通过OSS数据索引,您可以高效统计海量文件的数量、大小等信息,相较传统的ListObjects接口统计方式,显著提升统计效率,简化操作流程,适用于大规模数据统计场景。
方案优势
A企业在华南3(广州)地域名为mybucket的存储空间(Bucket)中,存储了2亿个按业务前缀分类的文件,共计180万个目录。使用OSS数据索引后,文件统计时间可减少83%。
传统方式 | OSS数据索引 | |
耗时 | 每日统计花费 2 小时 | 每日统计花费 20 分钟 |
复杂度 | 对于文件数量大于1000的目录,需要多次调用ListObject接口。 | 每个目录只需调用一次DoMetaQuery接口。 |
方案概览
使用OSS数据索引进行大规模数据统计的过程如下:

要实现以上过程,您只需要:
开启数据索引:OSS会帮您自动创建索引表,包含OSS元数据、自定义元数据和对象标签。
发起检索和统计:您需要设置检索条件,然后调用DoMetaQuery接口,OSS会进行快速检索。
最后,OSS会返回符合条件文件的数量、总大小和平均文件大小等统计信息,供您分析使用。
快速体验
步骤一:开启OSS数据索引
使用OSS控制台
登录OSS管理控制台。
单击Bucket 列表,然后单击目标Bucket名称。
在左侧导航栏, 选择。
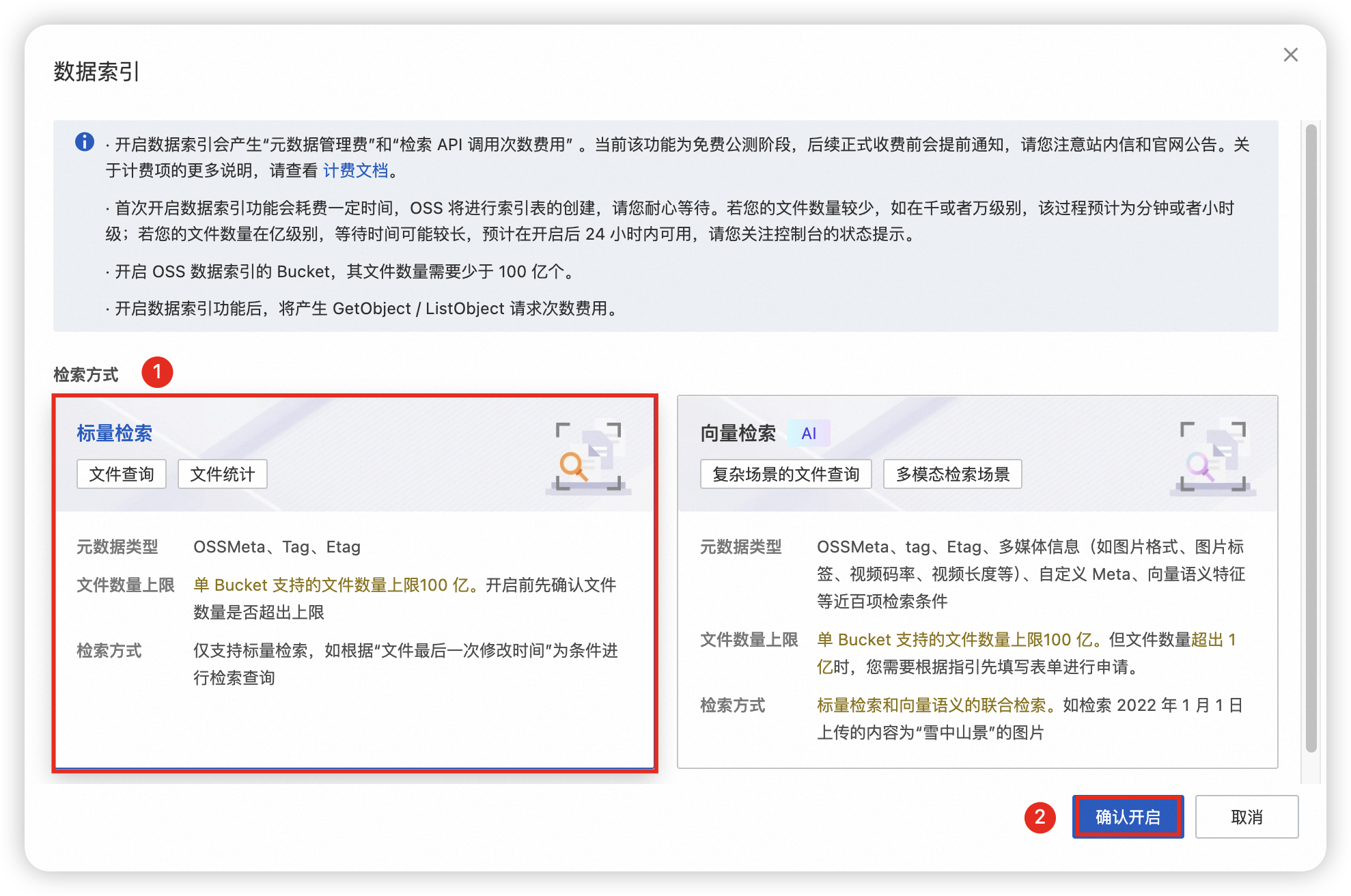
在数据索引页面,单击立即开启。
选择标量检索,单击确认开启。
使用阿里云SDK
仅Java SDK、Python SDK以及Go SDK支持通过标量检索功能查询满足指定条件的Object。
import com.aliyun.oss.*;
import com.aliyun.oss.common.auth.CredentialsProviderFactory;
import com.aliyun.oss.common.auth.EnvironmentVariableCredentialsProvider;
import com.aliyun.oss.common.comm.SignVersion;
public class Demo {
// Endpoint以华南3(广州)为例,其它Region请按实际情况填写。
private static String endpoint = "https://oss-cn-guangzhou.aliyuncs.com";
// 填写Bucket名称,例如examplebucket。
private static String bucketName = "examplebucket";
public static void main(String[] args) throws com.aliyuncs.exceptions.ClientException {
// 从环境变量中获取访问凭证。运行本代码示例之前,请确保已设置环境变量OSS_ACCESS_KEY_ID和OSS_ACCESS_KEY_SECRET。
EnvironmentVariableCredentialsProvider credentialsProvider = CredentialsProviderFactory.newEnvironmentVariableCredentialsProvider();
// 填写Bucket所在地域。以华南3(广州)为例,Region填写为cn-guangzhou。
String region = "cn-guangzhou";
// 创建OSSClient实例。
ClientBuilderConfiguration clientBuilderConfiguration = new ClientBuilderConfiguration();
clientBuilderConfiguration.setSignatureVersion(SignVersion.V4);
OSS ossClient = OSSClientBuilder.create()
.endpoint(endpoint)
.credentialsProvider(credentialsProvider)
.clientConfiguration(clientBuilderConfiguration)
.region(region)
