This guide walks you through submitting and monitoring your first reinforcement learning (RL) training job using an end-to-end example.
RL training workflow
The RL training process consists of five steps, from environment setup to model deployment:
-
Set up the environment — Install the offline SDK, get an API key, and complete RL service authorization.
-
Prepare data and code — Download the demo package to understand the data format and project structure.
-
Submit the training job — Run the demo to deploy functions, upload data, and submit the job in one step.
-
Monitor training status — View the training status, logs, and reward trends.
-
Publish and deploy the model — Publish a checkpoint to "My Models" and deploy it for API access.
How RL training works
RL training continuously improves the model's capabilities through a "generate-score-optimize" loop. The data flow for each training round is as follows:
Training data (user questions + reference answers)
│
▼
Rollout: The model generates candidate results based on the current policy.
│
▼
Reward: Scores the result on a scale of 0 to 1 by comparing it with the reference answer. This step can be merged with the rollout.
│
▼
Policy update: Reinforce high-scoring policies and suppress low-scoring ones based on the reward signal.
│
▼
Iteration: Resample using the updated model to improve quality in each round.
Supported models
|
Model name |
Model code |
MoE |
Recommended MTUs |
|
Qwen3.5-9B |
qwen3.5-9b |
No |
Type IV model training unit * 24 |
|
Qwen3.5-35B-A3B |
qwen3.5-35b-a3b |
Yes |
- |
Training unit pricing
|
Billing method |
Description |
Billing formula |
|
Model training unit · subscription |
Purchase dedicated model training units on a monthly subscription for faster, queue-free training. The minimum billing unit is one hour. If you cancel your subscription early, you are charged at 1.2 times the hourly rate. To purchase or manage subscription training units, go to the Model Fine-tuning console and click Manage Training Resources. |
|
|
Model training unit · pay-as-you-go |
Use dedicated training resources for faster, queue-free training. You are billed for the actual duration of use. This option is enabled automatically when you create a job and does not require a pre-purchase. |
|
|
Training unit type |
Billing method |
Unit price |
Minimum billing unit |
|
Type IV (MTU4) |
subscription (monthly) |
CNY 19,914.00/month/instance |
1 hour |
|
pay-as-you-go (per minute) |
CNY 41.00/hour/instance |
1 minute |
Contact your account manager for rules on subscription scaling, renewal, and cancellation, or for specific model training unit (MTU) capacity calculations.
Environment setup
RL training only supports billing based on model training units (MTUs). Billing by token is not supported.
Follow these steps to configure your environment:
-
Get an API key: Obtain a DashScope API key from the Model Studio console.
-
