PolarDB MySQL版通过数据库内核与RDMA网络的深度融合,提供全局一致性(高性能模式),简称PolarDB-SCC(PolarDB-StronglyConsistentCluster)。在保证全局数据一致性的前提下,实现高性能数据读写。与最终一致性方案相比,开启全局一致性(高性能模式)后集群性能损失保持在10%以内。本文将详细介绍全局一致性(高性能模式)的使用限制、技术原理、开启方式以及性能测试结果对比。
版本要求
若要开启全局一致性(高性能模式),PolarDB MySQL版企业版集群需为以下版本之一:
8.0.2版本且内核小版本需为8.0.2.2.19及以上。
8.0.1版本且内核小版本需为8.0.1.1.29及以上。
5.7版本且内核小版本需为5.7.1.0.26及以上。
如何确认集群版本,请参见查询版本号。
注意事项
Serverless集群的所有只读节点默认开启全局一致性(高性能模式)。
全球数据库网络GDN中的从集群的只读节点不支持开启全局一致性(高性能模式)。
全局一致性(高性能模式)与Fast Query Cache功能兼容。若此前全局一致性(高性能模式)打开了分层的细粒度的修改跟踪(MTT)优化功能。当同时开启Fast Query Cache功能和全局一致性(高性能模式)功能时,全局一致性(高性能模式)的MTT优化功能将失效。
全局一致性(高性能模式)技术方案
PolarDB MySQL版全局一致性(高性能模式)是以PolarTrans为基础,这是一套全新设计的基于时间戳的事务系统,旨在重构原生MySQL中基于活跃事务数组的传统事务管理方式。该系统不仅支持分布式事务的扩展,更显著提升了单机的性能表现。
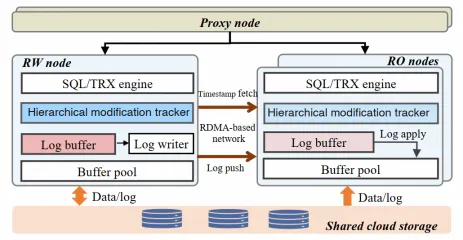
PolarDB全局一致性(高性能模式)的具体实现如下图所示,利用高速RDMA网络构建交互式多维度主从信息同步机制,取代了传统的主从日志复制架构,并通过线性Lamport时间戳算法,减少RO节点获取时间戳的次数,同时避免了不必要的日志回放等待。
