
本文介绍IMCI背后的技术路线和具体方案。
背景信息
PolarDB MySQL版是因云而生的一个数据库系统。除云上OLTP场景外,大量客户也对PolarDB提出了实时数据分析的性能需求。对此,PolarDB技术团队提出了In-Memory Column Index(IMCI)的技术方案,此方案在复杂分析查询场景获得了数百倍的加速效果。
MySQL生态HTAP数据库解决方案
MySQL是一款主要面向OLTP场景设计的开源数据库。开源社区的研发方向侧重于加强其事务处理的能力,例如:提升单核性能、多核扩展性能、增强集群能力以提升可用性等。在处理大数据量下复杂查询所需要的能力方面,如优化器处理子查询的能力、高性能算子HashJoin、SQL并行执行等。社区将其处于低优先级,因此MySQL的数据分析能力提升进展缓慢。
随着MySQL的发展,用户使用其存储了大量的数据,并且运行着关键的业务逻辑。对这些数据进行实时分析成为一个日益增长的需求。当单机MySQL不能满足需求时,用户寻求一个更好的解决方案。
MySQL+专用AP数据库的搭积木方案
专用分析型数据库产品众多,一个可选方案为:使用两套系统来分别满足OLTP和OLAP型需求,在两套系统中间通过数据同步工具进行数据实时同步。用户甚至可以增加一层proxy,自动将TP型负载路由至MySQL数据库,而将分析型负载路由至OLAP数据库。
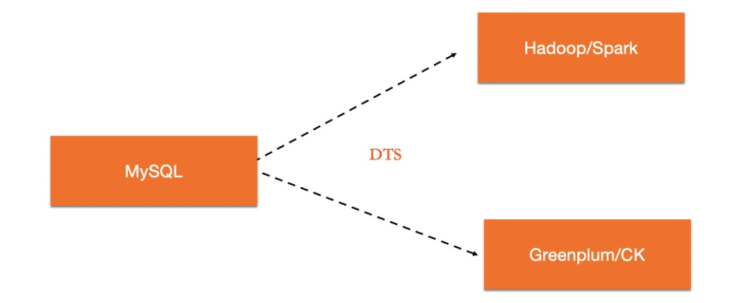 这样的架构有其灵活之处。例如,对于TP数据库和AP数据库都可以各自选择最好的方案,并且实现了TP/AP负载的完全隔离。但其缺点也是显而易见的。首先,在技术上需要维护两套不同技术体系的数据库系统。其次,由于两套系统处理机制的差异,维护上下游的数据实时一致性非常具有挑战。而且由于数据同步存在延迟,下游AP系统存储的经常是过时的数据,导致无法满足用户实时分析数据的需求。
这样的架构有其灵活之处。例如,对于TP数据库和AP数据库都可以各自选择最好的方案,并且实现了TP/AP负载的完全隔离。但其缺点也是显而易见的。首先,在技术上需要维护两套不同技术体系的数据库系统。其次,由于两套系统处理机制的差异,维护上下游的数据实时一致性非常具有挑战。而且由于数据同步存在延迟,下游AP系统存储的经常是过时的数据,导致无法满足用户实时分析数据的需求。基于多副本的Divergent Design方法
随着互联网而兴起的新型数据库产品很多都兼容MySQL协议。因此,新型数据库成为替代MySQL的一个可选项。而这些分布式数据库产品大部分采用了分布式Share Nothing的方案。核心特点是使用分布式一致性协议来保障单个partition多副本之间的数据一致性。由于一份数据在多个副本之间完全独立,因此在不同副本上使用不同格式进行存储,来服务不同的查询负载是一个易于实施的方案。例如,TiDB从TiDB4.0开始,在Raft Group的其中一个副本上使用列式存储(TiFlash)来响应AP型负载,并通过TiDB的智能路由功能来自动选取数据来源。实现了一套数据库系统同时服务OLTP型负载和OLAP型负载。该方法在诸多Research及Industry领域的工作中都被借鉴并使用,并日益成为分布式数据领域一体化HTAP的事实标准方案。但是应用这个方案的前提是用户需要迁移到对应的NewSQL数据库系统,而这会出现各种兼容性适配问题。
一体化的行列混合存储方案
较多副本Divergent Design方法更进一步的方案,是在同一个数据库实例中采用行列混合存储,同时响应TP型和AP型负载。这是传统商用数据库Oracle、SQL Server或DB2等不约而同采用的方案。
Oracle公司在2013年发表的Oracle 12C上,发布了Database In-Memory套件。其最核心的功能即为In-Memory Column Store,通过提供行列混合存储、高级查询优化(物化表达式,JoinGroup)等技术提升OLAP性能。
