Evaluate your application flow's performance before production deployment. LangStudio scores applications across multiple dimensions using preset or custom evaluation templates.
Overview
To evaluate an application flow, configure an evaluation dataset, map input fields, and select an evaluation template. The system batch-processes each dataset row through your application, scores each output against auxiliary fields, and aggregates the results.

Before you begin
-
Create and debug an application flow. Develop an application flow.
-
Prepare an evaluation dataset in JSONL format and upload it to OSS. Example:
{"history":[],"query": "Describe the perilous majesty of Mount Hua", "reference": "Mount Hua stands alone, soaring to the clouds; \nSheer cliffs cut the sky, with rugged, handsome crags. \nGreen pines and bamboo vie for beauty on the cliffs; \nMonkeys cry and eagles fly, lit by frosty swords of light. \n\nPerilous peaks like scissors, jagged swords pointing to the sky; \nNarrow paths on steep slopes, where vines are the only way. \nWind and mist intertwine, as clouds emerge from caves; \nA deep fairyland, with a heavenly ladder hard to climb. \n\nJagged ridges cross, like a surging dragon's spine; \nDangerous paths lead onward, twisting toward the heavens. \nFrom lonely pine tops, eagles strike the vast sky; \nAt the summit of Mount Hua, a majestic and heroic sight.", "contexts": ["Mount Hua is one of the Five Great Mountains of China.", "Mount Hua is famous for its precipitous cliffs."]} {"history":[],"query": "Can you list 5 rare metals? Please rank them by global demand.", "reference": "Rare metals are metallic elements that are scarce in the Earth's crust, unevenly distributed, or difficult to mine. They play a crucial role in high-tech fields and emerging industries. The ranking of global demand can change with time and technological progress, but the following are some rare metals that are typically in high demand. This list is not necessarily ranked by absolute demand, as that can vary at different times.\n\n1. **Cobalt (Co)** - Cobalt is a key component of lithium-ion batteries, especially in electric vehicles and portable electronics. It is also used to manufacture heat-resistant alloys, hard alloys, and catalysts.\n\n2. **Neodymium (Nd)** - Neodymium is a rare-earth metal mainly used to produce strong magnets, such as high-performance permanent magnets. These magnets are widely used in computer hard drives, wind turbines, and the drive motors of electric vehicles.\n\n3. **Lithium (Li)** - Lithium is primarily used to manufacture lithium batteries. As the demand for electric vehicles and portable electronic devices increases, the demand for lithium is rising rapidly.\n\n4. **Silver (Ag)** - Although silver is not as rare as the metals listed above, its industrial demand is huge. It is mainly used in electronics, solar panels, jewelry, and currency manufacturing.\n\n5. **Ruthenium (Ru)** - Ruthenium is a rare precious metal widely used for data storage in hard disk drives and large-capacity servers. It is also used in catalysts and electrochemical cells.\n\nThe demand for these metals is influenced by many factors, such as the global economy, technological development, and policy support. Moreover, as time passes and markets change, other rare metals such as tantalum, indium, rhenium, and other rare-earth metals may also appear on the list of most in-demand rare metals.", "contexts": ["Rare metals are metals with low abundance in the Earth's crust that are complex to mine and extract.", "Lithium (Li): Used in battery manufacturing.", "Cobalt (Co): Used in high-performance alloys and battery manufacturing."]}Sample file: langstudio_eval_demo.jsonl
-
Create the LLM connections required for the evaluation. Connection configuration.
Note: Some evaluation templates require a judge model. Configure the corresponding LLM connections before using these templates.
Billing
Application flow evaluation uses OSS for dataset storage and PAI-DLC for running offline tasks. You are charged for both resources. OSS Billing. Billing of Deep Learning Containers (DLC).
Create an evaluation task
After debugging your application, click Evaluation in the upper-right corner to create an evaluation task.

