For large datasets, if you frequently perform UPDATE operations based on a primary key or run queries with range filter conditions, consider setting an event time column (segment key). The system sorts data files based on the event time column range before merging them. This process reduces overlap between files, allowing the query engine to prune as many files as possible and improve query efficiency. A properly configured event time column improves query speed and overall performance. This topic describes how to set the event_time_column property for a table in Hologres.
Event time column
The event_time_column property was formerly named segment key. In Hologres V0.9 and later, the default property name is event_time_column. The segment key property is retained for backward compatibility.
The event time column is primarily used for the following scenarios:
-
Queries that include a
range filteror anequality condition. -
UPDATEoperations based on aprimary key.
To set the event_time_column property, you must specify it when you create a table. Use the following syntax:
-- Syntax supported in Hologres V2.1 and later
CREATE TABLE <table_name> (...) WITH (event_time_column = '[<columnName>[,...]]');
-- Syntax supported in all versions
BEGIN;
CREATE TABLE <table_name> (...);
call set_table_property('<table_name>', 'event_time_column', '[<columnName> [,...]]');
COMMIT;Parameters:
|
Parameter |
Description |
|
table_name |
The name of the table. |
|
columnName |
The column to use as the |
Recommendations
-
The
event time columnis best suited for columns with monotonically increasing or decreasing values, such as timestamp columns. It is ideal for time-related data, such as logs and traffic data, where a proper configuration can significantly improve performance. If anevent time columnis completely unordered, merged files will not have distinct value ranges, which negates the benefits of file pruning. -
If a table does not have a clear monotonically increasing or decreasing column, consider adding a column such as
update_timeand writing the current time to it for eachUPSERToperation. -
The
event time columnfollows theleftmost matching principle. Setting multiple columns can limit which query patterns are accelerated. Therefore, we recommend specifying no more than two columns in most cases.
Limitations
-
The
event time columnmust be a column or a combination of columns that are defined asNOT NULL. You can omit theevent_time_columnproperty, but you cannot set it to a column that allows null values. In Hologres V1.3.20 to V1.3.27, nullable columns were supported for theevent_time_columnproperty. Starting from Hologres V1.3.28, this is no longer supported because a nullableevent time columncan compromise data integrity. If you have a strong business requirement to set a nullable column as theevent time column, you can add the following statement before your SQL statement:set hg_experimental_enable_nullable_segment_key = true;You can use the following SQL statement to check whether the current database contains any
event time column(orsegment key) that is nullable:WITH t_base AS ( SELECT * FROM hologres.hg_table_info WHERE collect_time::date = CURRENT_DATE ), t1 AS ( SELECT db_name, schema_name, table_name, jsonb_array_elements(table_meta::jsonb -> 'columns') cols FROM t_base ), t2 AS ( SELECT db_name, schema_name, table_name, cols ->> 'name' col_name FROM t1 WHERE cols -> 'nullable' = 'true'::jsonb ), t3 AS ( SELECT db_name, schema_name, table_name, regexp_replace(regexp_split_to_table(table_meta::jsonb ->> 'segment_key', ','), ':asc|:desc$', '') segment_key_col FROM t_base WHERE table_meta::jsonb -> 'segment_key' IS NOT NULL ) SELECT CURRENT_DATE, t3.db_name, t3.schema_name, t3.table_name, jsonb_build_object('nullable_segment_key_column', string_agg(t3.segment_key_col, ',')) as nullable_segment_key_column FROM t2, t3 WHERE t3.db_name = t2.db_name AND t3.schema_name = t2.schema_name AND t3.table_name = t2.table_name AND t2.col_name = t3.segment_key_col GROUP BY t3.db_name, t3.schema_name, t3.table_name; -
You cannot modify the
event_time_columnproperty after a table is created. To change it, you must recreate the table. -
You cannot set an
event time columnfor arow-oriented table. -
For a
column-oriented table, if you do not explicitly set anevent time column, Hologres by default uses the firstNOT NULLcolumn of theTIMESTAMPorTIMESTAMPTZdata type as theevent time column. If no such column exists, the firstNOT NULLcolumn of theDATEdata type is used. In versions earlier than Hologres V0.9, no defaultevent time columnis set. -
You cannot use
DECIMAL,NUMERIC,FLOAT,DOUBLE,ARRAY,JSON,JSONB,BIT,MONEY, or other complex data types for anevent time column.
