
参数服务器PS(Parameter Server)致力于解决大规模的离线及在线训练任务,SMART(Scalable Multiple Additive Regression Tree)是GBDT(Gradient Boosting Decision Tree)基于PS实现的迭代算法。PS-SMART支持百亿样本及几十万特征的训练任务,可以在上千节点中运行。同时,PS-SMART支持多种数据格式及直方图近似等优化技术。
使用限制
支持的计算引擎为MaxCompute。
使用说明
PS-SMART二分类训练组件的目标列仅支持数值类型,且0表示负例,1表示正例。如果MaxCompute表数据是STRING类型,则需要进行类型转换。例如,分类目标是Good/Bad字符串,需要转换为1/0。
如果数据是KV格式,则特征ID必须为正整数,特征值必须为实数。如果特征ID为字符串类型,则需要使用序列化组件进行序列化。如果特征值为类别型字符串,需要进行特征离散化等特征工程处理。
虽然PS-SMART二分类训练组件支持数十万特征任务,但是消耗资源大且运行速度慢,可以使用GBDT类算法进行训练。GBDT类算法适合直接使用连续特征进行训练,除需要对类别特征进行One-Hot编码(筛除低频特征)以外,不建议对其他连续型数值特征进行离散化。
PS-SMART算法会引入随机性。例如,data_sample_ratio及fea_sample_ratio表示的数据和特征采样、算法使用的直方图近似优化及局部Sketch归并为全局Sketch的顺序随机性。虽然多个worker分布式执行时,树结构不同,但是从理论上可以保证模型效果相近。如果您在训练过程中,使用相同数据和参数,多次得到的结果不一致,属于正常现象。
如果需要加速训练,可以增大计算核心数。因为PS-SMART算法需要所有服务器获得资源后,才能开始训练,所以集群忙碌时,申请较多资源会增加等待时间。
组件配置
您可以使用以下任意一种方式,配置PS-SMART二分类组件参数。
方式一:可视化方式
在Designer工作流页面配置组件参数。
页签 | 参数 | 描述 |
字段设置 | 是否稀疏格式 | 稀疏格式的KV之间使用空格分隔,key与value之间使用英文冒号(:)分隔。例如1:0.3 3:0.9。 |
选择特征列 | 输入表中,用于训练的特征列。如果输入数据是Dense格式,则只能选择数值(BIGINT或DOUBLE)类型。如果输入数据是Sparse KV格式,且key和value是数值类型,则只能选择STRING类型。 | |
选择标签列 | 输入表的标签列,支持STRING及数值类型。但列存储内容仅支持数值类型,例如二分类中的0和1。 | |
选择权重列 | 列可以对每行样本进行加权,支持数值类型。 | |
参数设置 | 评估指标类型 | 支持以下几种类型:
|
树数量 | 需要配置为树数量,正整数,树数量和训练时间成正比。 | |
树最大深度 | 默认值为5,即最多16个叶子节点。取值为正整数。 | |
数据采样比例 | 构建每棵树时,采样部分数据进行学习,构建弱学习器,从而加快训练。 | |
特征采样比例 | 构建每棵树时,采样部分特征进行学习,构建弱学习器,从而加快训练。 | |
L1惩罚项系数 | 控制叶子节点大小。该参数值越大,叶子节点规模分布越均匀。如果过拟合,则增大该参数值。 | |
L2惩罚项系数 | 控制叶子节点大小。该参数值越大,叶子节点规模分布越均匀。如果过拟合,则增大该参数值。 | |
学习速率 | 取值范围为(0,1)。 | |
近似Sketch精度 | 构造Sketch的切割分位点阈值。该参数值越小,获得的桶越多。一般使用默认值0.03,无需手动配置。 | |
最小分裂损失变化 | 分裂节点所需要的最小损失变化。该参数值越大,分裂越保守。 | |
特征数量 | 特征数量或最大特征ID。如果估计使用资源时,未配置该参数,则系统会启动SQL任务自动计算。 | |
全局偏置项 | 所有样本的初始预测值。 | |