.build();
try {
// 开启数据索引功能。
ossClient.openMetaQuery(bucketName);
} catch (OSSException oe) {
System.out.println("Error Message:" + oe.getErrorMessage());
System.out.println("Error Code:" + oe.getErrorCode());
System.out.println("Request ID:" + oe.getRequestId());
System.out.println("Host ID:" + oe.getHostId());
} catch (ClientException ce) {
System.out.println("Error Message: " + ce.getMessage());
} finally {
// 关闭OSSClient。
ossClient.shutdown();
}
}
}
# -*- coding: utf-8 -*-
import oss2
from oss2.credentials import EnvironmentVariableCredentialsProvider
# 从环境变量中获取访问凭证。运行本代码示例之前,请确保已设置环境变量OSS_ACCESS_KEY_ID和OSS_ACCESS_KEY_SECRET。
auth = oss2.ProviderAuthV4(EnvironmentVariableCredentialsProvider())
# 填写Bucket所在地域对应的Endpoint。以华南3(广州)为例,Endpoint填写为https://oss-cn-guangzhou.aliyuncs.com。
endpoint = "https://oss-cn-guangzhou.aliyuncs.com"
# 填写Endpoint对应的Region信息,例如cn-guangzhou。注意,v4签名下,必须填写该参数
region = "cn-guangzhou"
# examplebucket填写存储空间名称。
bucket = oss2.Bucket(auth, endpoint, "examplebucket", region=region)
# 开启数据索引功能。
bucket.open_bucket_meta_query()package main
import (
"fmt"
"os"
"github.com/aliyun/aliyun-oss-go-sdk/oss"
)
func main() {
// 从环境变量中获取访问凭证。运行本代码示例之前,请确保已设置环境变量OSS_ACCESS_KEY_ID和OSS_ACCESS_KEY_SECRET。
provider, err := oss.NewEnvironmentVariableCredentialsProvider()
if err != nil {
fmt.Println("Error:", err)
os.Exit(-1)
}
// 创建OSSClient实例。
// yourRegion填写Bucket所在地域,以华南3(广州)为例,填写为cn-guangzhou。其它Region请按实际情况填写。
clientOptions := []oss.ClientOption{oss.SetCredentialsProvider(&provider)}
clientOptions = append(clientOptions, oss.Region("yourRegion"))
// 设置签名版本为V4(推荐版本)。
clientOptions = append(clientOptions, oss.AuthVersion(oss.AuthV4))
// yourEndpoint填写Bucket对应的Endpoint,以华南3(广州)为例,填写为https://oss-cn-guangzhou.aliyuncs.com。其它Region请按实际情况填写。
client, err := oss.New("yourEndpoint", "", "", clientOptions...)
