼平台调优后的模型) | 部署后,模型才能用于推理或评测。 获得高并发量、高推理性能(低延迟)的推理服务。 |
如果需要部署更多其他模型,请参考解决方案并结合具体业务需求选择最适合的部署方案。
支持的计费方式
计费方式 | 支持的模型 | 是否支持自助扩缩容 (即最大并发量可动态调节) | 计费最小单位 | 优点 | 缺点 |
包时(后付费) | 所有可部署模型 | 支持 | 小时 | - | - |
包月(预付费) | 部分可部署模型 | 支持 | 天 |
| - |
按调用量(后付费) | 只支持部分基于通义千问 2、通义2.5的自定义模型 | 不支持 提高最大并发量需要在控制台提交申请,并等待阿里云百炼平台的人工审核。 | token |
|
|
选择包时(后付费)时,即使不调用模型,部署服务仍将持续运行并产生费用。如您不再需要,请立即下线部署服务,以免产生预期之外的费用。
计费详情
按时间计费
按模型调用量计费
按模型调用量计费方式价格很低。而如果需要进一步增加并发量,需要部署后在模型部署控制台手动申请,平台会进行人工审批。
计费方式 | 按模型调用量 |
|
计费公式 | 费用 = 模型输入 Token 数 × 模型输入单价 + 模型输出 Token 数 × 模型输出单价(最小计费单位:1 token) |
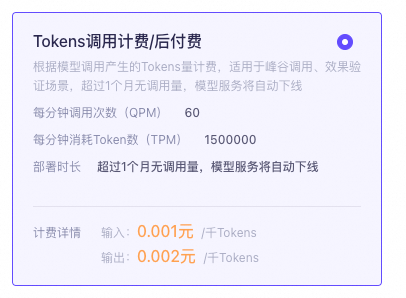
一个模型是可以在百炼的模型调优中进行重复训练的。
只有在基于以下基础模型,且只进行一次“SFT高效训练”后获得的自定义模型,才支持按调用量计费。
基础模型 | 输入单价 | 输出单价 |
通义千问3-32B | 0.002元/千Token | 非思考模式:0.008元/千Token 思考模式:0.02元/千Token |
通义千问3-14B | 0.001元/千Token | 非思考模式:0.004元/千Token 思考模式:0.01元/千Token |
通义千问3-8B | 0.0005元/千Token | 非思考模式:0.002元/千Token 思考模式:0.005元/千Token |
通义千问 2.5-72B | 0.004元/千Token | 0.012元/千Token |