随机数产生器种子 | 随机数种子,整型。 | |
特征重要性类型 | 支持以下几种类型:
| |
执行调优 | 计算核心数 | 默认为系统自动分配。 |
每个核内存大小 | 单个核心使用的内存,单位为MB。通常无需手动配置,系统会自动分配。 |
方式二:PAI命令方式
使用PAI命令方式,配置该组件参数。您可以使用SQL脚本组件进行PAI命令调用,详情请参见SQL脚本。
#训练。
PAI -name ps_smart
-project algo_public
-DinputTableName="smart_binary_input"
-DmodelName="xlab_m_pai_ps_smart_bi_545859_v0"
-DoutputTableName="pai_temp_24515_545859_2"
-DoutputImportanceTableName="pai_temp_24515_545859_3"
-DlabelColName="label"
-DfeatureColNames="f0,f1,f2,f3,f4,f5"
-DenableSparse="false"
-Dobjective="binary:logistic"
-Dmetric="error"
-DfeatureImportanceType="gain"
-DtreeCount="5"
-DmaxDepth="5"
-Dshrinkage="0.3"
-Dl2="1.0"
-Dl1="0"
-Dlifecycle="3"
-DsketchEps="0.03"
-DsampleRatio="1.0"
-DfeatureRatio="1.0"
-DbaseScore="0.5"
-DminSplitLoss="0";
#预测。
PAI -name prediction
-project algo_public
-DinputTableName="smart_binary_input"
-DmodelName="xlab_m_pai_ps_smart_bi_545859_v0"
-DoutputTableName="pai_temp_24515_545860_1"
-DfeatureColNames="f0,f1,f2,f3,f4,f5"
-DappendColNames="label,qid,f0,f1,f2,f3,f4,f5"
-DenableSparse="false"
-Dlifecycle="28";模块 | 参数 | 是否必选 | 描述 | 默认值 |
数据参数 | featureColNames | 是 | 输入表中,用于训练的特征列。如果输入表是Dense格式,则只能选择数值(BIGINT或DOUBLE)类型。如果输入表是Sparse KV格式,且KV格式中key和value是数值类型,则只能选择STRING类型。 | 无 |
labelColName | 是 | 输入表的标签列,支持STRING及数值类型。如果是内部存储,则仅支持数值类型。例如二分类中的0和1。 | 无 | |
weightCol | 否 | 列可以对每行样本进行加权,支持数值类型。 | 无 | |
enableSparse | 否 | 是否为稀疏格式,取值范围为{true,false}。稀疏格式的KV之间使用空格分隔,key与value之间使用英文冒号(:)分隔。例如1:0.3 3:0.9。 | false | |
inputTableName | 是 | 输入表的名称。 | 无 | |
modelName | 是 | 输出的模型名称。 | 无 | |
outputImportanceTableName | 否 | 输出特征重要性的表名。 | 无 | |
inputTablePartitions | 否 | 格式为ds=1/pt=1。 | 无 | |
outputTableName | 否 | 输出至MaxCompute的表,二进制格式,不支持读取,只能通过SMART的预测组件获取。 | 无 | |