How it works
The following figure shows the data write process within a single shard: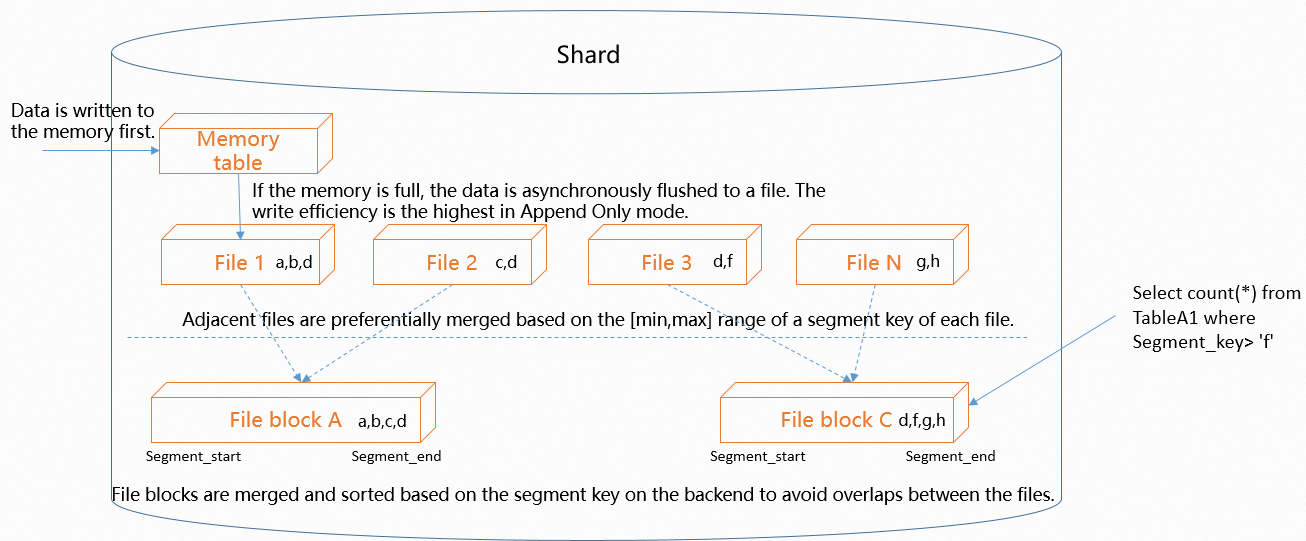
-
Within a
shard, data is first written to anin-memory tablein append-only mode to maximize write performance.In-memory tables have a fixed size. When anin-memory tableis full, the system asynchronously flushes its data to files. -
To optimize write performance, data is written in append-only mode, which causes the number of files to increase over time. The system periodically merges these files in the background. If you set an
event time column(orsegment key), the system sorts files based on theevent time columnrange and then merges files with adjacent ranges. This process reduces overlap between files, allowing the query optimizer to prune more files and improve query efficiency. -
Files are sorted based on the
event time column. Therefore, theevent time columnalso adheres to theleftmost matching principle. For example, if you set columnsa,b, andcas theevent time column, a query can benefit from this setting if its filter conditions are ona,b,cora,b. If the filter conditions are ona,c, only columnacan benefit. If the filter conditions are onb,c, the query cannot benefit from theevent time column.
As described, the event time column can accelerate the following scenarios:
-
Queries that include a
range filteror anequality condition.If a queried column is set as the
event time column, Hologres compares the range conditions in the query with the file-level statistics (min/max) of the column. This allows Hologres to quickly prune irrelevant files and accelerate the query. -
UPDATEoperations based on aprimary key.The Hologres
UPDATEcommand is implemented as a combination of theDELETEandINSERTcommands. In scenarios involving a primary key-based UPDATE or INSERT ON CONFLICT(UPSERT), the primary key is first used to find the segment key of the old data in the target table. This segment key is then used to locate the file that contains the old data, and the data is finally marked asDELETE. If a segment key is properly configured, the file containing the old data can be quickly located, which improves write performance. Conversely, if a column-oriented table has no segment key configured, the segment key is configured with an inappropriate field, or the field for the segment key does not have a strong correlation with time during data writes (for example, if the data is mostly out of order), a large number of files must be scanned to find the old data. This process not only causes a large number of I/O operations but also consumes significant CPU resources, which negatively affects write performance and the load of the entire instance.
