
在服务器上成功安装日志服务采集器后,还需要设置机器组将服务器关联到日志服务指定资源中,并通过采集配置定义数据的采集规则。随后手动绑定采集配置到机器组中,将采集规则应用到服务器上。
什么是机器组
机器组是包含多台服务器的虚拟分组,属于日志服务Project中的资源,日志服务通过机器组管理服务器,服务器通过心跳与机器组关联。Project支持将一个采集配置应用到多个机器组,或将一个机器组绑定到多个采集配置。
日志服务提供以下两种机器组类型:
IP地址机器组
使用IP地址机器组时,需要在机器组中添加IP地址信息来与服务器关联。
-
该种方式创建与配置更简单。
-
当IP地址发生冲突或IP改变会导致心跳失败,影响数据采集。
用户自定义标识机器组(推荐使用)
通过在机器组中配置一个用户自定义的字符串作为识别标识,并在服务器上的标识文件中添加该字符串来进行关联。一台服务器的标识文件中可配置多个用户自定义标识,标识之间以换行符分隔。
-
配置流程相比IP地址机器组更复杂。但在VPC等自定义网络环境,IP地址冲突会导致采集失败。而用户自定义标识可避免此类情况发生。
-
可实现机器组的自动弹性伸缩。为新增的服务器配置相同的用户自定义标识,日志服务可自动识别并添加至机器组中。若不再需要采集服务器日志,直接删除服务器上配置的标识文件,机器组自动将该服务器移除。
-
通常业务系统由多个模块组成,各模块均可进行独立的水平扩展,即支持添加多台服务器。为实现高效的日志数据收集和分类,建议为各模块创建单独的机器组。如常见网站分为HTTP请求模块、逻辑模块和存储模块,其自定义标识可分别定义为
http_module、logic_module和store_module。
如何创建机器组
机器组与服务器之间建立心跳关联的前提是在服务器上成功安装采集器。建议您在安装采集器时一并创建机器组,详情可参考安装采集器或安装配置。
步骤一:配置用户标识(可选)
存在如下任一情况时,需要在服务器上配置用户标识,若ECS与日志服务同账号可跳过该步骤。用户标识的作用在于标识这台服务器有权限被该账号访问,并授权日志服务Project通过Logtail采集该服务器日志。
-
服务器类型不是ECS。
-
服务器类型是ECS,但是与日志服务不属于同一个账号。
-
使用阿里云账号(主账号)登录日志服务控制台。鼠标悬浮在右上角用户头像,然后在弹出的标签页中查看并复制账号ID。如果您使用RAM用户登录,请复制主账号ID。
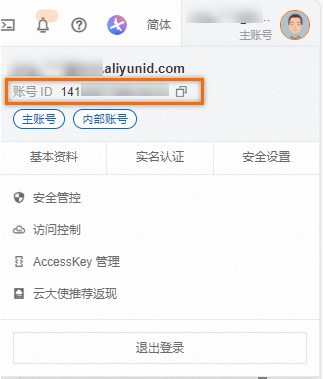
-
登录需要采集数据的服务器,通过以下方式配置用户标识,即配置阿里云账号ID文件。
Linux系统
-
在
/etc/ilogtail/users目录下,创建日志服务所属的阿里云账号ID文件。touch /etc/ilogtail/users/{阿里云账号ID}重要-
如果
/etc/ilogtail/users目录不存在,请手动创建目录。 -
新增、删除用户标识后,1分钟之内即可生效。
-
-
当您使用多个阿里云账号下的日志服务Project对同一台服务器进行日志采集时,您可以在同一台服务器上创建多个阿里云账号ID文件。例如:
touch /etc/ilogtail/users/{阿里云账号ID 1} touch /etc/ilogtail/users/{阿里云账号ID 2}
Windows系统
-
在
C:\LogtailData\users目录下,创建日志服务所属的阿里云账号ID文件。-
使用Windows PowerShell。
ni C:\LogtailData\users\{阿里云账号ID} -
使用命令提示符(cmd)。
type nul > C:\LogtailData\users\{阿里云账号ID}
-
-
当您使用多个阿里云账号下的日志服务Project对同一台服务器进行日志采集时,您可以在同一台服务器上创建多个阿里云账号ID文件。
容器环境
如果Logtail部署在阿里云Kubernetes集群中,且为Logtail-ds 1.7.3及以上版本,则您可以通过容器服务管理控制台设置用户自定义标识,即在组件管理页面,修改logtail-ds组件中的LogtailDSExternalUserDefinelDs参数。具体操作,请参见管理组件。