if err != nil {
fmt.Println("Error:", err)
os.Exit(-1)
}
//开启数据索引功能。
//填写需要开启数据索引的bucket名称,以examplebucket为例。
err = client.OpenMetaQuery("examplebucket")
if err != nil {
fmt.Println("Error:", err)
os.Exit(-1)
}
fmt.Println("Open data query success")
}
步骤二:发起检索和统计
使用OSS控制台
检索条件设置
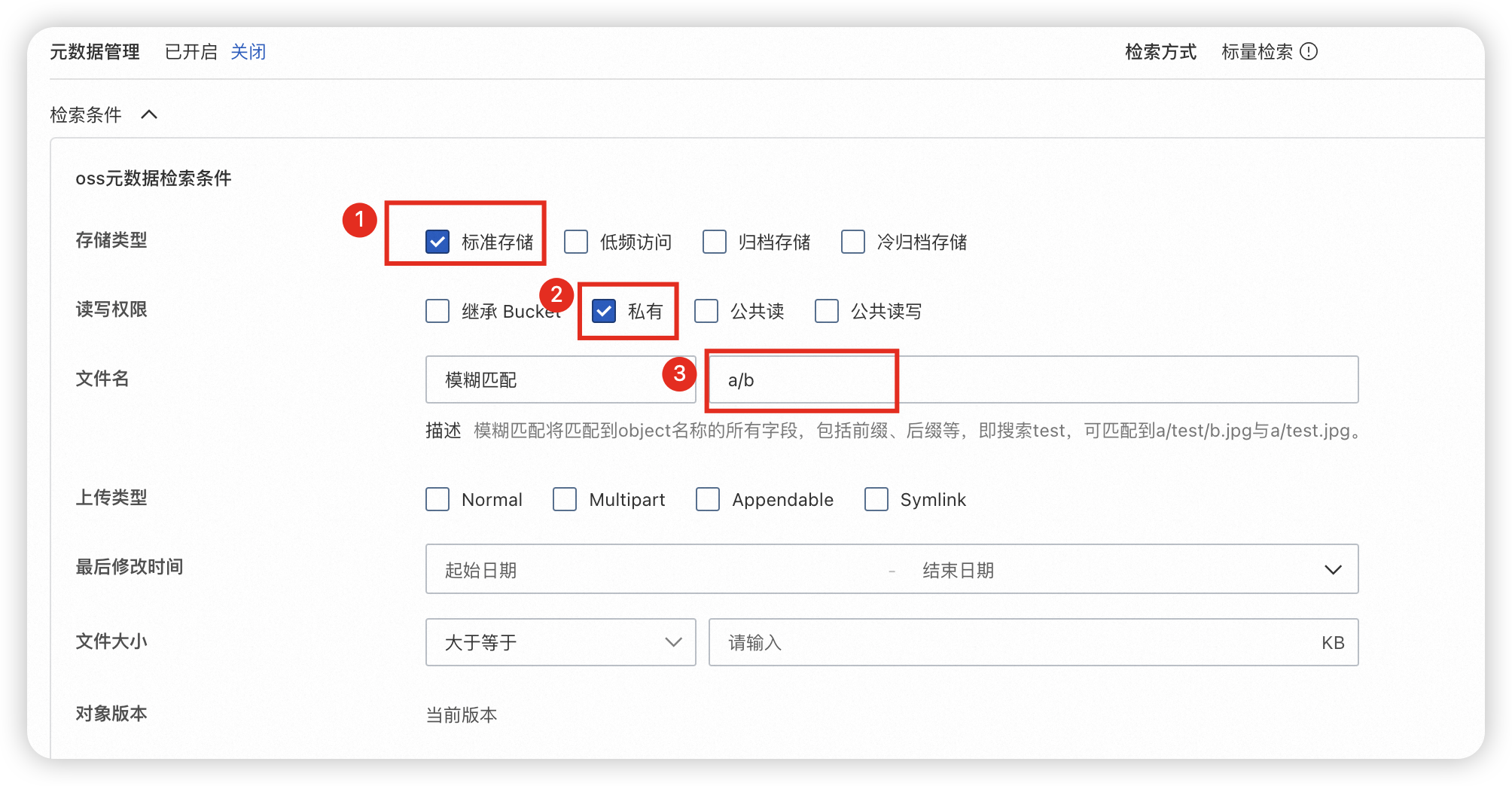
在左侧导航栏, 选择。
存储类型选择标准存储,读写权限选择私有。
通过模糊匹配目录前缀“a/b”来指定目录。
结果输出设置
按对象的最后修改时间降序排序结果。
对筛选后文件大小进行求和及平均值的计算。
按存储类型进行分组计数,以统计文件数量。

单击立即查询。
使用阿里云SDK
import com.aliyun.oss.*;
import com.aliyun.oss.common.auth.CredentialsProviderFactory;
import com.aliyun.oss.common.auth.EnvironmentVariableCredentialsProvider;
import com.aliyun.oss.common.comm.SignVersion;
import com.aliyun.oss.model.*;
import java.util.ArrayList;
import java.util.List;
public class Demo {
// Endpoint以华南3(广州)为例,其它Region请按实际情况填写。
private static String endpoint = "https://oss-cn-guangzhou.aliyuncs.com";
// 填写Bucket名称,例如examplebucket。
private static String bucketName = "examplebucket";
public static void main(String[] args) throws Exception {
// 从环境变量中获取访问凭证。运行本代码示例之前,请确保已设置环境变量OSS_ACCESS_KEY_ID和OSS_ACCESS_KEY_SECRET。
EnvironmentVariableCredentialsProvider credentialsProvider = CredentialsProviderFactory.newEnvironmentVariableCredentialsProvider();
// 填写Bucket所在地域。以华南3(广州)为例,Region填写为cn-guangzhou。
String region = "cn-guangzhou";
// 创建OSSClient实例。
ClientBuilderConfiguration clientBuilderConfiguration = new ClientBuilderConfiguration();
clientBuilderConfiguration.setSignatureVersion(SignVersion.V4);
OSS ossClient = OSSClientBuilder.create()
.endpoint(endpoint)
.credentialsProvider(credentialsProvider)
.clientConfiguration(clientBuilderConfiguration)
.region(region)
.build();
try {
// 设置查询参数,指定返回文件的最大数量(20个)
int maxResults = 20;
// 设置查询条件:文件名包含"a/b",且文件存储类型为"Standard",访问权限为"private"
// 查询语句使用逻辑运算符"and"来连接多个子查询条件
String query = "{\n" +
" \"Operation\": \"and\",\n" +
" \"SubQueries\": [\n" +
