This tutorial builds on our previous guide, "Get started with multimodal retrieval using DashVector and ModelScope". We will upgrade the multimodal retrieval system using the new ONE-PEACE universal multimodal representation model from Alibaba Cloud Model Studio in combination with the DashVector vector retrieval service. This guide demonstrates more advanced multimodal retrieval capabilities.
Overall flow
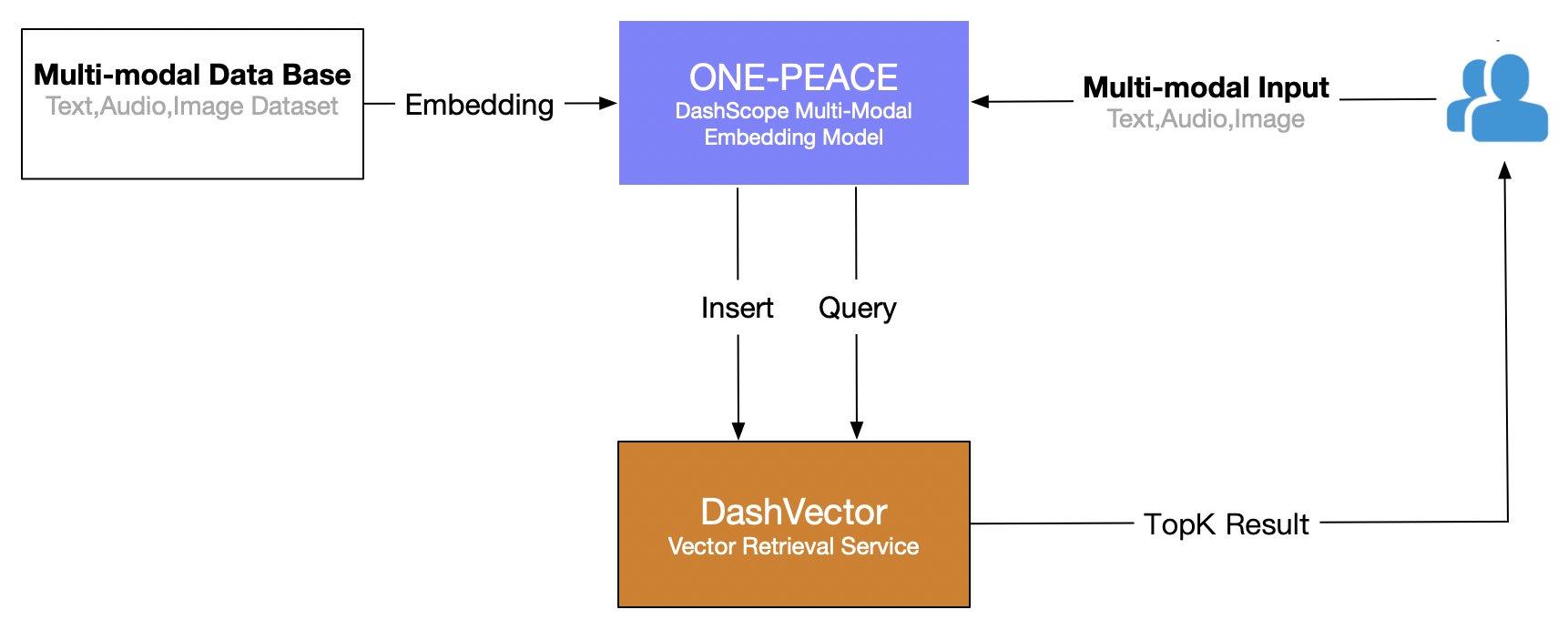
The process has two main stages:
Embed and store multimodal data. Use the Embedding API of the ONE-PEACE model service to convert data from various modalities into high-dimensional vectors.
Retrieve data with multimodal queries. Use the multimodal embedding capabilities of the ONE-PEACE model to combine inputs from different modalities, such as text-only, text and audio, or audio and image inputs. After you obtain the embedding vector, use DashVector to perform cross-modal retrieval to find similar results.
Prerequisites
1. Prepare API keys
Activate Alibaba Cloud Model Studio and obtain an API key. For more information, see Obtain an API key and Configure an API key as an environment variable.
Activate the DashVector vector retrieval service and obtain an API key. For more information, see Manage API keys.