Examples
-
Create a single
event time columnwhen you create a table.-
Syntax supported in Hologres V2.1 and later:
CREATE TABLE tbl_segment_test ( a int NOT NULL, b timestamptz NOT NULL ) WITH ( event_time_column = 'b' ); INSERT INTO tbl_segment_test values (1,'2022-09-05 10:23:54+08'), (2,'2022-09-05 10:24:54+08'), (3,'2022-09-05 10:25:54+08'), (4,'2022-09-05 10:26:54+08'); EXPLAIN SELECT * FROM tbl_segment_test WHERE b > '2022-09-05 10:24:54+08'; -
Syntax supported in all versions:
BEGIN; CREATE TABLE tbl_segment_test ( a int NOT NULL, b timestamptz NOT NULL ); CALL set_table_property('tbl_segment_test', 'event_time_column', 'b'); COMMIT; INSERT INTO tbl_segment_test VALUES (1,'2022-09-05 10:23:54+08'), (2,'2022-09-05 10:24:54+08'), (3,'2022-09-05 10:25:54+08'), (4,'2022-09-05 10:26:54+08'); EXPLAIN SELECT * FROM tbl_segment_test WHERE b > '2022-09-05 10:24:54+08';
You can check the
execution planby running anEXPLAINstatement. IfSegment Filterappears in the plan, the query is using theevent time column. The following plan includes aSegment Filter, indicating theevent time columnis active.QUERY PLAN Gather (cost=0.00..1.10 rows=1 width=12) -> Exchange (Gather Exchange) (cost=0.00..1.10 rows=1 width=12) -> Decode (cost=0.00..1.10 rows=1 width=12) -> Index Scan using holo_index:[1] on tbl_segment_test (cost=0.00..1.00 rows=1 width=12) Segment Filter: (b > '2022-09-05 10:24:54+08'::timestamp with time zone) Optimizer: HQO version 1.3.0 -
-
Create multiple
event time columns when you create a table.-
Syntax supported in Hologres V2.1 and later:
CREATE TABLE tbl_segment_test_2 ( a int NOT NULL, b timestamptz NOT NULL ) WITH ( event_time_column = 'a,b' ); INSERT INTO tbl_segment_test_2 VALUES (1,'2022-09-05 10:23:54+08'), (2,'2022-09-05 10:24:54+08'), (3,'2022-09-05 10:25:54+08'), (4,'2022-09-05 10:26:54+08') ; -- The query does not hit the event time column. SELECT * FROM tbl_segment_test_2 WHERE b > '2022-09-05 10:24:54+08'; -- The query hits the event time column. SELECT * FROM tbl_segment_test_2 WHERE a = 3 and b > '2022-09-05 10:24:54+08'; SELECT * FROM tbl_segment_test_2 WHERE a > 3 and b < '2022-09-05 10:26:54+08'; SELECT * FROM tbl_segment_test_2 WHERE a > 3 and b > '2022-09-05 10:24:54+08'; -
Syntax supported in all versions:
BEGIN; CREATE TABLE tbl_segment_test_2 ( a int NOT NULL, b timestamptz NOT NULL ); CALL set_table_property('tbl_segment_test_2', 'event_time_column', 'a,b'); COMMIT; INSERT INTO tbl_segment_test_2 VALUES (1,'2022-09-05 10:23:54+08'), (2,'2022-09-05 10:24:54+08'), (3,'2022-09-05 10:25:54+08'), (4,'2022-09-05 10:26:54+08') ; -- The query does not hit the event time column. SELECT * FROM tbl_segment_test_2 WHERE b > '2022-09-05 10:24:54+08'; -- The query hits the event time column. SELECT * FROM tbl_segment_test_2 WHERE a = 3 and b > '2022-09-05 10:24:54+08'; SELECT * FROM tbl_segment_test_2 WHERE a > 3 and b < '2022-09-05 10:26:54+08'; SELECT * FROM tbl_segment_test_2 WHERE a > 3 and b > '2022-09-05 10:24:54+08';
-
Related topics
-
For guidance on choosing the right table properties for your query patterns, see Guide on scenario-specific table creation and tuning.
For details about DDL statements for tables in Hologres, see: