EdgeAcc-SGLang是针对边缘节点服务ENS定制优化的大语言模型(LLM)推理加速引擎,结合ENS节点的基础设施特性以发挥最佳性能。帮助业务提升并发量,同时处理更多的终端请求,并优化首Token延迟和结果总生成时间。
工具优势
EdgeAcc-SGLang基于SGLang进行优化,因此天然支持SGLang的基础特性,并兼容其运行方式和访问接口。同时支持以下主要特性:
Intra-GPU PD分离技术(Semi-PD)。
针对单机多卡机型,将Prefill、Decoder实例在GPU内部按照流式多处理器(Streaming Multiprocessor)粒度拆分,减少P与D实例的跨卡通信,从而优化吞吐/TTFT/端到端延迟。
KV Cache卸载到内存,在多轮对话场景下收益显著。
支持将内存作为KV Cache的存储,更好支持长上下文、多轮对话等有状态服务场景。请结合机型配置合理分配内存,更多详情方案可联系您的客户经理。
动态RunningQueue,限制运行中的任务数量,解决高并发下的内存不足(Out Of Memory)问题。
适配主流模型,如Qwen3-32B。
适配GPUDirect P2P驱动,叠加优化效果。
EdgeAcc-SGLang相比原生SGLang在相对较小尺寸(70B以下)的LLM、单机多卡推理的场景上具备显著的性能优势。以Qwen3-32B测试为例,EdgeAcc-SGLang相对SGLang原始版本在各指标上的优化幅度:
吞吐率:提升 88.71% ~ 126.59%
TTFT:降低 36.34% ~ 52.37%
端到端延迟:降低 48.42% ~ 57.15%
TPOT:降低 49.92% ~ 56.99%
KV Cache命中率:由75%提升至94%
测试环境与结果请参考性能数据详情。
计费说明
EdgeAcc工具包不需要额外支付费用,您只需为执行计算任务过程中使用到的阿里云ENS资源付费。
基础环境依赖
硬件依赖:ENS所有在售智算规格。
软件依赖
操作系统:
Ubuntu 22.04CUDA版本:
12.7Pytorch版本:
2.6.0
如您有使用其他操作系统、CUDA版本等的需求,请联系客户经理支持。
开始使用
因硬件设备显存始终有限,过大的并发数会引发各性能指标劣化,并最终导致推理引擎崩溃。服务线上业务请您确保配置前置网关以进行必要的限流。合适的限流配置可参考性能数据详情,并结合上量前测试进行选定。
您可以参考下述步骤下载模型并通过Docker镜像启动EdgeAcc-SGLang。
根据需要选择模型下载方式:
使用modelscope工具从魔搭社区下载
使用pip安装modelscope工具。
pip install modelscope使用工具下载模型到指定路径。
modelscope download --model Qwen/Qwen3-32B --local_dir your_model_dir # 将your_model_dir替换为实际模型存储路径
