本文主要介绍智能语音交互的语音识别输入格式说明,以及输入语音格式不符合要求时常见问题以及方法,您可以优先在文本档获取对应解决方案。
语音识别各服务支持的语音输入格式
语音识别服务 | 语音输入格式说明 |
一句话识别 |
|
实时语音识别 |
|
录音文件识别 |
|
录音文件识别闲时版本 |
|
录音文件识别极速版本 |
|
如何查看语音格式
常见语音格式名词释义,请参见基本概念。
采样率:8000 Hz(8K Hz)、16000 Hz (16K Hz),即每秒8000个或16000个采样点。
采样位数:16 bit,即每个采样点的音频信息用16 bit(2个字节)保存。
声道:Mono单声道;Stereo立体声。
语音时长与文件大小转换:
语音文件Size大小(单位MiB)=
(采样率×采样位数×声道数×语音时长(单位s))/(8*1024*1024)=16000(Hz)*16(bit)*1(声道)*60(s)/(8*1024*1024)=1.83 MiB(近似值)
Linux操作系统下查看语音格式:
使用如下命令查看。
file input.wav预期结果:
8000 Hz采样率、16 bit采样位数、单声道(mono)的无压缩WAV格式如下图所示:

16000 Hz采样率、16 bit采样位数、单声道(mono)的无压缩WAV格式如下图所示:

Windows操作系统下查看语音格式:
在Windows操作系统中,您可以选中目标语音,单击鼠标右键,选择属性,可以查看更多信息。
预期结果:
8000 Hz采样率、16 bit采样位数、单声道(mono)的无压缩WAV格式如下图所示:

16000 Hz采样率、16 bit采样位数、单声道(mono)的无压缩WAV格式如下图所示:

如何进行语音格式转换
若输入语音采样率、采样位数、声道、编码等不符合语音识别格式要求时会报错,测试语音可先进行语音格式转换。
Linux操作系统下转换语音格式:
使用如下常见的FFmpeg命令进行转换。更多操作,请参见下载FFmpeg。
#查询语音格式如采样率、声道、编码等
ffmpeg -i input.mp3
#将某个wav文件转化为8K、16bit、单声道的wav文件
ffmpeg -i input.wav -ar 8000 -ac 1 -acodec pcm_s16le -f s16le output.wav
#将某个wav文件转化为16K、16bit、单声道的wav文件