微软在SQL Server 2016 SP1上,开始提供Column Store Index功能。用户可以根据负载特征,灵活的使用纯行存表、纯列存表、行列混合表、列存表+行存索引等多种模式。
IBM在2013年发布的10.5版本(Kepler)中,增加了DB2 BLU Acceleration组件,通过列式数据存储配合内存计算以及DataSkipping技术,大幅提升分析场景的性能。
三家领先的商用数据库厂商,均同时采用了行列混合存储结合内存计算的技术路线。列式存储由于有更好的IO效率(压缩,DataSkipping,列裁剪)以及CPU计算效率(Cache Friendly)。因此要达到最极致的分析性能必须使用列式存储,而列式存储中索引稀疏导致的索引精准度问题决定它不可能成为TP场景的存储格式,如此行列混合存储成为一个必选方案。但在行列混合存储架构中,行存索引和列存索引在处理随机更新时存在性能鸿沟,必须借助DRAM的低读写延时来弥补列式存储更新效率低的问题。因此在低延时在线事务处理和高性能实时数据分析两大前提下,行列混合存储结合内存计算是唯一方案。
对比上述三种方案,从组合搭积木的方法,到Divergent Design方法,再到一体化的行列混合存储。其集成度越来越高,用户的使用体验也越来越好。但是其对内核工程实现上的挑战也越来越大。基础软件的作用就是将复杂留给自己,把简单留给用户。因此一体化的方法更符合技术发展趋势。
PolarDB MySQL版 AP能力的演进
PolarDB MySQL版能力栈与开源MySQL类似,长于TP但AP能力较弱。由于PolarDB提供了单实例500 TB的存储能力,同时其事务处理能力远超用户自建MySQL。因此PolarDB用户倾向于在单实例存储更多的数据,同时会在这些数据上运行一些复杂聚合查询。借助于PolarDB一写多读的架构,用户可以增加只读的RO节点以运行复杂只读查询,从而避免分析型查询对TP负载的干扰。
MySQL的架构在AP场景的缺陷
MySQL的实现架构在执行复杂查询时,性能差存在诸多原因。对比专用的OLAP系统,其性能瓶颈体如下:
MySQL的SQL执行引擎基于流式迭代器模型(Volcano Iterator),而这个模型在工程实现上依赖大量深层次的函数嵌套及虚函数调用,当处理海量数据时,会影响CPU流水线的Pipeline效率,导致CPU Cache效率低下。同时Iterator执行模型也不能使用CPU提供的SIMD指令来做执行加速。
执行引擎只能串行执行,不能发挥多核CPU的并行执行能力。从MySQL 8.0开始,在一些count(*)等基本查询上增加并行执行的能力,但是复杂SQL的并行执行能力构建依然任重道远。
MySQL最常用的存储引擎都是按行存储。在按列进行海量数据分析时,按行从磁盘读取数据存在非常大的IO带宽浪费,其次,行式存储格式在处理大量数据时会大量拷贝不必要的列数据,对内存读写效率也存在冲击。
PolarDB 并行查询突破CPU瓶颈
PolarDB团队开发的并行查询框架(Parallel Query),在查询数据量到达一定阈值时,会自动启动并行执行。在存储层将数据分片至不同的线程,多个线程并行计算。并将结果流水线汇总到总线程。最后,总线程做些简单归并返回给用户。
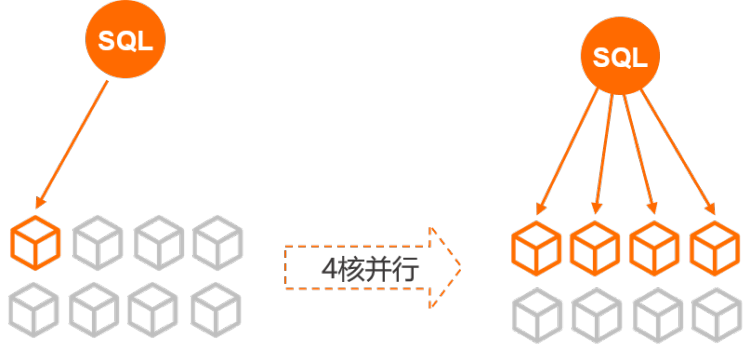 并行查询的加入使得PolarDB突破了单核执行性能的限制,利用多核CPU的并行处理能力,PolarDB部分SQL查询耗时成指数级下降。
并行查询的加入使得PolarDB突破了单核执行性能的限制,利用多核CPU的并行处理能力,PolarDB部分SQL查询耗时成指数级下降。Why We Need Column-Store
并行执行框架突破了CPU扩展能力的限制,带来了显著的性能提升。然而受限于行式存储及行式执行器的效率限制,单核执行性能存在天花板,其峰值性能依然与专用的OLAP系统存在差距。更进一步的提升PolarDB MySQL版的分析性能,我们需要引入列式存储:
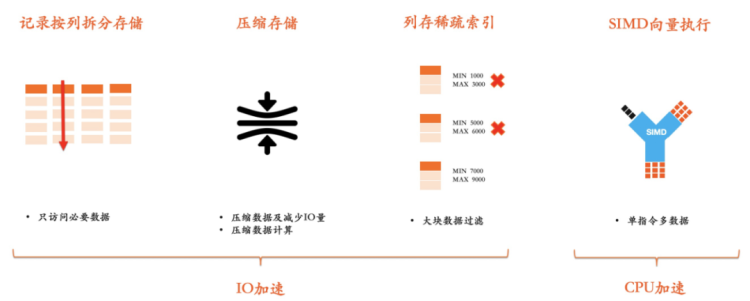
