What is OpenLake
Overview
Alibaba Cloud OpenLake is an open lakehouse platform for big data, search, and artificial intelligence (AI). Built on Data Lake Formation (DLF), it unifies structured, semi-structured, unstructured, and vector data under one metadata catalog. This Agentic Data architecture lets one copy of data serve multiple engines with global search and end-to-end governance.
OpenLake supports open table formats such as Paimon, Iceberg, and Lance. It covers the full workflow from data ingestion, feature engineering, and vectorization to retrieval-augmented generation (RAG), model training, and inference — delivering high-performance, low-cost, highly available, and easy-to-manage multimodal data infrastructure.
OpenLake serves industries such as Internet, finance, retail, manufacturing, education, and autonomous driving that need to process multimodal data and build AI-native applications.

Benefits
Open standards that eliminate data silos
-
Compatible with open table formats (Paimon, Iceberg, Lance) and file standards (Parquet, ORC, Avro, CSV).
-
Integrates with Spark, Flink, Trino, StarRocks, Hologres, and MaxCompute, eliminating data migration and format conversion costs.
-
DLF Omni Catalog unifies five data types — structured, semi-structured, unstructured, vector, and streaming — so you ingest once and use anywhere.
High-performance multi-engine collaboration
-
Spark, Flink, StarRocks, Hologres, and MaxCompute access the same lake data without redundant copies.
-
The DLF metadata service ensures consistent permissions, schema sync, and transaction isolation across engines.
-
Batch, streaming, interactive, and AI workloads share one storage layer, improving resource utilization and efficiency.
-
Supports high-concurrency, low-latency mixed workloads that combine T+1 batch processing with second-level real-time analytics.
Unified development and governance
-
OpenLake Studio integrates with DataWorks to provide Notebook, SQL IDE, and visual scheduling in one interface.
-
Centralized metadata, permissions, lineage, orchestration, and quality monitoring enable governance from day one.
-
Large-scale, high-concurrency task scheduling ensures enterprise-grade SLAs and stability.
-
The full data pipeline is traceable, auditable, and supports rollbacks for compliance.
Data, search, and AI integration
-
Combines structured tables, unstructured files (images, audio, video, documents), and vector data in one multimodal lakehouse.
-
Natively supports SQL, full-text search (OpenSearch, Elasticsearch), and vector search (Milvus, PgVector).
-
Provides a searchable, governable data pipeline for large language model (LLM) RAG and intelligent agents.
-
Streamlines the workflow from data ingestion, feature engineering, and vectorization to retrieval augmentation and model inference, accelerating AI application delivery.
Core features
|
Feature |
Description |
Documentation |
|
Unified metadata and table management |
Uses DLF to provide a unified catalog for Paimon, Iceberg, Lance, Parquet, and other formats. |
|
|
Storage cost optimization |
Reduces storage costs using OSS intelligent tiering, compression, and lifecycle policies. |
|
|
Real-time Integration of Data Lakes and Streams |
Flink, Streaming Storage Fluss, and DLF enable data ingestion in seconds and data visibility in minutes. |
What is Streaming Storage Fluss, What is Realtime Compute for Apache Flink |
|
Enterprise-grade high-performance engines |
Integrates Serverless Spark, Flink, Hologres, MaxCompute, and other cloud-native engines. |
What is EMR Serverless Spark, What is Realtime Compute for Apache Flink, What is Hologres, What is MaxCompute |
|
Collaborative development for big data and AI |
OpenLake Studio with Notebook, SQL, and visual scheduling. |
|
|
Agent and Copilot integration |
OpenLake Agent and MCP protocol enable multimodal intelligent agents to access the lakehouse directly. |
Architecture solutions
Solution 1: Classic lakehouse architecture (Serverless Spark + StarRocks + DLF)
-
Scenarios: T+1 batch processing for cost-effective, fully managed analytics: reports, business intelligence, and user personas.
-
Components: EMR Serverless Spark (batch processing) + StarRocks (sub-second queries) + DLF (unified metadata).
-
Alternative solutions: AWS Redshift + Glue, Databricks (batch processing), Hive + Presto.
-
Benefits: 30%+ cost reduction, 3–5x query performance, fully managed.
