Hologres是兼容PostgreSQL协议的一站式实时数仓引擎,支持海量数据实时写入、实时更新、实时分析,既支持PB级数据多维分析(OLAP)与即席分析(Ad Hoc),又支持高并发低延迟的在线数据服务(Serving)。本文为您介绍Hologres在数据写入、数据更新、点查场景的性能测试方法与结果。
测试方案介绍
测试场景
本文进行测试的场景如下。
数据写入场景:主要用于测试Hologres针对行存、列存、行列共存表进行数据写入的性能。
数据更新场景:主要用于测试Hologres针对行存、列存、行列共存表,在有主键的情况下进行数据更新的性能,包含全局更新与局部更新两个场景。
点查场景:主要用于测试Hologres针对行存、行列共存表进行主键过滤的点查性能。
测试工具
本文采用Hologres研发的开源测试工具holo-e2e-performance-tool进行测试,详情请参见holo-e2e-performance-tool(包含测试工具下载地址)。
holo-e2e-performance-tool测试工具具备如下优势:
测试过程简便:holo-e2e-performance-tool测试工具集成了建表、写入数据构造、性能测试等全部模块,无需提前准备测试数据。
参数配置灵活:仅需简单调整配置项,即可对表的列数、大小、行数等参数进行定制化设计,完成更加贴近实际业务场景的性能测试。
测试结果准确:测试数据的主键为递增的连续整数,因此只需对应调整参数配置项中的数据量,即可保证更新与点查场景的测试数据主键全部命中。
测试流程
使用holo-e2e-performance-tool进行数据写入、更新与点查场景测试的步骤如下:
进行数据写入测试,完成基本参数配置后测试一定行数下的写入性能。
保留写入场景的测试数据表,沿用写入场景的参数配置再次进行写入测试,即可实现数据更新场景的性能测试。
仍使用数据更新场景的测试数据表,配置需要查询的主键范围等参数,进行点查场景性能测试。
准备工作
基础环境准备
您需要准备测试所需的基础环境。具体内容如下:
为了减少可能对测试结果有影响的变量,建议每次使用新创建的实例进行测试,不要使用升降配的实例。
创建ECS实例。
登录阿里云,创建一个ECS实例,用于客户端测试。建议ECS规格如下:
实例规格:ecs.g6.4xlarge。
操作系统:Alibaba Cloud Linux 3.2104 LTS 64位。
存储:ESSD云盘。
ECS与Hologres实例需在相同地域,使用相同的VPC网络,并处于同一服务可用区。
说明上述规格非必须,您只需在测试过程中监测ECS实例的CPU与带宽,确保二者资源未被全部使用,即ECS实例资源没有成为测试瓶颈即可。
更多关于创建ECS的操作请参见创建实例。
创建Hologres实例。
本次测试使用了独享(按量付费)的实例,由于该实例仅用于测试使用,计算资源配置选择
64核256GB。您可以根据实际业务需求,选择计算资源配置。创建Hologres实例详细操作请参见购买Hologres。
创建测试数据库。
您需要登录创建的Hologres实例,创建一个数据库,详情请参见创建数据库。
测试工具准备
在ECS实例中安装JDK,建议使用JDK 11版本。具体操作,请参见手动部署OpenJDK。
下载测试工具holo-e2e-performance-tool。
将测试工具导入ECS实例,详情可参见使用Workbench上传或下载文件。
性能测试
数据写入场景
原理说明
写入模式说明:数据写入可以分为Fixed Copy和Insert两种模式。
Fixed Copy模式:通过COPY语句进行数据写入,同时通过Fixed Plan优化SQL执行,详情请参见Fixed Plan加速SQL执行。
Insert模式:通过INSERT语句进行数据写入,同时通过Fixed Plan优化SQL执行。
特殊配置说明:为便于兼容各测试场景、高效推进测试与验证,测试工具会在配置的表列数基础上,额外增加以下列:
主键列
id:作为表的主键和Distribution Key,在测试过程中从1开始逐条递增。时间列