lifecycle | 否 | 输出表的生命周期,单位为天。 | 3 | |
算法参数 | objective | 是 | 目标函数类型。如果进行二分类训练,则选择binary:logistic。 | 无 |
metric | 否 | 训练集的评估指标类型,输出在Logview文件Coordinator区域的stdout。支持以下类型:
| 无 | |
treeCount | 否 | 树数量,与训练时间成正比。 | 1 | |
maxDepth | 否 | 树的最大深度,正整数,取值范围为1~20。 | 5 | |
sampleRatio | 否 | 数据采样比例,取值范围为(0,1]。如果取值为1.0,则表示不采样。 | 1.0 | |
featureRatio | 否 | 特征采样比例,取值范围为(0,1]。如果取值为1.0,则表示不采样。 | 1.0 | |
l1 | 否 | L1惩罚项系数。该参数值越大,叶子节点分布越均匀。如果过拟合,则增大该参数值。 | 0 | |
l2 | 否 | L2惩罚项系数。该参数值越大,叶子节点分布越均匀。如果过拟合,则增大该参数值。 | 1.0 | |
shrinkage | 否 | 取值范围为(0,1)。 | 0.3 | |
sketchEps | 否 | 构造Sketch的切割分位点阈值,桶数为O(1.0/sketchEps)。该参数值越小,获得的桶越多。一般使用默认值,无需手动配置。取值范围为(0,1)。 | 0.03 | |
minSplitLoss | 否 | 分裂节点所需要的最小损失变化。该参数值越大,分裂越保守。 | 0 | |
featureNum | 否 | 特征数量或最大特征ID。如果估计使用资源时,未配置该参数,则系统会启动SQL任务自动计算。 | 无 | |
baseScore | 否 | 所有样本的初始预测值。 | 0.5 | |
randSeed | 否 | 随机数种子,整型。 | 无 | |
featureImportanceType | 否 | 计算特征重要性的类型,包括:
| gain | |
调优参数 | coreNum | 否 | 核心数量,该参数值越大,算法运行越快。 | 系统自动分配 |
memSizePerCore | 否 | 每个核心使用的内存,单位为MB。 | 系统自动分配 |
示例
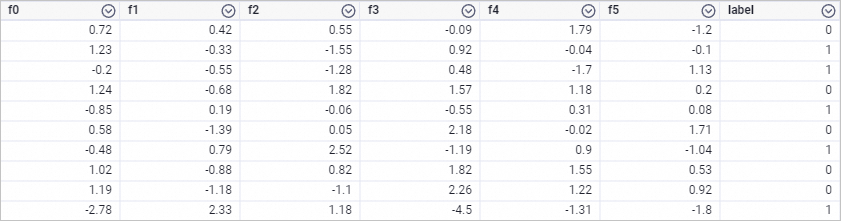
使用ODPS SQL节点执行如下SQL语句,生成训练数据(以Dense格式数据为例)。
drop table if exists smart_binary_input; create table smart_binary_input lifecycle 3 as select * from ( select 0.72 as f0, 0.42 as f1, 0.55 as f2, -0.09 as f3, 1.79 as f4, -1.2 as f5, 0 as label union all select 1.23 as f0, -0.33 as f1, -1.55 as f2, 0.92 as f3, -0.04 as f4, -0.1 as f5, 1 as label union all select -0.2 as f0, -0.55 as f1, -1.28 as f2, 0.48 as f3, -1.7 as f4, 1.13 as f5, 1 as label union all select 1.24 as f0, -0.68 as f1, 1.82 as f2, 1.57 as f3, 1.18 as f4, 0.2 as f5, 0 as label union all select -0.85 as f0, 0.19 as f1, -0.06 as f2, -0.55 as f3, 0.31 as f4, 0.08 as f5, 1 as label union