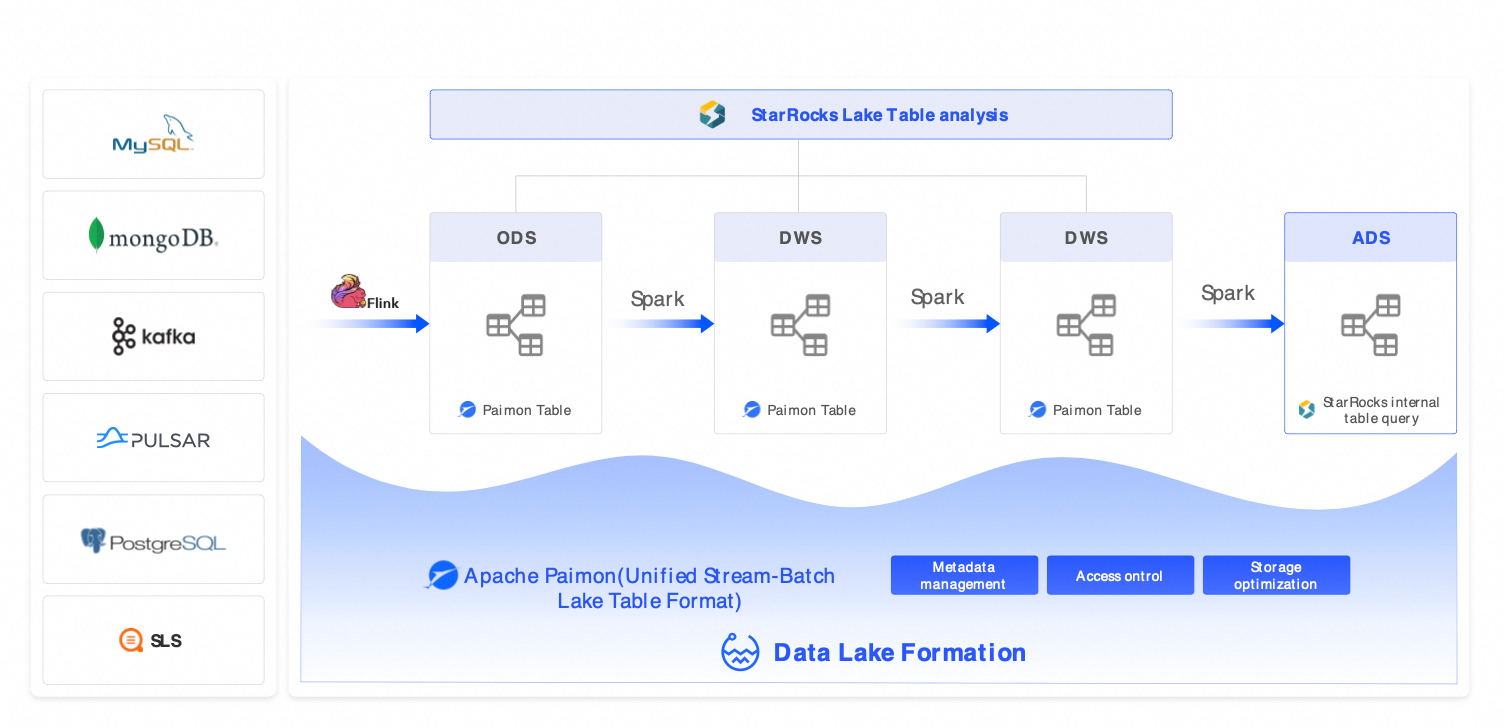
Solution 2: Streaming lakehouse architecture (Flink + Hologres + DLF)
-
Scenarios: Near-real-time analytics with second-to-minute latency: risk control, ad monitoring, and IoT monitoring.
-
Components: Flink (streaming ETL) + Hologres (real-time serving) + DLF (cross-engine collaboration).
-
Alternative solutions: Kafka + ClickHouse + Hive, AWS Kinesis + Redshift.
-
Benefits: End-to-end data visibility within 10 minutes, sub-second query latency.