在分析场景,经常需要访问某个列的大量记录。而列存按列拆分存储的方式会避免读取不需要的列。其次,列存由于把相同属性的列连续保存,其压缩效率也远超行存,通常可以达到10倍以上。最后,列存中的大块存储结构,结合MIN、MAX等粗糙索引信息可以实现大范围的数据过滤。所有这些行为都极大的提升了IO的效率。在存储计算分离架构下,减少网络读取的数据量,可以缩短对查询处理的响应时间。
列式存储同样能提高CPU在处理数据时的执行效率。首先,列存的紧凑排列方式可提升CPU访问内存效率,减少L1/L2 Cache miss导致的执行停顿。其次,在列式存储上可以使用SIMD技术进一步提升单核吞吐能力,这也是现代高性能分析执行引擎的通用技术路线(Oracle/SQL Server/ClickHouse)。
PolarDB In-Memory Column Index
PolarDB In-Memory Column Index功能,为PolarDB带来列式存储以及内存计算能力。让用户可以在一套PolarDB数据库上同时运行TP和AP型混合负载。在保证现有PolarDB优异的OLTP性能的同时,大幅提升PolarDB在大数据量上运行复杂查询的性能。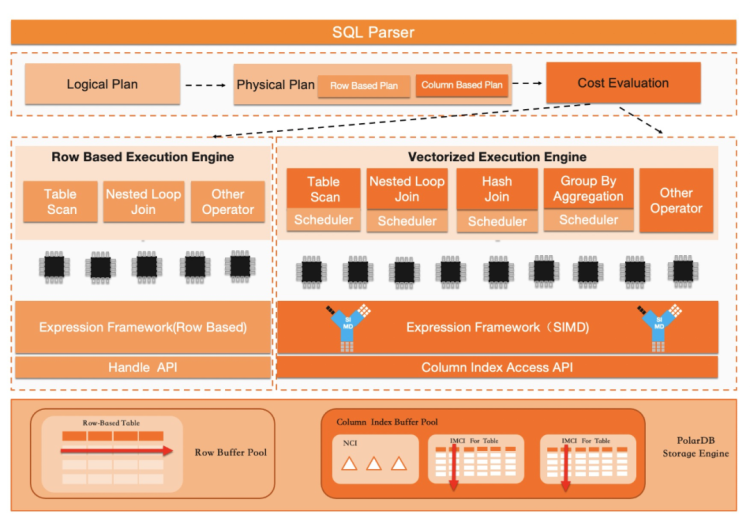 In-Memory Column Index使用行列混合存储技术,同时结合了PolarDB共享存储一写多读的架构。其包含如下几个关键的技术创新点:
In-Memory Column Index使用行列混合存储技术,同时结合了PolarDB共享存储一写多读的架构。其包含如下几个关键的技术创新点:
在PolarDB的存储引擎(InnoDB)上,新增列式索引(Columnar Index)。用户可以选择通过DDL将一张表的全部列或者部分列创建为列索引,列索引采用列压缩存储,其存储空间消耗会远小于行存格式。默认列索引会全部常驻内存以实现最大化分析性能,当内存不够时,也支持将其持久化至共享存储。
PolarDB的SQL执行器层,重写了一套面向列存的执行器引擎框架(Column-oriented)。该执行器框架充分利用列式存储的优势,例如,以一个4096行的Batch为单位访问存储层的数据,使用SIMD指令提升CPU单核处理数据的吞吐量,所有关键算子均支持并行执行。对比MySQL原有的行存执行器,性能有数量级的提升。
支持行列混合执行的优化器框架,该优化器框架会根据下发的SQL是否能在列索引上执行覆盖查询,并且其所依赖的函数及算子能被列式执行器所支持,来决定是否启动列式执行。优化器会同时对行存执行计划和列存执行计划做代价估算,并选中代价较低的执行计划。
用户可以使用PolarDB集群中的一个RO节点作为分析型节点,在该RO节点上配置生成列存索引。复杂查询运行在列存索引上并使用所有可用的CPU的计算能力,在获得最大执行性能的同时,不影响该集群上TP型负载的可用内存和CPU资源。
关键技术的结合,使得PolarDB成为了一个真正的HTAP数据库系统。其在大数据量上运行复杂查询的性能可以与Oracle、SQL Server等业界商用数据库系统处在同一水平。
In-Memory Column Index的技术架构
行列混合的优化器
PolarDB原生有一套面向行存的优化器组件。在引擎层增加列存功能后,此部分需要进行功能增强,优化器需要能够判断一个查询应该被调度到行存执行还是列存执行。通过一套白名单机制和执行代价计算框架来完成此项任务。系统保证对支持的SQL进行加速,同时兼容运行不支持的SQL。
如何实现100%的MySQL兼容性?
通过一套白名单机制来实现兼容性目标。使用白名单机制基于以下两点。
系统可用资源(主要是内存)限制。一般情况下,不会给所有的表都创建列索引,当一个查询语句需要使用的列不在列存中存在时,其不能在列存上执行。
性能。完全重写了一套面向列存的SQL执行引擎,包括其中所有的物理执行算子和表达式。其所覆盖的场景较MySQL原生行存支持的范围有欠缺。当下发的SQL中包含一些IMCI执行引擎不能支持的算子片段或者列类型时,需要能够识别拦截并切换回行存执行。