ts:作为表的Segment Key,在测试过程中写入当前时间。
数据写入原理:在测试过程中,测试工具会将主键
id从1开始逐条递增写入数据。时间列写入当前时间。针对配置的其他TEXT列,写入目标长度的字符串加主键id。在达到目标时间或目标行数后停止写入,计算测试结果。
操作步骤
在ECS实例中创建测试配置文件。
使用如下命令创建名称为test_insert.conf的文件。
vim test_insert.conf在文件内输入
i后进入编辑模式,添加如下示例内容。说明如下示例以行存表为例,测试列存、行列共存表时请将
orientation参数值修改为column、row,column。# 连接配置 holoClient.jdbcUrl=jdbc:hologres://<ENDPOINT>:<PORT>/<DBNAME> holoClient.username=<AccessKey_ID> holoClient.password=<AccessKey_Secret> holoClient.writeThreadSize=100 # 写入配置 put.threadSize=8 put.testByTime=false put.rowNumber=200000000 put.testTime=600000 # 表配置 put.tableName=kv_test put.columnCount=20 put.columnSize=20 put.orientation=row # 其他配置 put.createTableBeforeRun=true put.deleteTableAfterDone=false put.vacuumTableBeforeRun=false参数说明如下。
模块
参数
描述
备注
连接配置
jdbcUrl
Hologres的JDBC连接串,格式为
jdbc:hologres://<ENDPOINT>:<PORT>/<DBNAME>。ENDPOINT需要填写Hologres实例的指定VPC域名,您可以进入Hologres管理控制台的实例详情页,从网络信息中获取域名。username
当前阿里云账号的AccessKey ID。
您可以单击AccessKey 管理,获取AccessKey ID。
password
当前阿里云账号的AccessKey Secret。
您可以单击AccessKey 管理,获取AccessKey Secret。
writeThreadSize
每个Holo Client启动的写入线程数。每个Holo Client写入线程会占用1个连接。仅INSERT模式生效。
Holo Client详情请参见Holo Client。
写入配置
threadSize
生成数据的线程数。
FIXED_COPY模式:每个线程会占用一个连接,总连接数即为线程数。
INSERT模式:默认共用一个Holo Client,总连接数为
writeThreadSize。
针对本文测试的64核实例规格,在FIXED_COPY模式下推荐设置线程数为8。您需要根据实例规格及数据特征适当调整该参数。
testByTime
按规定时间进行测试或按规定行数进行测试。
参数取值如下:
true:表示按规定时间进行测试。
false:表示按规定行数进行测试。
rowNumber
测试的目标行数,testByTime为false时生效。
不涉及
testTime
测试的目标时间,单位为毫秒,testByTime为true时生效。
不涉及
表配置
tableName
测试的目标表名。
不涉及
columnCount
表的列数。每列的数据类型均为TEXT。
不涉及
columnSize
表每列的字符长度。
不涉及
orientation
表的存储类型。
参数取值如下:
row:行存表。
column:列存表。
row,column:行列共存表。
其他配置
createTableBeforeRun
测试开始前是否创建表。
参数取值如下:
true:表示建表。
false:表示不建表。