通义千问 2.5-32B | 0.002元/千Token | 0.006元/千Token |
通义千问 2.5-14B | 0.001元/千Token | 0.003元/千Token |
通义千问 2.5-7B | 0.0005元/千Token | 0.001元/千Token |
通义千问2.5-VL-72B | 0.016元/千Tokens | 0.048元/千Tokens |
通义千问2.5-VL-32B | 0.008元/千Tokens | 0.024元/千Tokens |
通义千问2.5-VL-7B | 0.002元/千Tokens | 0.005元/千Tokens |
通义千问 2-开源版-7B | 0.001元/千Token | 0.002元/千Token |
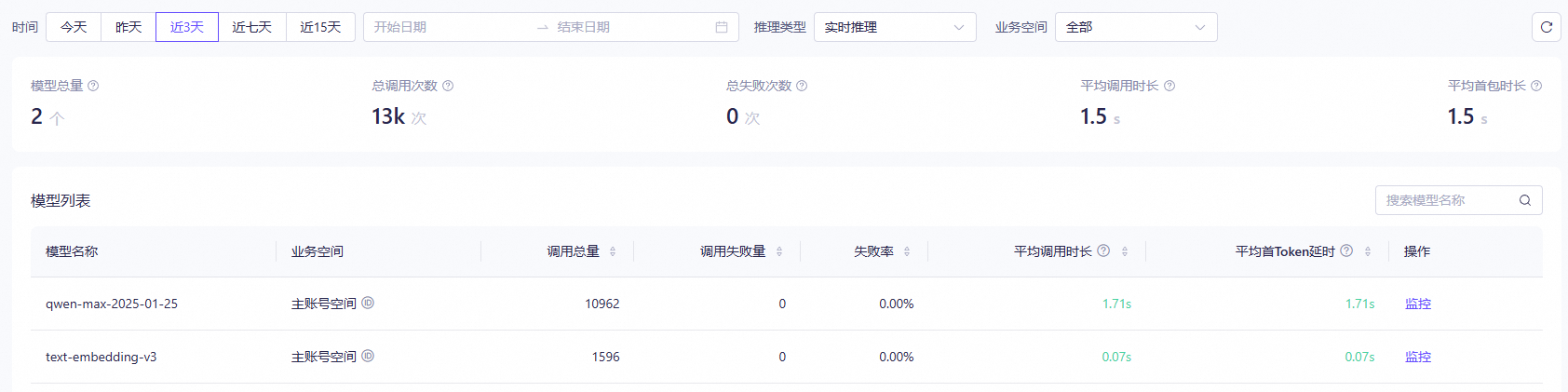
调用统计
您可以在模型观测页面查看已部署的模型的调用统计数据。
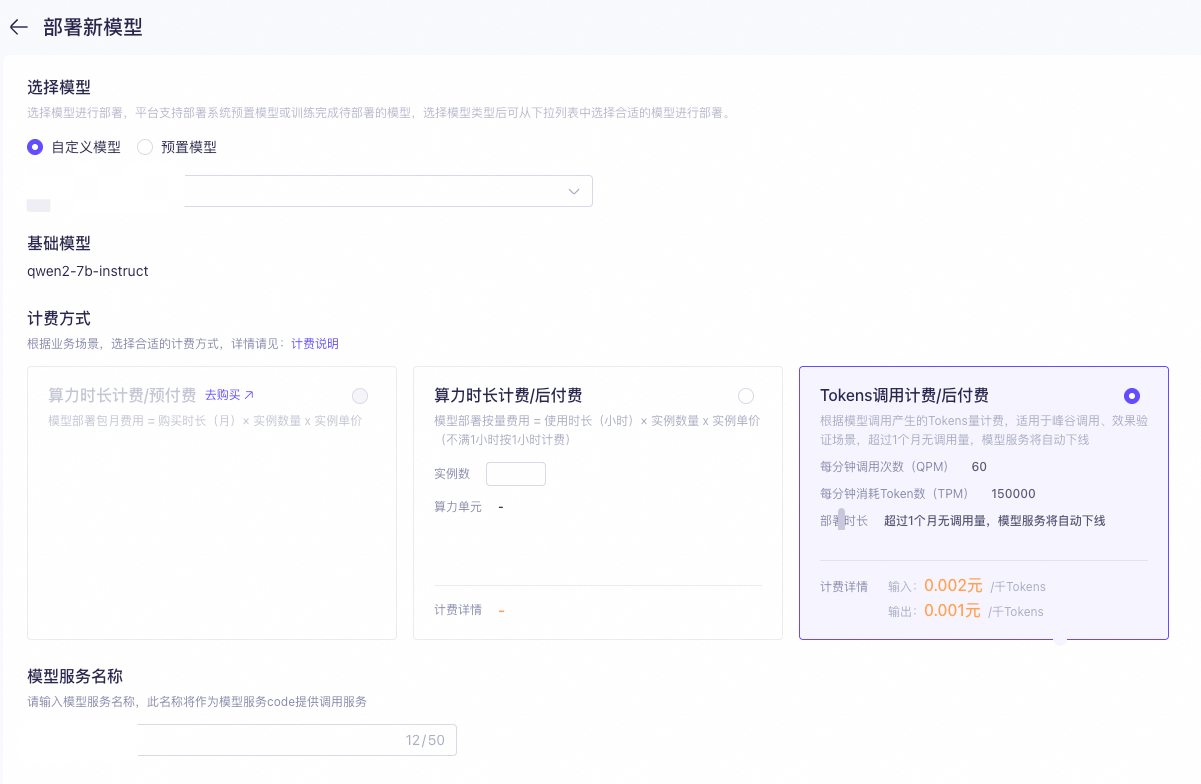
部署方法
您可以在控制台上部署模型,请参考以下操作步骤:
如果希望使用 API 部署模型请前往:使用 API 进行模型部署。
|
|
重要 开始部署后,模型部署服务将产生费用。 | |
|
部署后调用
模型部署成功后,支持通过 OpenAI 兼容、DashScope、LlamaIndex、LangChain及Assistant SDK进行调用。
在调用已部署成功的模型时,model的取值应为模型部署成功后的模型code。请您前往模型部署界面获取模型code。

示例代码以调用微调后的 qwen3-8b 模型为例:
DashScope
import os
import dashscope
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "你是谁?"},
]
response = dashscope.Generation.call(
# 若没有配置环境变量,请用百炼API Key将下行替换为:api_key="sk-xxx",
api_key=os.getenv("DASHSCOPE_API_KEY"),