Key parameters:
|
Parameter |
Description |
|
Evaluation dataset |
|
|
OSS file |
Select a JSONL file from OSS as your evaluation dataset. The dataset must contain a |
|
Application flow input mapping |
|
|
question/chat_history |
Map the application's input fields to dataset columns. Note: The evaluation task runs your application for inference before scoring results. Select the input fields your application requires.
|
|
Evaluation configuration |
|
|
Preset template evaluation |
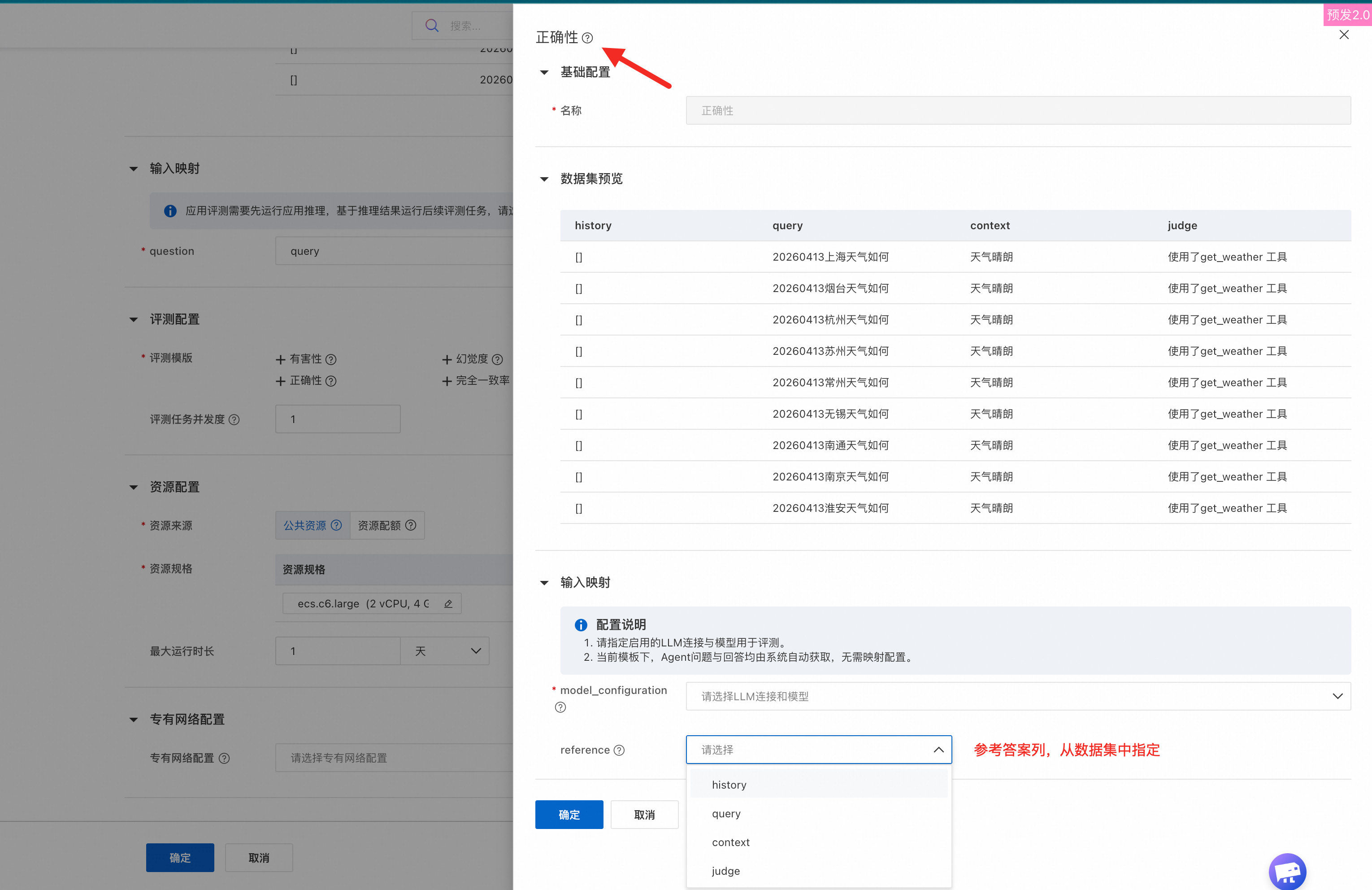
Multiple preset templates are available. Selecting multiple templates aggregates results on the task details page. The following example uses Answer Correctness Evaluation:
Key parameters:
|
|
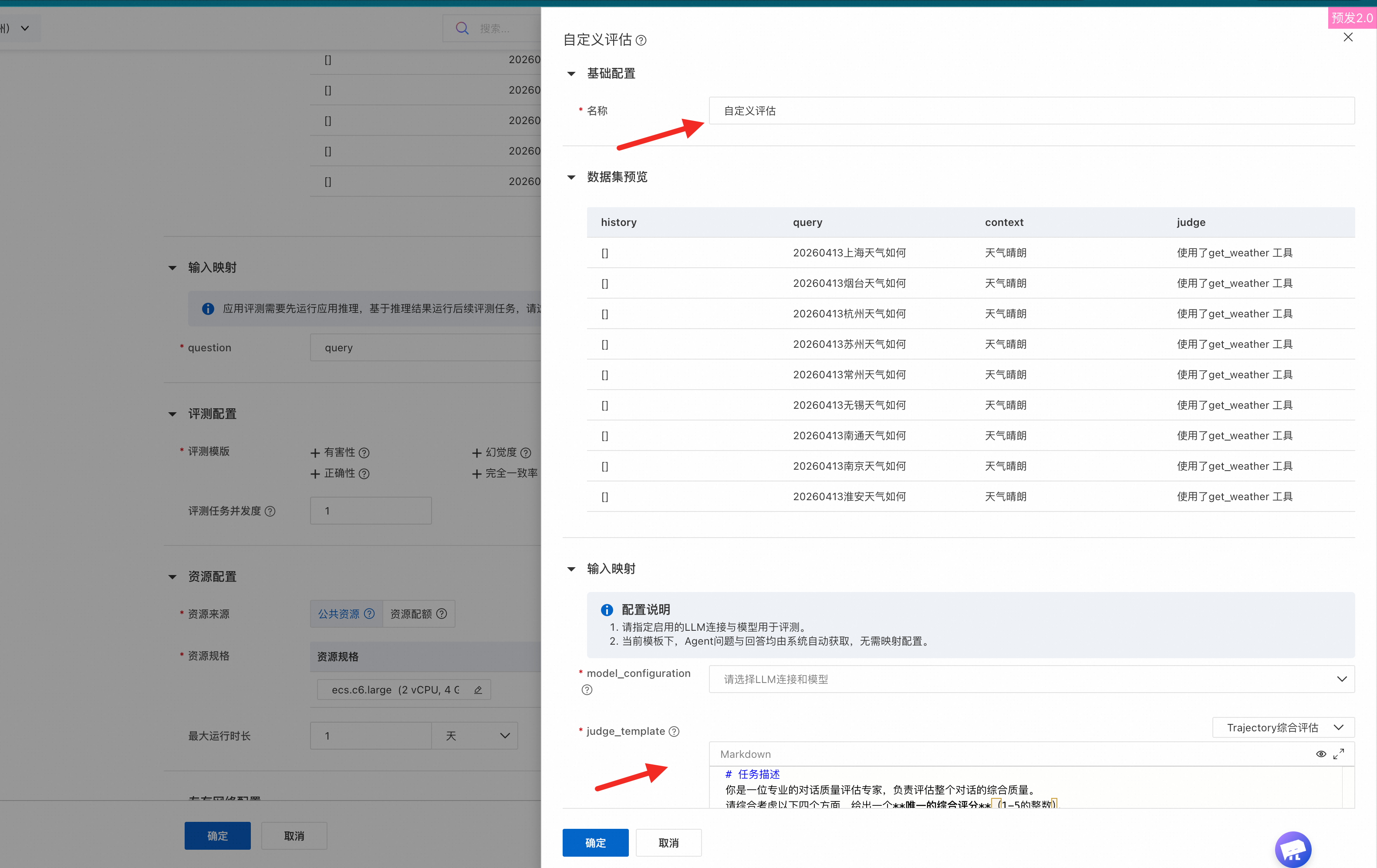
Custom evaluation |
Create a custom evaluation with a user-defined prompt template.