" {\n" +
" \"Field\": \"Filename\",\n" +
" \"Value\": \"a/b\",\n" +
" \"Operation\": \"match\"\n" +
" },\n" +
" {\n" +
" \"Field\": \"OSSStorageClass\",\n" +
" \"Value\": \"Standard\",\n" +
" \"Operation\": \"eq\"\n" +
" },\n" +
" {\n" +
" \"Field\": \"ObjectACL\",\n" +
" \"Value\": \"private\",\n" +
" \"Operation\": \"eq\"\n" +
" }\n" +
" ]\n" +
"}";
String sort = "FileModifiedTime";// 设置按文件修改时间排序
// 创建聚合操作实例,用于统计文件的大小(Size)的总和、数量和平均值
Aggregation aggregationRequest1 = new Aggregation();
aggregationRequest1.setField("Size");// 设置聚合字段为文件大小
aggregationRequest1.setOperation("sum");// 计算文件大小的总和
Aggregation aggregationRequest2 = new Aggregation();
aggregationRequest2.setField("Size");// 设置聚合字段为文件大小
aggregationRequest2.setOperation("count");// 计算文件数量
Aggregation aggregationRequest3 = new Aggregation();
aggregationRequest3.setField("Size");// 设置聚合字段为文件大小
aggregationRequest3.setOperation("average");// 计算文件大小的平均值
// 将所有聚合请求添加到一个列表中
Aggregations aggregations = new Aggregations();
List<Aggregation> aggregationList = new ArrayList<>();
aggregationList.add(aggregationRequest1);// 添加求和聚合
aggregationList.add(aggregationRequest2);// 添加计数聚合
aggregationList.add(aggregationRequest3);// 添加平均值聚合
aggregations.setAggregation(aggregationList);// 将所有聚合操作设置到Aggregations对象中
// 创建DoMetaQueryRequest请求对象,传入Bucket名称、最大返回文件数、查询条件和排序规则
DoMetaQueryRequest doMetaQueryRequest = new DoMetaQueryRequest(bucketName, maxResults, query, sort);
// 将聚合操作添加到Meta查询请求中
doMetaQueryRequest.setAggregations(aggregations);
// 设置排序方式为降序(DESC)
doMetaQueryRequest.setOrder(SortOrder.DESC);
// 执行Meta查询请求,获取查询结果
DoMetaQueryResult doMetaQueryResult = ossClient.doMetaQuery(doMetaQueryRequest);
// 判断查询结果
if (doMetaQueryResult.getFiles() != null) {
// 如果文件列表不为空,遍历文件信息并打印
for (ObjectFile file : doMetaQueryResult.getFiles().getFile()) {
System.out.println("Filename: " + file.getFilename()); // 文件名