2. Prepare the environment
This tutorial uses the latest ONE-PEACE model from DashScope as the multimodal model service. ONE-PEACE is a universal representation model for image, text, and audio modalities. It has achieved new state-of-the-art (SOTA) performance in tasks such as semantic segmentation, audio-text retrieval, audio classification, and visual grounding. It also delivers leading results in video classification, image classification, image-text retrieval, and other classic multimodal benchmarks. The model has the following environment dependencies:
Install Python 3.7 or later. Ensure that you have the correct Python version.
# Install the DashScope and DashVector SDKs
pip3 install dashscope dashvectorBasic retrieval
1. Data preparation
The DashScope ONE-PEACE model service currently supports only image and audio inputs as URLs. You can upload your dataset to public cloud storage, such as Object Storage Service (OSS) or Amazon S3, and obtain a list of URLs for the images and audio files.
This example uses the ImageNet-1k validation dataset as the image dataset for storage. The original image data is embedded and stored. For retrieval, the ESC-50 dataset is used as the audio input. You can define your own text and image inputs, or combine data from different modalities.
2. Embed and store data
Replace `your-dashscope-api-key`, `your-dashvector-api-key`, and `your-dashvector-cluster-endpoint` with your API keys and cluster endpoint. The code will not run without them.
The ImageNet-1k validation dataset contains 50,000 annotated images across 1,000 categories, with 50 images per category. We use the ONE-PEACE model to extract the embedding vectors of the original images and store them. To display the images later, we also store the original image URLs. The following code provides an example:
import dashscope
from dashscope import MultiModalEmbedding
from dashvector import Client, Doc, DashVectorException
dashscope.api_key = '{your-dashscope-api-key}'
# The ONE-PEACE model service currently supports only image and audio inputs in URL format.
# You must upload your dataset to public cloud storage, such as OSS or S3, and get a list of URLs for the images and audio files.
# This file stores the public URL of a single image from the dataset on each line. It is in the same directory as the current Python script.
IMAGENET1K_URLS_FILE_PATH = "imagenet1k-urls.txt"
def index_image():
# Initialize the DashVector client.
client = Client(
api_key='{your-dashvector-api-key}',
endpoint='{your-dashvector-cluster-endpoint}'
)
# Create a collection. Specify the collection name and vector dimensions. The ONE-PEACE model generates vectors with 1536 dimensions.
rsp = client.create('imagenet1k_val_embedding', 1536)
if not rsp:
raise DashVectorException(rsp.code, reason=rsp.message)
# Call the DashScope ONE-PEACE model to generate image embeddings and insert them into DashVector.
collection = client.get('imagenet1k_val_embedding')
with open(IMAGENET1K_URLS_FILE_PATH, 'r') as file:
for i, line in enumerate(file):
url = line.strip('\n')
input = [{'image': url}]
result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1,
input=input,
auto_truncation=True)
if result.status_code != 200:
print(f"ONE-PEACE failed to generate embedding of {url}, result: {result}")
continue
embedding = result.output["embedding"]
collection.insert(
Doc(
id=str(i),
vector=embedding,
fields={'image_url': url}
)
)
if (i + 1) % 100 == 0:
print(f"---- Succeeded to insert {i + 1} image embeddings")
if __name__ == '__main__':
index_image()
The code above needs to access the DashScope ONE-PEACE multimodal embedding model. The overall running speed depends on the queries per second (QPS) of the service you have activated.
The success of generating an embedding with the ONE-PEACE model can be affected by image size. After you run the code, the final number of stored data entries may be less than 50,000.
3. Modal retrieval
3.1. Text-based retrieval
For single-modality text retrieval, you can obtain a text embedding vector from the ONE-PEACE model. Then, you can use the retrieval interface of the DashVector service to quickly retrieve similar images from the database. In this example, the text query is "cat". The following code provides an example:
import dashscope
from dashscope import MultiModalEmbedding
from dashvector import Client
from urllib.request import urlopen
from PIL import Image
dashscope.api_key = '{your-dashscope-api-key}'
def show_image(image_list):
for img in image_list:
# Note: The show() function may require you to install necessary image browser components to work on a Linux server.
# We recommend running this code on a server that supports Jupyter Notebook.
img.show()
def text_search(input_text):
# Initialize the DashVector client.
client = Client(
api_key='{your-dashvector-api-key}',
endpoint='{your-dashvector-cluster-endpoint}'
)
# Get the collection that was previously created.
collection = client.get('imagenet1k_val_embedding')
# Get the embedding vector for the text query.
input = [{'text': input_text}]
result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1,
input=input,
auto_truncation=True)
if result.status_code != 200:
raise Exception(f"ONE-PEACE failed to generate embedding of {input}, result: {result}")
text_vector = result.output["embedding"]
# Perform a vector search with DashVector.
rsp = collection.query(text_vector, topk=3)
image_list = list()
for doc in rsp:
img_url = doc.fields['image_url']
img = Image.open(urlopen(img_url))
image_list.append(img)
return image_list
if __name__ == '__main__':
"""Text-based retrieval"""
# cat
text_query = "cat"
show_image(text_search(text_query))After you run the code, the results are as follows:
|
|
|



3.2. Audio-based retrieval
Single-modality audio retrieval is similar to text retrieval. Here, the audio query is a "cat meow" clip from the ESC-50 dataset. The following code provides an example:
import dashscope
from dashscope import MultiModalEmbedding
from dashvector import Client
from urllib.request import urlopen
from PIL import Image
dashscope.api_key = '{your-dashscope-api-key}'
def show_image(image_list):
for img in image_list:
# Note: The show() function may require you to install necessary image browser components to work on a Linux server.
# We recommend running this code on a server that supports Jupyter Notebook.
img.show()
def audio_search(input_audio):
# Initialize the DashVector client.
client = Client(
api_key='{your-dashvector-api-key}',
endpoint='{your-dashvector-cluster-endpoint}'
)
# Get the collection that was previously created.
collection = client.get('imagenet1k_val_embedding')
# Get the embedding vector for the audio query.
input = [{'audio': input_audio}]
result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1,
input=input,
auto_truncation=True)
if result.status_code != 200:
raise Exception(f"ONE-PEACE failed to generate embedding of {input}, result: {result}")
audio_vector = result.output["embedding"]
# Perform a vector search with DashVector.
rsp = collection.query(audio_vector, topk=3)
image_list = list()
for doc in rsp:
img_url = doc.fields['image_url']
img = Image.open(urlopen(img_url))
image_list.append(img)
return image_list
if __name__ == '__main__':
"""Audio-based retrieval"""
# cat meow
audio_url = "http://proxima-internal.oss-cn-zhangjiakou.aliyuncs.com/audio-dataset/esc-50/1-47819-A-5.wav"
show_image(audio_search(audio_url))After you run the code, the results are as follows:
|
|
|



3.3. Text and audio-based retrieval
Next, we will try a joint "text and audio" multimodal retrieval. First, obtain the embedding vector for the "text and audio" input from the ONE-PEACE model. Then, retrieve the results using the DashVector service. The text query is "grass", and the audio query is still the "cat meow" clip from ESC-50. The following code provides an example:
import dashscope
from dashscope import MultiModalEmbedding
from dashvector import Client
from urllib.request import urlopen
from PIL import Image
dashscope.api_key = '{your-dashscope-api-key}'
def show_image(image_list):
for img in image_list:
# Note: The show() function may require you to install necessary image browser components to work on a Linux server.
# We recommend running this code on a server that supports Jupyter Notebook.
img.show()
def text_audio_search(input_text, input_audio):
# Initialize the DashVector client.
client = Client(
api_key='{your-dashvector-api-key}',
endpoint='{your-dashvector-cluster-endpoint}'
)
# Get the collection that was previously created.
collection = client.get('imagenet1k_val_embedding')
# Get the embedding vector for the text and audio query.
input = [
{'text': input_text},
{'audio': input_audio},
]
result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1,
input=input,
auto_truncation=True)
if result.status_code != 200:
raise Exception(f"ONE-PEACE failed to generate embedding of {input}, result: {result}")
text_audio_vector = result.output["embedding"]