ffmpeg -i input.wav -ar 16000 -ac 1 -acodec pcm_s16le -f s16le output.wav
#将某个pcm文件转化为16K、16bit、单声道的wav文件
ffmpeg -i input.pcm -f s16le -ar 16000 -ac 1 -acodec pcm_s16le output.wav
#将某个wav文件转化为16K、16bit、单声道的pcm文件
ffmpeg -y -i input.wav -acodec pcm_s16le -f s16le -ac 1 -ar 16000 output.pcm
#将某个Mp3文件转换为转化为16K、16bit、单声道的wav文件
ffmpeg -y -i input.mp3 -acodec pcm_s16le -f s16le -ac 1 -ar 16000 output.wav
#将某个44.1KHz、16bit的wav文件转化为16K、16bit、单声道的wav文件
ffmpeg -y -f s16le -ar 44100 -ac 1 -i input.wav -acodec pcm_s16le -f s16le -ac 1 -ar 16000 output.wav
#将某个8K的alaw文件转化为8K、16bit、单声道的wav文件
ffmpeg -f alaw -ar 8000 -i input.wav -ar 8000 -ac 1 -acodec pcm_s16le -f s16le output.wav
#将某个8K的mulaw文件转化为8K、16bit、单声道的wav文件
ffmpeg -f mulaw -ar 8000 -i input.wav -ar 8000 -ac 1 -acodec pcm_s16le -f s16le output.wav
#将某个amr文件转化为16K、16bit、单声道的wav文件
ffmpeg -i input.wav -ar 16000 -ac 1 -acodec pcm_s16le -f s16le output.wavWindows操作系统下转换语音格式:
Windows系统下语音转换格式可使用转换工具,常见工具Adobe Audition、CoolEdit或其他在线、离线语音转换工具。
使用转换工具,优先打开语音,修改导出设置的格式后运行即可,以下是以输出16K数据为例。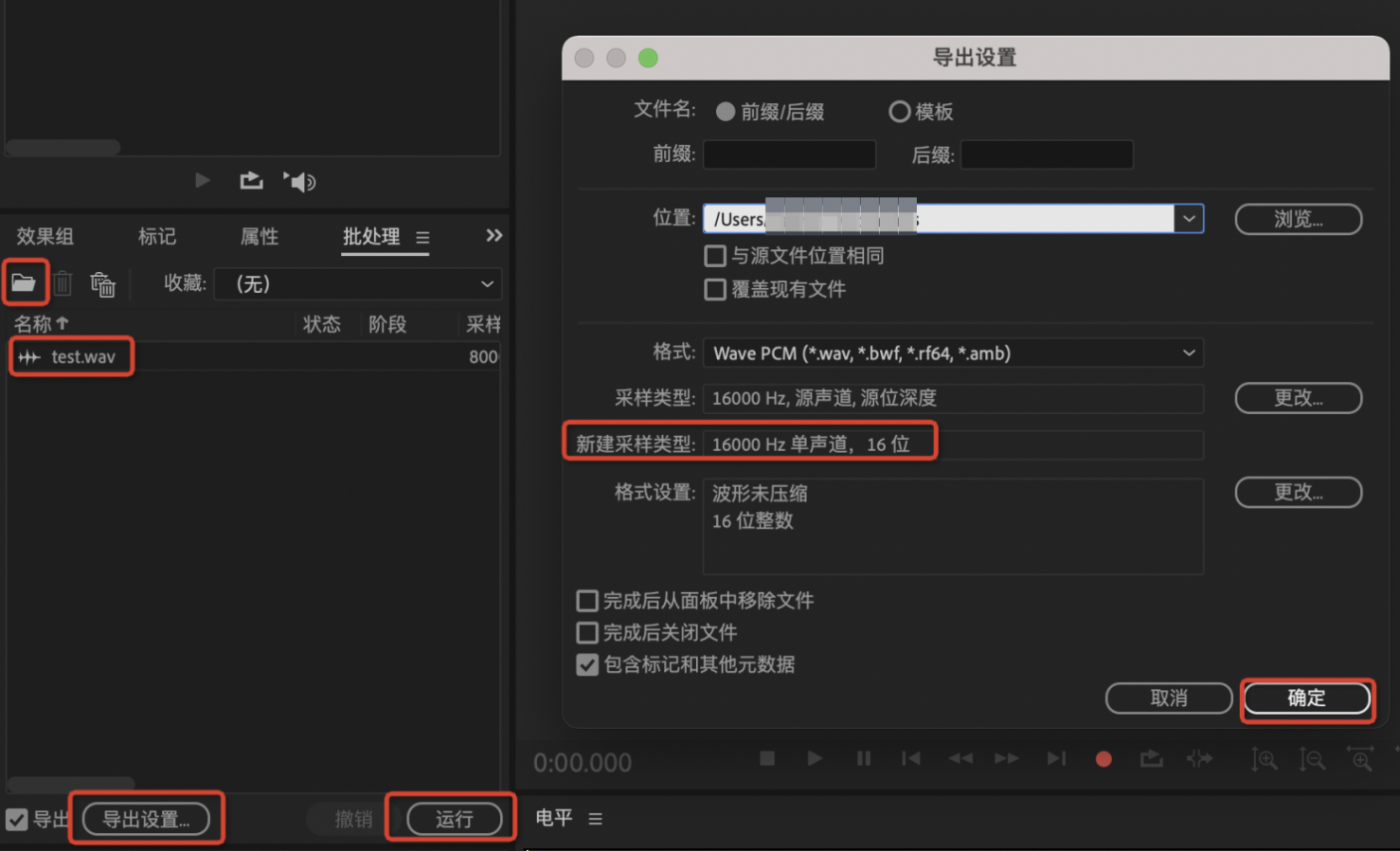
常见问题及解决方法
官网示例语音正常,换成自己待测试的语音就获取不到结果?