System.out.println("ETag: " + file.getETag());// 文件ETag
System.out.println("ObjectACL: " + file.getObjectACL()); // 文件访问权限
System.out.println("OssObjectType: " + file.getOssObjectType());// 文件类型
System.out.println("OssStorageClass: " + file.getOssStorageClass());// 存储类型
System.out.println("TaggingCount: " + file.getOssTaggingCount()); // 标签数量
if (file.getOssTagging() != null) {
// 打印文件标签
for (Tagging tag : file.getOssTagging().getTagging()) {
System.out.println("Key: " + tag.getKey());
System.out.println("Value: " + tag.getValue());
}
}
if (file.getOssUserMeta() != null) {
// 打印用户元数据
for (UserMeta meta : file.getOssUserMeta().getUserMeta()) {
System.out.println("Key: " + meta.getKey());
System.out.println("Value: " + meta.getValue());
}
}
}
} else if (doMetaQueryResult.getAggregations() != null) {
// 如果有聚合结果,遍历并打印聚合信息
for (Aggregation aggre : doMetaQueryResult.getAggregations().getAggregation()) {
System.out.println("Field: " + aggre.getField());// 聚合字段
System.out.println("Operation: " + aggre.getOperation()); // 聚合操作
System.out.println("Value: " + aggre.getValue());// 聚合结果值
if (aggre.getGroups() != null && aggre.getGroups().getGroup().size() > 0) {
// 获取分组聚合的值。
System.out.println("Groups value: " + aggre.getGroups().getGroup().get(0).getValue());
// 获取分组聚合的总个数。
System.out.println("Groups count: " + aggre.getGroups().getGroup().get(0).getCount());
}
}
} else {
System.out.println("NextToken: " + doMetaQueryResult.getNextToken());
}
} catch (OSSException oe) {
// 捕获OSS异常并输出相关信息
System.out.println("Error Message:" + oe.getErrorMessage());
System.out.println("Error Code:" + oe.getErrorCode());
System.out.println("Request ID:" + oe.getRequestId());
System.out.println("Host ID:" + oe.getHostId());
} catch (ClientException ce) {
// 捕获客户端异常并输出错误信息
System.out.println("Error Message: " + ce.getMessage());
} finally {
// 确保关闭OSSClient实例
ossClient.shutdown();