# Perform a vector search with DashVector.
rsp = collection.query(text_audio_vector, topk=3)
image_list = list()
for doc in rsp:
img_url = doc.fields['image_url']
img = Image.open(urlopen(img_url))
image_list.append(img)
return image_list
if __name__ == '__main__':
"""Text and audio-based retrieval"""
# grass
text_query = "grass"
# cat meow
audio_url = "http://proxima-internal.oss-cn-zhangjiakou.aliyuncs.com/audio-dataset/esc-50/1-47819-A-5.wav"
show_image(text_audio_search(text_query, audio_url))After you run the code, the results are as follows:
|
|
|



3.4. Image and audio-based retrieval
Let's try a joint "image and audio" multimodal retrieval. This is similar to the "text and audio" retrieval. The image is a picture of grass, which you must first upload to public cloud storage to obtain a URL. The audio query is still the "cat meow" clip from ESC-50. The following code provides an example:
import dashscope
from dashscope import MultiModalEmbedding
from dashvector import Client
from urllib.request import urlopen
from PIL import Image
dashscope.api_key = '{your-dashscope-api-key}'
def show_image(image_list):
for img in image_list:
# Note: The show() function may require you to install necessary image browser components to work on a Linux server.
# We recommend running this code on a server that supports Jupyter Notebook.
img.show()
def image_audio_search(input_image, input_audio):
# Initialize the DashVector client.
client = Client(
api_key='{your-dashvector-api-key}',
endpoint='{your-dashvector-cluster-endpoint}'
)
# Get the collection that was previously created.
collection = client.get('imagenet1k_val_embedding')
# Get the embedding vector for the image and audio query.
# Note: The weight parameter 'factor' for the audio modality input is set to 2. The default is 1.
# This increases the influence of the audio input (cat meow) on the search results.
input = [
{'factor': 1, 'image': input_image},
{'factor': 2, 'audio': input_audio},
]
result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1,
input=input,
auto_truncation=True)
if result.status_code != 200:
raise Exception(f"ONE-PEACE failed to generate embedding of {input}, result: {result}")
image_audio_vector = result.output["embedding"]
# Perform a vector search with DashVector.
rsp = collection.query(image_audio_vector, topk=3)
image_list = list()
for doc in rsp:
img_url = doc.fields['image_url']
img = Image.open(urlopen(img_url))
image_list.append(img)
return image_list
if __name__ == '__main__':
"""Image and audio-based retrieval"""
# grass
image_url = "http://proxima-internal.oss-cn-zhangjiakou.aliyuncs.com/image-dataset/grass-field.jpeg"
# cat meow
audio_url = "http://proxima-internal.oss-cn-zhangjiakou.aliyuncs.com/audio-dataset/esc-50/1-47819-A-5.wav"
show_image(image_audio_search(image_url, audio_url))The input image is shown below:

After you run the code, the results are as follows:
|
|
|



Advanced usage
In the previous scenarios, the database for retrieval contained single-modality image data. In this section, we use the ONE-PEACE model to obtain embedding vectors for data of multiple modalities simultaneously. We can then use these embedding vectors as the database for retrieval and observe the results.
1. Data preparation
This example uses the validation dataset from Microsoft COCO for the captioning scenario. We embed and store both the images and their corresponding caption text. For retrieval, you can use your own custom multimodal data, such as images, audio, and text, or data from public datasets.
2. Embed and store data
For the code in this tutorial to run correctly, you must replace your-xxx-api-key and your-xxx-cluster-endpoint with your API key and cluster endpoint.
The Microsoft COCO captioning validation set contains 5,000 well-annotated images and their corresponding descriptive text. We use the DashScope ONE-PEACE model to extract the "image and text" embedding vectors from the dataset and store them. To display the images later, we also store the original image URLs and their captions. The following code provides an example:
import dashscope
from dashscope import MultiModalEmbedding
from dashvector import Client, Doc, DashVectorException
dashscope.api_key = '{your-dashscope-api-key}'
# The ONE-PEACE model service currently supports only image and audio inputs in URL format.
# You must upload your dataset to public cloud storage, such as OSS or S3, and get a list of URLs for the images and audio files.
# This file stores the public URL of a single image and its corresponding caption text on each line, separated by a semicolon (;).