说明-
用户标识配置只需配置文件名,无需配置文件后缀。
-
一台服务器上可配置多个用户标识,Logtail容器中仅支持配置一个用户标识。
-
若您不再使用某个用户标识,直接删除服务器上阿里云账号ID文件即可。
-
步骤二:创建机器组
日志服务Project支持使用IP地址或用户自定义标识创建机器组。使用IP地址创建相对更简单,但使用用户自定义标识具有以下优势,推荐使用。
-
在VPC等自定义网络环境中,可能出现服务器IP地址冲突问题,导致Logtail采集失败。使用用户自定义标识可避免此类情况发生。
-
使用用户自定义标识可实现机器组的弹性伸缩。为新增的服务器配置相同的用户自定义标识,日志服务可自动识别,并将其添加至机器组中。如果不再需要采集服务器日志,直接删除在服务器上配置的用户自定义标识文件,日志服务可自动将该服务器从机器组中移除。
创建用户自定义标识机器组
通常情况下,业务系统由多个模块组成,每个模块都可以进行独立的水平扩展,即支持添加多台服务器。为了实现高效的日志数据收集和分类,建议为每个模块创建单独的机器组。用户需要在各个模块的服务器上配置自定义标识,以确保每个服务器能归属于正确的机器组。
例如常见网站分为前端HTTP请求处理模块、缓存模块、逻辑处理模块和存储模块,其自定义标识可以分别定义为http_module、cache_module、logic_module和store_module。
-
同一机器组中不允许同时存在Linux和Windows服务器,请勿在Linux和Windows服务器上配置相同的用户自定义标识。
-
一个服务器可配置多个用户自定义标识,标识之间以换行符分割。
-
配置用户自定义标识。
Linux环境
-
登录已安装Logtail的Linux服务器,使用以下命令配置用户自定义标识。
说明如果目录
/etc/ilogtail/不存在,请先手动创建该目录。echo "user-defined-1" > /etc/ilogtail/user_defined_id -
(可选)使用以下命令检查用户自定义标识是否写入成功。如果返回
user-defined-1,则表示写入成功。cat /etc/ilogtail/user_defined_id -
新增、删除、修改
user_defined_id文件后,默认情况下,1分钟内生效。如果需要立即生效,请执行以下命令重启Logtail。/etc/init.d/ilogtaild stop /etc/init.d/ilogtaild start
Windows环境
-
登录已安装Logtail的Windows服务器,在
C:\LogtailData目录下新建user_defined_id文件并写入user-defined-1,完成后保存。说明如果目录
C:\LogtailData不存在,请先手动创建该目录。 -
新增、删除、修改user_defined_id文件后,默认情况下,1分钟内生效。如需立即生效,请根据以下步骤重启Logtail。
-
选择。
-
在服务对话框中,选择对应的服务。
-
如果是0.x.x.x版本,选择LogtailWorker服务。
-
如果是1.0.0.0及以上版本,选择LogtailDaemon服务。
-
右键单击重新启动使配置生效。
-
容器环境
用户自定义标识配置在Logtail容器的环境变量
ALIYUN_LOGTAIL_USER_DEFINED_ID中,可通过docker inspect ${logtail_container_name} | grep ALIYUN_LOGTAIL_USER_DEFINED_ID命令查看。 -
-
登录日志服务控制台,在Project列表,单击打开目标Project。在左侧导航栏中,选择。在打开的机器组页面中,选择机器组右侧的
 > 创建机器组。
> 创建机器组。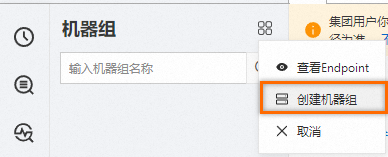
-
在弹出的创建机器组页面,填写以下信息,并单击确定。
