Reject Inference (RI) addresses a structural bias in credit scoring models: because training data includes only approved applicants, the model never learns from those who were rejected and tends to underestimate risk across the full applicant pool. RI infers the likely risk behavior of rejected applicants, assigns synthetic labels to their records, and produces an augmented dataset that gives the next scorecard model a more complete picture of the "through-the-door" population.
How it works
Run the Reject Inference component after you have scored both your accepted and rejected applicants using a prior Scorecard model. The component takes two inputs:
Accepted data — records with true labels (good/bad) and prediction scores from a prior Scorecard model run.
Rejected data — records without true labels, scored by the same or a related model.
It outputs a MaxCompute table with labels assigned to the rejected records. Connect this output to Scorecard Training or Binning to retrain on the augmented dataset.
Inference methods
Four methods are available. The fuzzy method is the default and works well for most cases. Choose a different method based on your risk tolerance and data characteristics.
Fuzzy method
The fuzzy method weights each rejected sample as a blend of both outcomes rather than forcing a hard binary assignment. Each rejected sample is duplicated into two weighted observations — one labeled positive (good) and one labeled negative (bad). The weight for each label is calculated as:
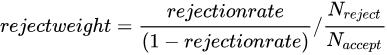
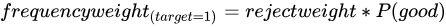
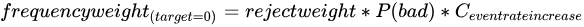
Where ![]() is the probability of a positive sample as predicted by the preceding Scorecard component.
is the probability of a positive sample as predicted by the preceding Scorecard component.
Two parameters control the weighting:
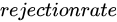 — the rejection rate for the entire dataset.
— the rejection rate for the entire dataset. — the factor by which the negative-sample probability for rejected records exceeds that of accepted records. The resulting probability is times that of accepted samples.
— the factor by which the negative-sample probability for rejected records exceeds that of accepted records. The resulting probability is times that of accepted samples.
Hard cutoff method
The hard cutoff method assigns labels using a single score threshold: samples scoring below the threshold are labeled negative (bad); samples scoring at or above it are labeled positive (good). Set the threshold based on the Scorecard model's score distribution and your acceptable risk level for rejected applicants.
Parcelling method
The parcelling method infers labels by comparing bucket-level default rates between accepted and rejected samples:
Group accepted samples into score buckets using the Scorecard model's predictions.
Calculate the default rate (percentage of bad samples) for each bucket.
Group rejected samples into the same buckets.
Within each bucket, randomly draw a proportion of rejected samples equal to the bucket's default rate — adjusted by the Bad sample ratio growth factor — and label them negative (bad). Label the rest positive (good).
Example: If 30% of accepted samples in a score bucket are bad and the Bad sample ratio growth factor is 1.5, then 30% × 1.5 = 45% of the rejected samples in that bucket are randomly labeled bad.
Two-stage method
The two-stage method corrects the Scorecard model's predictions for unlabeled samples by fitting the linear relationship between two scores from two separate upstream models:
AcceptRejectScore — the credit risk score from the preceding Scorecard model.
GoodBadScore — the predicted probability that a sample is accepted or rejected, output by a separate upstream model (for example, Linear Regression Prediction).
After fitting the linear relationship between AcceptRejectScore and GoodBadScore, the method assigns labels by following the same bucket-based steps as the parcelling method.
Input and output
Input ports
| Port | Accepted upstream components |
|---|---|
| Accepted samples | Read Table, Scorecard Prediction |
| Rejected samples | Read Table, Scorecard Prediction, Linear Regression Prediction |
Output port
The output is a MaxCompute table. Connect it to Scorecard Training or Binning.
Configure the component
Field settings
| Parameter | Required | Default | Description |
|---|---|---|---|
| Prediction result column for performance/default | Yes | None | The prediction score column output by the Scorecard component after training on the accepted dataset. Typically named prediction_score. |
| Actual label column for accepted data | Yes | None | The column containing true labels for accepted records. Values must be 0 or 1, where 1 represents a positive (good) sample. |
| Sample weight column | No | None | The column containing sample weights, if applicable. |
| Prediction result column for acceptance/rejection | No | None | The predicted acceptance probability for each sample, output by a Scorecard or linear model trained on the full dataset labeled as accepted/rejected. Required when Reject inference method is set to Two-stage method. |
Parameter settings
| Parameter | Required | Default | Description |
|---|---|---|---|
| Reject inference method | No | Fuzzy method | The method used to assign labels to rejected samples. Valid values: Fuzzy method, hard-cutoff, Parcel assignment method, Two-stage method. |
| Rejection rate | Yes | 0.3 | The probability that a sample is rejected in the real-world applicant population. |
| Number of buckets | No | 25 | The number of score buckets for the binning step. Applies only to the parcelling and two-stage methods. |
| Cutoff score | No | None | The score threshold for label assignment. Applies only to the hard-cutoff method. Samples scoring at or above this value are labeled positive; the rest are labeled negative. |
| Bad sample ratio growth factor | No | 1.0 | A multiplier applied to the accepted bucket's bad rate to estimate the bad rate for rejected samples in the same bucket. For example, if 30% of accepted samples in a bucket are bad and the factor is 1.5, then 45% of rejected samples in that bucket are labeled bad (30% × 1.5 = 45%). Applies to the fuzzy, parcelling, and two-stage methods. For the fuzzy method, this factor affects the sample weight calculation — see the |
| Random number seed | No | 0 | The seed for random label assignment. Applies only to the parcelling method. |
| Interval selection method | No | Full dataset | The dataset used to define the binning intervals. Options: Accepted dataset, Rejected dataset, Full dataset. Applies to the parcelling and two-stage methods. |
Score conversion
Select Score conversion to convert raw model scores into a standard scorecard scale using the scaledValue, odds, and pdo parameters. Score conversion is disabled by default. For configuration details, see Scorecard Training.
| Parameter | Required | Default |
|---|---|---|
| scaledValue | No | None |
| odds | No | None |
| pdo | No | None |
Execution tuning
| Parameter | Required | Default | Description |
|---|---|---|---|
| Computing resources for the underlying job | Yes | MaxCompute | The compute resource type for running the job. |
| Number of workers | No | None | The number of worker nodes. Must be a positive integer from 1 to 9,999. |
| Memory per worker | No | None | The memory allocated to each worker node, in MB. Valid range: 1,024–65,536. |