COCO_CAPTIONING_URLS_FILE_PATH = "cocoval5k-urls-captions.txt"
def index_image_text():
# Initialize the DashVector client.
client = Client(
api_key='{your-dashvector-api-key}',
endpoint='{your-dashvector-cluster-endpoint}'
)
# Create a collection. Specify the collection name and vector dimensions. The ONE-PEACE model generates vectors with 1536 dimensions.
rsp = client.create('coco_val_embedding', 1536)
if not rsp:
raise DashVectorException(rsp.code, reason=rsp.message)
# Call the DashScope ONE-PEACE model to generate image embeddings and insert them into DashVector.
collection = client.get('coco_val_embedding')
with open(COCO_CAPTIONING_URLS_FILE_PATH, 'r') as file:
for i, line in enumerate(file):
url, caption = line.strip('\n').split(";")
input = [
{'text': caption},
{'image': url},
]
result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1,
input=input,
auto_truncation=True)
if result.status_code != 200:
print(f"ONE-PEACE failed to generate embedding of {url}, result: {result}")
continue
embedding = result.output["embedding"]
collection.insert(
Doc(
id=str(i),
vector=embedding,
fields={'image_url': url, 'image_caption': caption}
)
)
if (i + 1) % 20 == 0:
print(f"---- Succeeded to insert {i + 1} image embeddings")
if __name__ == '__main__':
index_image_text()
The code above needs to access the DashScope ONE-PEACE multimodal embedding model. The overall running speed depends on the QPS of the service you have activated.
3. Modal retrieval
3.1. Text-based retrieval
First, let's try single-modality text retrieval. The following code provides an example:
import dashscope
from dashscope import MultiModalEmbedding
from dashvector import Client
from urllib.request import urlopen
from PIL import Image
dashscope.api_key = '{your-dashscope-api-key}'
def show_image_text(image_text_list):
for img, cap in image_text_list:
# Note: The show() function may require you to install necessary image browser components to work on a Linux server.
# We recommend running this code on a server that supports Jupyter Notebook.
img.show()
print(cap)
def text_search(input_text):
# Initialize the DashVector client.
client = Client(
api_key='{your-dashvector-api-key}',
endpoint='{your-dashvector-cluster-endpoint}'
)
# Get the collection that was previously created.
collection = client.get('coco_val_embedding')
# Get the embedding vector for the text query.
input = [{'text': input_text}]
result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1,
input=input,
auto_truncation=True)
if result.status_code != 200:
raise Exception(f"ONE-PEACE failed to generate embedding of {input}, result: {result}")
text_vector = result.output["embedding"]
# Perform a vector search with DashVector.
rsp = collection.query(text_vector, topk=3)
image_text_list = list()
for doc in rsp:
img_url = doc.fields['image_url']
img_cap = doc.fields['image_caption']
img = Image.open(urlopen(img_url))
image_text_list.append((img, img_cap))
return image_text_list
if __name__ == '__main__':
"""Text-based retrieval"""
# dog
text_query = "dog"
show_image_text(text_search(text_query))
After you run the code, the results are as follows:
The fur on this dog is long enough to cover his eyes. |
A picture of a dog on a bed. |
A dog going to the bathroom in the park. |



3.2. Audio-based retrieval
Now, let's try single-modality audio retrieval. We use a "dog bark" clip from the ESC-50 dataset as the audio input. The following code provides an example:
import dashscope
from dashscope import MultiModalEmbedding
from dashvector import Client
from urllib.request import urlopen
from PIL import Image
dashscope.api_key = '{your-dashscope-api-key}'
def show_image_text(image_text_list):
for img, cap in image_text_list:
# Note: The show() function may require you to install necessary image browser components to work on a Linux server.
# We recommend running this code on a server that supports Jupyter Notebook.
img.show()
print(cap)
def audio_search(input_audio):
# Initialize the DashVector client.
client = Client(
api_key='{your-dashvector-api-key}',
endpoint='{your-dashvector-cluster-endpoint}'
)
# Get the collection that was previously created.
collection = client.get('coco_val_embedding')
# Get the embedding vector for the audio query.
input = [{'audio': input_audio}]
result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1,
input=input,
auto_truncation=True)
if result.status_code != 200:
raise Exception(f"ONE-PEACE failed to generate embedding of {input}, result: {result}")
audio_vector = result.output["embedding"]