all select 0.58 as f0, -1.39 as f1, 0.05 as f2, 2.18 as f3, -0.02 as f4, 1.71 as f5, 0 as label union all select -0.48 as f0, 0.79 as f1, 2.52 as f2, -1.19 as f3, 0.9 as f4, -1.04 as f5, 1 as label union all select 1.02 as f0, -0.88 as f1, 0.82 as f2, 1.82 as f3, 1.55 as f4, 0.53 as f5, 0 as label union all select 1.19 as f0, -1.18 as f1, -1.1 as f2, 2.26 as f3, 1.22 as f4, 0.92 as f5, 0 as label union all select -2.78 as f0, 2.33 as f1, 1.18 as f2, -4.5 as f3, -1.31 as f4, -1.8 as f5, 1 as label ) tmp;生成的训练数据如下。
构建如下工作流,并运行组件,详情请参见算法建模。
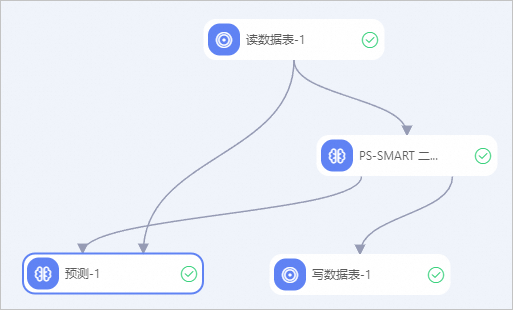
在Designer左侧组件列表中,分别搜索读数据表组件、PS-SMART二分类训练组件、预测组件、写数据表组件,并拖入右侧画布中。
参照上图,通过连线的方式,将各个节点组织构建成为一个有上下游关系的工作流。
配置组件参数。
在画布中单击读数据表-1组件,在右侧表选择页签,配置表名为smart_binary_input。
在画布中单击PS-SMART二分类训练-1组件,在右侧配置如下表中的参数,其余参数使用默认值。
页签
参数
描述
字段设置
特征列
选择f0、f1、f2、f3、f4、及f5列。
标签列
选择label列。
参数设置
评估指标类型
选择Area under curve for classification。
树数量
输入5。
在画布中单击预测-1组件,在右侧字段设置页签,选择原样输出列为全选。其余参数使用默认值。
在画布中单击写数据表-1组件,在右侧表选择页签,配置写入表表名为smart_binary_output。
参数配置完成后,单击运行按钮
 ,运行工作流。
,运行工作流。
右键单击预测-1组件,在快捷菜单中,选择,查看预测结果。
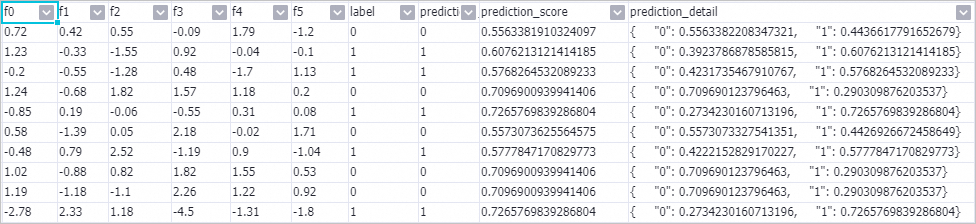 其中prediction_detail列的1表示正例,0表示负例。
其中prediction_detail列的1表示正例,0表示负例。右键单击PS-SMART二分类训练-1组件,在快捷菜单,选择,查看特征重要性表。
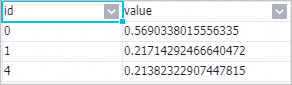 其中:
其中:id:表示传入的特征序号。因为该示例传入的特征为f0、f1、f2、f3、f4及f5,所以id列的0表示f0特征列,id列的4表示f4特征列。如果输入数据是KV格式,则id列表示KV中的key。
value:表示特征重要性类型,默认为gain,即该特征对模型带来的信息增益之和。
该特性重要性表中仅有3个特性,表示树在分裂过程中仅使用了这三个特性,可以认为其他特性的特征重要性为0。
PS-SMART模型部署说明
如果您需要将PS-SMART组件生成的模型部署为在线服务,您需要在该组件的下游接入通用模型导出组件,并按照PS系列组件的使用方式配置组件参数,详情请参见通用模型导出。
组件运行成功后,您可以前往PAI EAS模型在线服务页面,部署模型服务,详情请参见服务部署:控制台。
相关文档
关于Designer组件更详细的内容介绍,请参见Designer概述。
Designer预置了多种算法组件,你可以根据不同的使用场景选择合适的组件进行数据处理,详情请参见组件参考:所有组件汇总。