
接入 ARMS 应用监控以后,探针对常见的 AI 框架进行了自动埋点,因此不需要修改任何代码,就可以实现调用链信息的采集。如果您需要在调用链信息中,体现业务方法的执行情况,可以引入 loongsuite-util-genai 以及 OpenTelemetry SDK,在业务代码中增加自定义埋点。本文介绍如何通过 loongsuite-util-genai 以及 OpenTelemetry Python SDK 实现自定义埋点以及自定义 Attribute。
ARMS 探针支持的 AI 组件和框架,请参见:
前提条件
已经成功接入 ARMS 应用监控。
引入依赖
pip install loongsuite-util-genai安装后提供 opentelemetry.util.genai 包及 ExtendedTelemetryHandler 等扩展接口。更多信息,请参见 loongsuite-util-genai 详细文档。
使用 loongsuite-util-genai 和 OpenTelemetry SDK
通过 loongsuite-util-genai 和 OpenTelemetry SDK 主要可以实现以下操作:
创建 GenAI 语义的 Span(Entry、Agent、Tool、ReAct Step等)。
通过 OpenTelemetry SDK 埋点生成自定义 Span。
为 Span 增加自定义 Attributes。
获取当前 Trace 上下文并打印 traceId。
名词介绍
Span:一次请求的一个具体操作,比如一次 LLM 调用或一次工具执行。
SpanContext:一次请求追踪的上下文,包含 traceId、spanId 等信息。
Attribute:Span 的附加属性字段,用于记录关键信息,如模型名称、Token 用量等。
Handler:loongsuite-util-genai 提供的
ExtendedTelemetryHandler,用于创建符合 GenAI语义约定的 Span。
loongsuite-util-genai 支持的全部 Span 类型如下表所示,本文重点介绍 Entry、Agent、Tool 和 ReAct Step 的用法,其他类型(Embedding、Retrieval、Rerank、Memory等)的详细用法请参见loongsuite-util-genai 完整文档。
Span 类型 | 操作名 | 说明 |
Entry |
| 应用入口,携带 session_id / user_id / 应用完整互动信息 |