Authorize the RL service: On the Model Fine-tuning page in the Model Studio console, complete the one-click authorization. The first time you use RL training, the console prompts you to authorize Alibaba Cloud OpenTelemetry, Function Compute (FC), and Log Service (SLS).
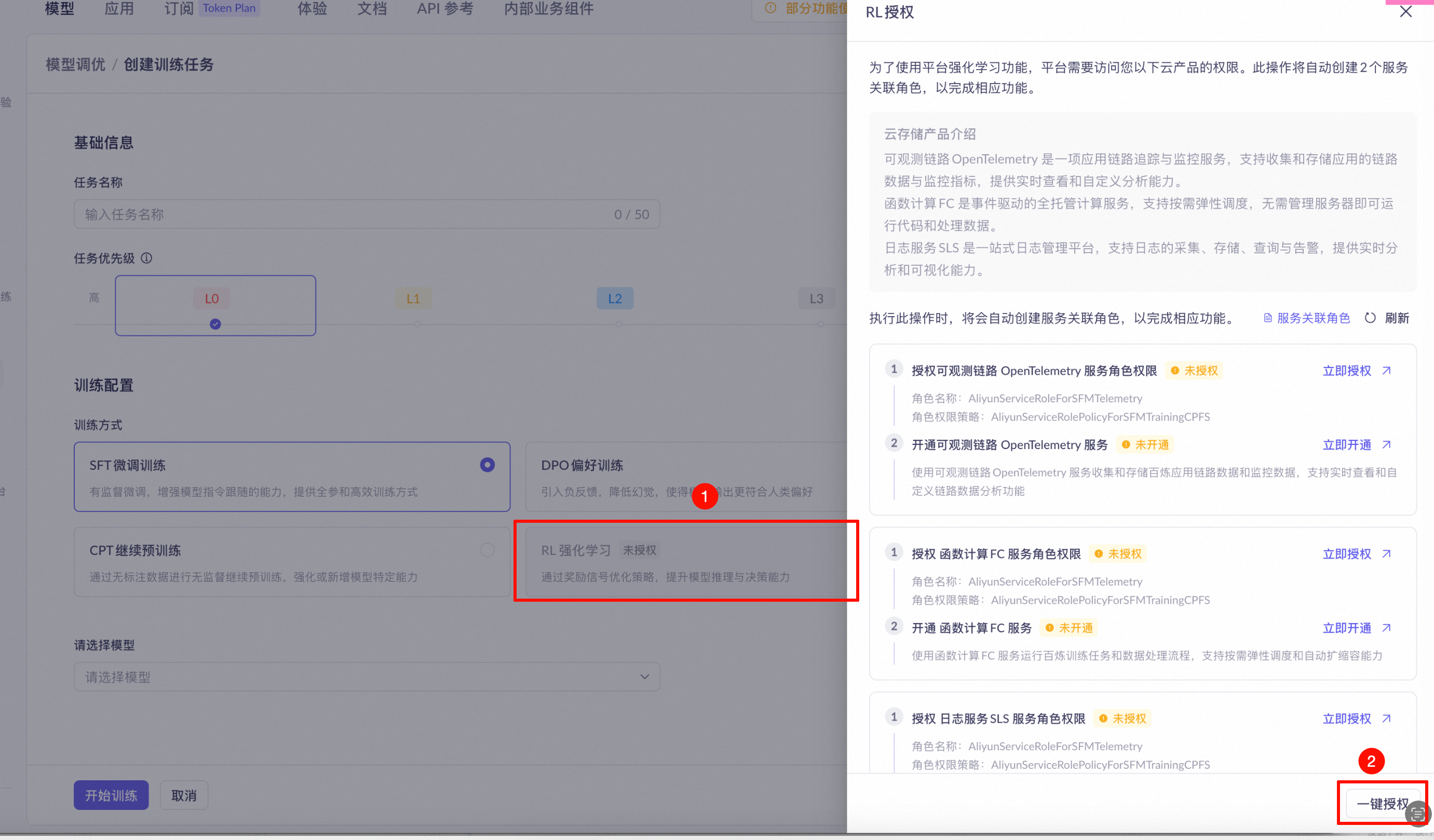
-
Set environment variables: The local SDK reads the following variables to control packaging, uploading, and deployment:
-
DASHSCOPE_API_KEY (Required): Your API key.
-
FC_PYPI_LIB (Required): Specifies the offline dashscope package to be installed when the FC container starts. The SDK automatically injects this variable as
FC_SDK_PACKAGEduring deployment, so you do not need to install it manually in FC. The .whl filename must exactly match this variable and be placed in the project's root directory. -
LOG_LEVEL (Optional, default:
info): Set todebugto output complete request/response information, which is useful for troubleshooting submission failures.
export DASHSCOPE_API_KEY="sk-your-api-key" export FC_PYPI_LIB="dashscope-1.25.16-py3-none-any.whl" export LOG_LEVEL="info" -
Data and code preparation
-
Download the demo package agentic-rl-example.zip. (This demo requires a minimum of 24 Type IV model training units to run.)
-
After downloading the demo package, install the DashScope SDK (requires Python >= 3.10). Follow the instructions in the demo package to install the required dependencies:
pip install dashscope-1.25.16-py3-none-any.whl # Install the local .whl package # Or use the PyPI source: pip install dashscope==1.25.16
The project has the following structure:
agentic-rl-example/
├── submit_job.py ← Main entry point for submitting the training job
├── test_functions.py ← Function registration and remote testing
├── config.yaml ← Optional YAML configuration file
├── dashscope-1.25.16-py3-none-any.whl ← Offline SDK installation package
├── requirements.txt ← List of dependencies
├── data/
│ ├── calc_train.jsonl ← Training data (full version)
│ ├── calc_train_min.jsonl ← Training data (demo uses the minimal version by default)
│ ├── calc_validation.jsonl ← Validation data (full version)
│ └── calc_validation_min.jsonl ← Validation data (demo uses the minimal version by default)
├── functions/
│ ├── __init__.py
│ ├── rollout/
│ │ ├── rollout.py ← Rollout function (LangGraph + MCP tool)
│ │ └── rollout_only.py ← Rollout function (simple version, with trajectory example)
│ └── reward/
│ ├── reward.py ← Reward function (basic scoring)
│ ├── reward_decorator.py ← Reward function (decorator style)
│ └── group_reward.py ← Reward function (group scoring)
└── resources/
├── rollout_input.json ← Rollout test input
├── reward_input.json ← Reward test input
├── reward_decorator_input.json ← Decorator reward test input
└── group_reward_input.json ← Group reward test input
Demo
This demo implements a calculation agent:
-
Rollout function: Calls the model being trained, using a calculator tool to answer math problems.