参数
说明
名称
机器组名称,命名规则如下所示:
-
只能包括小写字母、数字、短划线(-)和下划线(_)。
-
必须以小写字母或者数字开头和结尾。
-
长度必须在 2~128 字符之间。
重要创建后,不支持修改机器组名称,请谨慎填写。
机器组标识
选择用户自定义标识。
机器组Topic
(可选)机器组Topic用于区分不同服务器产生的日志数据。
用户自定义标识
填入已配置的用户自定义标识,例如
user-defined-1。 -
创建IP地址机器组
-
登录日志服务控制台,在Project列表,单击打开目标Project。
-
左侧导航栏中,选择。在打开的机器组页面中,选择机器组右侧的
> 创建机器组。登录日志服务控制台,在机器组页面单击创建机器组。 -
在弹出的创建机器组页面,填写以下信息,并单击确定。
参数
说明
名称
机器组名称,命名规则如下所示:
-
只能包括小写字母、数字、短划线(-)和下划线(_)。
-
必须以小写字母或者数字开头和结尾。
-
长度必须在 2~128 字符之间。
重要创建后,不支持修改机器组名称,请谨慎填写。
机器组标识
选择IP地址。
机器组Topic
(可选)机器组Topic用于区分不同服务器产生的日志数据。
IP地址
填入Logtail自动获取的服务器IP:
在已安装Logtail的服务器,打开
app_info.json文件,并查看ip字段的值。-
app_info.json文件路径说明 -
Logtail自动获取的服务器IP地址记录在
app_info.json文件的ip字段中。[root@iZ2zexxx ]# cat /usr/local/ilogtail/app_info.json { "UUID" : "Cxxx", "compiler" : "GCC 9.3.1", "hostname" : "iZ2zeixxx", "instance_id" : "xxx_l_172.26.128.15_1730267282", "ip" : "172.26.128.15", "logtail_version" : "1.8.7", "os" : "Linux; 5.10.134-17.2.al8.x86_64; #1 SMP Fri Aug 9 15:49:42 CST 2024; x86_64", "update_time" : "2024-10-30 13:48:02" }
重要-
存在多台服务器时,请手动输入对应的IP地址,IP地址之间需使用换行符分隔。
-
同一机器组中不允许同时存在Linux和Windows服务器。请勿将Windows和Linux服务器IP添加到同一机器组中。
-
什么是采集配置
采集配置是定义如何采集、处理数据的核心规则。其目的是通过灵活配置,实现数据的高效采集、结构化解析、过滤加工等效果。采集配置通过绑定到机器组中来实现下发采集规则到服务器上,并在数据采集时使用服务器上资源进行处理。采集配置项主要包含三部分内容:
-
全局配置:包含采集配置的名称,日志主题(Topic)与Tag 等,利用Topic与Tag可对采集到的日志进行标记与分类。
-
输入配置:定义了待采集数据的类型(如文件输入,集群标准输出,SQL查询结果,HTTP输入等),以及不同类型数据的采集路径、来源等信息。
-
处理配置:通过处理插件的组合,来定义解析数据的规则,将待采集数据按需格式化(如过滤,脱敏,正则匹配,JSON解析等)。
配置项
说明
日志样例
待采集日志的样例,请务必使用实际场景的日志。日志样例可协助您配置日志处理相关参数,降低配置难度。支持添加多条样例,总长度不超过1500个字符。
[2023-10-01T10:30:01,000] [INFO] java.lang.Exception: exception happened at TestPrintStackTrace.f(TestPrintStackTrace.java:3) at TestPrintStackTrace.g(TestPrintStackTrace.java:7) at TestPrintStackTrace.main(TestPrintStackTrace.java:16)多行模式