使用多线程下载器从任意URL下载
常规的工具如浏览器,默认采用单线程下载,然而由于网络运营商线路质量等因素有时下载会很慢,且下载中断难以处理。推荐参考Aria2的脚本hfd,进行多线程加速以提高下载速度。
设置镜像端点,若从huggingface下载,则国内推荐源站hf-mirror。
export HF_ENDPOINT="https://hf-mirror.com"下载
hfd.sh到机器,设置执行权限和alias。chmod a+x hfd.sh alias hfd="$PWD/hfd.sh"使用多线程下载模型到本地目录。
hfd Qwen/Qwen3-32B -x 8 --local-dir your_model_dir # 将your_model_dir替换为实际模型存储路径
通过Docker启动镜像。
docker login -u edgeacc -p edgeacc alien-registry.alibaba-inc.com/edgeacc docker run -d --pull always --gpus all --privileged --network host --ipc host \ -v /data:/data \ -e MODEL_PATH=your_model_dir # 将your_model_dir替换为实际模型存储路径 -e SERVED_MODEL_NAME=Qwen3-0.6B \ -e SERVER_HOST=127.0.0.1 \ -e SERVER_PORT=30000 \ -e TENSOR_PARALLEL_SIZE=8 \ -e ENABLE_EDGE_ACC=True \ # 代表按照EdgeAcc推荐最优效果的配置项运行服务,自动开启Intra-GPU PD和其余优化项,用于提升长文本、高并发下的性能。 alien-registry.alibaba-inc.com/edgeacc/sglang:v0.4.4.post1-edge-acc-d7a58713 --enable-hierarchical-cache --kv-cache-offload-memory-gb=50 # 代表开启KV Cache多级缓存,并设定为每个TP分配50GB内存。建议配置:TP数 x 内存总量 <= 80% * 主机容量,且KV Cache卸载到内存的配置需 >= 显存分配的Cache值SGLang服务启动后,即可通过API调用,请参考https://docs.sglang.ai/。示例可参考:
curl -X POST http://localhost:30000/generate -H "Content-Type: application/json" -d '{"text": "Write a 1940s country song about the hardships of being a programmer", "sampling_params": {"temperature": 0.0, "max_new_tokens": 245, "ignore_eos": true}, "stream": false, "lora_path": null, "return_logprob": false, "logprob_start_len": -1}'
性能数据详情
测试环境
系统:
Ubuntu 22.04Driver Version:
565.57.01CUDA Version:
12.7
非多轮会话场景
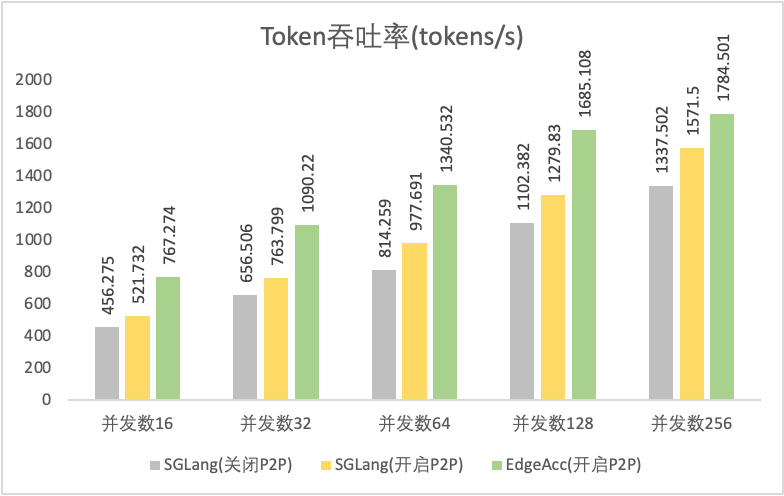
测试条件
模型:Qwen3-32B/TP=8
数据集:ShareGPT_V3_unfiltered_cleaned_split
并发数:16、32、64、128、256
对比项:
SGLang(开源版本v0.4.6)、不开启P2P
SGLang(开源版本v0.4.6)、开启P2P
SGLang(EdgeAcc版本)、开启P2P
测试结果
Token吞吐率
|
|
首Token延迟 TTFT
|
|

端到端延迟
|
|
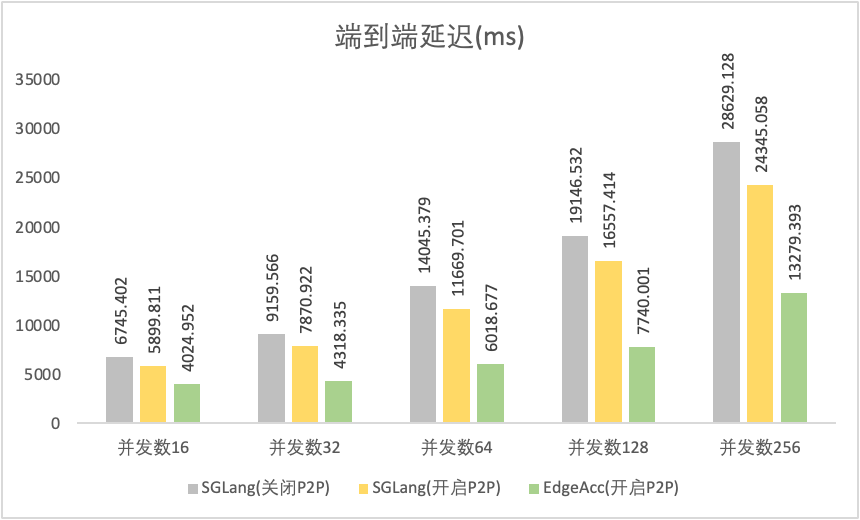
|
|
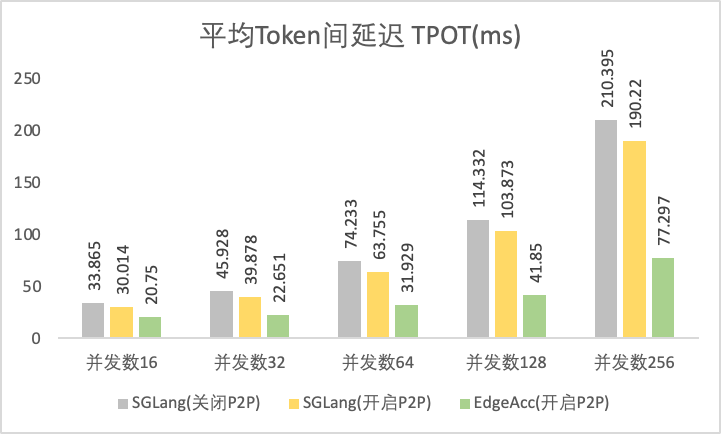
多轮会话场景
测试条件
模型:Qwen3-32B/TP=8
数据集:AutoGenerated 数据集,使用AI chatbot动态输出拟真对话内容
并发数:固定32并发,20轮对话
Token输入输出:多轮平均输入3150 Tokens;固定500输出Tokens
对比项:
SGLang(开源版本v0.4.6)、不开启P2P
SGLang(开源版本v0.4.6)、开启P2P
SGLang(EdgeAcc版本)、开启P2P
测试结果
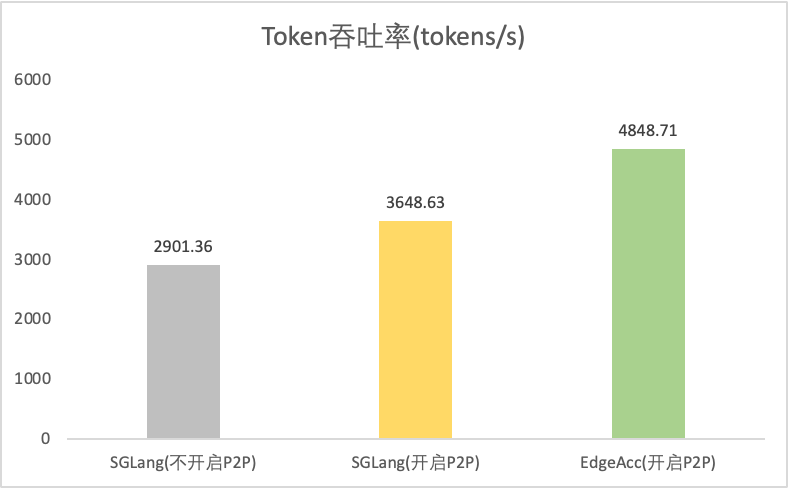
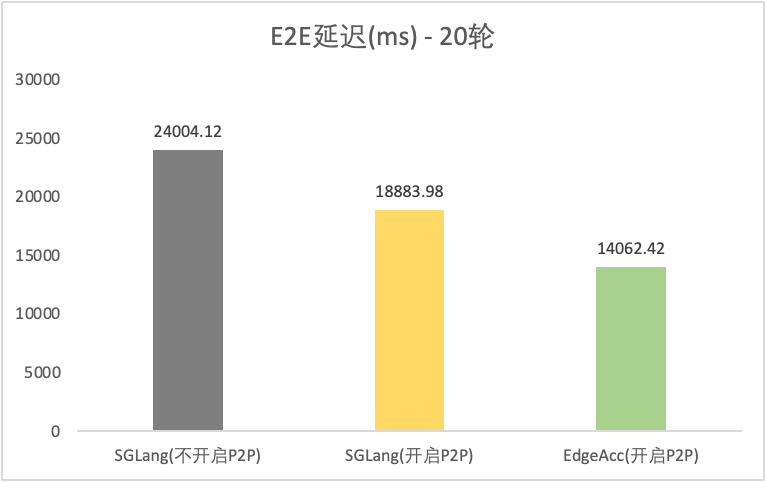
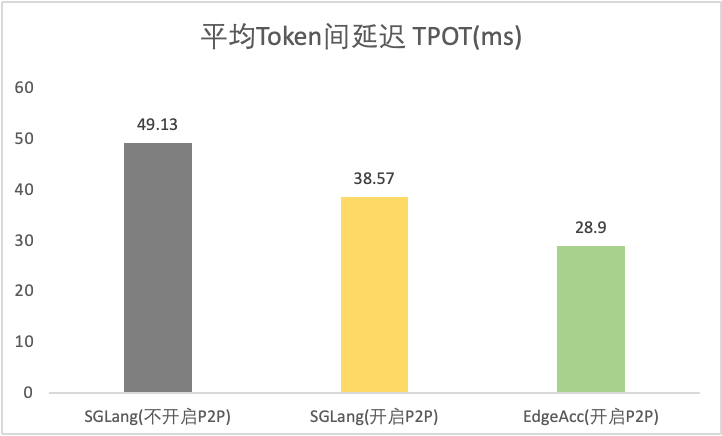
工具类型 | 是否开启P2P | Token吞吐率(tokens/s) | 平均首Token延迟 TTFT(ms) | 20轮 E2E延迟(ms) | 平均Token间延迟 TPOT(ms) |
SGLang | 2901.36 | 304.63 | 24004.12 | 49.13 | |
SGLang | 3648.63 | 290.68 | 18883.98 | 38.57 | |
EdgeAcc-SGLang | 4848.71 | 250.91 | 14062.42 | 28.9 | |
测试结果图 |
|
|
|
| |