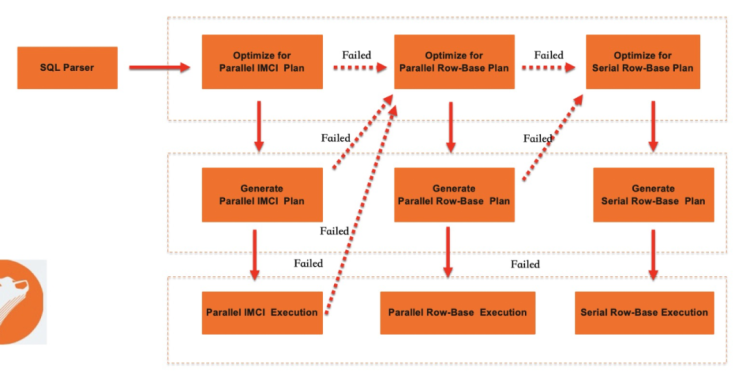
查询计划转换
Plan转换的目的,是将MySQL的原生逻辑执行计划表示方式AST转换为IMCI的Logical Plan。在生成IMCI的Logical Plan后,会经过Optimize过程,生成Physical Plan。Plan转换的方法简单,只需要遍历执行计划树,将MySQL优化后的AST转换成IMCI中以relation operator为节点的树状结构即可。在这个过程中,会做一部分额外的动作。例如,类型的隐式转换。
兼顾行列混合执行的优化器
存在行存和列存两套执行引擎,优化器在选择执行计划时有了更多的选择。其可以对比行存执行计划的Cost和列存执行计划的Cost,并使用代价最低的执行计划。在PolarDB中,除原生MySQL的行存串行执行外,还有能够发挥多核计算能力的基于行存的Parallel Query功能。因此,优化器会在行存串行执行、行存Parallel Query和IMCI三个选项之中选择。在目前的迭代阶段,优化器按如下的流程执行:
执行SQL的Parse过程,并生成LogicalPlan,然后再调用MySQL原生优化器。同时该阶段获得的逻辑执行计划转给IMCI的执行计划编译模块后,会尝试生成一个列存的执行计划(此处可能会被白名单拦截并fallback回行存)。
PolarDB的Optimizer会根据行存的Plan,计算得出一个面向行存的执行Cost。如果此Cost超过一定阈值,则会尝试下推到IMCI执行器并使用IMCI_Plan执行。
如果IMCI无法执行此SQL,则PolarDB会尝试编译出一个Parallel Query的执行计划并执行。如果无法生成PQ的执行计划,则说明IMCI和PQ均无法支持此SQL,fallback回行存执行。
上述策略从执行性能比较,IMCI优于行存并行执行,行存并行执行优于行存串行执行。从SQL兼容性比较,行存串行执行优于行存并行执行,行存并行执行优于IMCI。但实际情况可能会更复杂,例如,某些情况下,基于行存有序索引覆盖的并行Index Join会比基于列存的Sort Merge join有更低的Cost。目前的策略下,可能选择IMCI列存执行。
面向列式存储的执行引擎
IMCI执行引擎面向列存优化,并完全独立于现有MySQL行式执行器。重写执行器的目的是消除现有行存执行引擎在执行分析型SQL时导致效率低下的两个关键瓶颈点,按行访问导致的虚函数访问开销以及无法并行执行。
支持BATCH并行的算子
IMCI执行器引擎使用经典的火山模型,同时借用了列存存储以及向量执行来提升执行性能。
火山模型中,SQL生成的语法树所对应的关系代数中,每一种操作会抽象为一个Operator,执行引擎会将整个SQL构建为一个Operator 树。查询树时,自顶向下调用Next()接口,数据则自底向上被拉取处理。该方法的优点为:计算模型简单直接,通过把不同物理算子抽象为迭代器。每一个算子只关注其内部逻辑,各个算子之间的耦合性降低,从而比较容易写出一个逻辑正确的执行引擎。
IMCI执行引擎中,每个Operator使用迭代器函数来访问数据。不同的是,每次调用迭代器时会返回一批数据,而不是一行。可以认为是一个支持batch处理的火山模型。
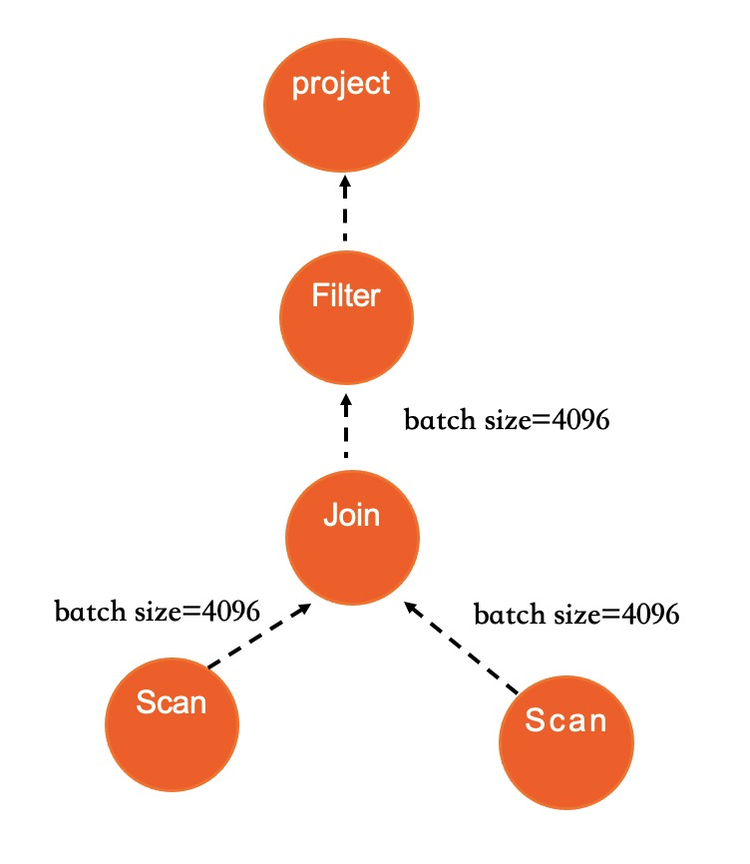
串行执行受限于单核计算效率、访存延时和IO延迟等。而IMCI执行器在几个关键物理算子(Scan/Join/Agg等)上均支持并行执行。除物理算子需要支持并行外,IMCI的优化器需要生成并行执行计划。优化器在确定一个表的访问方式时,会根据需要访问的数据量来决定是否启用并行执行。如果确定启用并行执行,则会参考一系列状态数据决定并行度,包括当前系统可用的CPU、Memory、IO资源、目前已经调度和在排队的任务信息、统计信息、query 的复杂程度以及用户可配置的参数等。根据这些数据计算出一个推荐的DOP值给算子, 而算子内部会使用相同的DOP。同时DOP也支持用户使用Hint的方式自行设定。
