本文为您介绍TensorFlow的相关问题。
如何开通深度学习功能?
PAI提供的深度学习组件包括TensorFlow、PyTorch、Caffe及MXNet,需要进行GPU资源和OSS访问授权。关于如何开启GPU,详情请参见管理工作空间;关于如何进行OSS访问授权,详情请参见云产品依赖与授权:Designer。
如何支持多Python文件引用?
您可以通过Python文件组织训练脚本。通常首先将数据预处理逻辑存放在某个Python文件中,然后将模型定义在另一个Python文件中,最后通过一个Python文件串联整个训练过程。例如,在test1.py中定义函数,如果test2.py文件需要使用test1.py中的函数,且将test2.py作为程序入口文件,则只需要将test1.py和test2.py打包为.tar.gz包并上传即可,如下图所示。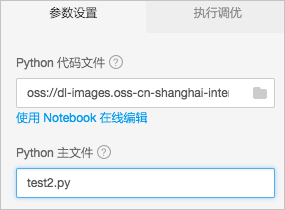 其中:
其中:
Python代码文件:.tar.gz包。
Python主文件:入口程序文件。
如何上传数据到OSS?
上传数据的视频请参见如何上传数据。
深度学习算法的数据存储在OSS的Bucket中,因此需要先创建OSS Bucket。建议您将OSS Bucket创建在与深度学习GPU集群相同的地域,从而使用阿里云经典网络进行数据传输,进而使算法运行免收流量费。创建OSS Bucket后,可以在OSS管理控制台创建文件夹、组织数据目录或上传数据。
您可以通过API或SDK上传数据至OSS,详情请参见简单上传。同时,OSS提供了大量工具(工具列表请参见OSS常用工具汇总。)帮助您更高效地完成任务,建议使用ossutil或osscmd工具上传下载文件。
使用工具上传文件时,需要配置AccessKey ID和AccessKey Secret,您可以登录阿里云管理控制台创建或查看该信息。
如何读取OSS数据?
Python不支持读取OSS数据,因此所有调用Python Open()及os.path.exist()等文件和文件夹操作函数的代码都无法执行。例如Scipy.misc.imread()及numpy.load()等。
通常采用以下两种方式在PAI中读取数据:
使用tf.gfile下的函数,适用于简单读取一张图片或一个文本等。成员函数如下。
tf.gfile.Copy(oldpath, newpath, overwrite=False) # 拷贝文件。 tf.gfile.DeleteRecursively(dirname) # 递归删除目录下所有文件。 tf.gfile.Exists(filename) # 文件是否存在。 tf.gfile.FastGFile(name, mode='r') # 无阻塞读取文件。 tf.gfile.GFile(name, mode='r') # 读取文件。 tf.gfile.Glob(filename) # 列出文件夹下所有文件, 支持Pattern。 tf.gfile.IsDirectory(dirname) # 返回dirname是否为一个目录 tf.gfile.ListDirectory(dirname) # 列出dirname下所有文件。 tf.gfile.MakeDirs(dirname) # 在dirname下创建一个文件夹。如果父目录不存在, 则自动创建父目录。如果文件夹已经存在, 且文件夹可写, 则返回成功。 tf.gfile.MkDir(dirname) # 在dirname处创建一个文件夹。 tf.gfile.Remove(filename) # 删除filename。 tf.gfile.Rename(oldname, newname, overwrite=False) # 重命名。 tf.gfile.Stat(dirname) # 返回目录的统计数据。 tf.gfile.Walk(top, inOrder=True) # 返回目录的文件树。使用
tf.gfile.Glob、tf.gfile.FastGFile、tf.WhoFileReader()及tf.train.shuffer_batch(),适用于批量读取文件(读取文件之前需要获取文件列表。如果批量读取,还需要创建Batch)。
使用Designer搭建深度学习实验时,通常需要在界面右侧设置读取目录及代码文件等参数。tf.flags支持通过-XXX(XXX表示字符串)的形式传入该参数。
import tensorflow as tf
FLAGS = tf.flags.FLAGS
tf.flags.DEFINE_string('buckets', 'oss://{OSS Bucket}/', '训练图片所在文件夹')
tf.flags.DEFINE_string('batch_size', '15', 'batch大小')
files = tf.gfile.Glob(os.path.join(FLAGS.buckets,'*.jpg')) # 列出buckets下所有JPG文件路径。批量读取文件时,对于不同规模的文件,建议分别使用如下方式:
读取小规模文件时,建议使用
tf.gfile.FastGfile()。for path in files: file_content = tf.gfile.FastGFile(path, 'rb').read() # 一定记得使用rb读取, 否则很多情况下都会报错。 image = tf.image.decode_jpeg(file_content, channels=3) # 以JPG图片为例。读取大规模文件时,建议使用
tf.WhoFileReader()。reader = tf.WholeFileReader() # 实例化reader。 fileQueue = tf.train.string_input_producer(files) # 创建一个供reader读取的队列。 file_name, file_content = reader.read(fileQueue) # 使reader从队列中读取一个文件。 image_content = tf.image.decode_jpeg(file_content, channels=3) # 将读取结果解码为图片。 label = XXX # 省略处理label的过程。 batch = tf.train.shuffle_batch([label, image_content], batch_size=FLAGS.batch_size, num_threads=4, capacity=1000 + 3 * FLAGS.batch_size, min_after_dequeue=1000) sess = tf.Session() # 创建Session。 tf.train.start_queue_runners(sess=sess) # 启动队列。如果未执行该命令,则线程会一直阻塞。 labels, images = sess.run(batch) # 获取结果。核心代码解释如下:
tf.train.string_input_producer:将files转换为队列,且需要使用tf.train.start_queue_runners启动队列。tf.train.shuffle_batch参数如下:batch_size:批处理大小,即每次运行Batch返回的数据数量。
num_threads:运行线程数,一般设置为4。
capacity:随机取文件范围。例如,数据集有10000个数据,如果需要从5000个数据中随机抽取,则将capacity配置为5000。
min_after_dequeue:维持队列的最小长度,不能大于capacity。
如何为OSS写入数据?
您可以通过以下任意一种方式将数据写入OSS中,生成的文件存储在输出目录/model/example.txt:
通过
tf.gfile.FastGFile()写入,示例如下。tf.gfile.FastGFile(FLAGS.checkpointDir + 'example.txt', 'wb').write('hello world')通过
tf.gfile.Copy()拷贝,示例如下。tf.gfile.Copy('./example.txt', FLAGS.checkpointDir + 'example.txt')
为什么运行过程中出现OOM?
使用的内存达到上限30 GB,建议通过gfile读取OSS数据,详情请参见如何读取OSS数据?。
TensorFlow有哪些案例?
使用TensorFlow实现图像分类,详情请参见TensorFlow实现图像分类视频、使用TensorFlow实现图片分类及TensorFlow案例相关代码。
使用TensorFlow自动写歌,详情请参见TensorFlow自动写歌词及写歌案例。
如何查看TensorFlow相关日志?
查看TensorFlow相关日志请参见查看训练中的日志。
配置两个GPU时,model_average_iter_interval有什么作用?
如果未配置model_average_iter_interval参数,则GPU会运行标准的Parallel-SGD,每个迭代都会交换梯度更新。如果model_average_iter_interval大于1,则使用Model Average方法,训练迭代间隔若干轮(model_average_iter_interval表示数值轮数)计算两个平均模型参数。
- 本页导读 (1)