-
Reward function: Compares the model's output with the reference answer to determine if the response is correct and assigns a score.
The rollout function in the demo uses LangGraph to orchestrate the agent workflow and calls the calculator tool via the Model Context Protocol (MCP), a tool-calling protocol for LLMs.
To write your own rollout and reward functions, see the Reinforcement Learning Development Guide.
Data format
The training data is in JSONL format, with each line being a JSON object containing messages and rollout_extra fields:
{"messages": [{"content": "Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?", "role": "user"}], "rollout_extra": {"solution": "72"}}
-
messages: The user's question, in a format consistent with ChatML. -
rollout_extra: Contains the reference answer or other business data, which is passed to the reward function for scoring. You can customize the fields in this object.
Data in rollout_extra passes through to RolloutInput.rollout_extra in the rollout function and RewardInput.agent_output.rollout_extra in the reward function, making it available for your scoring logic. This field supports custom keys and is not limited to the solution key used in the example.
Recommended dataset size
-
Getting started: A few dozen to a few hundred entries are enough to validate your approach (the data volume must be greater than the
batch_size). -
Production training: A larger dataset generally yields better results. Large datasets also support a larger batch size, which helps improve training stability.
Job submission
The demo already includes the rollout and reward functions. Run the following command to deploy the functions, upload data, and submit the training job in a single step:
python submit_job.pyYou can also submit training jobs via a configuration file or the CLI (dashscope rl run). For detailed explanations of all three submission methods and their fields, see Training Configuration — Submission and Configuration.
Getting started tips
After your first successful run, follow these four practices:
-
Start with a minimal dataset: The demo defaults to using
calc_train_min.jsonlandn_epochs=1. Run this once to confirm the entire pipeline works before switching to the full dataset. This helps you avoid wasting 24 MTUs on a large dataset only to discover a configuration error. -
Do not change the hyperparameters initially: The 13 hyperparameters listed above are the recommended starting point for qwen3.5-9b. Do not adjust them for your first training run. When you do make adjustments, change only one variable at a time (like the learning rate or batch size) and run for at least
eval_steps × 3steps before evaluating the trend. -
Focus on one core metric: On the Metrics tab, watch
critic/rewards/mean. A steady increase indicates the model is learning. If it stagnates or decreases, stop the job and investigate instead of letting it run idly. -
If the job fails, check the logs first: If a job status is FAILED, go to the Logs tab and check the error messages at the end, or use the SDK to pull the logs:
AgenticRL.logs(job_id="ft-xxx", lines=100). Configuration or dependency errors are usually easy to spot.
For algorithm selection, hyperparameter starting points, and tuning decisions, see "Training Configuration — Submission and Configuration." For reward function design principles and defense against hacking, see the "Reinforcement Learning Development Guide." For guidance on attributing the cause of abnormal metrics, see "Observability Configuration and Metric Reference for Reinforcement Learning."
Training monitoring and analysis
After you submit the job, the job_id returned by run() is the unique identifier for querying the training status. Training typically takes from tens of minutes to several hours, depending on the dataset size and model.