}
}
}# -*- coding: utf-8 -*-
import oss2
from oss2.credentials import EnvironmentVariableCredentialsProvider
from oss2.models import MetaQuery, AggregationsRequest
import json
# 从环境变量中获取访问凭证。运行本代码示例之前,请确保已设置环境变量OSS_ACCESS_KEY_ID和OSS_ACCESS_KEY_SECRET。
auth = oss2.ProviderAuthV4(EnvironmentVariableCredentialsProvider())
# 填写Bucket所在地域对应的Endpoint。以华南3(广州)为例,Endpoint填写为https://oss-cn-guangzhou.aliyuncs.com。
endpoint = "https://oss-cn-guangzhou.aliyuncs.com"
# 填写Endpoint对应的Region信息,例如cn-guangzhou。注意,v4签名下,必须填写该参数
region = "cn-guangzhou"
# 填写存储空间名称,以examplebucket为例。
bucket = oss2.Bucket(auth, endpoint, "examplebucket", region=region)
# 查询条件:文件名包含"a/b",且文件存储类型为"Standard",访问权限为"private"
query = {
"Operation": "and",
"SubQueries": [
{"Field": "Filename", "Value": "a/b", "Operation": "match"},
{"Field": "OSSStorageClass", "Value": "Standard", "Operation": "eq"},
{"Field": "ObjectACL", "Value": "private", "Operation": "eq"}
]
}
# 将字典转换为JSON字符串
query_json = json.dumps(query)
# 创建聚合操作实例,用于统计文件的大小(Size)的总和、数量和平均值
aggregations = [
AggregationsRequest(field="Size", operation="sum"), # 计算文件大小的总和
AggregationsRequest(field="Size", operation="count"), # 计算文件的数量
AggregationsRequest(field="Size", operation="average") # 计算文件大小的平均值
]
# 创建MetaQuery请求对象,指定查询条件、最大返回文件数、排序字段和方式以及聚合操作
do_meta_query_request = MetaQuery(
max_results=20, # 返回最多20个文件
query=query_json, # 设置查询条件
sort="FileModifiedTime", # 按文件修改时间排序
order="desc", # 降序排序
aggregations=aggregations # 设置聚合操作
)
# 执行Meta查询请求,获取查询结果
result = bucket.do_bucket_meta_query(do_meta_query_request)
# 打印查询结果中满足条件的文件信息
if result.files:
for file in result.files:
print(f"Filename: {file.file_name}") # 打印文件名
print(f"ETag: {file.etag}") # 打印文件的ETag
print(f"ObjectACL: {file.object_acl}") # 打印文件的访问控制列表(ACL)
print(f"OssObjectType: {file.oss_object_type}") # 打印文件的OSS对象类型
print(f"OssStorageClass: {file.oss_storage_class}") # 打印文件的存储类型