多行日志的类型:多行日志是指每条日志分布在连续的多行中,需要从日志内容中区分出每一条日志。
自定义:通过行首正则表达式区分每一条日志。
多行JSON:每个JSON对象被展开为多行,例如:
{ "name": "John Doe", "age": 30, "address": { "city": "New York", "country": "USA" } }
切分失败处理方式:
Exception in thread "main" java.lang.NullPointerException at com.example.MyClass.methodA(MyClass.java:12) at com.example.MyClass.methodB(MyClass.java:34) at com.example.MyClass.main(MyClass.java:10)对于以上日志内容,如果日志服务切分失败:
丢弃:直接丢弃这段日志。
保留单行:将每行日志文本单独保留为一条日志,保留为一共四条日志。
处理模式
处理插件组合,包括原生插件和拓展插件。有关处理插件的更多信息,请参见处理插件概述。
重要处理插件的使用限制,请以控制台页面的提示为准。
2.0版本的Logtail:
原生处理插件可任意组合。
原生处理插件和扩展处理插件可同时使用,但扩展处理插件只能出现在所有的原生处理插件之后。
低于2.0版本的Logtail:
不支持同时添加原生插件和扩展插件。
原生插件仅可用于采集文本日志。使用原生插件时,须符合如下要求:
第一个处理插件必须为正则解析插件、分隔符模式解析插件、JSON解析插件、Nginx模式解析插件、Apache模式解析插件或IIS模式解析插件。
从第二个处理插件到最后一个处理插件,最多包括1个时间解析处理插件,1个过滤处理插件和多个脱敏处理插件。
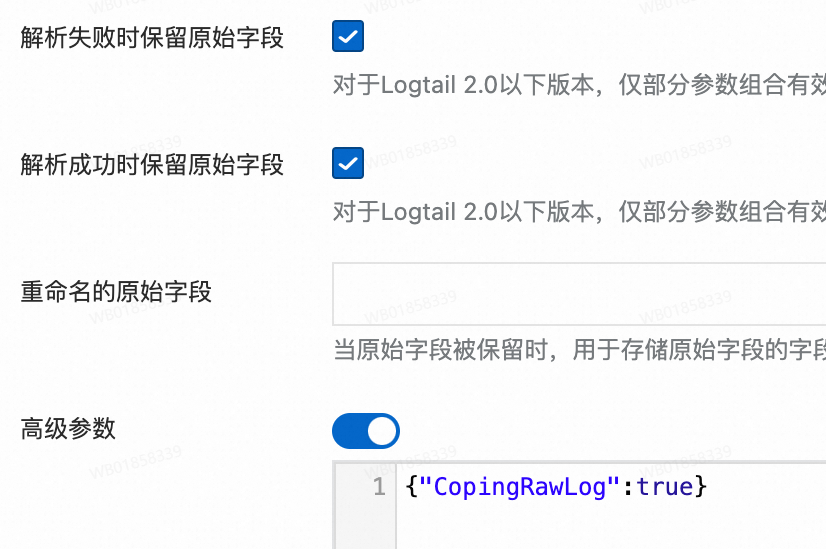
对于解析失败时保留原始字段和解析成功时保留原始字段参数,只有以下组合有效,其余组合无效。
只上传解析成功的日志:

解析成功时上传解析后的日志,解析失败时上传原始日志:

解析成功时不仅上传解析后的日志,并且追加原始日志字段,解析失败时上传原始日志。
例如,原始日志
"content": "{"request_method":"GET", "request_time":"200"}"解析成功,追加原始字段是在解析后日志的基础上再增加一个字段,字段名为重命名的原始字段(如果不填则默认为原始字段名),字段值为原始日志{"request_method":"GET", "request_time":"200"}。
如何创建采集配置
采集配置需要绑定到生效的机器组中才能下发到服务器上,因此建议您根据不同数据源类型,参考完整采集流程进行配置,详情可参考日志数据采集(Log)。
如何修改采集配置
为确保日志采集配置稳定可靠,修改操作必须在采集配置的原始创建位置进行。若跨途径修改(如配置由环境变量创建却在控制台调整),采集配置可能在Pod重建、组件更新等运维操作中被原始来源覆盖,引发日志格式异常、采集中断等风险。
以下是各创建方式对应的规范修改方法及关键注意事项:
-
SLS控制台/CLI/SDK创建:在SLS控制台/CLI/SDK直接修改采集配置。
-
容器服务控制台/业务容器环境变量创建:调整容器环境变量(如 aliyun_logs_*),参数详见采集ACK集群容器日志。不支持在SLS控制台修改。
-
环境变量创建采集配置是一种快速接入方式,仅支持基础采集路径配置,无法设置高级参数或处理插件,如需使用高级功能,建议:删除当前容器环境变量与已创建的采集配置 → 改用SLS控制台、SDK、CLI或CRD方式重新创建。
-
若采集配置通过环境变量方式创建,并曾经在SLS控制台补充过处理插件或高级参数,这些修改可能在Pod重建或组件更新等情况下被原始采集配置覆盖丢失,请尽快迁移。
-
-
CRD方式创建:直接编辑对应的CR资源(如 AliyunPipelineConfig),参数详见AliyunPipelineConfig参数说明。不支持在SLS控制台修改。