# Perform a vector search with DashVector.
rsp = collection.query(audio_vector, topk=3)
image_text_list = list()
for doc in rsp:
img_url = doc.fields['image_url']
img_cap = doc.fields['image_caption']
img = Image.open(urlopen(img_url))
image_text_list.append((img, img_cap))
return image_text_list
if __name__ == '__main__':
"""Audio-based retrieval"""
# dog bark
audio_url = "http://proxima-internal.oss-cn-zhangjiakou.aliyuncs.com/audio-dataset/esc-50/1-100032-A-0.wav"
show_image_text(audio_search(audio_url))
After you run the code, the results are as follows:
The fur on this dog is long enough to cover his eyes. |
A dog standing on a bed in a room. |
A small black and white dog with the wind blowing through it's hair. |



3.3. Text and audio-based retrieval
Next, let's try dual-modality retrieval using "text and audio". We use a "dog bark" clip from the ESC-50 dataset as the audio input and "beach" as the text input. The following code provides an example:
import dashscope
from dashscope import MultiModalEmbedding
from dashvector import Client
from urllib.request import urlopen
from PIL import Image
dashscope.api_key = '{your-dashscope-api-key}'
def show_image_text(image_text_list):
for img, cap in image_text_list:
# Note: The show() function may require you to install necessary image browser components to work on a Linux server.
# We recommend running this code on a server that supports Jupyter Notebook.
img.show()
print(cap)
def text_audio_search(input_text, input_audio):
# Initialize the DashVector client.
client = Client(
api_key='{your-dashvector-api-key}',
endpoint='{your-dashvector-cluster-endpoint}'
)
# Get the collection that was previously created.
collection = client.get('coco_val_embedding')
# Get the embedding vector for the text and audio query.
input = [
{'text': input_text},
{'audio': input_audio},
]
result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1,
input=input,
auto_truncation=True)
if result.status_code != 200:
raise Exception(f"ONE-PEACE failed to generate embedding of {input}, result: {result}")
text_audio_vector = result.output["embedding"]
# Perform a vector search with DashVector.
rsp = collection.query(text_audio_vector, topk=3)
image_text_list = list()
for doc in rsp:
img_url = doc.fields['image_url']
img_cap = doc.fields['image_caption']
img = Image.open(urlopen(img_url))
image_text_list.append((img, img_cap))
return image_text_list
if __name__ == '__main__':
"""Text and audio-based retrieval"""
text_query = "beach"
# dog bark
audio_url = "http://proxima-internal.oss-cn-zhangjiakou.aliyuncs.com/audio-dataset/esc-50/1-100032-A-0.wav"
show_image_text(text_audio_search(text_query, audio_url))
After you run the code, the results are as follows:
a couple of dogs stand on a beach next to some water. |
A view of a beach that has some people sitting on it. |
people enjoy swimming in the waves of the ocean on a sunny day at the beach. |



Looking at the search results, the last two images focus more on the beach from the "beach" text input. The dog image, indicated by the "dog bark" audio input, is not prominent. In the second image, you can see a dog standing in the water only after zooming in. The third image has almost no dog in it.
In this situation, you can adjust the weights of different inputs to control which modality has a greater influence on the embedding vector. This lets you emphasize certain aspects in the retrieval. For example, in the code above, we can assign a greater weight to the "dog bark" audio to highlight the dog's image in the search results.
# The rest of the code is the same.
# Use the 'factor' parameter to adjust the weights of different modality inputs. The default is 1. Here, we set the audio weight to 2.
input = [
{'factor': 1, 'text': input_text},
{'factor': 2, 'audio': input_audio},
]After you replace the input code block, run the script again. The results are as follows:
a couple of dogs stand on a beach next to some water. |
A beautiful woman in a bikini surfing with her dog. |
A small black and white dog with the wind blowing through it's hair. |



Conclusion
This topic demonstrates a variety of multimodal retrieval examples using the ONE-PEACE model from DashScope and the DashVector vector retrieval service. By leveraging the excellent multimodal embedding capabilities of the ONE-PEACE model and the powerful vector retrieval of DashVector, you can achieve impressive results in AI-powered multimodal retrieval.
In the examples in this topic, the vector retrieval service, model service, and data are all publicly accessible. The provided examples offer a limited view of what multimodal retrieval can do. We encourage you to try it out and explore the potential of multimodal retrieval for yourself.