线性Lamport时间戳:为了优化读操作(RO)节点获取最新修改时间戳的效率,我们引入了线性Lamport时间戳机制。传统方法中,RO节点需要在处理每个请求时都从写操作(RW)节点获取时间戳,即使网络速度很快,在高负载情况下也会产生显著开销。线性Lamport时间戳的优势在于,RO节点可以将从RW节点获取的时间戳存储在本地。对于早于本地存储的时间戳的请求,RO节点可以直接使用本地时间戳,无需再次向RW节点获取。这种机制有效减少了高负载下频繁获取时间戳的开销,提高了RO节点的性能。
分层的细粒度的修改跟踪:为了优化读操作(RO)的性能,RW引入了多级时间戳机制:全局、表级和页面级。当RO处理请求时,首先会获取全局时间戳。如果全局时间戳大于RO回放日志的时间戳,RO不会立即进入等待状态,而是会继续检查请求访问的表和页面时间戳。只有当访问的页面时间戳仍然不满足时,RO才会等待日志回放完成。这种机制可以有效避免一些不必要的日志回放等待,提高RO的响应速度。
基于RDMA的日志传输:PolarDB全局一致性(高性能模式)采用了单边RDMA的接口来实现RW到RO的日志传输,极大地提高了日志传输速度,同时减少了日志传输时带来的CPU开销。
线性Lamport时间戳
为了降低读请求的延迟和带宽消耗,RO节点可以利用线性Lamport时间戳机制。当一个请求到达RO节点时,如果发现其他请求已经从RW节点获取了时间戳,它可以直接重用该时间戳,从而避免重复请求,保证强一致性的同时提升性能。
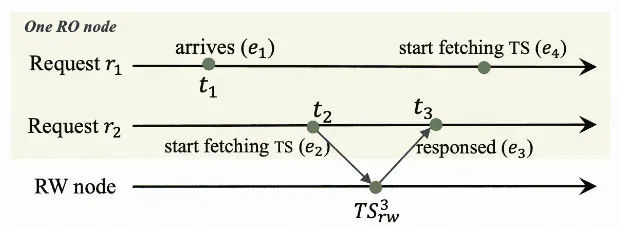