 向量化执行解决了单核执行效率低的问题,而并行执行突破了单核的计算瓶颈。二者结合使用使得IMCI执行速度相比传统MySQL行式执行有了数量级的提升。
向量化执行解决了单核执行效率低的问题,而并行执行突破了单核的计算瓶颈。二者结合使用使得IMCI执行速度相比传统MySQL行式执行有了数量级的提升。
SIMD向量化计算加速
AP型场景,SQL中经常会包含很多涉及到一个或者多个值、运算符、函数组成的计算过程,都属于表达式计算的范畴。表达式的求值是一个计算密集型的任务。因此,表达式的计算效率是影响整体性能的一个关键因素。
传统MySQL表达式计算体系,是以一行为单位的逐行运算,一般称其为迭代器模型实现。由于迭代器对整张表进行了抽象,整个表达式实现为一个树形结构,其实现代码易于理解,整个处理过程非常清晰。
这种抽象同时会带来性能上的损耗。在迭代器进行迭代的过程中,每获取一行数据都会引发多层的函数调用。同时逐行地获取数据会带来过多的 I/O,对缓存也不友好。MySQL采用树形迭代器模型,其受限于存储引擎访问方法,导致其很难对复杂的逻辑计算进行优化。
在列存格式下,由于每一列的数据都单独顺序存储,涉及到某一个特定列上的表达式计算过程都可以批量进行。对每一个计算表达式,其输入和输出都以Batch为单位,在Batch处理模式下,计算过程可以使用SIMD指令进行加速。即表达式系统有两项关键优化:
充分利用列式存储的优势,使用分批处理模型代替迭代器模型,使用SIMD指令重写大部分常用数据类型的表达式。例如,所有数字类型(int、decimal、double)的基本数学运算(+-*/abs),全部使用对应的SIMD指令。在AVX512指令集的加持下,单核运算性能获得数倍提升。
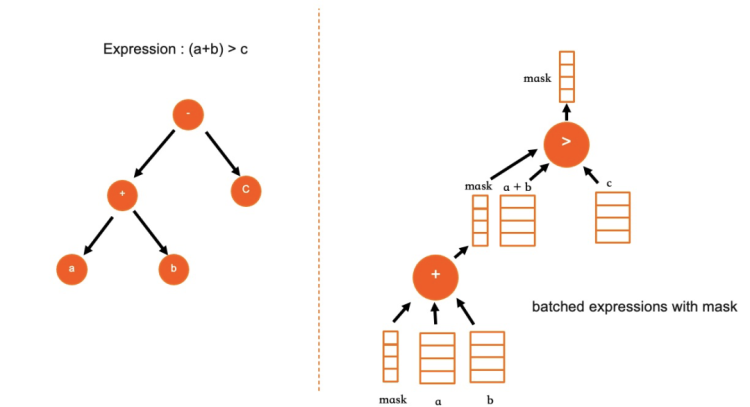
采用了与PostgreSQL类似的表达式实现方法。在SQL编译及优化阶段,IMCI的表达式以一个树形结构来存储,在执行前对该表达式树进行后序遍历,将其转换为一维数组来存储。在后续计算时,只需要遍历该一维数组即可。由于消除了树形迭代器模型中的递归过程,计算效率会更高。同时,该方法在计算过程中将数据和计算过程分离,适合并行计算。
支持行列混合存储的存储引擎
事务型应用和分析型应用对存储引擎有截然不同的要求。前者要求索引可以精确定位到每一行,并支持高效的增删改。而后者则需要支持高效批量扫描处理。这两个场景对存储引擎的设计要求完全不同,有时甚至矛盾。
因此设计一个一体化的存储引擎能同时服务OLTP型和OLAP型负载非常具有挑战性。目前市场上HTAP存储引擎做的比较好的只有有几十年研发经验的大公司,如Oracle(In-Memory Column Store)、SQL Server(In Memory Column index)、DB2(BLU)等。TiDB等只能通过将多副本集群中的单个副本调整为列存来支持HTAP需求。
一体化的HTAP存储引擎一般使用行列混合的存储方案。即引擎中同时存在行存和列存,行存服务于TP,列存服务于AP。相比于独立部署OLTP数据库和OLAP数据库来满足业务需求,HTAP引擎具有以下优势:
行存数据和列存数据具有实时一致性,能满足很多苛刻的业务需求,所有数据写入即可见于分析型查询。
成本低。用户可以指定一张表中的哪些列,甚至哪个范围的存储为列存格式。全量数据继续以行存存储。
管理运维方便。用户无需关注数据是否在两套系统之间同步及数据一致性问题。
PolarDB采用了和Oracle、SQL Server等商用数据库类似的行列混合存储技术,称之为In-Memory Column Index。
建表时可以指定部分表或者列为列存格式,或者对已有的表使用Alter table语句为其增加列存属性。分析型查询会自动使用列存格式来进行查询加速。
列存数据默认以压缩格式存储在磁盘,并可以使用In-Memory Column-Store Area做缓存加速查询,传统的行格式依然保存在BufferPool中供OLTP负载使用。