print(f"TaggingCount: {file.oss_tagging_count}") # 打印文件的标签数量
# 打印文件的所有标签
if file.oss_tagging:
for tag in file.oss_tagging:
print(f"Key: {tag.key}") # 打印标签的Key
print(f"Value: {tag.value}") # 打印标签的Value
# 打印文件的用户元数据
if file.oss_user_meta:
for meta in file.oss_user_meta:
print(f"Key: {meta.key}") # 打印用户元数据的Key
print(f"Value: {meta.value}") # 打印用户元数据的Value
# 打印聚合结果
if result.aggregations:
for aggre in result.aggregations:
print(f"Field: {aggre.field}") # 打印聚合操作字段
print(f"Operation: {aggre.operation}") # 打印聚合操作类型(如sum、count、average)
print(f"Value: {aggre.value}") # 打印聚合结果值package main
import (
"encoding/json" // 导入 json 包
"fmt"
"os"
"github.com/aliyun/aliyun-oss-go-sdk/oss"
)
func main() {
// 从环境变量中获取访问凭证。运行本代码示例之前,请确保已设置环境变量OSS_ACCESS_KEY_ID和OSS_ACCESS_KEY_SECRET。
provider, err := oss.NewEnvironmentVariableCredentialsProvider()
if err != nil {
fmt.Println("Error:", err)
os.Exit(-1)
}
region := "cn-guangzhou" // 设置Region,以华南3(广州)为例,填写cn-guangzhou
endpoint := "https://oss-cn-guangzhou.aliyuncs.com" // 设置Bucket对应的Endpoint,以华南3(广州)为例,填写https://oss-cn-guangzhou.aliyuncs.com
bucketName := "examplebucket" // 设置Bucket名称,例如examplebucket
// 创建OSSClient实例。
clientOptions := []oss.ClientOption{oss.SetCredentialsProvider(&provider)}
clientOptions = append(clientOptions, oss.Region(region))
// 设置签名版本V4
clientOptions = append(clientOptions, oss.AuthVersion(oss.AuthV4))
client, err := oss.New(endpoint, "", "", clientOptions...)
if err != nil {
fmt.Println("Error:", err)
os.Exit(-1)
}
// 构建查询条件,文件名包含"a/b",存储类型为"Standard",访问权限为"private"
query := map[string]interface{}{
"Operation": "and",
"SubQueries": []map[string]interface{}{
{"Field": "Filename", "Value": "a/b", "Operation": "match"},
{"Field": "OSSStorageClass", "Value": "Standard", "Operation": "eq"},
{"Field": "ObjectACL", "Value": "private", "Operation": "eq"},
},
}
// 将查询条件转为JSON字符串
queryJSON, err := json.Marshal(query)
if err != nil {
fmt.Println("Error:", err)
os.Exit(-1)
}
// 创建聚合操作,用于统计文件大小的总和、数量和平均值
aggregations := []oss.MetaQueryAggregationRequest{
{Field: "Size", Operation: "sum"}, // 计算文件大小总和
{Field: "Size", Operation: "count"}, // 计算文件数量
{Field: "Size", Operation: "average"}, // 计算文件大小平均值
}
// 创建MetaQuery请求对象
metaQueryRequest := oss.MetaQuery{
MaxResults: 20, // 返回最多20个文件
Query: string(queryJSON), // 设置查询条件
Sort: "FileModifiedTime", // 按文件修改时间排序
Order: "desc", // 降序排序
Aggregations: aggregations, // 设置聚合操作
}
// 执行Meta查询请求,获取查询结果
result, err := client.DoMetaQuery(bucketName, metaQueryRequest)
if err != nil {
fmt.Println("Error:", err)
os.Exit(-1)
}
// 打印NextToken(用于分页查询)
if result.NextToken != "" {
fmt.Printf("NextToken: %s\n", result.NextToken)
}
// 打印查询结果中满足条件的文件信息
for _, file := range result.Files {
fmt.Printf("Filename: %s\n", file.Filename)
fmt.Printf("ETag: %s\n", file.ETag)
fmt.Printf("ObjectACL: %s\n", file.ObjectACL)
fmt.Printf("OssObjectType: %s\n", file.OssObjectType)
fmt.Printf("OssStorageClass: %s\n", file.OssStorageClass)
fmt.Printf("TaggingCount: %d\n", file.OssTaggingCount)
// 打印文件标签信息
for _, tag := range file.OssTagging {
fmt.Printf("Key: %s\n", tag.Key)
fmt.Printf("Value: %s\n", tag.Value)
}
// 打印用户元数据
for _, meta := range file.OssUserMeta {
fmt.Printf("Key: %s\n", meta.Key)
fmt.Printf("Value: %s\n", meta.Value)
}
}
// 打印聚合结果
for _, aggregation := range result.Aggregations {
fmt.Printf("Field: %s\n", aggregation.Field)
fmt.Printf("Operation: %s\n", aggregation.Operation)
fmt.Printf("Value: %v\n", aggregation.Value)
}
}
步骤三:结果验证
使用OSS控制台
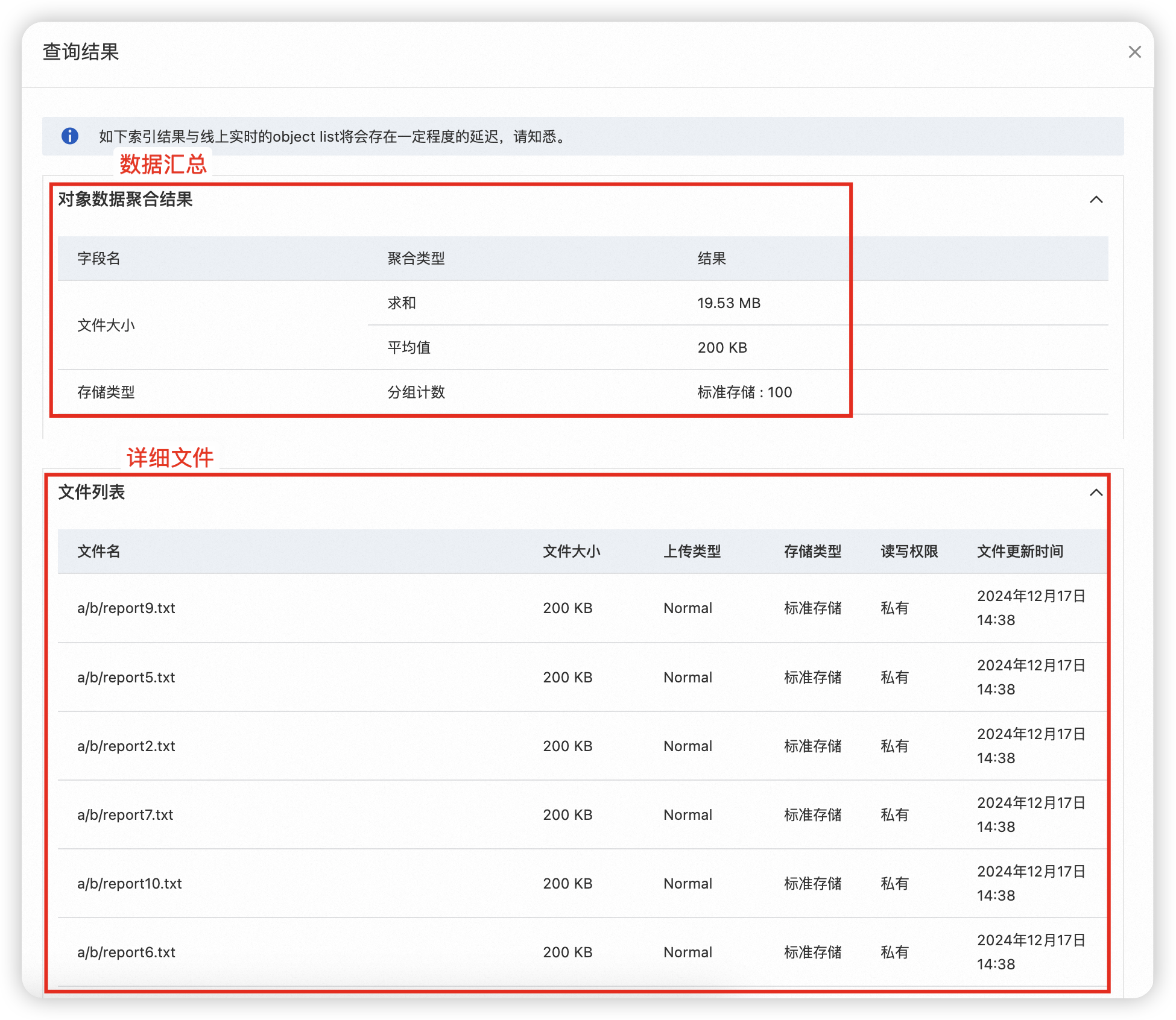
如图所示,符合条件的100个标准存储类型文件总大小为19.53MB,平均每个文件约200KB。
使用阿里云SDK
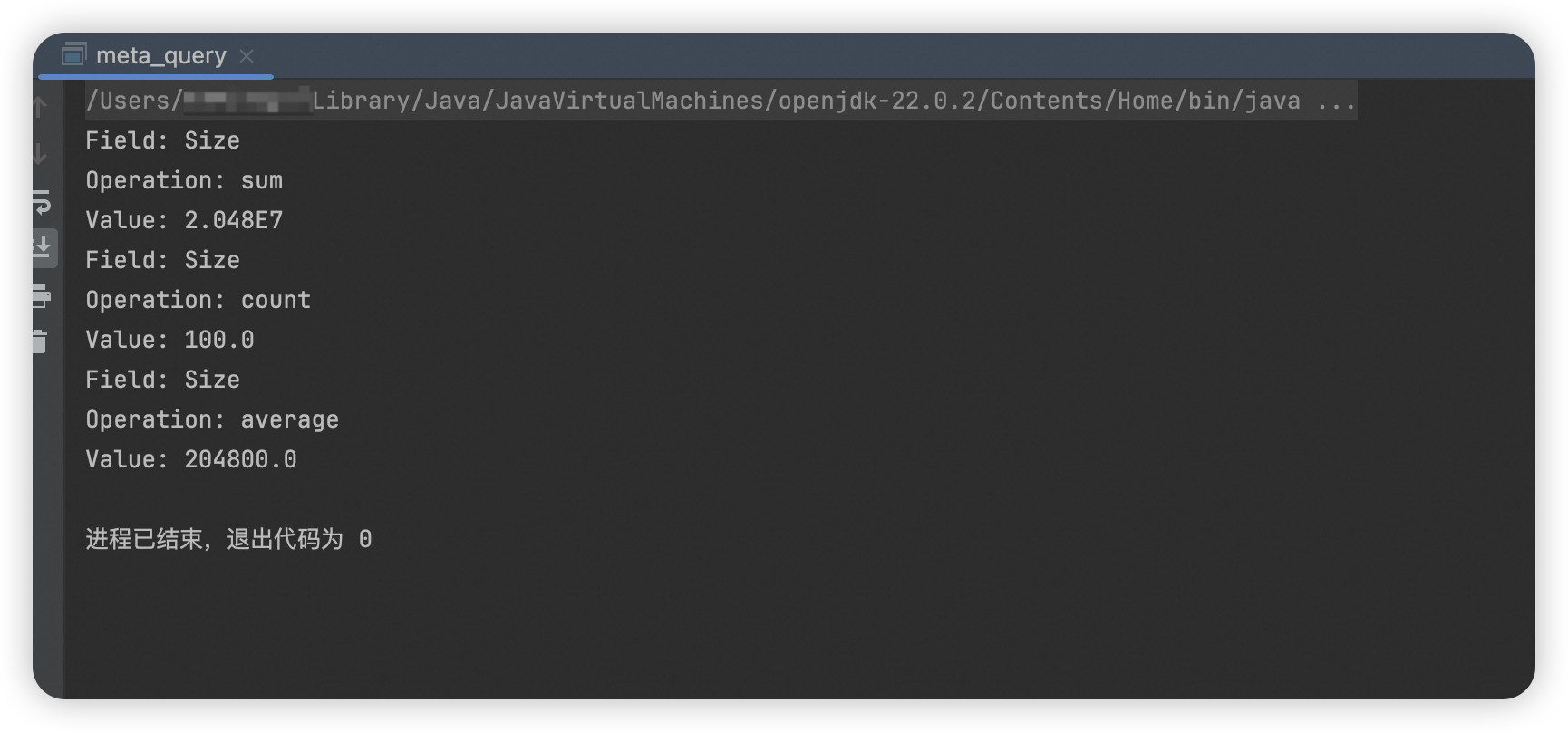
如图所示,符合条件的100个标准存储类型文件总大小为19.53MB,平均每个文件约200KB。
了解更多
如果您的程序自定义要求较高,您可以直接发起REST API请求。直接发起REST API请求需要手动编写代码计算签名。更多信息,请参见签名版本4和DoMetaQuery API。