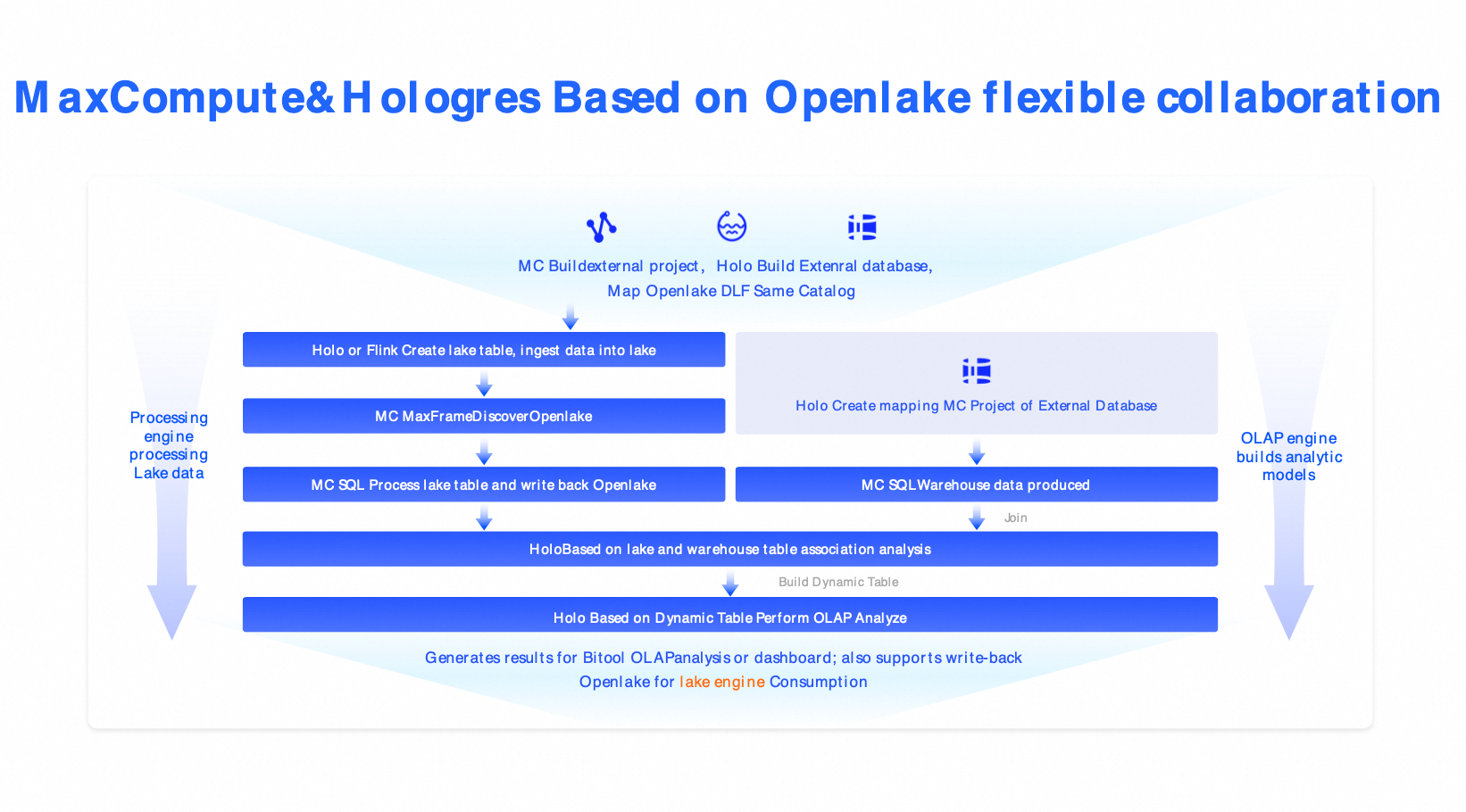
Solution 3: Cloud-native lakehouse architecture (MaxCompute + Hologres + DLF)
-
Scenarios: For finance, government, and other industries with strict security, compliance, and scale requirements.
-
Components: MaxCompute (petabyte-scale batch processing) + Hologres (millisecond writes) + DLF (governance).
-
Alternative solutions: Snowflake, Azure Synapse, Databricks commercial editions.
-
Benefits: Enterprise-grade security, elastic scaling, RPO=0, and RTO < 30 minutes.