Agent |
| Agent 调用,汇总 Token 用量 |
Tool |
| 工具/函数执行 |
Step |
| ReAct 单轮迭代标识 |
LLM |
| 大模型对话(通常由探针自动采集) |
Embedding |
| 向量嵌入 |
Retriever |
| 检索(RAG) |
Reranker |
| 重排序 |
Memory |
| 记忆读写 |
下面分步介绍各类 Span 的埋点写法,每一步给出独立的代码片段。完整可运行的示例代码请参见本文末尾附录部分。
请务必通过 get_extended_telemetry_handler() 获取 Handler 实例,而非直接实例化 TelemetryHandler。ARMS 探针仅对 get_extended_telemetry_handler() 进行了兼容适配,直接实例化 TelemetryHandler 可能导致环境变量兼容性问题。
自定义埋点时请务必遵循LLM Trace字段定义说明中的语义规范。AI应用可观测能力(Token统计、会话分析等)均基于该规范中定义进行适配和渲染,若 Span 属性不符合规范,相关数据可能无法在控制台中正确展示。
1. 获取 Handler 和 Tracer
通过 get_extended_telemetry_handler() 获取 loongsuite-util-genai 的单例 Handler,通过 get_tracer(__name__) 获取 OpenTelemetry SDK 的 Tracer。两者分别用于创建 GenAI 语义 Span 和自定义业务 Span。
from opentelemetry.util.genai.extended_handler import get_extended_telemetry_handler
from opentelemetry.util.genai.extended_types import (
ExecuteToolInvocation,
InvokeAgentInvocation,
)
from opentelemetry.util.genai._extended_common import EntryInvocation, ReactStepInvocation
from opentelemetry.util.genai.types import Error, InputMessage, OutputMessage, Text
from opentelemetry.trace import get_tracer