如果设为true,测试工具默认会先执行删除同名表、再创建表的操作,请注意目标表名不与实例中其他表名相同。
deleteTableAfterDone
测试结束后是否删除表。
参数取值如下:
true:表示删除表。
false:表示不删除表。
如果在写入测试后,需要基于同一个表进行更新、点查等测试,则需要设为true。
vacuumTableBeforeRun
测试开始前是否执行Vacuum操作。
参数取值如下:
true:表示执行Vacuum操作。
false:表示不执行Vacuum操作。
执行Vacuum会强制触发Compaction操作。只影响INSERT模式下的数据更新场景测试,不影响FIXED_COPY模式。
按Esc键,输入
:wq并回车以保存并关闭文件。
数据写入测试。
执行如下语句进行测试。
# 使用Fixed copy模式进行数据写入测试 java -jar holo-e2e-performance-tool-1.0.0.jar test_insert.conf FIXED_COPY测试工具会默认将结果文件
result.csv保存在根目录下。其中数据写入与更新场景的模式参数包含两个取值,FIXED_COPY对应Fixed Copy模式,INSERT对应Insert模式。
获取测试结果。
使用如下命令获取测试结果。
cat result.csv测试结果文件
result.csv中包含如下字段。字段
描述
start
测试开始时间。
end
测试结束时间。
count
测试数据行数。
qps1
最后1分钟的平均QPS。
qps5
最后5分钟的平均QPS。
qps15
最后15分钟的平均QPS。
latencyMean
平均延迟。
INSERT、GET模式收集。
latencyP99
P99延迟。
INSERT、GET模式收集。
latencyP999
P999延迟。
INSERT、GET模式收集。
version
实例版本。
数据更新场景
原理说明
在测试过程中,测试工具会将主键
id从1开始逐条递增进行数据更新。针对时间列,更新为当前时间。针对配置的其他需要更新的TEXT列(可配置全局更新或局部更新),重新写入目标长度的字符串加主键id。在达到目标时间或目标行数后停止更新,计算测试结果。需要先进行数据写入,并设置deleteTableAfterDone为false,以确保表中已有数据,可以进行数据更新。
全局更新操作步骤
在ECS实例中创建测试配置文件。
使用如下命令创建名称为test_update.conf的文件。
vim test_update.conf在文件内输入
i后进入编辑模式,添加如下示例内容。说明如下示例以行存表为例,测试列存、行列共存表时请将
orientation参数值修改为column、row,column。相比于数据写入场景,仅需将
createTableBeforeRun参数值由true修改为false,其他参数均保持不变,即可开始数据更新场景的测试。
# 连接配置 holoClient.jdbcUrl=jdbc:hologres://<ENDPOINT>:<PORT>/<DBNAME> holoClient.username=<AccessKey_ID> holoClient.password=<AccessKey_Secret> holoClient.writeThreadSize=100 # 写入配置 put.threadSize=8 put.testByTime=false put.rowNumber=200000000 put.testTime=600000 # 表配置 put.tableName=kv_test put.columnCount=20 put.columnSize=20 put.orientation=row # 其他配置 put.createTableBeforeRun=false put.deleteTableAfterDone=false put.vacuumTableBeforeRun=false配置参数说明请参见数据写入场景的参数说明。
按Esc键,输入