所有事务的增删改操作都会实时反应在列存存储上,保证事务级别的数据一致性。
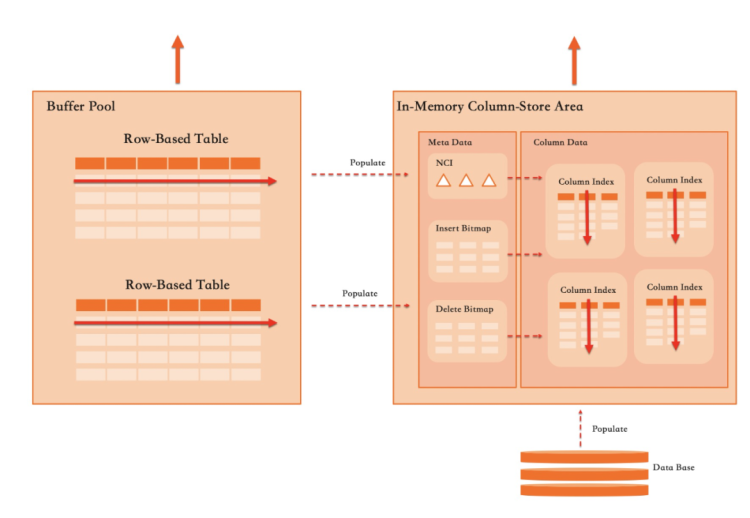
实现行列混合存储引擎技术上非常困难,但在InnoDB这样一个成熟的面向OLTP负载优化的存储引擎中增加列存支持,又面临不同的情况:
满足OLTP业务需求为第一优先级,因此增加列存不能对TP性能影响太大。这就要求维护列存必须足够轻量,必要时需要降低AP的性能提升TP的性能。
列存设计无需考虑事务并发对数据的修改以及数据unique check等问题,这些问题在行存系统中已经被解决,而这些问题对ClickHouse等单独的列存引擎难以处理。
由于行存系统的存在,列存系统出现任何问题都可以切换回行存系统。
上述条件可谓有利有弊,这也影响了对PolarDB整个行列混合存储的方案设计,表现为以下几个方面。
Index列存
基于MySQL插件式的存储引擎框架架构,增加列存最简单方案为实现一个单独的存储引擎。例如,Inforbright以及MarinaDB的ColumnStore。而PolarDB采用了将列存实现为InnoDB的二级索引的方案,主要基于如下几点考量:
InnoDB原生支持多索引,Insert、Update和Delete操作都会以行粒度apply到Primary Index和所有的Secondary Index上。将列存实现为一个二级索引。
在数据编码格式上,二级索引的列存可以和其他行存索引使用完全一样的格式,直接拷贝即可。不需要考虑charset和collation等信息。
二级索引操作非常灵活,可以在建表时指定索引所包含的列,也可以后续通过DDL语句对一个二级索引中包含的列进行增加或者删除操作。例如,用户可以将需要分析的INT、FLOAT和DOUBLE列加入列索引。而对于只需要点查但又占用大量空间的TEXT和BLOB字段,则可以保留在行存中。
崩溃恢复过程可以复用InnoDB的Redo事务日志模块,与现有实现无缝兼容。同时也支持PolarDB的物理复制过程,支持在独立RO节点或者Standby节点上生成列存索引。
同时二级索引与主表有一样的生命周期,方便管理。
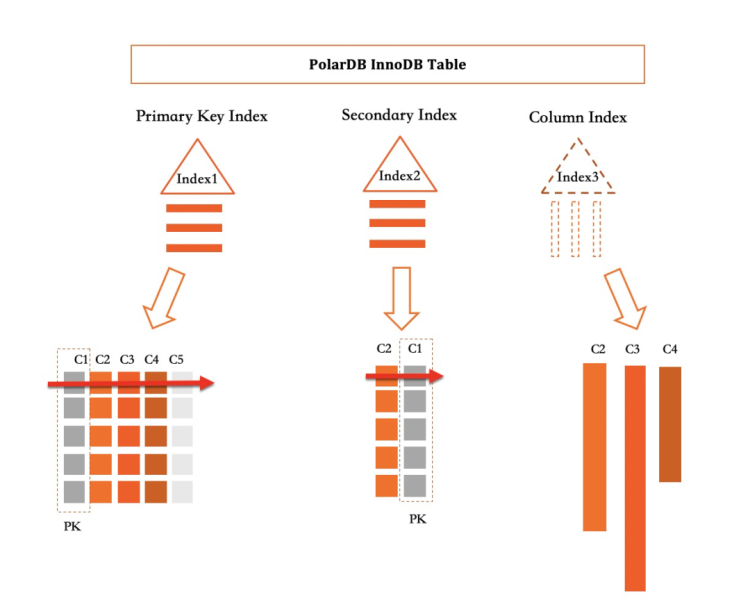 如上图所示,在PolarDB中,所有Primary Index和Secondary Index都实现为一个B+Tree。而列索引定义为一个Index,但其是一个虚拟索引,用于捕获对该索引覆盖列的增删改操作。
如上图所示,在PolarDB中,所有Primary Index和Secondary Index都实现为一个B+Tree。而列索引定义为一个Index,但其是一个虚拟索引,用于捕获对该索引覆盖列的增删改操作。主表(Primary Index)包含(C1、C2、C3、C4、C5)5列数据,Secondary Index索引包含(C2、C1)两列数据,在普通二级索引中,C2与C1编码为一行,并保存在B+tree中。而其中的列存索引包含(C2、C3、C4)三列数据。在实际物理存储时,会对三列进行拆分独立存储,每一列都会按写入顺序转成列存格式。
列存实现为二级索引的另一个优点为:执行器的工程实现非常简单,在MySQL中已经存在覆盖索引的概念,即查询所需要的列均在一个二级索引中存储,则这个二级索引中的数据均满足查询需求,使用二级索引相对于使用Primary Index可以极大减少读取的数据量,进而提升查询性能。当一个查询所需要的列都被列索引覆盖时,借助列存的加速作用,可以数十倍甚至数百倍的提升查询性能。
列存数据组织
Column Index中的每一列,其存储都使用了无序且追加写的格式。结合删除标记及后台异步compaction,实现空间回收。其具体实现关键点有:
列索引中,记录按照RowGroup进行组织,每个RowGroup中不同的列会各自打包成DataPack。