In the Model Studio console, go to the Model Fine-tuning page and click a job to open its details page, which contains the following five tabs:
|
Tab |
Purpose |
Main content |
|
Details |
Job metadata |
Job ID, status, base model, training method, start/end times, data configuration |
|
Trajectory |
Agent behavior replay |
Complete dialogue process, reward analysis (across step, sample, and trajectory dimensions), and tool calling details |
|
Metrics |
Training health |
13 groups of metric charts (actor, critic, trajectory, trace, timing, perf, fully_async, etc.), including user-defined metrics |
|
Logs |
Runtime troubleshooting |
stdout/stderr from the training process, used to locate the cause of errors when a job fails |
|
Output |
Model assets |
List of checkpoints and their publishing status. You can publish a checkpoint to "My Models" for deployment and use. |
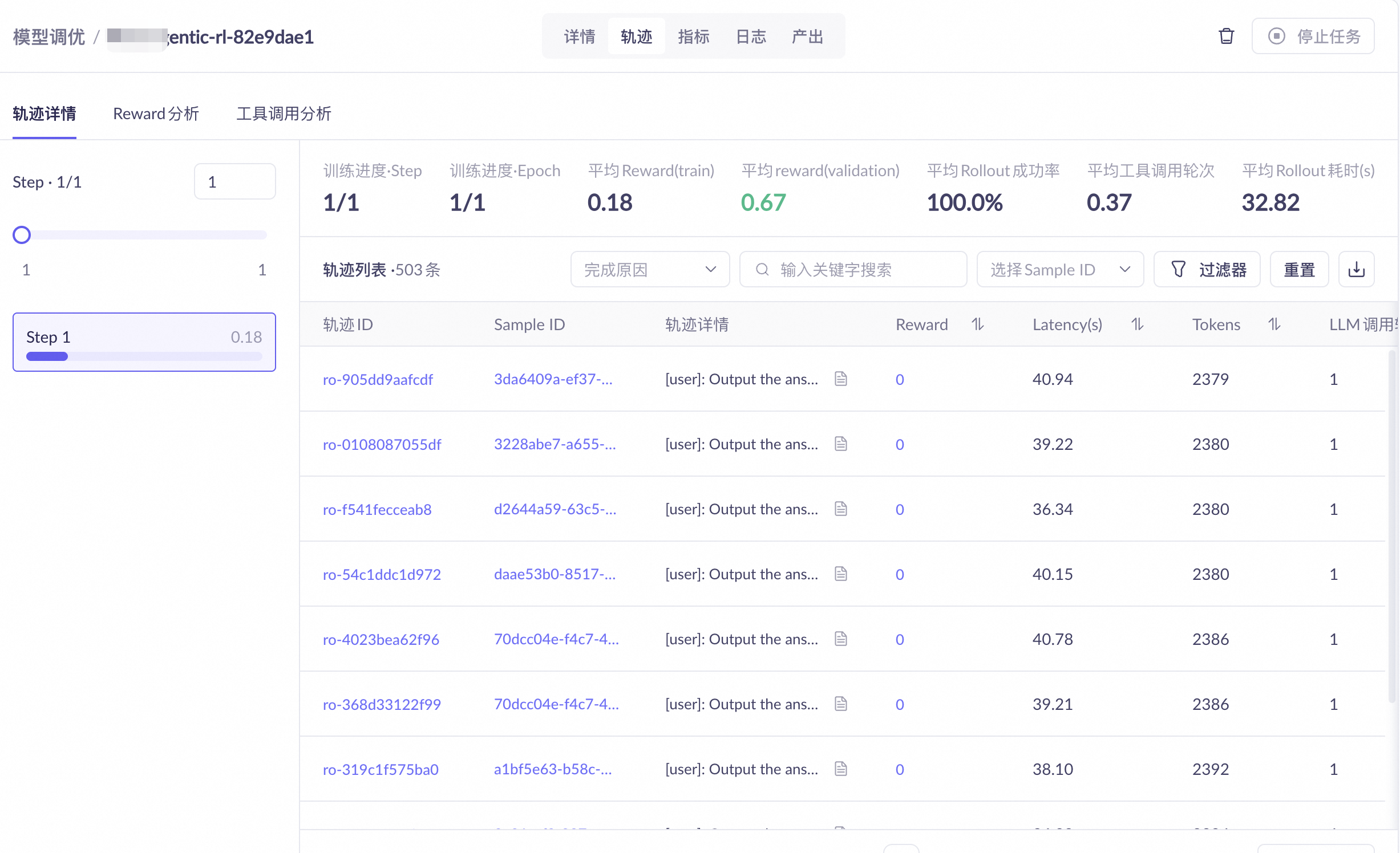
For a detailed description of each tab, see Observability Configuration for Reinforcement Learning.
Model publishing and deployment
When training is complete, the final checkpoint is automatically published to My Models. To publish an intermediate checkpoint, go to the Model Fine-tuning > Output page in the Model Studio console and do so manually. For details, see Model Fine-tuning Console (Model Studio documentation, online only).
After a model is published, you can deploy it from the My Models page. Once deployed, you can call the model via an API. For details, see Model Deployment (Model Studio documentation, online only).
Next steps
-
Learn the full details of function development → Reinforcement Learning Development Guide
-
Learn about training configuration and monitoring → Reinforcement Learning Training Configuration — Submission and Configuration
-
Reference for training metrics → Observability Configuration and Metric Reference for Reinforcement Learning
-
Learn about observability configuration and trajectory viewing → Observability Configuration and Metric Reference for Reinforcement Learning