|
|
Resource configuration: Used for scheduling the evaluation task. Select CPU resources based on task complexity. |
|

View evaluation results
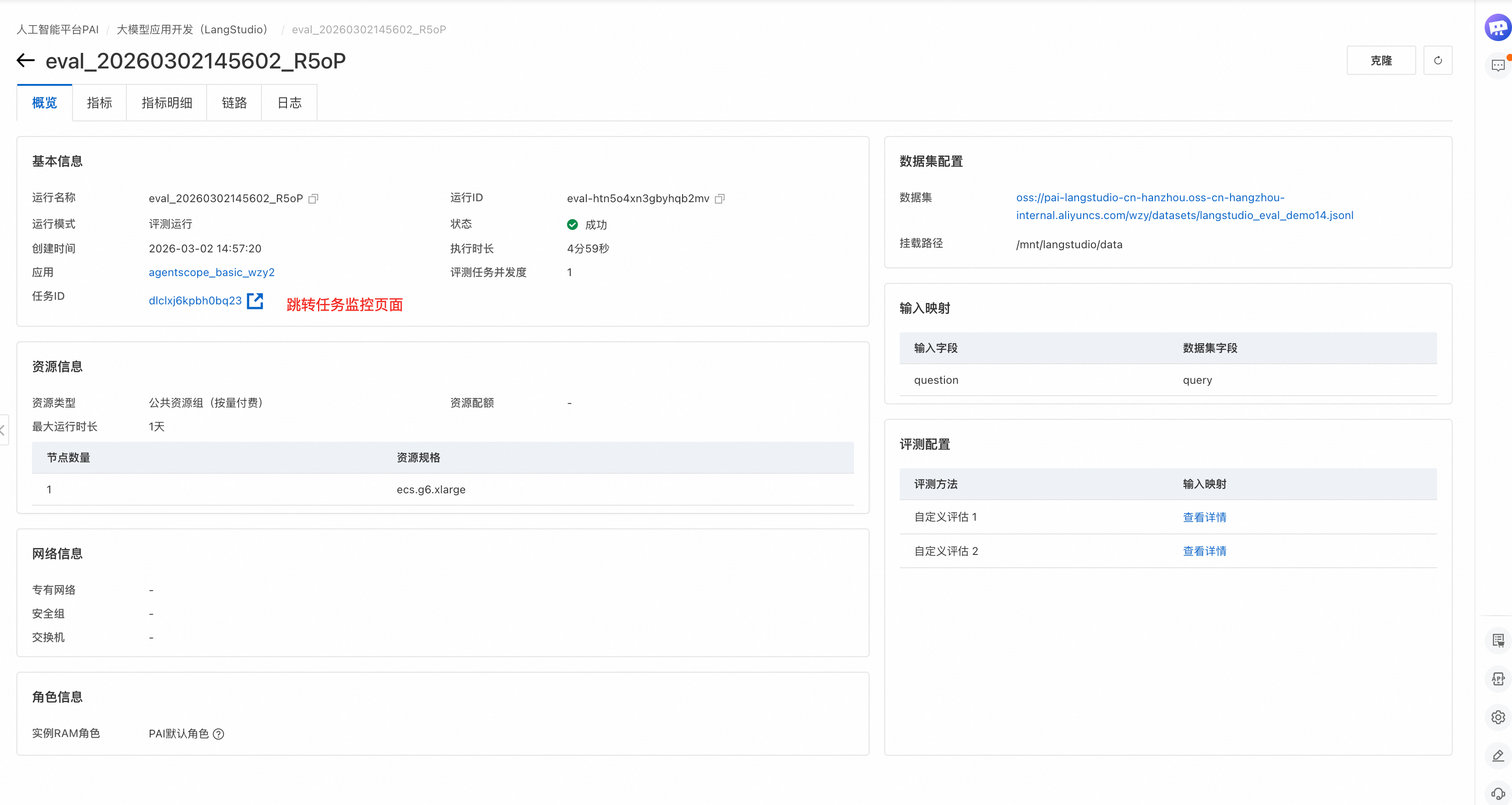
After submitting an evaluation task, LangStudio redirects to the task Overview page. Each run has two stages: Batch Run processes each dataset row through your application, and Metric Evaluation scores each output against auxiliary fields. After completion, view the trace, metrics, and output details for each subtask.