每个RowGroup都采用追加写格式,每个列的DataPack也采用追加写格式。对于一个列索引,只有Active RowGroup负责接受新的写入。当该RowGroup写满后即冻结,其所有的Datapack会转为压缩格式保存到磁盘,同时记录每个数据块的统计信息。
列存RowGroup中每新写入一行,会分配一个RowID定位。属于一行的所有列都可以使用该RowID计算定位,同时系统维护PK到RowID的映射索引,以支持后续的删除和修改操作。
更新操作,首先根据RowID计算出其原始位置并设置删除标记,然后在ActiveRowGroup中写入新的数据版本。
当RowGroup中的无效记录超过一定阈值时,会触发后台异步compaction操作。其作用一方面是为了回收空间,另一方面可以让有效的数据存储更加紧凑,提升分析型查询单的效率。
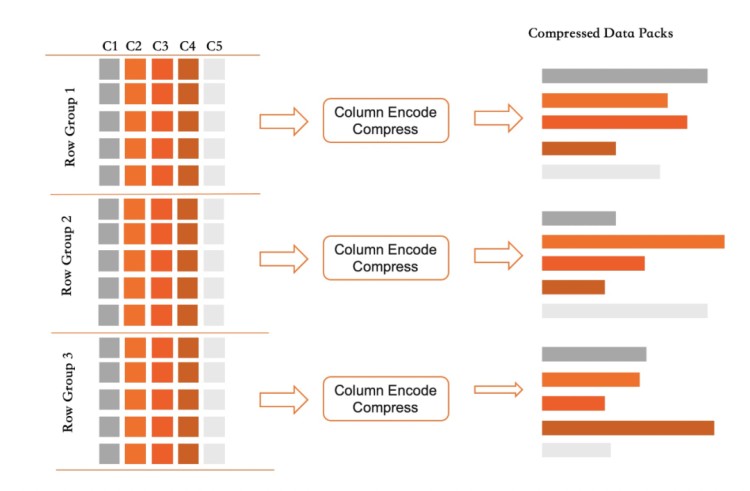
采用列存数据组织方式,一方面满足了分析型查询按列进行批量扫描过滤的要求。另一方面,对于TP型事务操作影响非常小,写入操作只需要按列追加写入内存即可。删除操作只需要设置一个删除标记位。而更新操作则是删除标记附加追加写。列存支持事务级别更新的同时,几乎不影响OLTP的性能。
全量及增量行转列
以下两种情况,会涉及行转列操作。
使用DDL语句对部分列创建列索引,此时需要扫描全表数据以创建列索引。
在实际操作过程中,对于涉及到的列执行行转列操作。
涉及全表行转列时,使用并行扫描的方式对InnoDB的Primary Key进行扫描,并依次将所有涉及到的列转换为列存形式。这种操作的速度非常快,其基本只受限于服务器可用的IO吞吐速度和可用CPU资源。该操作是一个online-DDL过程,不会阻塞在线业务的运行。
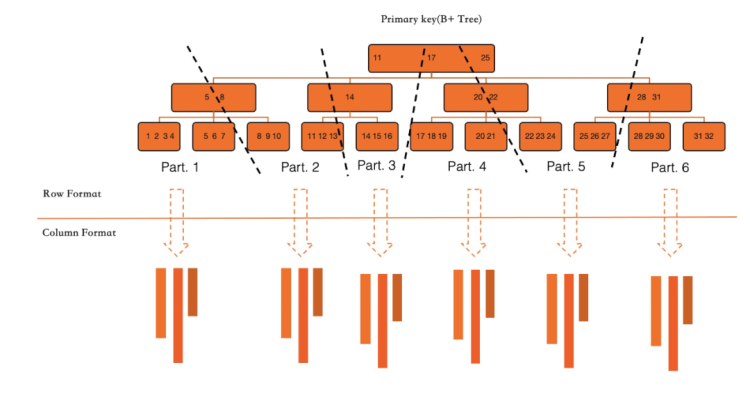
在一张表上建立列索引之后,所有的更新事务将会同步更新行存和列存数据,以保证二者事务的一致性。下图演示了在IMCI功能关闭和开启之间的差异性。
关闭IMCI功能时,事务对所有行的更新操作都会先加锁,然后再对数据页进行修改。在事务提交之前会对所有加锁的记录一次性放锁。
开启IMCI功能时,事务系统会创建一个列存更新缓存。在所有数据页被修改的同时,会记录所涉及到的列存的修改操作,在事务提交结束前,该更新缓存会应用到列存系统。
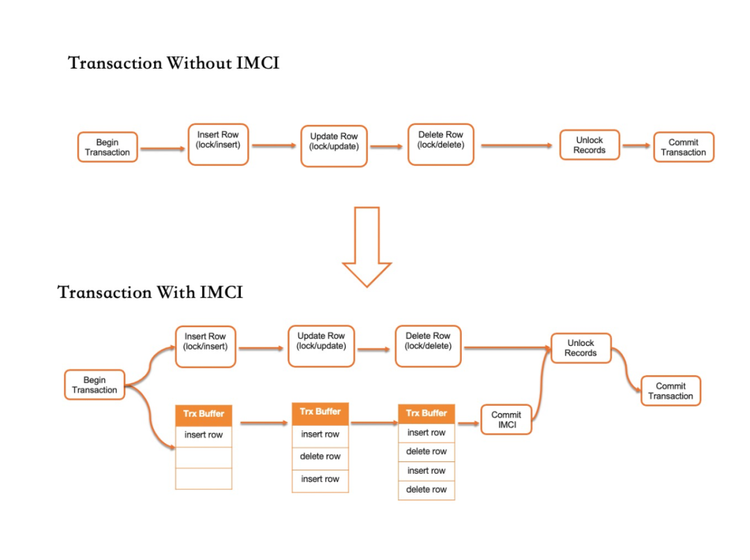
在此实现下,列存存储提供了与行存一样的事务隔离级别。对于每一个写操作,RowGroup中的每一行都会记录修改该行的事务编号。而对于每个标记,删除操作也会记录该动作的事务编号。借助写事务编号和删除事务编号,AP型查询可以使用非常轻量级的方式,来获得一个全局一致性的快照。
列索引粗糙索引
由列存格式可以看出,IMCI中所有的Datapack都采用无序且追加写的方式。因此,无法像InnoDB的普通有序索引那样,可以精准的过滤掉不符合要求的数据。在IMCI中,借助统计信息来进行数据块过滤以达到降低数据访问单价的目的。
在每个Active Datapack终结写入时,会预先进行计算,并生成Datapack所包含数据的最小值、最大值、数值的总和、空值的个数、记录总条数等信息。所有这些信息会维护在DataPacks Meta元信息区域并常驻内存。由于冻结的Datapack中存在数据的删除操作,因此,统计信息的更新维护会在后台完成。
对于查询请求,会根据查询条件将Datapacks分为相关、不相关、可能相关三大类,从而减少实际的数据块访问量。而对于一些聚合查询操作,如
count和sum等,可以通过预先计算好的统计值进行简单的运算得出,且这些数据块不需要解压。
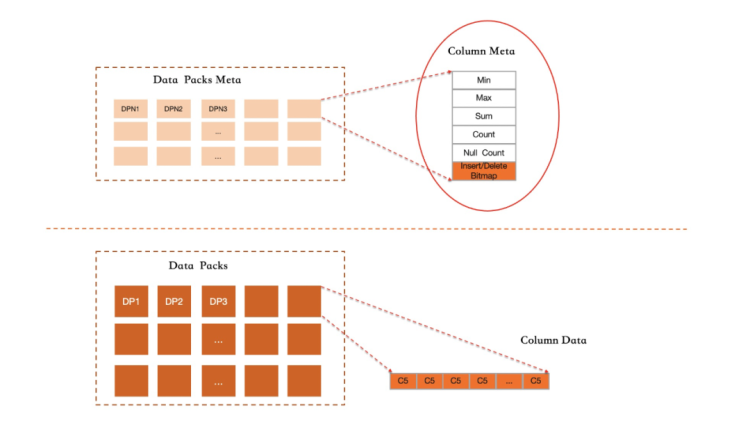 采用基于统计信息的粗糙索引方案,对于一些需要精准定位部分数据的查询并不友好。但是,在一个行列混合存储引擎中,列索引只需要辅助加速那些涉及到大量数据扫描的查询,这种场景下,使用列索引具有显著的优势。而对于那些只访问少量数据的SQL,优化器会基于代价模型计算得出一个基于行存的成本更低的方案。
