By default, vector retrieval scans only 1% of your documents. When a filter condition matches very few documents, that 1% scan often misses them entirely — returning sparse results or none at all. Filter optimization solves this by using inverted indexes to locate matching documents first, then computing vector similarity only on those documents.
How it works
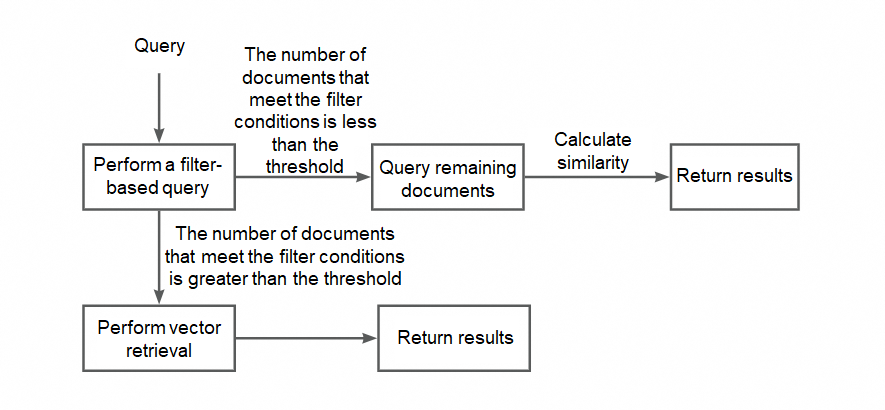
When filter optimization is enabled, the system runs a pre-query using inverted indexes instead of scanning a fixed percentage of vectors. The decision logic works as follows:
The system rewrites filter conditions as inverted index queries (see Filter expression support) and fetches up to
prefetch_sizeresults (default: 500).Fewer than `prefetch_size` results returned — the matching document set is small. The system calculates vector similarity directly on those results.
`prefetch_size` or more results returned — the system checks whether the document ID of the last result represents greater than or equal to
prefetch_coverage(default: 0.8) of the total document set.At or above the threshold: Few documents match the filter. The system fetches the remaining matches, then calculates vector similarity.
Below the threshold: Many documents match. The system falls back to standard vector retrieval.
Example
You have 1,000,000 documents, 600 of which match count = 1. With prefetch_size = 500 and prefetch_coverage = 0.8:
Pre-query: The system fetches 600 documents using
count = 1as an inverted query condition. Because 600 > 500, proportion calculation runs.Proportion check: The system checks whether the 500th result's document ID meets or exceeds 80% of all document IDs. If it does, the system fetches the remaining 100 documents and calculates vector similarity across all 600. If it does not, standard vector retrieval runs.
Enable filter optimization
Set vector_service.search.enable_filter_optimize to true in searchParams:
{
"vector": [0.1, 0.2, 0.3],
"topK": 10,
"namespace": "123",
"filter": "count = 1 AND tag=\"text\"",
"searchParams": "{\"vector_service.search.enable_filter_optimize\":true}"
}Note: Disable filter optimization when most documents pass the filter condition. In that case, the pre-query overhead increases query time without improving recall. The default value is false (disabled).Parameters
| Parameter | Default | Description |
|---|---|---|
vector_service.search.enable_filter_optimize | false | Enables filter optimization. Set to true to enable. |
vector_service.search.filter_optimize_prefetch_size | 500 | Number of results to fetch in the pre-query phase. |
vector_service.search.filter_optimize_prefetch_coverage | 0.8 | Proportion threshold. If the last prefetched result's document ID represents greater than or equal to this proportion of the total document set, the system treats the filter as highly selective and uses the inverted index results. |
Filter expression support
The system builds single-field inverted indexes for all fields except text fields. When filter optimization runs, it rewrites filter conditions as inverted index queries where possible.
| Expression | Rewritable | Result |
|---|---|---|
attrName = constValue (indexed field, constant value) | Yes | attrName:'constValue' |
AND — both sides rewritable | Yes | QUERY: a:'x' AND b:'y' / FILTER: None |
AND — one side not rewritable | Partial | QUERY: a:'x' / FILTER: b > 1 |
OR — both sides rewritable | Yes | QUERY: a:'x' OR b:'y' / FILTER: None |
OR — one side not rewritable | No | Rewriting fails; standard vector retrieval runs |
in/contain (in(tag, 'text|image')) | Yes | QUERY: tag:'text' OR tag:'image' |
range | No | Not supported in the current version |
Examples
AND — fully rewritable
count = 1 AND tag = "text"Rewrites to:
QUERY: count:'1' AND tag:'text'
FILTER: NoneAND — partially rewritable
tag = 'text' AND count > 1Rewrites to:
QUERY: tag:'text'
FILTER: count > 1OR — fully rewritable
count = 1 OR tag = "text"Rewrites to:
QUERY: count:'1' OR tag:'text'
FILTER: NoneOR — partially rewritable (rewriting fails)
tag = 'text' OR count > 1Rewriting fails. Standard vector retrieval runs.
in/contain
in(tag, 'text|image')Rewrites to:
QUERY: tag:'text' OR tag:'image'