handler = get_extended_telemetry_handler()
tracer = get_tracer(__name__)
Handler 提供两种使用方式:
上下文管理器(
with handler.entry(inv)等):推荐方式,自动管理 Span 生命周期。start/stop/fail API(
handler.start_entry(inv)/handler.stop_entry(inv)/handler.fail_entry(inv, error)):适用于异步、回调或流式等无法使用with语句的场景。
2. 创建 Entry Span
在请求入口处创建 Entry Span,携带 session_id、user_id,并通过 input_messages 记录用户输入。流式响应完成后,将输出内容拼接设置到 output_messages,再调用 stop_entry 结束 Span。这样在控制台中能直接看到该次请求的完整输入和最终输出。
entry_inv = EntryInvocation(
session_id=req.session_id or str(uuid.uuid4()),
user_id=req.user_id or "anonymous",
input_messages=[
InputMessage(role="user", parts=[Text(content=req.topic)]),
],
)
def event_generator():
handler.start_entry(entry_inv)
output_chunks: list[str] = [ ]
try:
for chunk in run_agent_stream(topic=req.topic):
output_chunks.append(chunk)
yield f"data: {json.dumps({'content': chunk}, ensure_ascii=False)}\n\n"
yield "data: [DONE]\n\n"
except Exception as exc:
handler.fail_entry(entry_inv, Error(message=str(exc), type=type(exc)))
yield f"data: {json.dumps({'error': str(exc)}, ensure_ascii=False)}\n\n"
return
entry_inv.output_messages = [