上图中一个RO上有两个并发的读请求r1和r2。r2在t2时向RW发送读取时间戳的请求,在t3时刻拿到了RW的时间戳TS3rw。我们可以得到这几个事件的关系:e2TS3rwe3。r1在t1时刻到达。通过在RO给每个事件分配一个时间戳,可以确定同一个RO上不同事件的先后关系。如果t1在t2之前,我们可以得到e1e2TS3rwe3。也就是说r2拿到的时间戳,其实已经反映了r1到达之前的所有更新,所以r1可以直接使用r2的时间戳,而不必去拿新的时间戳。基于这个原则,RO每次拿到RW的时间戳时,都会把这个时间戳保存在本地,并且会记录获取到该时间戳的时间,如果某个请求的到达时间早于本地缓存时间戳的获取时间,则该请求可以直接使用该时间戳。
分层的细粒度的修改跟踪
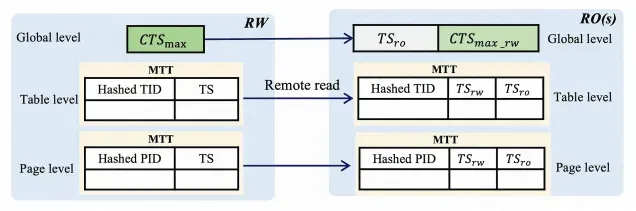
为了实现强一致读,RO需要首先获取RW当前事务的最新提交时间戳,并等待RO上的日志回放到该时间戳才能处理读请求。然而,在等待日志回放期间,当前请求的数据可能已经是最新的,无需等待。为了避免不必要的等待时间。PolarDB全局一致性(高性能模式)采用了更加细粒度的修改追踪。在RW上维护三层修改信息:全局的最新修改的时间戳,表级的时间戳和页面(page)级别的时间戳。
在处理读请求时,RO首先获取全局时间戳,以判断数据一致性。如果全局时间戳不满足条件,RO会进一步获取目标表的本地时间戳,进行更细粒度的校验。如果仍不满足,RO会继续检查目标页面的时间戳,进行更精确的判断。只有当页面时间戳仍然大于RO日志回放时间戳时,RO才需要等待日志回放,以确保读取到最新的数据。
在RW上,为了降低内存消耗,三种层级的时间戳都保存在内存哈希表中。为了进一步优化内存使用,多个表或页的时间戳可能被映射到同一个哈希表位置。为了保证一致性,仅允许较大的时间戳替换较小的。这种设计确保即使RO获取到较大的时间戳也不会破坏一致性。具体实现如图所示,TID和PID分别表示表和页的ID。RO获取到的时间戳会按照线性Lamport时间戳的设计缓存到本地,方便其他符合条件的请求使用。
基于RDMA的日志传输
在PolarDB全局一致性(高性能模式)中。RW通过单边RDMA的方式远程将日志写入到RO缓存,该过程不需要RO的CPU参与,同时延迟也很低。具体实现如下图所示,RO和RW都维护了相同大小的log buffer。RW的后台线程会将RW的log buffer通过RDMA写入到RO的log buffer,RO通过读取本地log buffer替代读取文件, 加快复制同步效率。
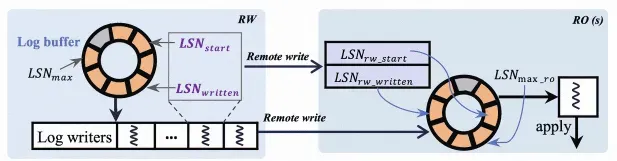
如需了解RDMA日志传输的更多说明,请参见RDMA日志传输。
如何开启全局一致性(高性能模式)
登录PolarDB控制台,在目标集群的基本信息页面的数据库连接区域,选中需要开启全局一致性(高性能模式)功能的连接地址,单击配置。详细操作步骤请参见配置数据库代理。

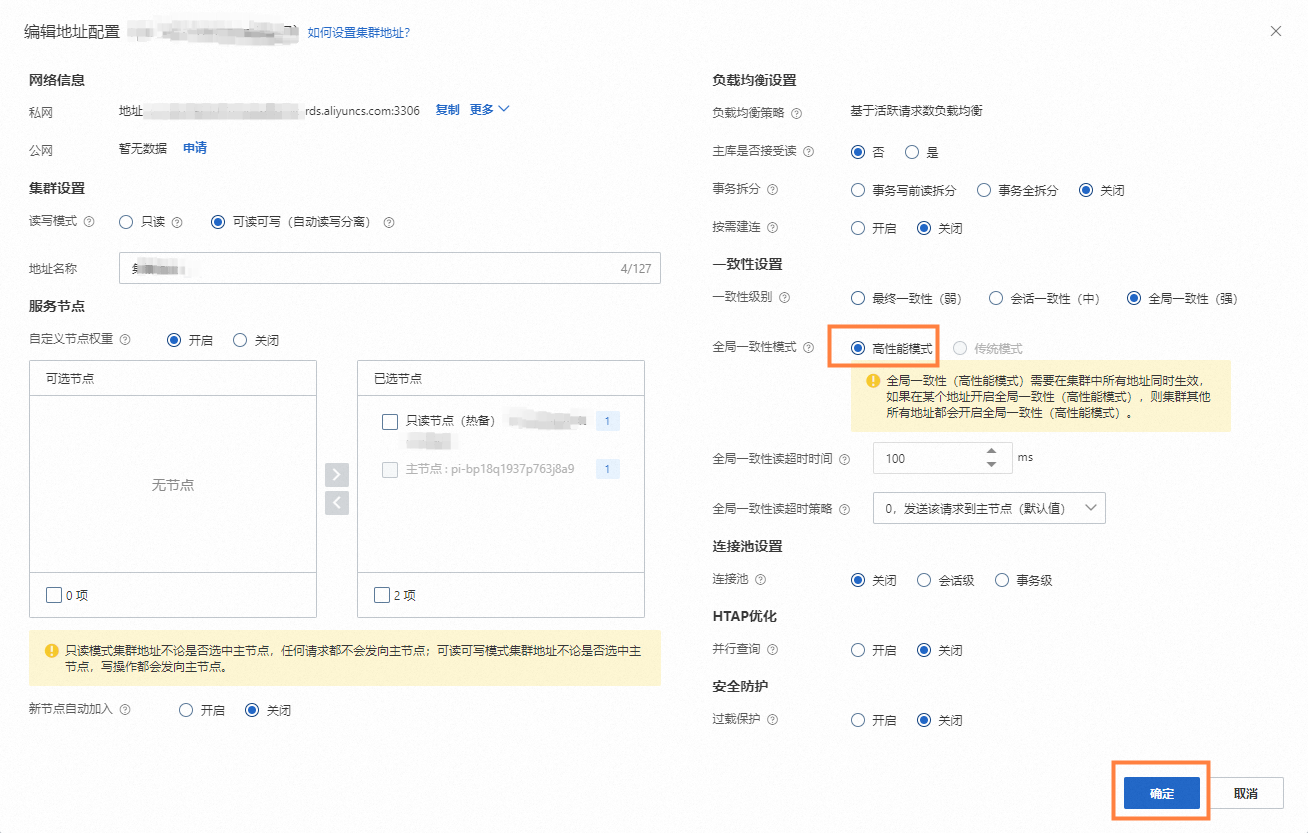
全局一致性(高性能模式)需要在集群中所有地址同时生效,如果在某个地址开启全局一致性(高性能模式),则集群其他所有地址都会开启全局一致性(高性能模式)。
性能对比
测试环境
一个规格为8核32 GB的PolarDB MySQL版8.0版本集群版。
测试工具
Sysbench
测试数据量
25张表,每张表250000行数据。
测试结果及说明
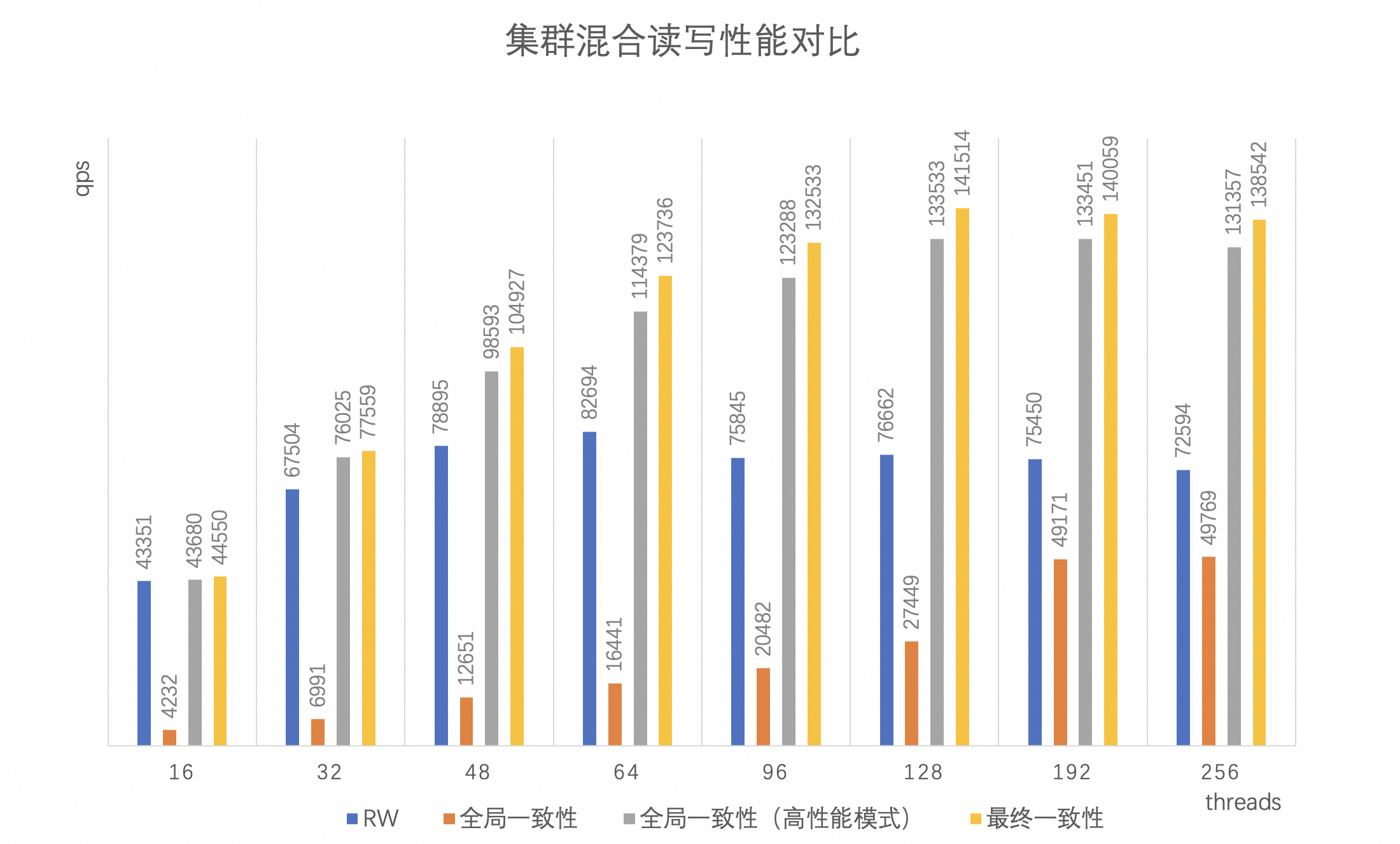
全局一致性(高性能模式)集群混合读写性能对比
图表说明:
纵坐标qps:表示sysbench测试结果。
横坐标threads:表示测试时使用的sysbench并发线程数。
RW:表示假设RO无法提供全局一致性读,所有的读写请求均发往RW节点。
全局一致性:表示由代理提供的全局一致性功能。
全局一致性(高性能模式):表示打开内核提供的全局一致性(高性能模式)代理设置最终一致性。
最终一致性:表示代理设置为最终一致性读,并且关闭内核提供的全局一致性(高性能模式)。
在
sysbench oltp_read_write场景中,全局一致性(高性能模式)相比较于最终一致性,集群整体性能损耗控制在10%以内。