LLM data processing algorithms help you transform data samples, filter low-quality content, and remove duplicates. By combining algorithms based on your needs, you can produce high-quality data for LLM training. This topic uses a small sample from the open-source RedPajama arXiv dataset to show how PAI's LLM data processing components clean and process arXiv data.
Dataset
The dataset for the 'LLM Data Processing - arXiv (Paper Data)' preset template in Designer consists of 5,000 samples extracted from the source data of the open-source RedPajama project.
Create and run a pipeline
Go to the Designer page.
Log on to the PAI console.
In the upper-left corner, select a region.
In the left-side navigation pane, click Workspaces and then click the name of your workspace to open it.
In the left-side navigation pane, choose Model Training > Visualized Modeling (Designer) to open the Designer page.
Create a pipeline.
On the Preset Templates tab, choose Business Area > LLM, and click Create on the LLM Data Processing-arXiv (Paper Data) template card.
Configure the pipeline parameters (or keep the default settings) and click Confirm.
In the pipeline list, select your new pipeline and click Open.
Pipeline details:

Key algorithm components in the pipeline:
LLM-Sensitive Information Mask (MaxCompute)-1
Masks sensitive information in the
textfield. For example:Replaces email addresses with
[EMAIL].Replaces telephone or mobile phone numbers with
[TELEPHONE]or[MOBILEPHONE].Replaces ID card numbers with
[IDNUM].
LLM-Special Content Removal (MaxCompute)-1
Removes URLs from the
textfield.LLM-Text Normalization (MaxCompute)-1
Normalizes text in the
textfield using Unicode and converts Traditional Chinese characters to Simplified Chinese.LLM-Count Filter (MaxCompute)-1
Removes samples from the
textfield that do not meet the specified count or ratio of alphanumeric characters. Because most characters in the arXiv dataset are letters and numbers, this component can effectively remove noisy data.LLM-Length Filter (MaxCompute)-1
Filters samples based on the average line length in the
textfield. The average length is calculated by splitting the sample by the newline character\n.LLM-N-Gram Repetition Filter (MaxCompute)-1
Filters samples based on the character-level N-gram repetition rate in the
textfield. This process uses a sliding window of size N to create a sequence of character fragments, where each fragment is a gram. The component counts the occurrences of each gram. The repetition rate is the ratio ofthe total frequency of grams that appear more than once / the total frequency of all grams.LLM-Sensitive Words Filter (MaxCompute)-1
Filters samples from the
textfield that contain preset sensitive words.LLM-Length Filter (MaxCompute)-2
Filters samples based on the maximum line length in the
textfield. The maximum line length is determined by splitting the sample by the newline character\n.LLM-Perplexity Filter (MaxCompute)-1
Calculates the perplexity of the text in the
textfield and filters samples based on a specified perplexity threshold.LLM-Special Characters Ratio Filter (MaxCompute)-1
Removes samples from the
textfield that do not meet the specified ratio of special characters.LLM-Length Filter (MaxCompute)-3
Filters samples based on the length of the
textfield.LLM-Tokenization (MaxCompute)-1
Tokenizes the text in the
textfield and saves the result to a new column.LLM-Length Filter (MaxCompute)-4
Samples in the "text" field are split into a list of words by using the delimiter
" "(a space), and then filtered based on the length of the resulting list, which is the number of words.LLM-N-Gram Repetition Filter (MaxCompute)-2
Filters samples based on the word-level N-gram repetition rate in the
textfield. All words are converted to lowercase before the calculation. This process uses a sliding window of size N to create a sequence of word fragments, where each fragment is a gram. The component counts the occurrences of each gram. The repetition rate is the ratio ofthe total frequency of grams that appear more than once / the total frequency of all grams.LLM-MinHash Deduplication (MaxCompute)-1
Removes duplicate and near-duplicate samples by using the MinHash algorithm.
Run the pipeline.
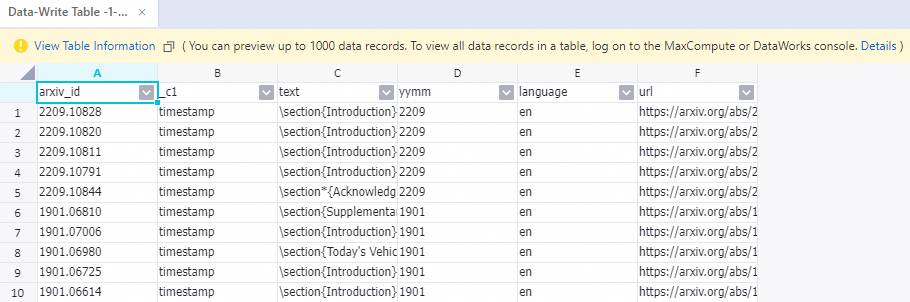
Once the pipeline completes its run, right-click the Write To Data Table-1 component and choose View Data > Output to view the processed samples.
Additional resources
For more information about the LLM algorithm components, see LLM data processing (MaxCompute).