OutputMessage(
role="assistant",
parts=[Text(content="".join(output_chunks))],
finish_reason="stop",
),
]
handler.stop_entry(entry_inv)
3. 创建 Agent Span
通过 start_invoke_agent 创建 Agent Span,记录 Agent 名称、模型和描述信息。Agent Span 是整个调用链的根 GenAI Span,所有后续的 ReAct Step、LLM 调用和 Tool 调用都作为它的子 Span。
invocation = InvokeAgentInvocation(
provider="dashscope",
agent_name="TechContentAgent",
agent_description="技术内容生成助手",
request_model="qwen-plus",
)
total_input_tokens = 0
total_output_tokens = 0
handler.start_invoke_agent(invocation)
try:
# ... Agent 核心逻辑(ReAct 循环) ...
invocation.input_tokens = total_input_tokens
invocation.output_tokens = total_output_tokens
handler.stop_invoke_agent(invocation)
except Exception:
handler.fail_invoke_agent(invocation, Error(message="agent failed", type=RuntimeError))
raise
Agent 执行完成后,将累积的 total_input_tokens 和 total_output_tokens 写入 Agent Span,实现 Token 指标汇总统计。
4. 创建 ReAct Step Span
在每一轮 ReAct 推理迭代时创建 Step Span,传入当前轮次 round。迭代结束时设置 finish_reason:需要继续迭代为 continue,最终回答为 stop。示例中每轮迭代的 LLM 调用由 ARMS 探针自动埋点,无需手动创建。
step_inv = ReactStepInvocation(round=iteration + 1)
handler.start_react_step(step_inv)