-
若采集配置通过CRD - AliyunPipelineConfig方式创建,并曾经在SLS控制台修改,所有改动均会在修改后30分钟内被还原,请检查当前采集配置是否符合预期。
-
若采集配置通过CRD - AliyunLogConfig方式创建,并曾经在SLS控制台修改,这些修改可能在Pod重建或组件更新等情况下被原始采集配置覆盖丢失,请尽快检查当前采集配置是否符合预期并更新CR,建议升级至AliyunPipelineConfig。
-
机器组与采集配置的关系
日志服务支持将一个LoongCollector采集配置应用到多个机器组,一个机器组也支持应用多个LoongCollector采集配置,采集配置仅与机器组绑定,机器组中服务器增减将自动应用或取消相应采集配置,从而实现了服务器与采集配置的解耦。不同系统类型的服务器不支持添加到同一个机器组中。

机器组与采集配置关联场景
采集怎么匹配多个目录
需求:例如需要同时采集/var/log/messages和/opt/app/logs/*.log到同一LogStore中。
解决方案:
-
在目标LogStore中创建两个采集配置,路径分别为
/var/log/messages与/opt/app/logs/*.log。 -
将这两个采集配置应用到同一个机器组中。
-
日志服务会将该机器组中所有服务器上路径为
/var/log/messages与/opt/app/logs/*.log的数据采集到目标LogStore中。
同服务器日志上传至多LogStore
需求:例如单台服务器上存在多目录下多类型日志,需要保存到不同LogStore中。
解决方案:
-
在不同LogStore中分别创建不同的采集配置。
需要注意:若多个配置采集同一个文件,需要在输入配置中,打开允许文件多次采集开关。详情参考日志多次采集。
-
将这些采集配置应用到同一个机器组中。
-
日志服务会根据不同的采集配置将该机器组中不同日志上传到不同LogStore中。
不同服务器上日志如何集中汇总
需求:例如多台服务器分散在不同机器组中,但存在某类日志需要汇总到同一LogStore保存。
解决方案:
-
在目标LogStore中创建一个采集配置。
-
将这个采集配置应用到多台服务器所在的多个机器组中。
-
日志服务会将多个机器组中服务器上的日志采集到目标LogStore中。
变更服务器上的采集规则
需求1:机器组绑定的采集配置所定义的规则不符合预期,需要修改为其他采集配置。
解决方案:
-
登录日志服务控制台,在Project列表,单击打开目标Project。在左侧导航栏中,选择。在打开的机器组页面中,选择需要修改的机器组后,在机器组配置页面单击修改。
-
在管理配置中查看左侧采集配置列表,勾选需要的采集配置后添加到右侧应用列表中。
需求2:新增服务器时需要应用已有的采集配置,或已有服务器不再需要继续采集。
解决方案:
-
登录日志服务控制台,在Project列表,单击打开目标Project。在左侧导航栏中,选择。在打开的机器组页面中,选择需要修改的机器组后,在机器组配置页面单击修改。
-
修改机器组覆盖的服务器数量,来应用或取消采集配置:
-
若是IP地址型机器组,在IP地址栏中增加或删除IP地址信息,多台服务器IP地址之间需使用换行符分隔。
IP值必须与服务器的/usr/local/ilogtail/app_info.json文件中
ip字段相同。 -
若是用户自定义标识型机器组,在新增的服务器上配置相同的用户自定义标识,日志服务可自动识别并添加至机器组中。若不再需要采集服务器日志,直接删除服务器上配置的标识文件,机器组自动将该服务器移除,实现自动弹性伸缩。
说明将服务器添加到机器组并不会自动安装LoongCollector,您需要先在新增服务器上安装LoongCollector。
-
相关参考
采集性能如何优化
-
调整启动参数:通过修改配置解决常见采集问题。
-
调整处理插件:通过写入处理器或数据加工进行数据处理,具体可参考处理插件、写入处理器、数据加工、消费处理器的对比。