
通过OSS向量检索,您可以基于语义内容、OSS元数据、多媒体元数据、对象ETag及标签和自定义元数据等条件,快速定位海量Object中的目标文件,优化检索效率。
使用场景
个人及企业办公场景
向量检索可以通过特定语义内容直接对办公文件进行搜索,例如直接搜索“ERP 系统使用方式”、“IT 维修流程”、“2024 年经营情况分析”等关键词,以实现文件搜索方式的便捷化,从而提升办公效率。
多媒体社交场景
在多媒体社交场景中,您可以利用检索能力,为您的用户提供特定内容和多媒体数据检索功能。例如,在某款社交应用程序中,用户上传了大量图片数据。通过语义检索,用户可以直接根据内容进行图片搜索,比如直接搜索内容为“郊外春游”、“春节团聚”、“我见过的大海”等照片,从而为应用程序增加实用性和趣味性。
网盘场景
在网盘场景中,目前大多数提供基于标量检索的文件搜索功能,例如按文件名称、创建时间或文件后缀进行搜索。网盘通常应用于个人或企业场景,用户可以利用向量检索功能,对网盘中的特定内容进行搜索,比如相关文档或相册中的相关图片。
视频监控场景
针对视频监控存储的数据,企业可以利用向量检索能力对监控数据中的部分文件进行搜索。比如输入“雪天户外监控”、“晴天中的果园”等关键词,即可对相应文件进行检索。
使用限制
地域限制
华北1(青岛)、华北2(北京)、华北3(张家口)、华东1(杭州)、华东2(上海)、华南1(深圳)、华南3(广州)、西南1(成都)、中国香港、新加坡、印度尼西亚(雅加达)、德国(法兰克福)地域的Bucket支持使用向量检索功能。
说明中国香港、新加坡、印度尼西亚(雅加达)、德国(法兰克福)地域暂不支持音频检索。
Bucket限制
开通向量检索的 Bucket,其包含的文件数量最多为50亿。Bucket内文件数量超过50亿时,可能出现检索性能下降的情况。如需处理更大规模的数据,请联系技术支持进行评估。
分片上传
对于通过分片上传生成的Object,查询结果中只显示已通过CompleteMultipartUpload操作将碎片(Part)合成的完整Object,不显示已初始化但未完成(Complete)或者未中止(Abort)的碎片。
性能参考
OSS 向量检索模式的性能表现如下,供参考。
OSS提供的内网带宽和QPS
该内网带宽和QPS(即每秒可处理1250个文件请求)为 OSS 向量检索模式额外提供,不占用您 Bucket 的 QoS。
地域
内网带宽
默认QPS
华北2(北京)、华东1(杭州)、华东2(上海)、华南1(深圳)
10Gbps
1250
其他地域
1Gbps
1250
存量文件索引生成时间参考
向量检索模式的索引构建期间会产生 List/Head/Get 等 API 接口的请求次数费用。同时,视频、音频和文档文件的索引生成时间较图片索引生成时间会更长,建议您在使用前合理评估文件数量。
若 Bucket 内文件以结构化数据和图片文件为主。
单 Buket 文件数量 1000 万:2~3 小时
单 Buket 文件数量 1 亿:1 天
单 Buket 文件数量 10 亿: 10 天左右
若 Bucket 内文件以视频,文档和音频文件为主。
单 Buket 文件数量 1000 万:2~3 天左右
单 Buket 文件数量 1 亿:7~9 天左右
增量文件索引更新时间参考
当 Bucket 内新增、修改或删除的QPS低于默认值1250时,文件从上传或修改到可被检索的延迟通常在分钟至小时级;若超过默认值1250QPS,您可以通过技术支持联系我们,我们将根据实际情况评估,并提供技术支持。
文件检索响应性能
检索结果返回为秒级,默认超时时间为 30 秒。
开启向量检索
使用OSS控制台
登录OSS管理控制台。
单击Bucket 列表,然后单击目标Bucket名称。
在左侧导航栏, 选择。
在数据索引页面,首次使用数据索引功能时,需要按指引完成对 AliyunMetaQueryDefaultRole 角色的授权,以便 OSS 服务能管理 Bucket 中的数据。授权后,单击开通数据索引。
选择向量检索,单击确认开启。
说明构建元数据索引需要等待一定的时间,具体等待时长取决于Bucket中Object的数量。若开启时间过久可通过刷新来查看开启状态。
使用阿里云SDK
Java
仅Java SDK 3.18.2及以上版本支持使用向量检索功能,更多用法见向量检索(Java SDK)。
import com.aliyun.oss.*;
import com.aliyun.oss.common.auth.*;
import com.aliyun.oss.common.comm.SignVersion;
import com.aliyun.oss.model.MetaQueryMode;
public class OpenMetaQuery {
public static void main(String[] args) throws com.aliyuncs.exceptions.ClientException {
// Endpoint以华东1(杭州)为例,其它Region请按实际情况填写。
String endpoint = "https://oss-cn-hangzhou.aliyuncs.com";
// 填写Bucket名称,例如examplebucket。
String bucketName = "examplebucket";
// 从环境变量中获取访问凭证。运行本代码示例之前,请确保已设置环境变量OSS_ACCESS_KEY_ID和OSS_ACCESS_KEY_SECRET。
EnvironmentVariableCredentialsProvider credentialsProvider = CredentialsProviderFactory.newEnvironmentVariableCredentialsProvider();
// 填写Bucket所在地域。以华东1(杭州)为例,Region填写为cn-hangzhou。
String region = "cn-hangzhou";
// 创建OSSClient实例。
//当OSSClient实例不再使用时,调用shutdown方法以释放资源。
ClientBuilderConfiguration clientBuilderConfiguration = new ClientBuilderConfiguration();
clientBuilderConfiguration.setSignatureVersion(SignVersion.V4);
OSS ossClient = OSSClientBuilder.create()
