MaxCompute is a serverless, fully managed cloud data warehouse built for large-scale data analytics — from 100 GB to the exabyte (EB) scale. It handles both batch and real-time ingestion, runs SQL and Spark workloads, and integrates natively with Alibaba Cloud's AI, BI, and data governance ecosystem, all without the overhead of managing distributed infrastructure.
Why MaxCompute
Traditional data platforms require you to provision and manage clusters, plan capacity in advance, and handle infrastructure scaling manually. MaxCompute eliminates all of that:
-
No hardware or software to install, configure, or manage
-
No cluster capacity planning — resources scale independently with your workload
-
No compute costs when idle — pay-as-you-go billing only charges for what you use
Storage and compute scale independently, so you can connect all your data assets in one place and eliminate data silos without over-provisioning for either dimension.
What you can build
MaxCompute provides a single platform for the following workloads:
-
Data warehousing and BI: Run SQL-based analytics on datasets at TB, PB, and EB scale. Integrate with Quick BI for dashboards and reports, or connect via Java Database Connectivity (JDBC) to any compatible BI tool.
-
Near real-time analytics: Ingest streaming data directly into the warehouse and run high-concurrency queries at second-level latency. Deep integration with Hologres delivers 10x or greater query acceleration without moving data.
-
Data lake analytics: Query data in OSS or Hadoop Distributed File System (HDFS) directly, using external tables or Apache Spark. Run joint analysis across your data lake and data warehouse in a single service.
-
AI and machine learning: Train models on MaxCompute data using Platform for AI (PAI), run Spark-ML pipelines, or bring in third-party Python machine learning libraries — all within the same compute environment.
-
Data engineering: Build ETL/ELT pipelines with DataWorks, manage workflows, and govern data across projects. Ingest from major streaming sources, including Apache Flink and Apache Kafka, with native connectors.
Core features
Serverless compute
MaxCompute is an out-of-the-box service accessed through APIs. A pre-provisioned shared resource pool handles peak workloads on demand — no cluster setup, no idle capacity costs.
Independent storage and compute scaling
Storage and compute resources scale independently. This lets you handle sudden traffic spikes without over-provisioning, and grow your data assets without being constrained by compute costs.
Columnar storage with 5x compression
The MaxCompute storage engine uses columnar storage, which typically achieves a 5x compression ratio compared to row-based formats. This significantly reduces storage costs at scale.
Unified batch and streaming
MaxCompute supports both batch and real-time data ingestion in a single service. Streaming data written to MaxCompute is available for analysis without a separate pipeline to a different system.
Lakehouse architecture
Map external data in OSS or HDFS to external tables and query it alongside warehouse data in a unified interface. For more information, see Lakehouse of MaxCompute.
SQL and multi-engine support
MaxCompute provides a native SQL compute engine for standard SQL workloads. For Spark and Mars workloads, the CUPID computing platform runs third-party engine tasks with full integration into MaxCompute's storage, permissions, and resource system.
Security and compliance
MaxCompute includes over 20 security features that meet Level 3 standards for classified information security protection. Coverage spans infrastructure, data centers, networks, power supply, platform security, permission management, and privacy protection — combining capabilities from both open-source big data systems and managed databases.
Video introduction
Product architecture
The following figure shows the MaxCompute architecture.
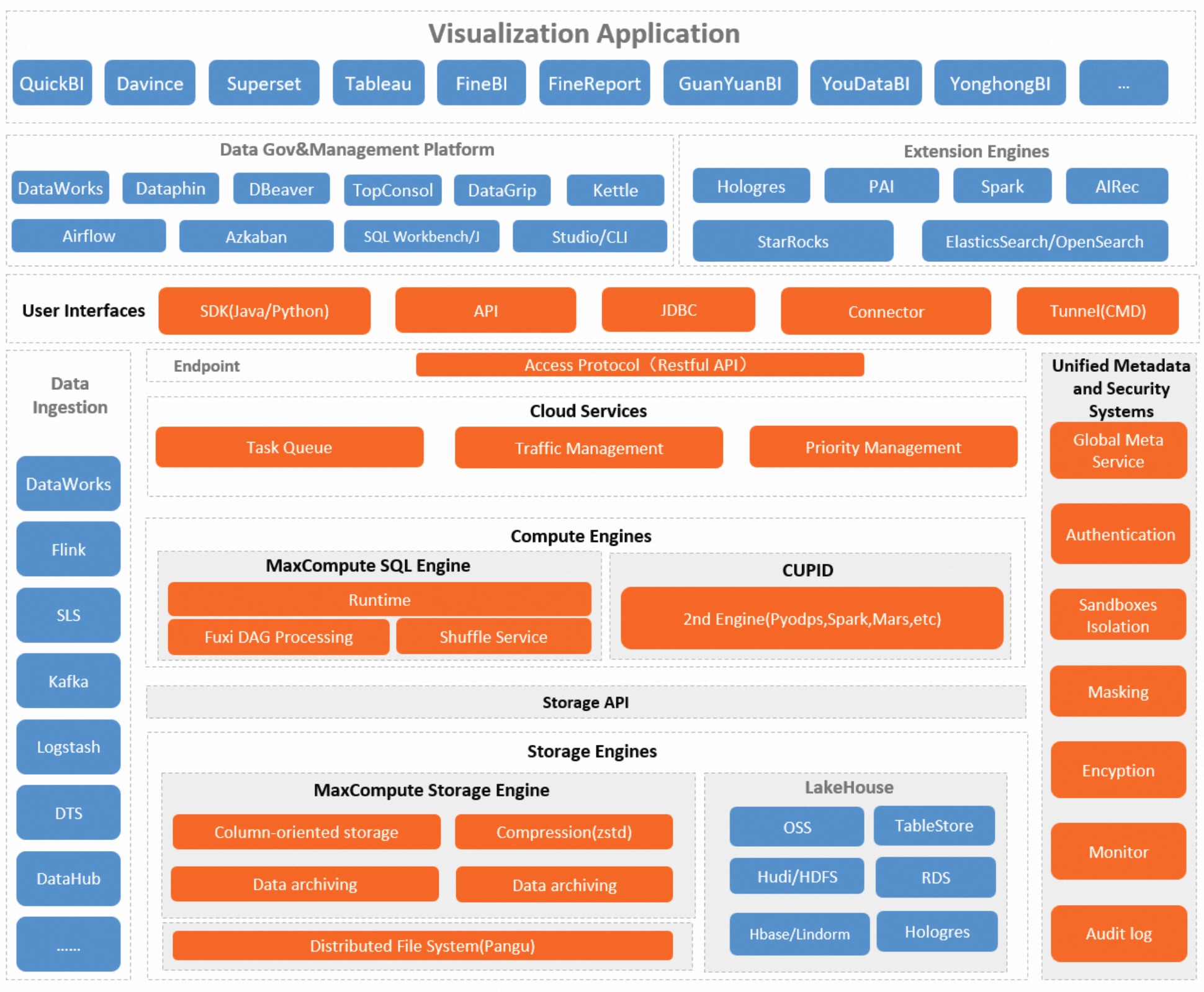
MaxCompute is designed around a layered architecture that separates storage, compute, and service concerns — so each layer can scale and evolve independently.
| Module | Description |
|---|---|
| Storage engine | The MaxCompute storage engine stores tables and resources using columnar storage with a typical 5x compression ratio. External tables provide direct read access to data in OSS, Tablestore, and RDS without copying data into MaxCompute. |
| Compute engine | Two compute engines handle different workload types: the MaxCompute SQL engine runs SQL tasks directly (see Overview of MaxCompute SQL); the CUPID computing platform runs Apache Spark and Mars tasks with full access to MaxCompute storage and permissions. |
| Cloud service layer | Task queues with configurable resource allocations and priorities control how jobs execute. A scheduling system manages compute resource allocation across all queues. Multi-layered data protection — including project-level isolation, access control, and data encryption — is enforced at this layer. |
| Metadata and security | Information Schema provides tenant-level metadata and historical usage logs covering resource consumption, run duration, and data processed. This supports job optimization and capacity planning. A comprehensive security system adds access control, data encryption, and dynamic data masking. See Security features. |
| User interfaces | Tunnel — a data transmission service with shared and dedicated cluster options. Restful API and SDKs — Restful API, SDK for Java, and PyODPS. [JDBC driver](https://www.alibabacloud.com/help/en/document_detail/143408.html#concept-2338749) — for connecting standard BI and SQL tools. Connectors — for Apache Flink, Apache Spark, and Apache Kafka. |
| TopConsole | The MaxCompute console for project management, quota management, and tenant management. Includes job operations and maintenance (O&M), resource monitoring, materialized views, and cost analytics and optimization. See Resource management and use. |
| Data ecosystem support | Deep integration with DataWorks for one-stop data development, analytics, and governance. Also supports data lake connectivity, data integration, and development with third-party engines. |
Ecosystem integrations
MaxCompute integrates with the following Alibaba Cloud services:
-
DataWorks — Build and schedule ETL/ELT pipelines, manage data governance policies, and develop SQL or Spark jobs in a web-based IDE, all with native MaxCompute project support.
-
Platform for AI (PAI) — Train machine learning models directly on MaxCompute data using built-in algorithm components, without exporting data to a separate environment.
-
Hologres — Deeply integrates with MaxCompute as a real-time data warehouse, supporting queries on associated external tables and direct reads from the storage layer, achieving over 5x higher query efficiency than other external table types. Accelerate interactive queries on MaxCompute data with 10x or greater performance. Hologres also supports batch import of MaxCompute metadata, eliminating the need to manually create external tables.
-
Quick BIFor more information about the Alibaba Cloud services that integrate with MaxCompute, see Supported Alibaba Cloud services. — Create reports and interactive dashboards directly on MaxCompute data with no data movement.
Use cases
MaxCompute has been validated at scale within Alibaba Group and is suited for:
-
Data warehousing and Business Intelligence (BI) analytics for large internet companies
-
Website log analysis
-
E-commerce transaction analysis
-
User behavior and interest analysis
Product advantages
-
Easy to use: High-performance storage and compute optimized for data warehousing. Pre-integrated with services and supports standard SQL for simple development. Built-in management and security capabilities. Fully managed with a pay-as-you-go model; you incur no compute costs when not in use.
-
Elasticity that matches business growth: With decoupled storage and compute, resources scale independently and dynamically. This on-demand elasticity meets sudden business growth without upfront capacity planning.
-
Support for various analytics scenarios: Supports an open data ecosystem, providing a unified platform for data warehousing, BI, Near-real-time Analytics, Data Lake Analysis, and Machine Learning.For more information about its development history, product awards, and customer use cases, see Development history and Customer use cases.
-
Open platform: Provides open APIs and a rich ecosystem, offering flexibility for data and application migration and custom development. Flexibly combines with open-source and commercial products like Airflow and Tableau to build a wide range of data applications.