try:
response = client.chat.completions.create(
model="qwen-plus",
messages=messages,
tools=TOOL_DEFINITIONS,
)
# ... 处理响应 ...
step_inv.finish_reason = "stop" # 或 "continue"
handler.stop_react_step(step_inv)
except Exception:
handler.fail_react_step(step_inv, Error(message="step failed", type=RuntimeError))
raise
5. 创建 Tool Span
当模型返回工具调用时,为每个 tool_call 创建 Tool Span,记录工具名称、调用 ID、入参和返回结果。
tool_inv = ExecuteToolInvocation(
tool_name=tool_call.function.name,
tool_call_id=tool_call.id,
tool_call_arguments=tool_call.function.arguments,
tool_type="function",
)
handler.start_execute_tool(tool_inv)
try:
result = dispatch_tool(tool_name, tool_call.function.arguments)
tool_inv.tool_call_result = result
except Exception as exc:
handler.fail_execute_tool(tool_inv, error=Error(message=str(exc), type=type(exc)))
raise
else:
handler.stop_execute_tool(tool_inv)
6. 使用 OpenTelemetry SDK 创建自定义 Span
除了 loongsuite-util-genai 提供的 GenAI 语义 Span,还可以通过 OpenTelemetry SDK 的 tracer.start_as_current_span() 创建自定义业务 Span,与 GenAI Span 混合使用。
以下示例展示了两种典型的自定义 Span 用法:
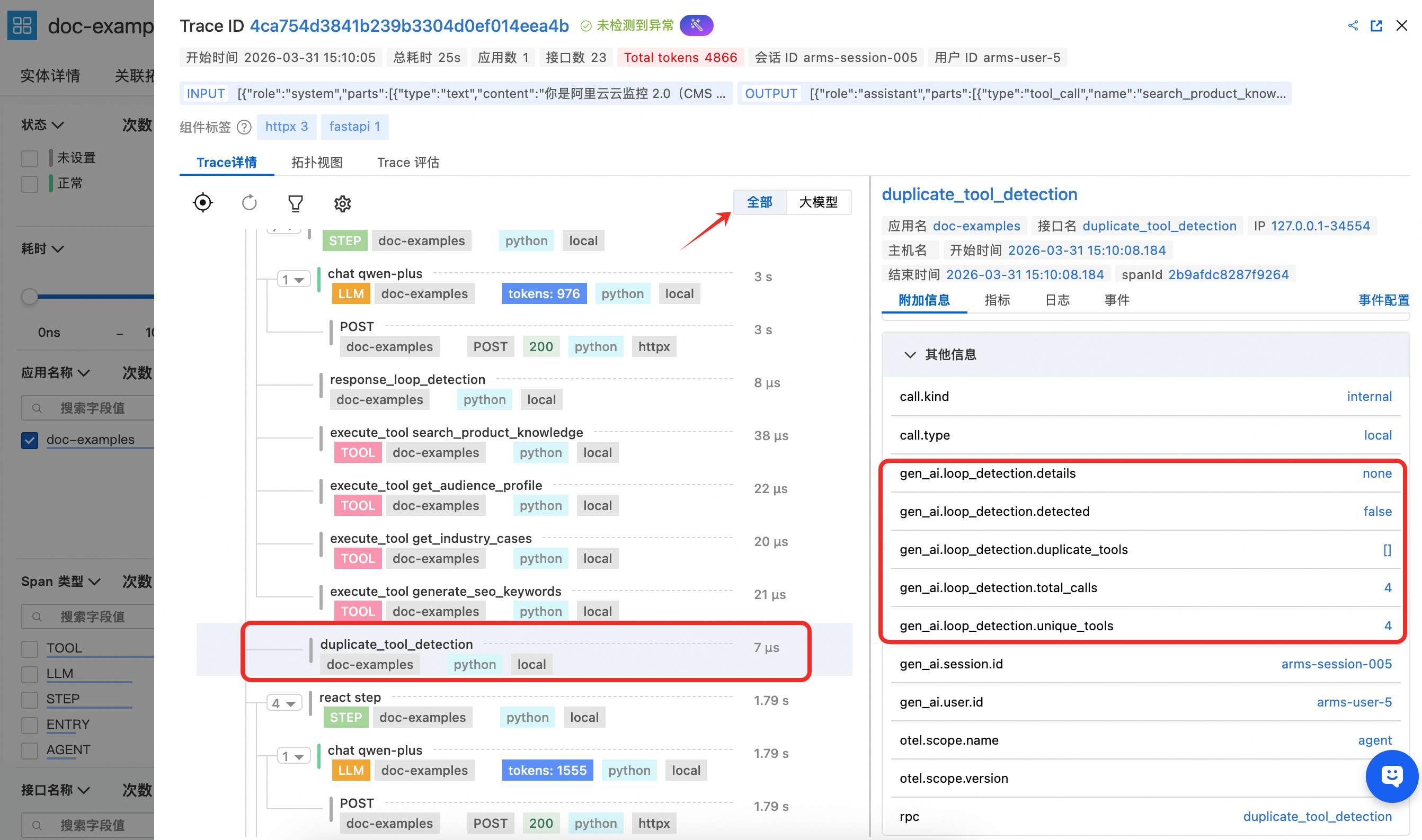
duplicate_tool_detection — 工具重复调用检测
在每轮 ReAct 迭代前执行,通过 Counter 统计每个工具的调用次数,将检测结果写入 gen_ai.loop_detection.* 属性。若发现重复,向消息列表追加系统提示引导模型避免重复。
def _check_duplicate_tools(
tool_usage_counter: Counter,
messages: list[dict[str, Any]],
) -> None:
duplicates = [name for name, count in tool_usage_counter.items() if count > 1]
has_duplicates = len(duplicates) > 0
with tracer.start_as_current_span("duplicate_tool_detection") as span:
span.set_attributes({
"gen_ai.loop_detection.detected": has_duplicates,
"gen_ai.loop_detection.duplicate_tools": str(duplicates) if has_duplicates else "[ ]",
"gen_ai.loop_detection.total_calls": sum(tool_usage_counter.values()),
"gen_ai.loop_detection.unique_tools": len(tool_usage_counter),
})
if has_duplicates:
details = ", ".join(f"{n}({tool_usage_counter[n]}次)" for n in duplicates)
messages.append({
"role": "system",
"content": f"[系统提示] 检测到工具被重复调用:{details}。请避免重复调用。",
})
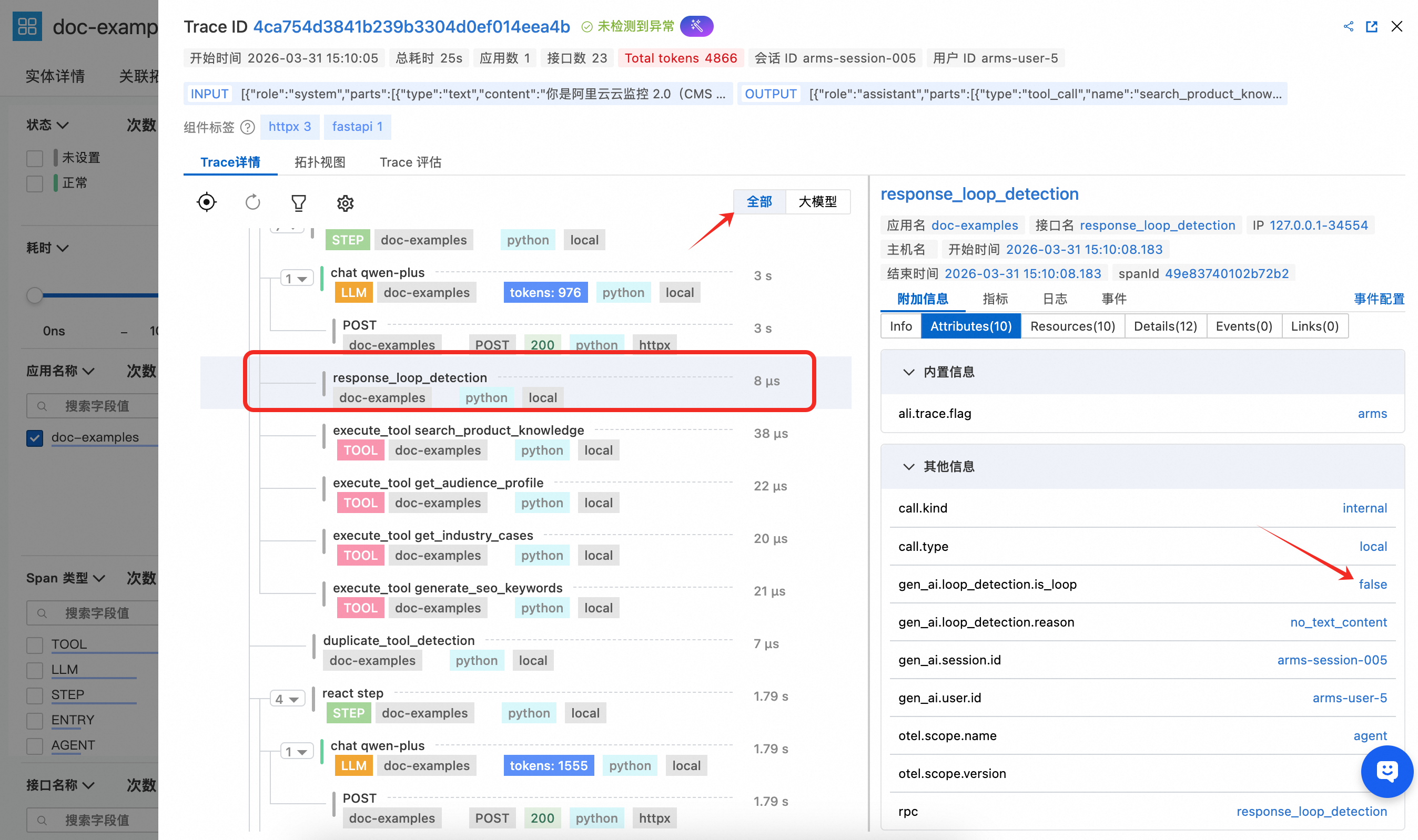
response_loop_detection — LLM 回复循环检测
在每轮 LLM 回复后执行,通过比较当前回复与上一轮回复的文本相似度,将 is_loop、overlap_ratio 等指标写入 Span 属性。若检测到循环(文本完全相同或重叠率超过 80%),设置 finish_reason 为 loop_detected 并提前终止 Agent。
def _check_response_loop(
current_content: str | None,
previous_content: str | None,
) -> bool:
cur = (current_content or "").strip()
prev = (previous_content or "").strip()
with tracer.start_as_current_span("response_loop_detection") as span:
if not prev or not cur:
span.set_attributes({
"gen_ai.loop_detection.is_loop": False,
"gen_ai.loop_detection.reason": "no_text_content",
})
return False
is_identical = cur == prev
longer = max(len(cur), len(prev))
common_prefix_len = sum(1 for a, b in zip(cur, prev) if a == b)
overlap_ratio = common_prefix_len / longer if longer > 0 else 0.0
is_loop = is_identical or overlap_ratio > 0.8
span.set_attributes({
"gen_ai.loop_detection.is_loop": is_loop,
"gen_ai.loop_detection.is_identical": is_identical,
"gen_ai.loop_detection.overlap_ratio": round(overlap_ratio, 2),
"gen_ai.loop_detection.current_length": len(cur),
"gen_ai.loop_detection.previous_length": len(prev),
})
return is_loop
由于自定义 Span 不属于大模型语义规范,在控制台的调用链视图中需要切换到全部视图才能查看。
查看监控详情
登录云监控2.0控制台,选择目标工作空间,在左侧导航栏选择所有功能 > AI应用可观测。
在AI应用列表页面可以看到已接入的应用,单击应用名称可以查看详细的应用监控数据。
埋点效果展示
1. Entry Span 详情