:wq并回车以保存并关闭文件。
全局更新测试。
执行如下语句进行测试。
# 使用Fixed copy模式进行数据写入测试 java -jar holo-e2e-performance-tool-1.0.0.jar test_update.conf FIXED_COPY获取测试结果。
使用如下命令获取测试结果。
cat result.csv测试结果文件
result.csv中包含如下字段。字段
描述
start
测试开始时间。
end
测试结束时间。
count
测试数据行数。
qps1
最后1分钟的平均QPS。
qps5
最后5分钟的平均QPS。
qps15
最后15分钟的平均QPS。
latencyMean
平均延迟。
INSERT、GET模式收集。
latencyP99
P99延迟。
INSERT、GET模式收集。
latencyP999
P999延迟。
INSERT、GET模式收集。
version
实例版本。
局部更新操作步骤
在ECS实例中创建测试配置文件。
使用如下命令创建名称为test_update_part.conf的文件。
vim test_update_part.conf在文件内输入
i后进入编辑模式,添加如下内容。说明如下示例以行存表为例,测试列存、行列共存表时请将
orientation参数值修改为column、row,column。相比于全局更新场景,局部更新场景需要增加参数
writeColumnCount,该参数用于定义数据写入全部TEXT列中的几列。本文均将该参数设为表列数columnCount的50%。
# 连接配置 holoClient.jdbcUrl=jdbc:hologres://<ENDPOINT>:<PORT>/<DBNAME> holoClient.username=<AccessKey_ID> holoClient.password=<AccessKey_Secret> holoClient.writeThreadSize=100 # 写入配置 put.threadSize=8 put.testByTime=false put.rowNumber=200000000 put.testTime=600000 # 表配置 put.tableName=kv_test put.columnCount=20 put.columnSize=20 put.writeColumnCount=10 put.orientation=row # 其他配置 put.createTableBeforeRun=false put.deleteTableAfterDone=false put.vacuumTableBeforeRun=false参数说明请参见全局更新场景的参数说明。
按Esc键,输入
:wq并回车以保存并关闭文件。
局部更新场景测试。
执行如下命令进行测试。
# 使用Fixed copy模式进行数据写入测试 java -jar holo-e2e-performance-tool-1.0.0.jar test_update_part.conf FIXED_COPY获取测试结果。
使用如下命令获取测试结果。
cat result.csv测试结果文件
result.csv中包含如下字段。字段
描述
start
测试开始时间。
end
测试结束时间。
count
测试数据行数。
qps1
最后1分钟的平均QPS。
qps5
最后5分钟的平均QPS。
qps15
最后15分钟的平均QPS。
latencyMean
平均延迟。
INSERT、GET模式收集。
latencyP99
P99延迟。
INSERT、GET模式收集。
latencyP999
P999延迟。
INSERT、GET模式收集。
version
实例版本。
点查场景
原理说明
点查模式说明:
同步模式:点查接口是阻塞的,点查调用需要等待实际请求完成才返回。对于一个工作线程,每个点查请求都对应一个SQL从发起到完成,一个请求结束后才能进行下一个请求。同步模式适合latency敏感、吞吐需求相对不敏感的场景。
异步模式:点查接口是非阻塞的,点查调用无须等待实际请求完成,会立即返回。多个点查请求异步提交后,当客户端一个工作线程中判断满足攒批大小或者提交间隔后,会把多个点查请求通过攒批方式用一条SQL批量处理。异步模式适合吞吐需求高、latency需求相对较低的场景,如Flink消费实时数据进行高吞吐的维表关联等。
点查测试原理:在测试过程中,测试工具会在配置的主键范围内,随机生成目标
id进行同步或异步点查。在达到目标时间后停止点查测试,计算测试结果。
操作步骤
如果自动生成的数据无法满足您需要的点查业务场景,您可以自行写入业务数据,完成主键、分布列、分段列等表属性的创建,而后根据如下步骤进行点查性能测试。
自行创建的数据表中必须包含单列主键,主键数据类型为INT或BIGINT,同时需要注意主键的连续性。
在ECS实例中创建测试配置文件。
使用如下命令创建名称为test.conf的文件。
vim test.conf在文件内输入
i后进入编辑模式,添加如下内容。说明如下示例以行存表为例,测试行列共存表时请将
orientation参数值修改为row,column。# 连接配置 holoClient.jdbcUrl=jdbc:hologres://<ENDPOINT>:<PORT>/<DBNAME> holoClient.username=<AccessKey_ID> holoClient.password=<AccessKey_Secret> holoClient.readThreadSize=32 # 测试配置 get.threadSize=8 get.testTime=300000 get.tableName=kv_test get.async=true get.vacuumTableBeforeRun=true get.keyRangeParams=L1-200000000 # 表初始化配置(仅PREPARE_GET_DATA模式生效) prepareGetData.rowNumber=200000000 prepareGetData.orientation=row put.columnCount=20 put.columnSize=20配置参数说明如下。
模块
参数
描述
备注
连接配置
jdbcUrl
Hologres的JDBC连接串,格式为
jdbc:hologres://<ENDPOINT>:<PORT>/<DBNAME>。ENDPOINT需要填写Hologres实例的指定VPC域名,您可以进入Hologres管理控制台的实例详情页,从网络信息中获取域名。username
当前阿里云账号的AccessKey ID。
您可以单击AccessKey 管理,获取AccessKey ID。
password
当前阿里云账号的AccessKey Secret。
您可以单击AccessKey 管理,获取AccessKey Secret。
readThreadSize
查询场景的连接数。
异步模式下为提高攒批效率,建议设为线程数
threadSize的2~4倍。同步模式下为确保计算资源充分利用,建议适当调高连接数。本文设置的连接数为
100。
测试配置
threadSize
生成请求条件的线程数。
针对本文测试的64核实例规格:
在异步点查模式下建议设置线程数为8。
在同步点查模式下建议设置线程数为500。
您需要根据实例规格及数据特征适当调整该参数。
testTime
测试的目标时间,单位为毫秒。
不涉及。
tableName
测试的目标表名。
不涉及。
async
点查测试的模式是否为异步。
参数取值如下:
true:表示异步。
false:表示同步。
vacuumTableBeforeRun
测试开始前是否执行vacuum操作。
参数取值如下:
true:表示执行Vacuum操作。
false:表示不执行Vacuum操作。
执行Vacuum会强制触发Compaction操作。
keyRangeParams
点查的主键参数范围,格式为
<I/L><Start>-<End>。参数说明如下:
I/L:I表示INT类型,L表示BIGINT类型。Start:主键起始值。End:主键结束值。
点查测试过程中,测试工具会在配置的范围内随机生成目标主键进行查询。
表初始化配置(仅PREPARE_GET_DATA模式生效)
rowNumber
需要预生成的表的数据行数。
不涉及。
orientation
需要预生成的表的存储类型。
参数取值如下:
row:行存表。
column:列存表。
row,column:行列共存表。
columnCount
需要预生成的表的列数。每列的数据类型均为TEXT。
不涉及。
columnSize
需要预生成的表每列的字符长度。
不涉及。
按Esc键,输入
:wq并回车以保存并关闭文件。
执行如下语句进行测试:
说明点查场景的模式参数包含两个取值:
PREPARE_GET_DATA对应点查前的数据准备模式,GET对应点查模式。如果您已写入业务数据或已经完成了数据写入、更新场景的测试并保留了测试表,则不需使用PREPARE_GET_DATA模式进行数据准备,直接使用GET模式进行点查即可。# 使用PREPARE_GET_DATA模式进行数据准备 java -jar holo-e2e-performance-tool-1.0.0.jar test.conf PREPARE_GET_DATA # 使用GET模式进行点查测试 java -jar holo-e2e-performance-tool-1.0.0.jar test.conf GET获取测试结果。
使用如下命令获取测试结果。
cat result.csv测试结果文件
result.csv中包含如下字段。字段
描述
start
测试开始时间。
end
测试结束时间。
count
测试数据行数。
qps1
最后1分钟的平均QPS。
qps5
最后5分钟的平均QPS。
qps15
最后15分钟的平均QPS。
latencyMean
平均延迟。
INSERT、GET模式收集。
latencyP99
P99延迟。
INSERT、GET模式收集。
latencyP999
P999延迟。
INSERT、GET模式收集。
version
实例版本。
测试结果
本文对多个场景进行了测试:数据写入、更新场景均测试行存、列存、行列共存三种存储类型;由于列存表不适合进行点查,因此数据点查场景仅测试行存、行列共存两种存储类型。
测试性能数据结果如下,其中表的列数选择20、50、100三种规格,列大小均为20。本文使用的Hologres实例版本为V3.0.22(JDK版本为JDK 11),规格为64核,该规格实例推荐的数据总规模在4000万行到4亿行之间,因此本文各场景选取的测试数据量均为2亿行。
实例规格、表结构、数据量、并发数等参数均会对性能产生较大影响。在实际测试中,您需要先确定Hologres实例规格、表结构、数据量等参数,而后调整并发数进行多次测试。
如果您的目标是测试Hologres最优性能,您需要在每次测试完成后监测实例的CPU资源使用率,如果CPU资源未被全部使用,您需要适当增加并发数继续测试,以获取最优、最准确的性能结果。
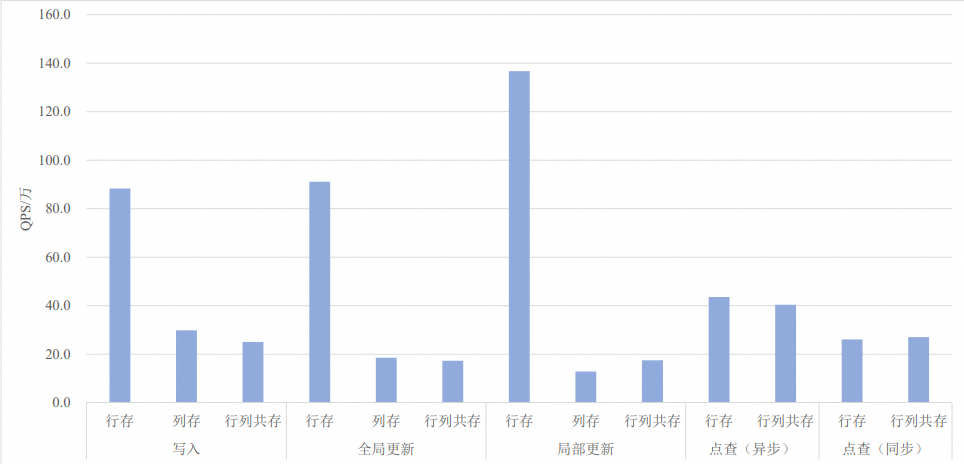
20列
测试结果QPS和latency(点查)具体数值和对比图如下所示。其中QPS选用测试结果文件中的
qps1指标,latency选用测试结果文件中的latencyMean指标。存储格式
测试场景
并发配置
QPS/万
latency/ms
行存
写入(Fixed copy)
threadSize=8
88.3
不涉及
全局更新(Fixed copy)
threadSize=8
91.1
不涉及
局部更新(Fixed copy)
threadSize=8
136.7
不涉及
点查(异步)
threadSize=8
readThreadSize=32
43.6
8.60
点查(同步)
threadSize=100
readThreadSize=100
26.1
7.88
列存
写入(Fixed copy)
threadSize=8
29.9