.endpoint(endpoint)
.credentialsProvider(credentialsProvider)
.clientConfiguration(clientBuilderConfiguration)
.region(region)
.build();
try {
// 开启向量检索功能。
ossClient.openMetaQuery(bucketName, MetaQueryMode.SEMANTIC);
} catch (OSSException oe) {
System.out.println("Error Message:" + oe.getErrorMessage());
System.out.println("Error Code:" + oe.getErrorCode());
System.out.println("Request ID:" + oe.getRequestId());
System.out.println("Host ID:" + oe.getHostId());
} catch (ClientException ce) {
System.out.println("Error Message: " + ce.getMessage());
} finally {
// 关闭OSSClient。
if(ossClient != null){
ossClient.shutdown();
}
}
}
}
Python
更多用法见向量检索。
import argparse
import alibabacloud_oss_v2 as oss
# 创建命令行参数解析器,并添加描述信息
parser = argparse.ArgumentParser(description="open meta query sample")
# 添加必需的命令行参数 --region,用于指定存储空间所在的区域
parser.add_argument('--region', help='The region in which the bucket is located.', required=True)
# 添加必需的命令行参数 --bucket,用于指定要操作的存储空间名称
parser.add_argument('--bucket', help='The name of the bucket.', required=True)
# 添加可选的命令行参数 --endpoint,用于指定访问OSS时使用的域名
parser.add_argument('--endpoint', help='The domain names that other services can use to access OSS')
def main():
# 解析命令行参数
args = parser.parse_args()
# 从环境变量中加载认证信息
credentials_provider = oss.credentials.EnvironmentVariableCredentialsProvider()
# 使用SDK提供的默认配置
cfg = oss.config.load_default()
# 设置认证信息提供者
cfg.credentials_provider = credentials_provider
# 根据命令行参数设置区域
cfg.region = args.region
# 如果提供了endpoint,则更新配置中的endpoint
if args.endpoint is not None:
cfg.endpoint = args.endpoint
# 创建OSS客户端
client = oss.Client(cfg)
# 构建一个OpenMetaQuery请求,,用于开启存储空间的向量检索功能
result = client.open_meta_query(oss.OpenMetaQueryRequest(
bucket=args.bucket,
mode='semantic',# 设置为"semantic",表示选择向量检索
))
# 打印请求的结果状态码和请求ID
print(f'status code: {result.status_code},'
f' request id: {result.request_id},'
)
# 当作为主程序运行时调用main函数
if __name__ == "__main__":
main()
Go
更多用法见向量检索(Go SDK V2)。
package main
import (
"context"
"flag"
"log"
"github.com/aliyun/alibabacloud-oss-go-sdk-v2/oss"
"github.com/aliyun/alibabacloud-oss-go-sdk-v2/oss/credentials"
)
var (
region string
bucketName string
)
// init函数在main函数之前执行,用来初始化程序
func init() {
// 设置命令行参数来指定region
flag.StringVar(®ion, "region", "", "The region in which the bucket is located.")
// 设置命令行参数来指定bucket名称
flag.StringVar(&bucketName, "bucket", "", "The name of the bucket.")
}
func main() {
flag.Parse() // 解析命令行参数
// 检查是否提供了存储空间名称,如果没有提供,则输出默认参数并退出程序
if len(bucketName) == 0 {
flag.PrintDefaults()
log.Fatalf("invalid parameters, bucket name required")
}
// 检查是否提供了区域信息,如果没有提供,则输出默认参数并退出程序
if len(region) == 0 {
flag.PrintDefaults()
log.Fatalf("invalid parameters, region required")
}
// 创建客户端配置,并使用环境变量作为凭证提供者
cfg := oss.LoadDefaultConfig().
WithCredentialsProvider(credentials.NewEnvironmentVariableCredentialsProvider()).
WithRegion(region)
client := oss.NewClient(cfg) // 使用配置创建一个新的OSS客户端实例
// 构建一个OpenMetaQuery请求,用于开启特定存储空间的向量检索功能
request := &oss.OpenMetaQueryRequest{
Bucket: oss.Ptr(bucketName),
Mode: oss.Ptr("semantic"), // 设置为"semantic",表示开启向量检索功能
}
result, err := client.OpenMetaQuery(context.TODO(), request)
if err != nil {
log.Fatalf("failed to open meta query %v", err)
}
log.Printf("open meta query result:%#v\n", result) // 打印开启向量检索的结果
}
PHP
更多用法见向量检索(PHP SDK V2)。
<?php
// 引入自动加载文件,确保依赖库能够正确加载
require_once __DIR__ . '/../vendor/autoload.php';
use AlibabaCloud\Oss\V2 as Oss;
// 定义命令行参数的描述信息
$optsdesc = [
"region" => ['help' => 'The region in which the bucket is located.', 'required' => True], // Bucket所在的地域(必填)
"endpoint" => ['help' => 'The domain names that other services can use to access OSS.', 'required' => False], // 访问域名(可选)
"bucket" => ['help' => 'The name of the bucket', 'required' => True], // Bucket名称(必填)
];
// 将参数描述转换为getopt所需的长选项格式
// 每个参数后面加上":"表示该参数需要值
$longopts = \array_map(function ($key) {
return "$key:";
}, array_keys($optsdesc));
// 解析命令行参数
$options = getopt("", $longopts);
// 验证必填参数是否存在
foreach ($optsdesc as $key => $value) {
if ($value['required'] === True && empty($options[$key])) {
$help = $value['help']; // 获取参数的帮助信息
echo "Error: the following arguments are required: --$key, $help" . PHP_EOL;
exit(1); // 如果必填参数缺失,则退出程序
}
}
// 从解析的参数中提取值
$region = $options["region"]; // Bucket所在的地域
$bucket = $options["bucket"]; // Bucket名称
// 加载环境变量中的凭证信息
// 使用EnvironmentVariableCredentialsProvider从环境变量中读取Access Key ID和Access Key Secret
$credentialsProvider = new Oss\Credentials\EnvironmentVariableCredentialsProvider();
// 使用SDK的默认配置
$cfg = Oss\Config::loadDefault();
$cfg->setCredentialsProvider($credentialsProvider); // 设置凭证提供者
$cfg->setRegion($region); // 设置Bucket所在的地域
if (isset($options["endpoint"])) {
$cfg->setEndpoint($options["endpoint"]); // 如果提供了访问域名,则设置endpoint
}
// 创建OSS客户端实例
$client = new Oss\Client($cfg);
// 开启向量检索功能
$request = new Oss\Models\OpenMetaQueryRequest($bucket,'semantic');
$result = $client->openMetaQuery($request);
printf(
'status code:' . $result->statusCode . PHP_EOL .
'request id:' . $result->requestId
);使用ossutil
以下示例展示了如何开启存储空间examplebucket的向量检索功能。命令示例如下:
ossutil api open-meta-query --bucket examplebucket --meta-query-mode semantic关于使用ossutil进行向量检索的具体操作, 请参见open-meta-query。
发起向量检索
使用OSS控制台
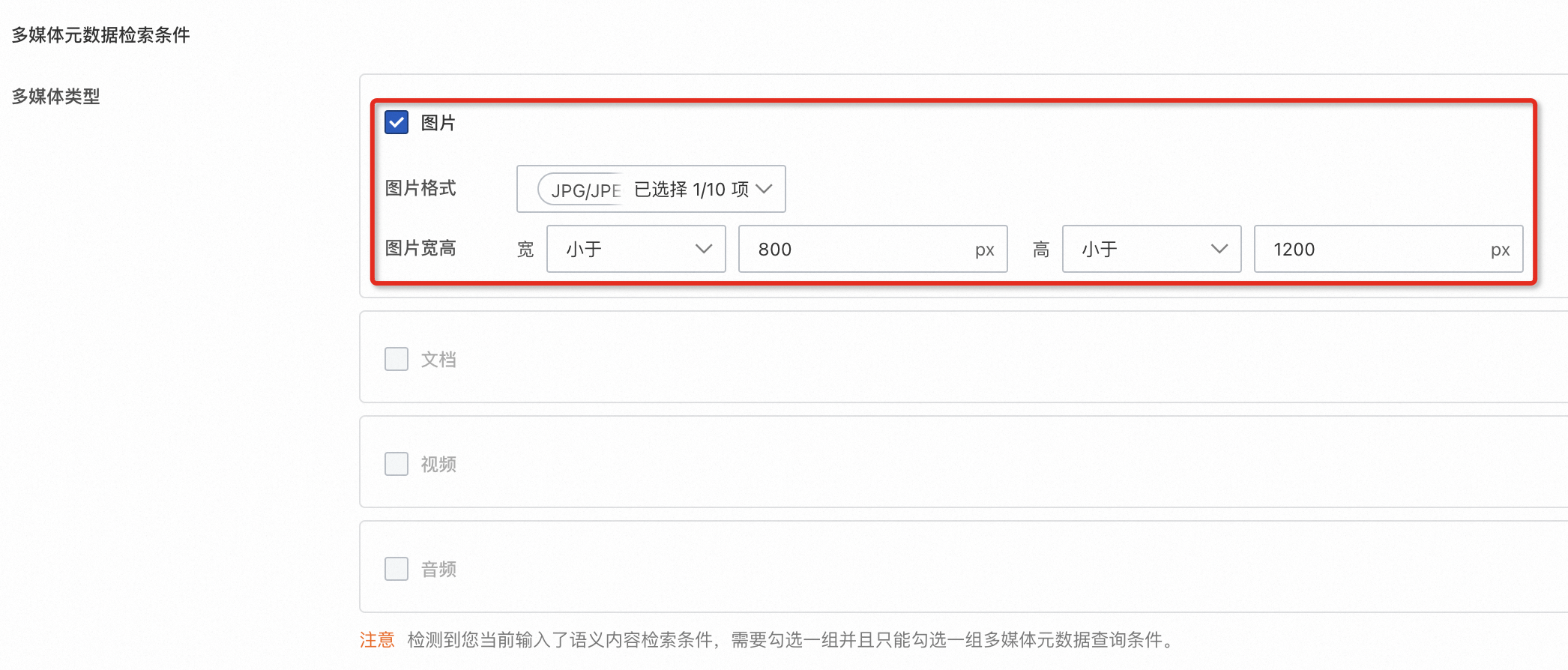
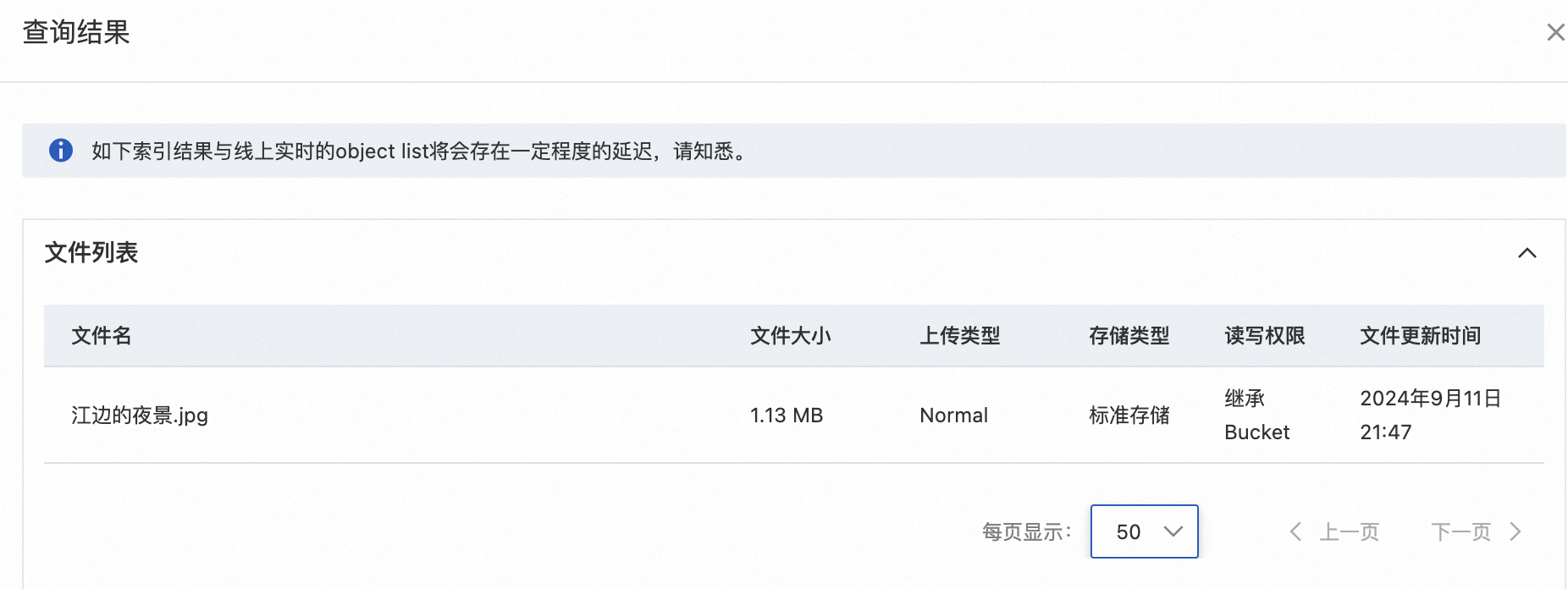
以查询内容为“发光的建筑”、格式为JPG、图片宽高在800*1200内的文件为例进行演示,期望检索结果为下图“江边的夜景.jpg”。


使用阿里云SDK
Java
仅Java SDK 3.18.2及以上版本支持使用向量检索功能,更多用法见向量检索(Java SDK)。
import com.aliyun.oss.*;
import com.aliyun.oss.common.auth.CredentialsProviderFactory;
import com.aliyun.oss.common.auth.EnvironmentVariableCredentialsProvider;
import com.aliyun.oss.common.comm.SignVersion;
import com.aliyun.oss.model.*;
import java.util.ArrayList;
import java.util.List;
public class DoMetaQuery {
public static void main(String[] args) throws Exception {
// Endpoint以华东1(杭州)为例,其它Region请按实际情况填写。
String endpoint = "https://oss-cn-hangzhou.aliyuncs.com";
// 填写Bucket名称,例如examplebucket。
String bucketName = "examplebucket";
// 从环境变量中获取访问凭证。运行本代码示例之前,请确保已设置环境变量OSS_ACCESS_KEY_ID和OSS_ACCESS_KEY_SECRET。
EnvironmentVariableCredentialsProvider credentialsProvider = CredentialsProviderFactory.newEnvironmentVariableCredentialsProvider();
// 填写Bucket所在地域。以华东1(杭州)为例,Region填写为cn-hangzhou。
String region = "cn-hangzhou";
// 创建OSSClient实例。
// 当OSSClient实例不再使用时,调用shutdown方法以释放资源。
ClientBuilderConfiguration clientBuilderConfiguration = new ClientBuilderConfiguration();
clientBuilderConfiguration.setSignatureVersion(SignVersion.V4);
OSS ossClient = OSSClientBuilder.create()
.endpoint(endpoint)
.credentialsProvider(credentialsProvider)
.clientConfiguration(clientBuilderConfiguration)
.region(region)
.build();
try {
int maxResults = 20;
List<String> mediaTypes = new ArrayList<String>();
mediaTypes.add("image");
String query = "Snow";
String simpleQuery = "{\"Operation\":\"gt\", \"Field\": \"Size\", \"Value\": \"30\"}";
String sort = "Size";
DoMetaQueryRequest doMetaQueryRequest = new DoMetaQueryRequest(bucketName, maxResults, query, sort, MetaQueryMode.SEMANTIC, mediaTypes, simpleQuery);
DoMetaQueryResult doMetaQueryResult = ossClient.doMetaQuery(doMetaQueryRequest);
} catch (OSSException oe) {
System.out.println("Error Message: " + oe.getErrorMessage());
System.out.println("Error Code: " + oe.getErrorCode());
System.out.println("Request ID: " + oe.getRequestId());
System.out.println("Host ID: " + oe.getHostId());
} catch (ClientException ce) {