model="qwen3-8b-ft-xxx-xxx", # 请替换为模型部署成功后的code
messages=messages,
result_format="message",
enable_thinking=False,
)
print(response)OpenAI兼容接口
import os
from openai import OpenAI
client = OpenAI(
# 若没有配置环境变量,请用百炼API Key将下行替换为:api_key="sk-xxx",
api_key=os.getenv('DASHSCOPE_API_KEY'),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
completion = client.chat.completions.create(
model="qwen3-8b-ft-xxx-xxx",# 请替换为模型部署成功后的code
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "你是谁?"},
],
extra_body={"enable_thinking": False}
)
print(completion)模型特性(是否支持非流式输出、结构化输出等)与微调前的模型保持一致。
部署服务扩缩容
按时间计费方式部署的模型可点击黄框的扩缩容,自助、手动调节实例数量。
按调用量计费方式部署的模型点击红框的扩容申请,填写并提交扩容申请表单,等待人工审核。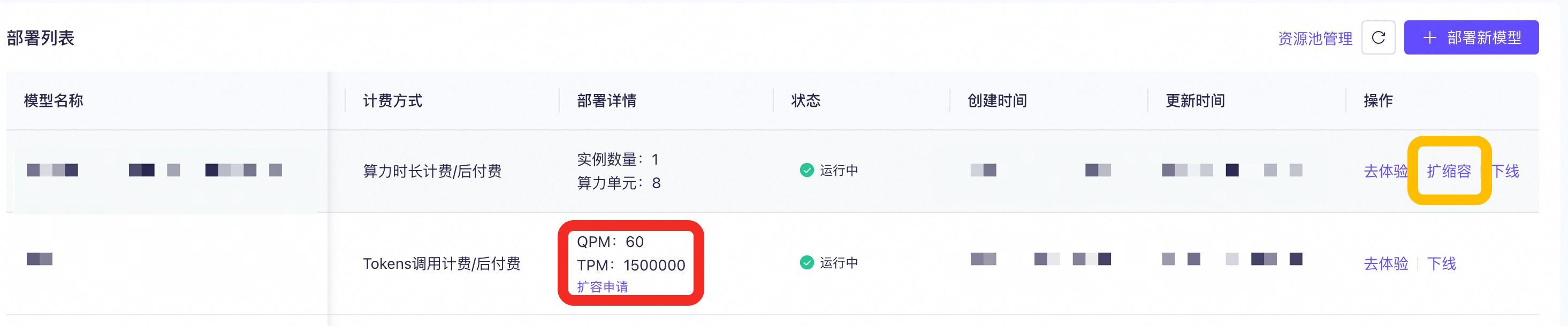
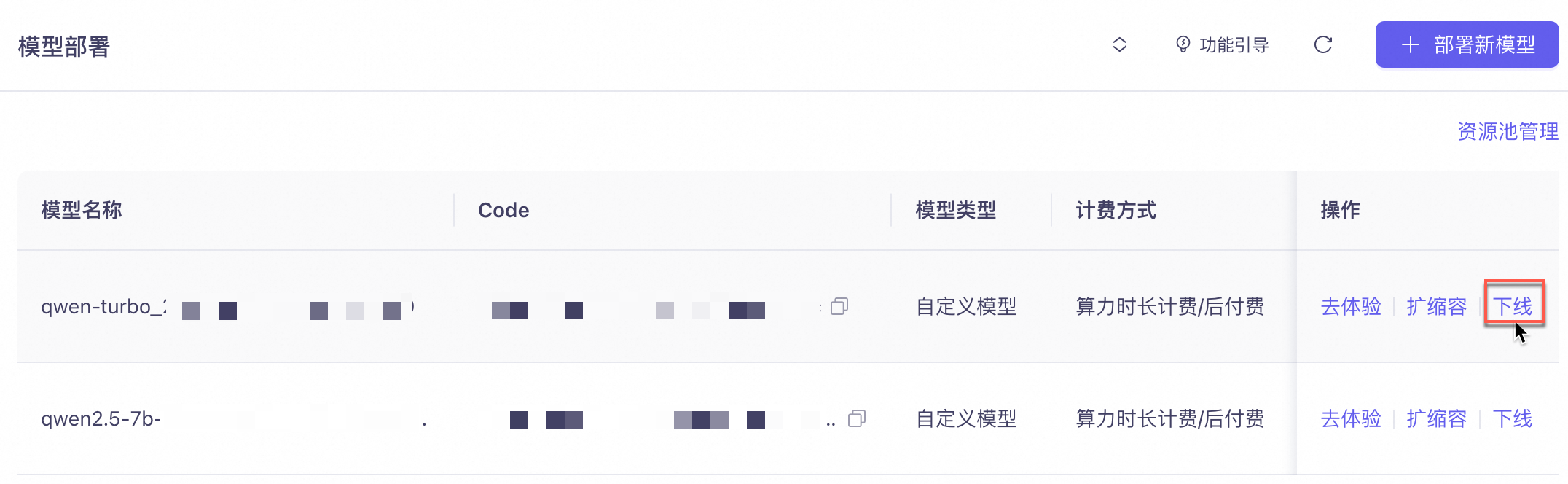
部署服务下线
如果不再需要模型部署服务,需要停止服务计费,请您按照此操作下线部署服务,下线后将不再产生计费:
|
|
|
|
常见问题
可以上传和部署自己的模型吗?
暂不支持上传和部署自有模型,建议您持续关注阿里云百炼最新动态。此外,阿里云人工智能平台 PAI 提供了部署自有模型的功能,您可以参考PAI模型部署与推理了解部署方法。