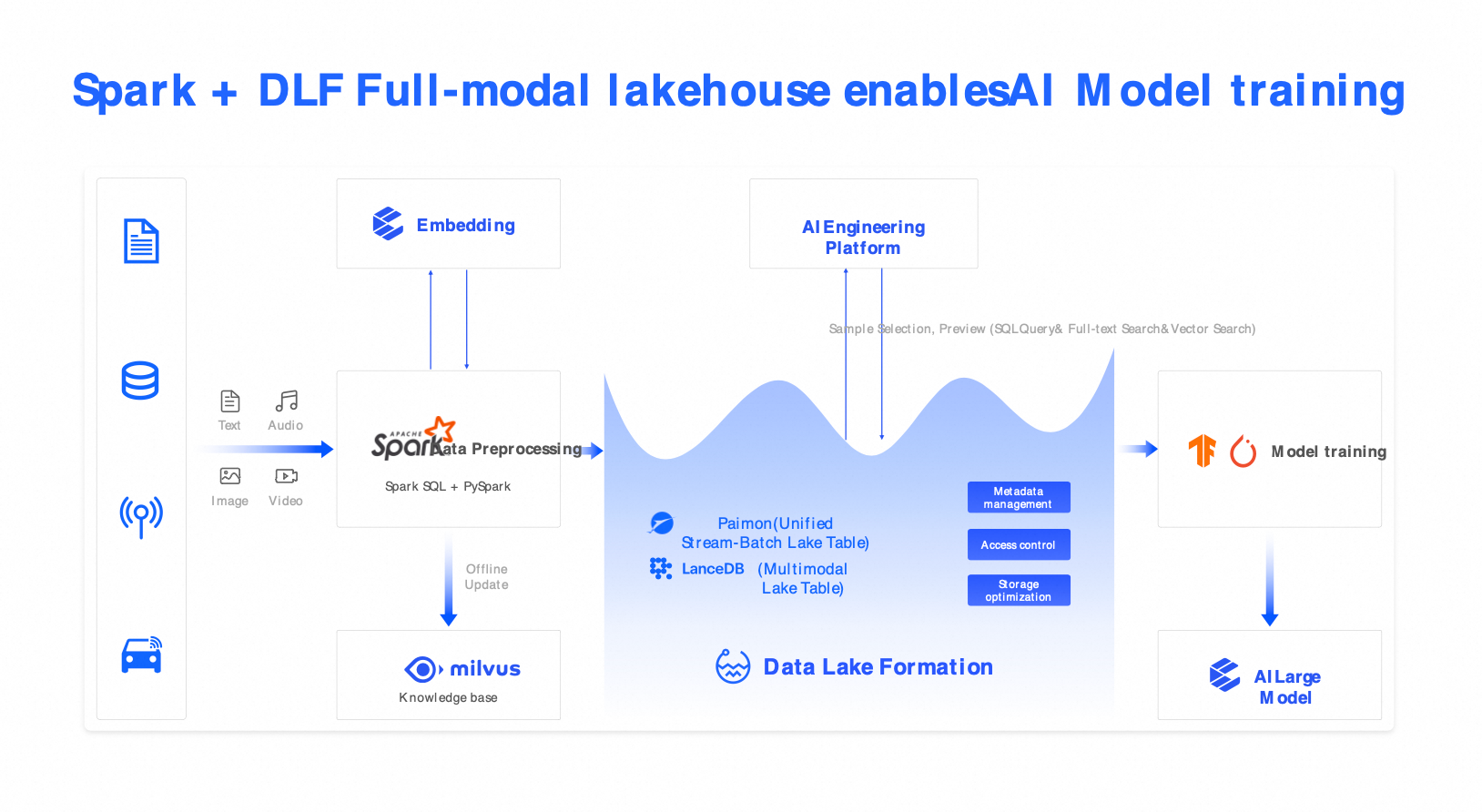
Solution 4: Omni-modal vector lake (Spark + Milvus + DLF)
-
Scenarios: AI training, multimodal semantic search, RAG, intelligent customer service, and autonomous driving perception data management.
-
Components: Spark (multimodal pre-processing), Milvus (vector search), and DLF (unified catalog).
-
Capabilities: Hybrid search across text, images, audio, and video with combined SQL and vector queries.
-
Benefits: 5x sample selection efficiency and high-quality LLM fine-tuning.
-
Use cases: AI training, multimodal search, RAG, customer service, and autonomous driving.