
支持新建多种类型的数据源,为使用数据资源平台做数据支撑。本文介绍如何新建云计算资源。
前提条件
已创建工作组,具体操作,请参见新建工作组。
背景信息
当前支持的云计算资源类型有RDS MySQL、AnalyticDB MySQL、AnalyticDB MySQL 2.0、AnalyticDB PostgreSQL、Blink、DM、DataHub、Flink、GaussDB、Hive、Hologres、Kafka、MaxCompute、Oracle、PostgreSQL、Table Store等多种类型。
操作步骤
登录数据资源平台控制台。
在页面右上角,单击
 图标,选择系统设置。
图标,选择系统设置。在左侧导航栏,单击工作组管理。
在工作组管理页面,选择目标工作组,单击操作列中云计算资源。
在云计算资源页面,单击新建云计算资源。
在新建云计算资源对话框中,配置云计算资源各项参数。
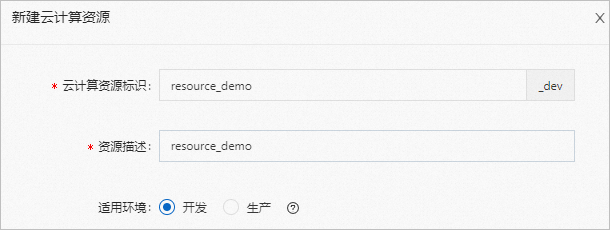
配置云计算资源基础信息。
参数
说明
云计算资源标识
自定义计算资源的标识。
资源描述
对云计算资源的使用场景等特性进行自定义描述。
适用环境
(条件必选)当工作组为专业模式时,可设置云计算资源的使用环境,分为开发和生产环境,对生产环境的数据读写权限、任务上线发布进行严格权限控制。
云计算资源创建后,云计算资源标识自动添加后缀:_dev(开发)、_prod(生产)。
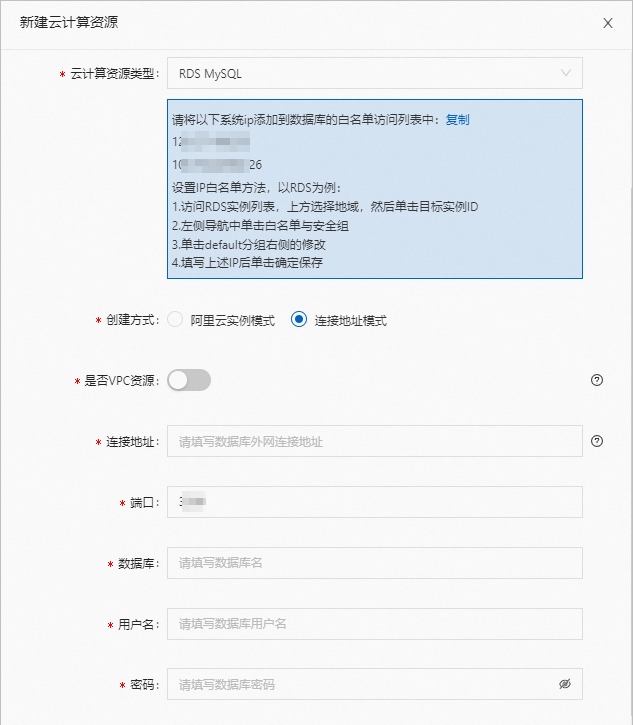
选择云计算资源类型,配置资源连接信息,此处以RDS MySQL为例。
参数
说明
云计算资源类型
单击下拉列表选择云计算资源类型,此处以RDS MySQL为例。
说明配置云计算资源时,请参考界面提示信息,将系统IP添加到数据库的白名单访问列表中。
创建方式
支持阿里云实例模式和连接地址模式两种创建方式,此处以连接地址模式为例。
阿里云实例模式:授权后支持通过接口获取链接信息,当实例ID通过下拉选择时,自动填充VPC实例ID、实例端口、VPC ID。访问资源的实例信息时,需通过服务关联角色功能获取访问权限,详情请参见服务关联角色。
说明支持阿里云实例模式的资源类型:RDS MySQL、SQLServer、PostgreSQL、PolarDB、AnalyticDB for PostgreSQL。
连接地址模式:选择是否为VPC资源,通过手动配置连接地址、端口、数据库等信息。
是否为VPC资源
当您的网络类型为专有网络(VPC)时,可开启使用。
连接地址
RDS MySQL实例的外网地址。
您可以通过以下步骤进行获取:
登录RDS管理控制台。
单击左侧导航栏实例列表,在页面左上角,选择实例所在地域。
在实例列表中,筛选数据库类型为MySQL,找到目标实例,单击实例ID/名称。
说明RDS实例需先申请外网地址。
端口
RDS MySQL实例的外网端口。
数据库
RDS MySQL的数据库名称。
可登录RDS管理控制台,单击左侧导航栏的数据库管理进行查看。
用户名
登录数据库的账号。
可登录RDS管理控制台,单击左侧导航栏的账号管理进行查看。
密码
登录数据库的密码。
如果忘记密码,可登录RDS管理控制台,单击左侧导航栏的账号管理进行重置密码操作。
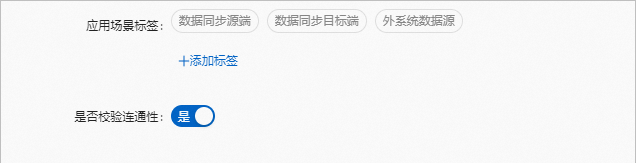
设置应用场景标签和校验连通性。
参数
说明
应用场景标签
选择云计算资源的应用场景标签,可多选。
单击添加标签,可自定义应用场景标签。
是否校验连通性
可选项,用于新建资源的连通性测试,默认选是。
配置资源组连通性。
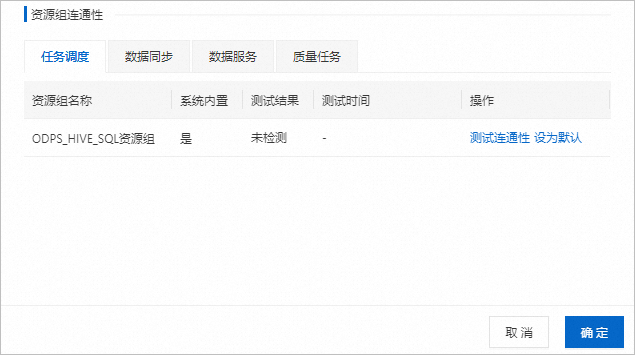
配置完成后,单击确定。
在云计算资源列表页面查看新建的云计算资源。
相关操作
操作 | 说明 |
编辑云计算资源 | 在云计算资源页面,单击目标云计算资源操作列的编辑,可对云计算资源的连接信息、应用场景标签等进行修改。 重要 编辑云计算资源的AK、用户名、密码可能导致该云计算资源中存储的已授权物理表无法正常访问,请谨慎操作。 |
删除云计算资源 | 在云计算资源页面,单击目标云计算资源操作列的删除,可删除当前云计算资源。 重要 删除云计算资源将造成数据无法访问,导致该云计算资源中存储的已授权物理表、标签、数据服务API等无法使用或加工任务异常,请谨慎操作。 |