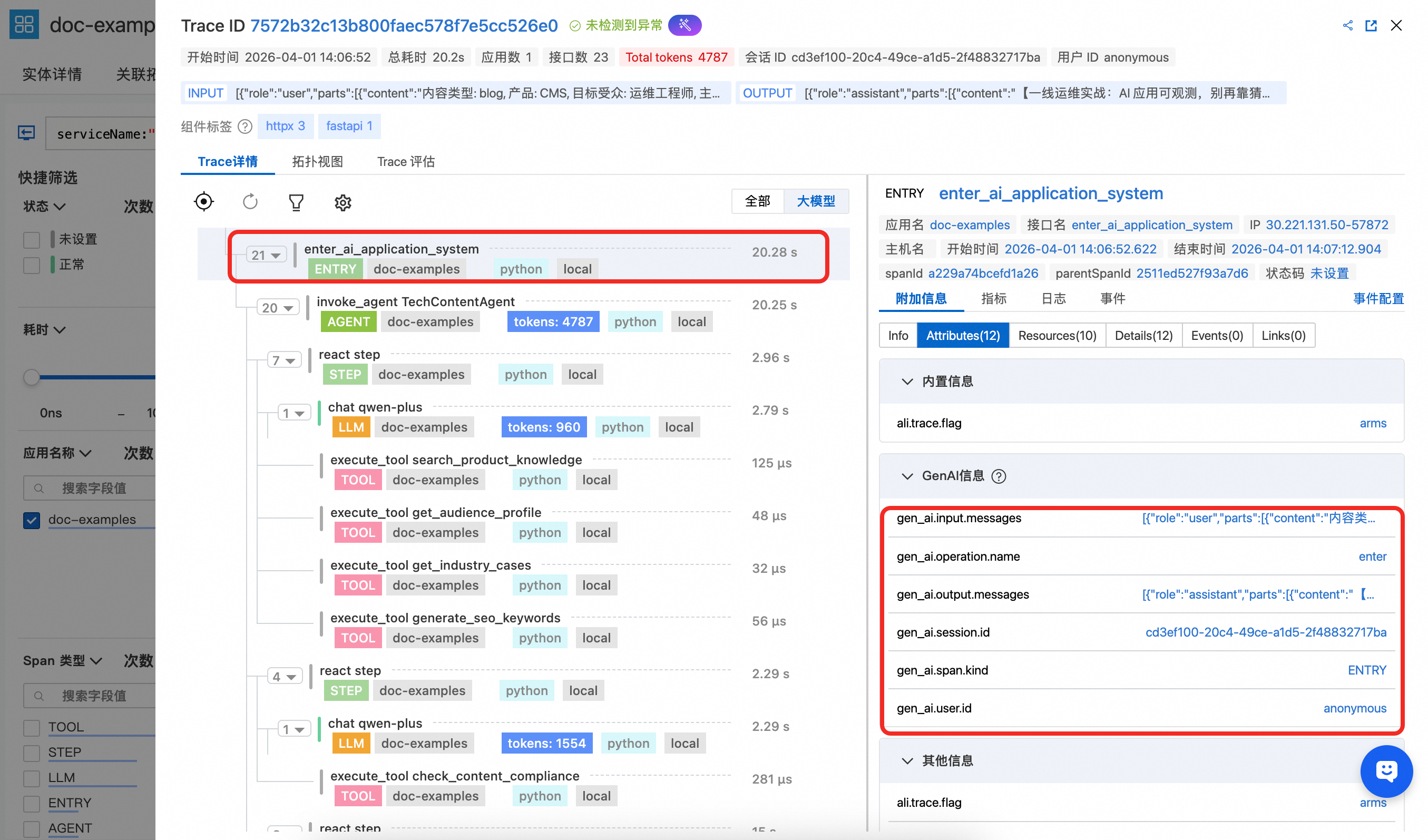
Enter Span 能看到 gen_ai.session.id、gen_ai.user.id 等关键属性,通过在函数入口处设置能自动透传到 LLM、TOOL等Span中,能用于关联会话和用户信息进行分析。同时 Entry Span 还携带 gen_ai.input.messages(用户输入内容)和 gen_ai.output.messages(最终输出内容),便于在控制台中直接查看该次请求的整体交互内容。
2. Agent Span 详情
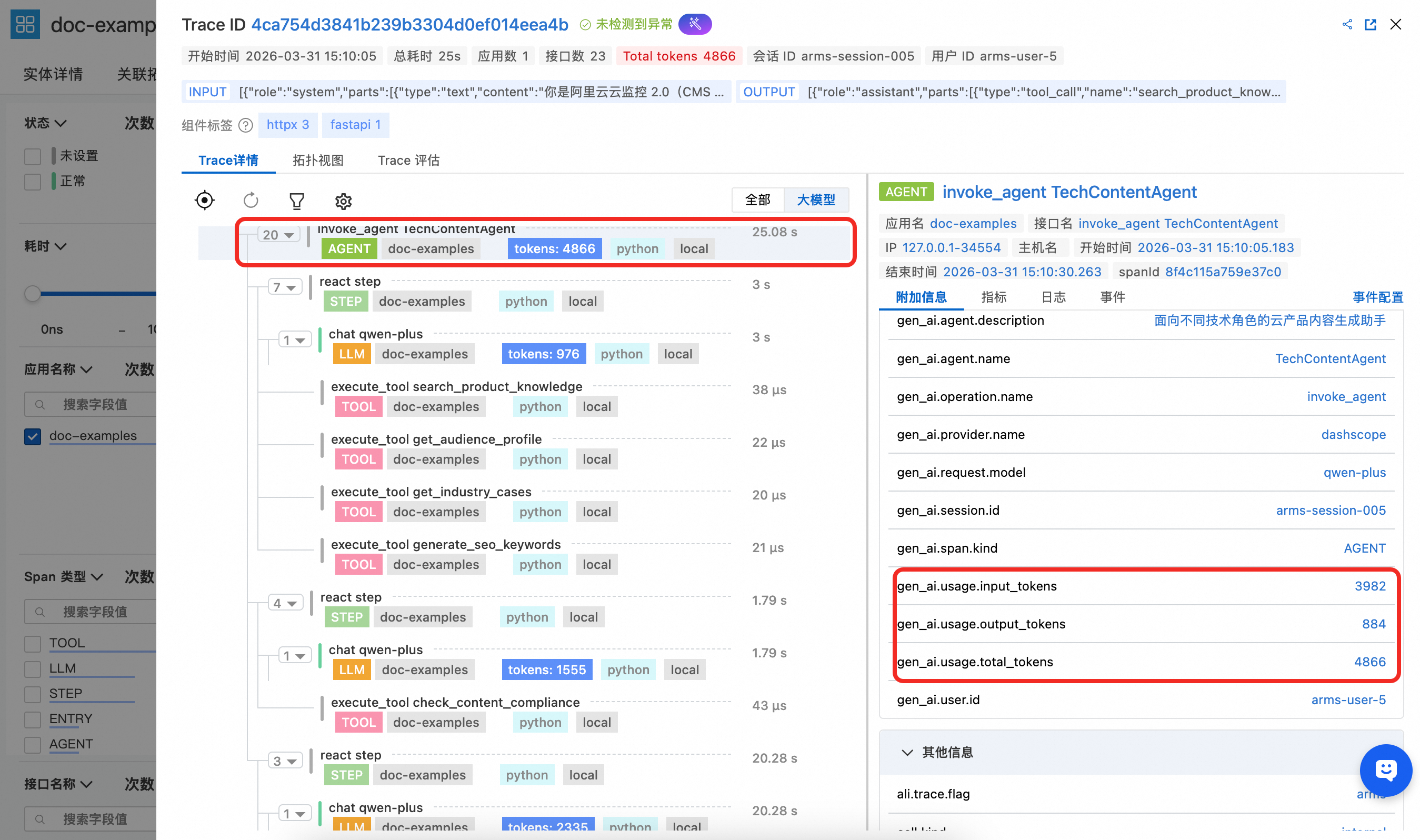
Agent Span能看到该 Agent 的定义名称以及相应的描述,同时体现上述示例代码中统计的属于该 Agent 级别的 Token 用量汇总统计效果。
3. Tool Span 详情
Tool Span 能看到该 Tool 的名称以及入参配置,并且展示工具调用结果。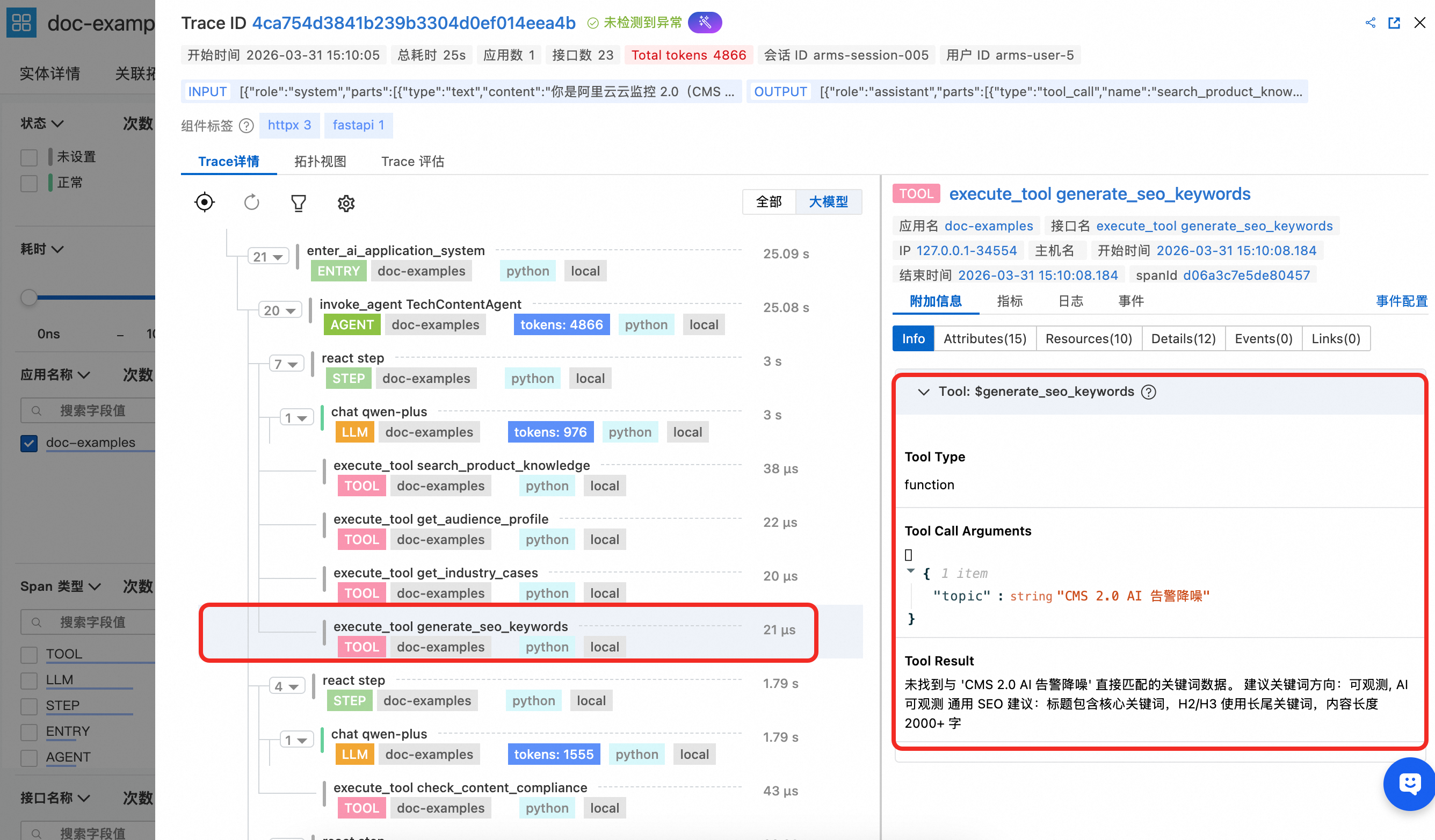
4. LLM Span 详情
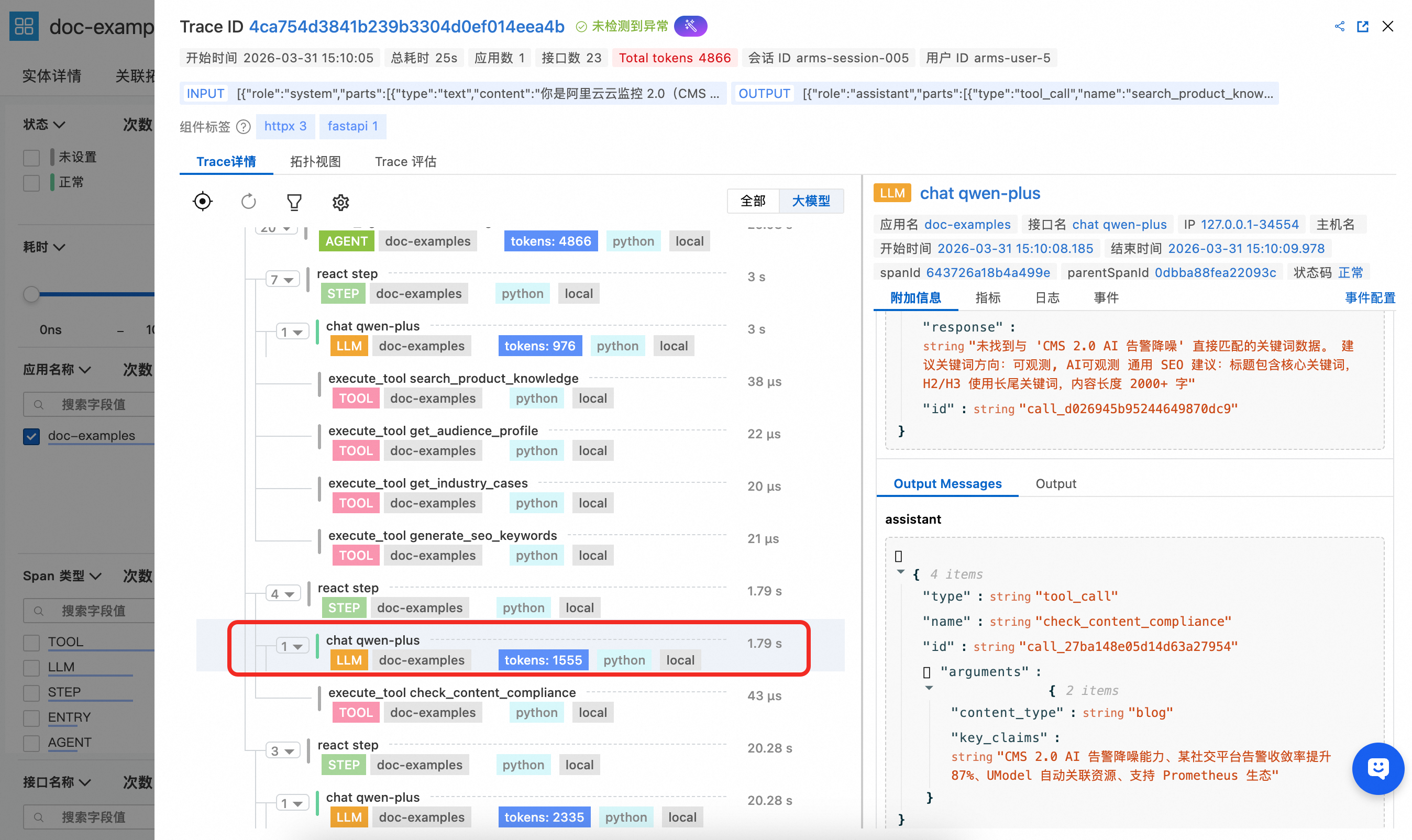
LLM Span在上述示例代码中并没有进行手动埋点,由于是 openai 调用,此处全部由探针自动采集,能清晰观察到该次 LLM 调用的完整上下文信息以及 token 消耗。
5.自定义 Span 详情
示例代码中通过 OpenTelemetry SDK 创建了两个自定义业务 Span,展示如何将自定义埋点与 GenAI 语义 Span 混合使用,由于该自定义Span并不在大模型语义中,需要打开全部视图进行查看。
duplicate_tool_detection:在每轮 ReAct 迭代前执行,用于检测 Agent 是否陷入工具重复调用。Span 属性中记录了是否检测到重复、重复的工具列表、总调用次数和去重工具数,便于在 ARMS 中快速定位 Agent 的工具调用循环问题。
response_loop_detection:在每轮 LLM 回复后执行,用于检测模型是否连续返回高度相似的内容。Span 属性中记录了是否判定为循环、文本是否完全相同、重叠率以及当前和上一轮回复的文本长度,帮助排查模型陷入重复输出的异常场景。

相关文档
loongsuite-util-genai 支持的全部 Span 类型(Embedding、Retrieval、Rerank、Memory等)的详细用法,请参见loongsuite-util-genai 完整文档。