采用基于统计信息的粗糙索引方案,对于一些需要精准定位部分数据的查询并不友好。但是,在一个行列混合存储引擎中,列索引只需要辅助加速那些涉及到大量数据扫描的查询,这种场景下,使用列索引具有显著的优势。而对于那些只访问少量数据的SQL,优化器会基于代价模型计算得出一个基于行存的成本更低的方案。行列混合存储下的TP和AP资源隔离
PolarDB行列混合存储可以应用于实例中同时存在AP型查询和TP型查询的场景。但很多业务有很高的OLTP型负载,而突发性的OLAP负载可能干扰到TP型业务的响应时延。因此负载隔离在HTAP数据库中是一个必要的功能。借助PolarDB的一写多读架构,可以非常方便的对AP型负载和TP型负载进行隔离。基于PolarDB技术架构,有以下三种部署方式:
第一种方式,在RW节点开启行列混合存储。这种部署模式可以支持轻量级的AP查询,在主要负载为TP且AP型请求比较少时,可以采用此部署模式。或使用PolarDB进行报表查询,但报表查询仅适用于数据来自批量数据导入的场景。
第二种方式,RW节点支持OLTP型负载,并启动AP型RO节点开启行列混合存储。这种部署模式下CPU资源可以实现100%隔离,同时该AP型RO节点上的内存可以100%分配给列存存储和执行器。但是,由于使用相同的共享存储,在IO上会相互影响。
第三种方式,RW节点和RO节点同时支持OLTP型负载,在单独的Standby节点开启行列混合存储以支持AP型查询。由于Standby使用独立的共享存储集群,这种方案在第二种方案支持CPU和内存资源隔离的基础上,还可以实现IO资源的隔离。
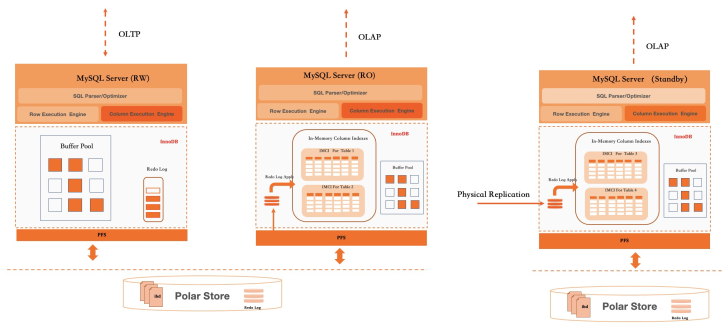
除上述部署架构不同,但可以支持资源隔离之外。PolarDB内部对于一些需要使用并行执行的大查询支持动态并行度调整(Auto DOP),这个机制会综合考虑当前系统的负载以及可用的CPU和内存资源,限制查询所用资源,以避免查询消耗的资源太多,影响系统处理其他请求。
PolarDB IMCI的OLAP性能
为了验证IMCI的技术效果,对PolarDB MySQL IMCI进行了TPC-H场景测试。同时在相同场景下,将其与原生MySQL的行存执行引擎以及当前OLAP引擎单机性能最强的ClickHouse进行了对比。测试参数简要介绍如下:
数据量TPC-H 100 GB,22条Query语句。
CPU Intel(R) Xeon(R) CPU E5-2682 2 socket
内存512 GB,启动后数据均输入内存。
PolarDB IMCI VS MySQL串行
TPC-H场景下,22条Query语句。IMCI处理延时相比原生MySQL有数十倍到数百倍不等的加速效果。其中Q6的效果将近400倍。体现出了IMCI的巨大优势。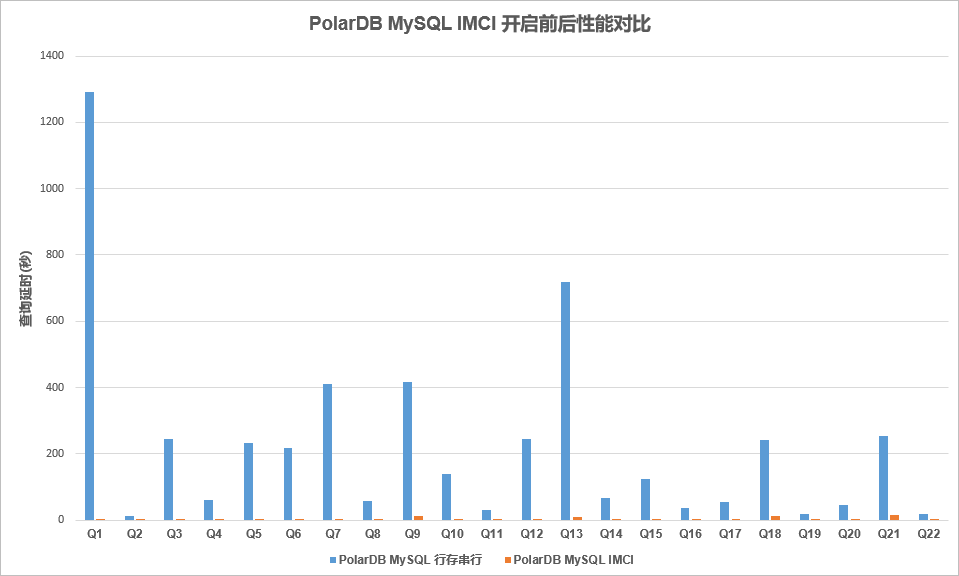
PolarDB IMCI VS ClickHouse
对比当前社区最火热的分析型数据库ClickHouse时,IMCI在TPC-H场景下的性能也与其基本位于同一水平。在处理部分SQL的处理延时时各有优劣。用户完全可以使用IMCI替代ClickHouse,同时其数据管理也更加方便。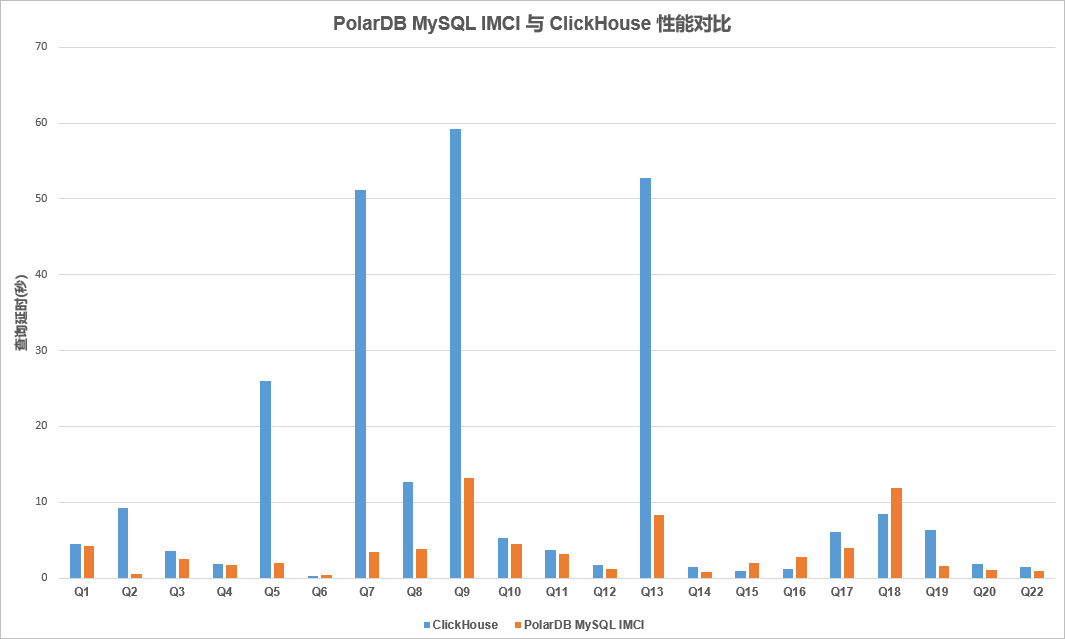
FutureWork
IMCI是PolarDB迈向数据分析市场的第一步,它的迭代脚步不会停止,接下来我们会在如下几个方向进一步研究和探索,给客户带来更好的使用体验:
自动化的索引推荐系统。目前列存的创建和删除需要用户手动指定,增加了DBA的工作量,研究方向上即将引入自动化推荐技术,根据用户的SQL请求,自动创建列存索引,降低维护工作量。
单独的列存表以及OSS存储。目前IMCI只是一个索引,对于纯分析型场景,删除行存可以更进一步的降低存储大小。而IMCI执行器支持读写OSS对象存储,可以将存储成本降到最低。
行列混合执行。即SQL执行计划部分片段在行存执行,部分片段在列存执行。以获得最大化的执行加速效果。