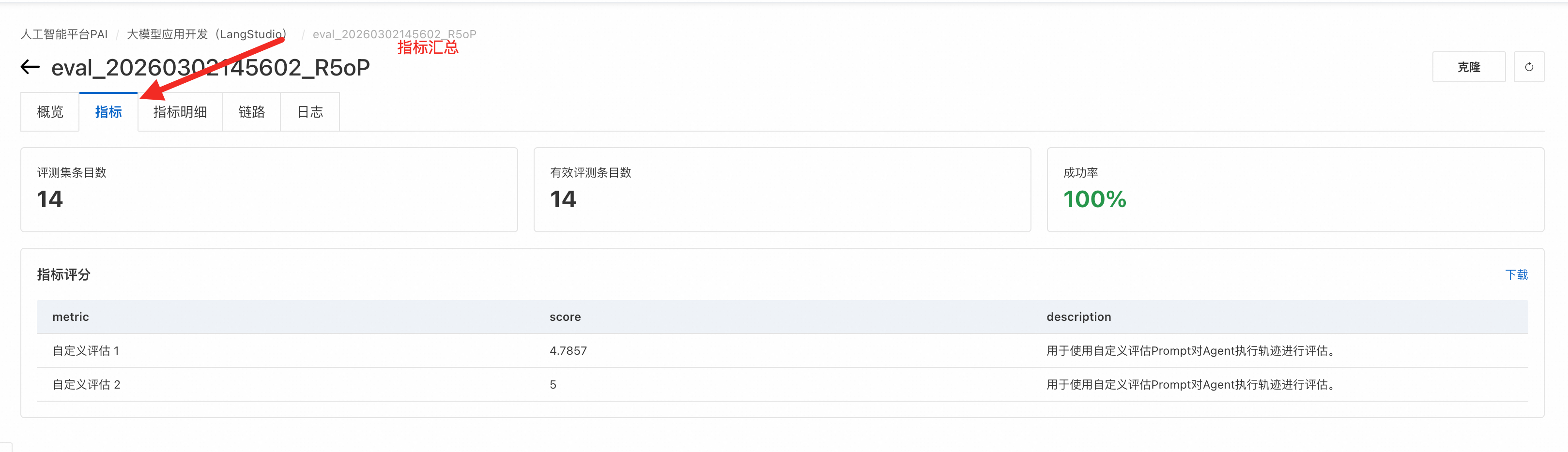
The Metrics page displays all evaluation metric results. Metric names are defined in Appendix: Preset evaluation templates.
Appendix: Preset evaluation templates
LangStudio provides the following built-in evaluation templates:
|
Template name |
Description |
Model service type |
Input fields |
|
Exact Match Evaluation |
Compares the Agent's output against the reference for exact matches. Score: 0 (no match) to 1 (perfect match). |
None |
|
|
Answer Relevancy Evaluation |
Scores the relevance of the application's output to the input using an LLM judge. Score: 1–5 (higher = more relevant). |
LLM |
|
|
Answer Correctness Evaluation |
Evaluates factual accuracy, information coverage, and format matching against a reference. Score: 1–5 (higher = closer match). |
LLM |
|
|
Instruction Following Evaluation |
Evaluates adherence to instructions in content, format, and constraints. Score: 1–5 (higher = better compliance). |
LLM |
|
|
Answer Faithfulness Evaluation |
Detects fabricated information not supported by or contradicting the context. Score: 1–5 (higher = more faithful). |
LLM |
|
|
Safety Evaluation |
Detects harmful, offensive, or inappropriate content. Score: 1–5 (higher = safer). |
LLM |
|
|
Trajectory Evaluation |
Evaluates the Agent's execution trajectory holistically. Score: 1–5 (higher = better performance). |
LLM |
|