System.out.println("Error Message: " + ce.getMessage());
} finally {
if(ossClient != null){
ossClient.shutdown();
}
}
}
}
Python
更多用法见向量检索。
import argparse
import alibabacloud_oss_v2 as oss
# 创建命令行参数解析器,用于处理命令行输入
parser = argparse.ArgumentParser(description="do meta query semantic sample")
# 添加必要的命令行参数
parser.add_argument('--region', help='The region in which the bucket is located.', required=True) # 存储空间所在地域
parser.add_argument('--bucket', help='The name of the bucket.', required=True) # 存储空间名称
parser.add_argument('--endpoint', help='The domain names that other services can use to access OSS') # OSS访问域名,可选
def main():
# 解析命令行参数
args = parser.parse_args()
# 从环境变量中加载访问凭证
# 运行前需要设置环境变量:OSS_ACCESS_KEY_ID 和 OSS_ACCESS_KEY_SECRET
credentials_provider = oss.credentials.EnvironmentVariableCredentialsProvider()
# 加载SDK默认配置
cfg = oss.config.load_default()
# 设置凭证提供者
cfg.credentials_provider = credentials_provider
# 设置区域
cfg.region = args.region
# 如果提供了endpoint,则更新配置中的endpoint
if args.endpoint is not None:
cfg.endpoint = args.endpoint
# 创建OSS客户端实例
client = oss.Client(cfg)
# 发起元数据查询请求 - 向量检索模式
result = client.do_meta_query(oss.DoMetaQueryRequest(
bucket=args.bucket,
mode='semantic',
meta_query=oss.MetaQuery(
max_results=1000,
query='俯瞰白雪覆盖的森林',
order='desc',
media_types=oss.MetaQueryMediaTypes(
media_type=['image']
),
simple_query='{"Operation":"gt", "Field": "Size", "Value": "30"}',
),
))
# 打印检索结果
print(vars(result))
if __name__ == "__main__":
main()
Go
更多用法见向量检索(Go SDK V2)。
package main
import (
"context"
"flag"
"log"
"github.com/aliyun/alibabacloud-oss-go-sdk-v2/oss"
"github.com/aliyun/alibabacloud-oss-go-sdk-v2/oss/credentials"
)
var (
region string
bucketName string
)
func init() {
// 设置命令行参数来指定region,默认为空字符串
flag.StringVar(®ion, "region", "", "The region in which the bucket is located.")
// 设置命令行参数来指定bucket名称,默认为空字符串
flag.StringVar(&bucketName, "bucket", "", "The name of the bucket.")
}
func main() {
flag.Parse() // 解析命令行参数
// 检查是否提供了存储空间名称,如果没有提供,则输出默认参数并退出程序
if len(bucketName) == 0 {
flag.PrintDefaults()
log.Fatalf("invalid parameters, bucket name required")
}
// 检查是否提供了区域信息,如果没有提供,则输出默认参数并退出程序
if len(region) == 0 {
flag.PrintDefaults()
log.Fatalf("invalid parameters, region required")
}
// 创建客户端配置,并使用环境变量作为凭证提供者和指定的区域
cfg := oss.LoadDefaultConfig().