建议您检查待测试的语音格式是否符合语音识别输入格式要求。更多内容,请参见语音识别各服务支持的语音输入格式。
将待测试语音转换成8K或16K、16 bit采样位数、单声道(mono)无压缩的WAV文件。更多语音格式转换,请参见如何进行语音格式转换。
调用录音文件识别或录音文件识别闲时版报错status:41010101 ,message: UNSUPPORT_SAMPLE_RATE,怎么办?
建议优先检查控制台选择的模型采样率和您输入语音的采样率是否匹配。8K模型要输入8K的语音数据测试,16K模型要输入16K的语音数据进行测试。
在发送请求时增加采样率自适应参数:enable_sample_rate_adaptive=true。更多内容,请参见接口说明。
如果尚不能解决问题,您可以将语音格式进行转换,再进行测试。更多内容,请参见如何进行语音格式转换。
调用实时语音识别结果返回Null怎么回事?
根据实时语音识别产品介绍,请参见语音识别各服务支持的语音输入格式。实时语音识别主要用于语音流式输入的场景,仅支持8K或16K、16 bit采样位数、单声道(mono)无压缩的PCM或WAV文件。
如果您在使用已有的语音文件测试实时语音识别服务,需先将已有语音文件转换成实时语音识别的语音输入格式。更多内容,请参见如何进行语音格式转换。
输入Mp3语音文件调用一句话识别报错怎么办?
根据一句话产品介绍,参见语音识别各服务支持的语音输入格式。一句话产品不支持输入Mp3格式,建议您调用录音文件识别或者录音文件识别闲时版服务,且在发送请求时添加enable_sample_rate_adaptive=true参数。
调用一句话识别报错status:41010104,message:TOO_LONG_SPEECH 怎么办?
根据一句话产品介绍,参见语音识别各服务支持的语音输入格式。一句话产品仅支持60s以内的音频。如果您的输入语音超过60s,建议您调用实时语音识别、录音文件识别或录音文件识别闲时版服务。
控制台产品体验上传音频后无法识别怎么办?
建议您先将待测试语音转换成8K或16K、16 bit采样位数、单声道(mono)无压缩的WAV文件。更多关于语音格式转换内容,请参见如何进行语音格式转换。
调用录音文件识别或录音文件识别闲时版报错 status:41050103,message:AUDIO_DURATION_TOO_LONG,怎么办?
根据录音文件识别或录音文件识别闲时版服务产品介绍,服务支持的最大音频时长是12小时,当您提交的音频时长大于12小时会报此错误。您可以使用 ffmpeg 命令,将长音频切分成多个音频文件,分别识别。
ffmpeg工具下载地址:https://ffmpeg.en.lo4d.com/download
ffmpeg命令用法如下:
ffmpeg -i input_audio.wav -ss 00:10:00 -to 5:10:00 -c copy output_audio.wav
参数说明:
-i input_audio.wav:指定输入文件,即待处理的音频文件 input_audio.wav。
-ss 00:10:00:指定开始时间,从 00:10:00(即原始音频的第10分钟)开始处理。
-to 5:10:00:指定结束时间,处理到 5:10:00(即原始音频的第5小时10分钟)结束。
-c copy:指定编解码器选项。copy 表示直接复制音频数据,不做重新编码。
output_audio.wav:指定输出文件,即处理后的音频文件 output_audio.wav,音频时长5小时。
注意:如果是双声道音频且两个声道都需要识别,服务支持的最大音频时长是6小时。其他立体声音频以此类推。