不涉及
全局更新(Fixed copy)
threadSize=8
18.5
不涉及
局部更新(Fixed copy)
threadSize=8
12.8
不涉及
行列共存
写入(Fixed copy)
threadSize=8
25.0
不涉及
全局更新(Fixed copy)
threadSize=8
17.3
不涉及
局部更新(Fixed copy)
threadSize=8
17.5
不涉及
点查(异步)
threadSize=8
readThreadSize=32
40.4
8.75
点查(同步)
threadSize=100
readThreadSize=100
27.0
8.12
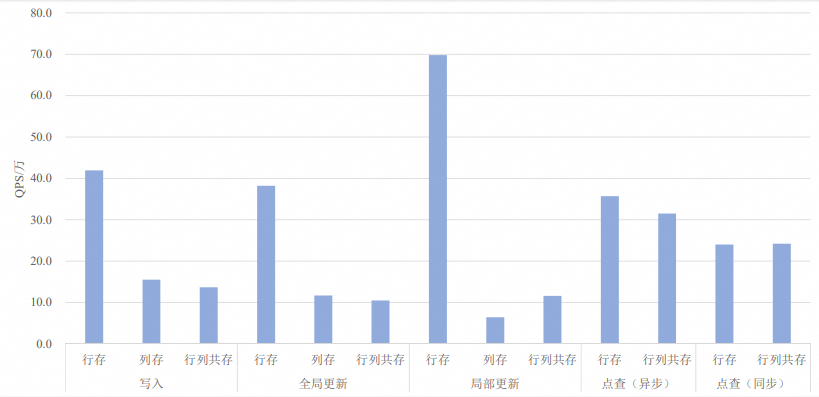
50列
测试结果QPS和latency(点查)具体数值及对比图如下所示。其中QPS选用测试结果文件中的
qps1指标,latency选用测试结果文件中的latencyMean指标。存储格式
测试场景
并发配置
QPS/万
latency/ms
行存
写入(Fixed copy)
threadSize=8
41.9
不涉及
全局更新(Fixed copy)
threadSize=8
38.2
不涉及
局部更新(Fixed copy)
threadSize=8
69.8
不涉及
点查(异步)
threadSize=8
readThreadSize=32
35.7
10.20
点查(同步)
threadSize=100
readThreadSize=100
24.0
9.28
列存
写入(Fixed copy)
threadSize=8
15.5
不涉及
全局更新(Fixed copy)
threadSize=8
11.7
不涉及
局部更新(Fixed copy)
threadSize=8
6.4
不涉及
行列共存
写入(Fixed copy)
threadSize=8
13.7
不涉及
全局更新(Fixed copy)
threadSize=8
10.5
不涉及
局部更新(Fixed copy)
threadSize=8
11.6
不涉及
点查(异步)
threadSize=8
readThreadSize=32
31.5
12.29
点查(同步)
threadSize=100
readThreadSize=100
24.2
10.00
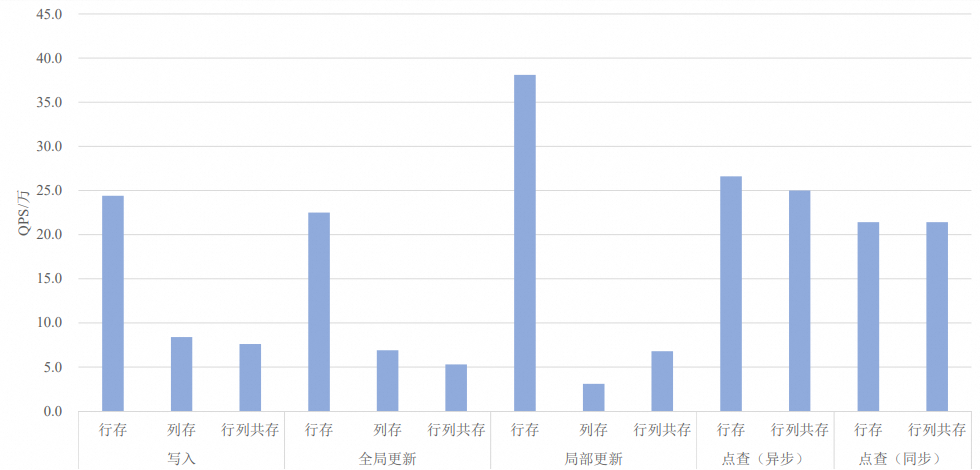
100列
测试结果QPS和latency(点查)具体数值及对比图如下所示。其中QPS选用测试结果文件中的
qps1指标,latency选用测试结果文件中的latencyMean指标。存储格式
测试场景
并发配置
QPS/万
latency/ms
行存
写入(Fixed copy)
threadSize=8
24.4
不涉及
全局更新(Fixed copy)
threadSize=8
22.5
不涉及
局部更新(Fixed copy)
threadSize=8
38.1
不涉及
点查(异步)
threadSize=8
readThreadSize=32
26.6
14.34
点查(同步)
threadSize=100
readThreadSize=100
21.4
12.12
列存
写入(Fixed copy)
threadSize=8
8.4
不涉及
全局更新(Fixed copy)
threadSize=8
6.9
不涉及
局部更新(Fixed copy)
threadSize=8
3.1
不涉及
行列共存
写入(Fixed copy)
threadSize=8
7.6
不涉及
全局更新(Fixed copy)
threadSize=8
5.3
不涉及
局部更新(Fixed copy)
threadSize=8
6.8
不涉及
点查(异步)
threadSize=8
readThreadSize=32
25.0
15.66
点查(同步)
threadSize=100
readThreadSize=100
21.4
13.79