WithCredentialsProvider(credentials.NewEnvironmentVariableCredentialsProvider()).
WithRegion(region)
client := oss.NewClient(cfg) // 使用配置创建一个新的OSS客户端实例
// 执行向量检索操作
request := &oss.DoMetaQueryRequest{
Bucket: oss.Ptr(bucketName),
Mode: oss.Ptr("semantic"),
MetaQuery: &oss.MetaQuery{
MaxResults: oss.Ptr(int64(99)),
Query: oss.Ptr("Overlook the snow-covered forest"), // 输入语义内容检索,此处为示例文本
MediaType: oss.Ptr("image"), // 指定检索的媒体类型,此处为图像类型
SimpleQuery: oss.Ptr(`{"Operation":"gt", "Field": "Size", "Value": "30"}`),
},
}
result, err := client.DoMetaQuery(context.TODO(), request)
if err != nil {
log.Fatalf("failed to do meta query %v", err)
}
log.Printf("do meta query result:%#v\n", result)
}
PHP
更多用法见向量检索(PHP SDK V2)。
<?php
// 引入自动加载文件,确保依赖库能够正确加载
require_once __DIR__ . '/../vendor/autoload.php';
use AlibabaCloud\Oss\V2 as Oss;
// 定义命令行参数的描述信息
$optsdesc = [
"region" => ['help' => 'The region in which the bucket is located.', 'required' => True], // Bucket所在的地域(必填)
"endpoint" => ['help' => 'The domain names that other services can use to access OSS.', 'required' => False], // 访问域名(可选)
"bucket" => ['help' => 'The name of the bucket', 'required' => True], // Bucket名称(必填)
];
// 将参数描述转换为getopt所需的长选项格式
// 每个参数后面加上":"表示该参数需要值
$longopts = \array_map(function ($key) {
return "$key:";
}, array_keys($optsdesc));
// 解析命令行参数
$options = getopt("", $longopts);
// 验证必填参数是否存在
foreach ($optsdesc as $key => $value) {
if ($value['required'] === True && empty($options[$key])) {
$help = $value['help']; // 获取参数的帮助信息
echo "Error: the following arguments are required: --$key, $help" . PHP_EOL;
exit(1); // 如果必填参数缺失,则退出程序
}
}
// 从解析的参数中提取值
$region = $options["region"]; // Bucket所在的地域
$bucket = $options["bucket"]; // Bucket名称
// 加载环境变量中的凭证信息
// 使用EnvironmentVariableCredentialsProvider从环境变量中读取Access Key ID和Access Key Secret
$credentialsProvider = new Oss\Credentials\EnvironmentVariableCredentialsProvider();
// 使用SDK的默认配置
$cfg = Oss\Config::loadDefault();
$cfg->setCredentialsProvider($credentialsProvider); // 设置凭证提供者
$cfg->setRegion($region); // 设置Bucket所在的地域
if (isset($options["endpoint"])) {
$cfg->setEndpoint($options["endpoint"]); // 如果提供了访问域名,则设置endpoint
}
// 创建OSS客户端实例
$client = new Oss\Client($cfg);
// 执行向量检索查询满足指定条件的对象
$request = new Oss\Models\DoMetaQueryRequest($bucket, new Oss\Models\MetaQuery(
maxResults: 99,
query: "Overlook the snow-covered forest",
mediaTypes: new Oss\Models\MetaQueryMediaTypes('image'),
simpleQuery: '{"Operation":"gt", "Field": "Size", "Value": "30"}',
), 'semantic');
$result = $client->doMetaQuery($request);
printf(
'status code:' . $result->statusCode . PHP_EOL .
'request id:' . $result->requestId . PHP_EOL .
'result:' . var_export($result, true)
);使用ossutil
以下示例展示了如何查询存储空间examplebucket中满足指定条件的文件。
ossutil api do-meta-query --bucket examplebucket --meta-query "{\"Query\":\"Overlooking the snow covered forest\",\"MediaTypes\":{\"MediaType\":\"image\"},\"SimpleQuery\":\"{\\\"Operation\\\":\\\"gt\\\", \\\"Field\\\": \\\"Size\\\", \\\"Value\\\": \\\"1\\\"}\"}" --meta-query-mode semantic关于该命令的更多信息,请参见do-meta-query。
关闭向量检索
关闭该功能不会影响您 OSS 中已存储的数据。若后续重新开启,系统将重新扫描存量文件并构建索引,需要一定等待时间,具体时间取决于您的文件数量。
功能关闭后的下一小时会停止计费,但出账会有一定延迟,请及时关注账单金额。
使用OSS控制台
登录OSS控制台,在数据索引功能页,单击元数据管理右侧关闭,按提示确认关闭即可。

使用阿里云SDK
Java
仅Java SDK 3.18.2及以上版本支持使用向量检索功能,更多用法见向量检索(Java SDK)。
import com.aliyun.oss.*;
import com.aliyun.oss.common.auth.*;
import com.aliyun.oss.common.comm.SignVersion;
public class CloseMetaQuery {
public static void main(String[] args) throws Exception {
// Endpoint以华东1(杭州)为例,其它Region请按实际情况填写。
String endpoint = "https://oss-cn-hangzhou.aliyuncs.com";
// 填写Bucket名称,例如examplebucket。
String bucketName = "examplebucket";
// 从环境变量中获取访问凭证。运行本代码示例之前,请确保已设置环境变量OSS_ACCESS_KEY_ID和OSS_ACCESS_KEY_SECRET。
EnvironmentVariableCredentialsProvider credentialsProvider = CredentialsProviderFactory.newEnvironmentVariableCredentialsProvider();
// 填写Bucket所在地域。以华东1(杭州)为例,Region填写为cn-hangzhou。
String region = "cn-hangzhou";
// 创建OSSClient实例。
// 当OSSClient实例不再使用时,调用shutdown方法以释放资源。
ClientBuilderConfiguration clientBuilderConfiguration = new ClientBuilderConfiguration();
clientBuilderConfiguration.setSignatureVersion(SignVersion.V4);
OSS ossClient = OSSClientBuilder.create()
.endpoint(endpoint)
.credentialsProvider(credentialsProvider)
.clientConfiguration(clientBuilderConfiguration)
.region(region)
.build();
try {
// 关闭存储空间(Bucket)的向量检索功能。
ossClient.closeMetaQuery(bucketName);
} catch (OSSException oe) {
System.out.println("Error Message:" + oe.getErrorMessage());
System.out.println("Error Code:" + oe.getErrorCode());
System.out.println("Request ID:" + oe.getRequestId());
System.out.println("Host ID:" + oe.getHostId());
} catch (ClientException ce) {
System.out.println("Error Message: " + ce.getMessage());
} finally {
// 关闭OSSClient。
if(ossClient != null){
ossClient.shutdown();
}
}
}
}
Python
更多用法见向量检索。
import argparse
import alibabacloud_oss_v2 as oss
# 创建一个命令行参数解析器,用于处理命令行参数
parser = argparse.ArgumentParser(description="close meta query sample")
parser.add_argument('--region', help='The region in which the bucket is located.', required=True)
parser.add_argument('--bucket', help='The name of the bucket.', required=True)
parser.add_argument('--endpoint', help='The domain names that other services can use to access OSS')
def main():
# 解析命令行参数
args = parser.parse_args()
# 从环境变量中加载凭据信息
credentials_provider = oss.credentials.EnvironmentVariableCredentialsProvider()
# 使用SDK的默认配置
cfg = oss.config.load_default()
# 设置凭据提供者为从环境变量获取的凭据
cfg.credentials_provider = credentials_provider
# 设置配置中的区域信息
cfg.region = args.region
# 如果提供了endpoint,则设置配置中的endpoint
if args.endpoint is not None:
cfg.endpoint = args.endpoint
# 创建OSS客户端
client = oss.Client(cfg)
# 调用close_meta_query方法关闭存储空间的检索功能
result = client.close_meta_query(oss.CloseMetaQueryRequest(
bucket=args.bucket,
))
# 打印响应的状态码和请求ID
print(f'status code: {result.status_code}, request id: {result.request_id}')
# 当此脚本直接运行时执行main函数
if __name__ == "__main__":
main()
Go
更多用法见向量检索(Go SDK V2)。
package main
import (
"context"
"flag"
"log"
"github.com/aliyun/alibabacloud-oss-go-sdk-v2/oss"
"github.com/aliyun/alibabacloud-oss-go-sdk-v2/oss/credentials"
)
var (
region string
bucketName string
)
func init() {
// 设置命令行参数来指定region
flag.StringVar(®ion, "region", "", "The region in which the bucket is located.")
// 设置命令行参数来指定bucket名称
flag.StringVar(&bucketName, "bucket", "", "The name of the bucket.")
}
func main() {
flag.Parse() // 解析命令行参数
// 检查是否提供了存储空间名称,如果没有提供,则输出默认参数并退出程序
if len(bucketName) == 0 {
flag.PrintDefaults()
log.Fatalf("invalid parameters, bucket name required") // 记录错误并终止程序
}
// 检查是否提供了区域信息,如果没有提供,则输出默认参数并退出程序
if len(region) == 0 {
flag.PrintDefaults()
log.Fatalf("invalid parameters, region required")
}
// 创建客户端配置,并使用环境变量作为凭证提供者和指定的区域
cfg := oss.LoadDefaultConfig().
WithCredentialsProvider(credentials.NewEnvironmentVariableCredentialsProvider()).
WithRegion(region)
client := oss.NewClient(cfg) // 创建一个新的OSS客户端实例
// 构建一个CloseMetaQuery请求,用于关闭特定存储空间的元数据管理功能
request := &oss.CloseMetaQueryRequest{
Bucket: oss.Ptr(bucketName), // 指定要操作的存储空间名称
}
result, err := client.CloseMetaQuery(context.TODO(), request) // 执行请求以关闭存储空间的元数据管理功能
if err != nil {
log.Fatalf("failed to close meta query %v", err)
}
log.Printf("close meta query result:%#v\n", result)
}PHP
更多用法见向量检索(PHP SDK V2)。
<?php
// 引入自动加载文件,确保依赖库能够正确加载
require_once __DIR__ . '/../vendor/autoload.php';
use AlibabaCloud\Oss\V2 as Oss;
// 定义命令行参数的描述信息
$optsdesc = [
"region" => ['help' => 'The region in which the bucket is located.', 'required' => True], // Bucket所在的地域(必填)
"endpoint" => ['help' => 'The domain names that other services can use to access OSS.', 'required' => False], // 访问域名(可选)
"bucket" => ['help' => 'The name of the bucket', 'required' => True], // Bucket名称(必填)
];
// 将参数描述转换为getopt所需的长选项格式
// 每个参数后面加上":"表示该参数需要值
$longopts = \array_map(function ($key) {
return "$key:";
}, array_keys($optsdesc));
// 解析命令行参数
$options = getopt("", $longopts);
// 验证必填参数是否存在
foreach ($optsdesc as $key => $value) {
if ($value['required'] === True && empty($options[$key])) {
$help = $value['help']; // 获取参数的帮助信息
echo "Error: the following arguments are required: --$key, $help" . PHP_EOL;
exit(1); // 如果必填参数缺失,则退出程序
}
}
// 从解析的参数中提取值
$region = $options["region"]; // Bucket所在的地域
$bucket = $options["bucket"]; // Bucket名称
// 加载环境变量中的凭证信息
// 使用EnvironmentVariableCredentialsProvider从环境变量中读取Access Key ID和Access Key Secret
$credentialsProvider = new Oss\Credentials\EnvironmentVariableCredentialsProvider();
// 使用SDK的默认配置
$cfg = Oss\Config::loadDefault();
$cfg->setCredentialsProvider($credentialsProvider); // 设置凭证提供者
$cfg->setRegion($region); // 设置Bucket所在的地域
if (isset($options["endpoint"])) {
$cfg->setEndpoint($options["endpoint"]); // 如果提供了访问域名,则设置endpoint
}
// 创建OSS客户端实例
$client = new Oss\Client($cfg);
// 创建CloseMetaQueryRequest对象,用于关闭Bucket的检索功能
$request = new \AlibabaCloud\Oss\V2\Models\CloseMetaQueryRequest(
bucket: $bucket
);
// 执行关闭检索功能的操作
$result = $client->closeMetaQuery($request);
// 打印关闭检索功能的结果
printf(
'status code:' . $result->statusCode . PHP_EOL . // HTTP状态码,例如200表示成功
'request id:' . $result->requestId . PHP_EOL // 请求ID,用于调试或追踪请求
);
使用ossutil
以下示例展示了如何关闭存储空间examplebucket的元数据管理功能。命令示例如下:
ossutil api close-meta-query --bucket examplebucket关于该命令的更多信息,请参见close-meta-query。
检索条件和输出设置
检索条件设置
以下是完整的检索条件,您可以根据需要设置单个或多个检索条件。
结果输出设置
设置“语义内容检索条件”后,不支持指定排序方式以及数据聚合。
您可对输出结果进行排序和简单统计。
对象排序方式:支持根据最后修改时间、文件名和文件大小进行升序、降序及默认排序。您可以按需选择并排序检索结果,便于快速找到所需文件。
数据聚合:支持多种输出类型,您可以对检索结果进行去重统计、分组计数、最大值、最小值、平均值和求和等计算,便于高效分析和管理数据。
相关API
以上操作方式底层基于API实现,如果您的程序自定义要求较高,您可以直接发起REST API请求。直接发起REST API请求需要手动编写代码计算签名。
关于开启元数据管理功能的更多信息,请参见OpenMetaQuery。
关于查询满足指定条件的文件,请参见DoMetaQuery。
关于关闭元数据管理功能的更多信息,请参见CloseMetaQuery。
计费说明
向量检索费用主要来自以下两个方面:
向量检索功能计费项(公测期间免费)
包括Object的元数据管理费用。当前处于公测阶段暂不计费,将于 2025 年 8 月 25 日公测结束后正式计费。公测结束后将按OSS数据索引定价标准计费,详见数据索引费用。
API请求费用
在存量文件索引构建期间和增量文件索引更新期间会产生API请求费用,按照API调用次数收费。涉及的API请求如下:
行为
API
为Bucket中的文件构建索引
HeadObject和GetObject
Bucket中文件存在Tag
GetObjectTag
Bucket中文件携带自定义Meta
GetObjectMeta
Bucket中存在软链接文件
GetSymlink
扫描Bucket中的文件
ListObjects
关于OSS API的请求费用,请参见请求费用。
如您希望停止相关计费,请及时关闭向量检索。
常见问题
为什么文件上传后,无法立即检索到?
文件上传后,对应文件的索引生成需要一定时间,所以查询结果会有一定程度的延迟,可能无法立即得到查询结果,等待片刻后重试即可。