在线上业务的内容生产过程中,为了及时识别其中的高风险内容,PAI提供了图像内容风控解决方案。本文介绍如何基于人工智能算法,快速构建符合业务场景的风控模型,助力您快速识别高风险内容,进而对其进行拦截。
背景信息
问题背景
在诸多用户生成内容的场景,例如用户使用图像进行评论、用户发布短视频、用户直播等等,由于用户产生内容的范围不受限,难免出现涉黄、涉暴、涉政等风险极大的内容。此时需要通过人工智能算法,自动判断出用户生产的风险内容,并及时进行拦截。
解决方案
PAI提供给用户图像内容风控领域,端到端的白盒解决方案。首先客户可以利用PAI的标注平台,完成对目标场景中图像的快捷标注。然后基于PAI提供的预训练模型,客户可以针对自己的图像风控场景,在PAI可视化建模平台上进行模型的Fine-tune。从而根据自己业务风控场景,基于resnet50构建图像分类模型,基于yoloV5构建目标检测模型。最后客户可以在PAI上将模型进行在线部署,形成完整的端到端流程,从而识别出生产环境内容中涉黄、涉暴、涉政等风险内容。
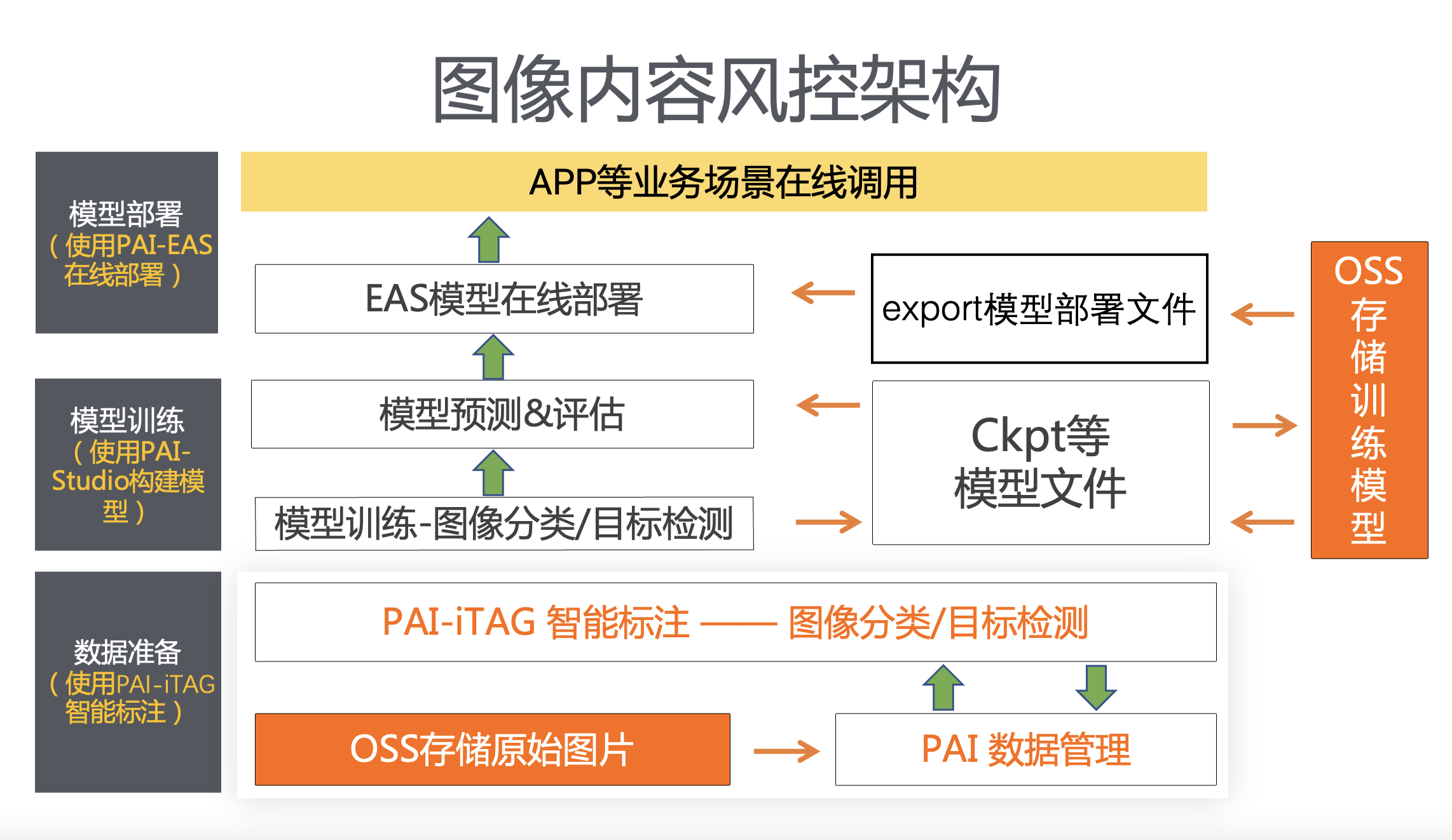
方案架构
图像内容风控解决方案的架构图如下所示。
前提条件
已开通PAI(Studio、DSW、EAS)后付费,详情请参见开通。
已开通AI工作空间,并开通MaxCompute计算资源和DLC计算资源,详情请参见AI工作空间。
已创建OSS存储空间(Bucket),用于存储标签文件和训练获得的模型文件。关于如何创建存储空间,请参见创建存储空间。
已开通MaxCompute,用于存储训练数据和测试数据。关于如何开通MaxCompute,请参见快速体验MaxCompute。
已创建PAI-EAS专属资源组,本文训练好的模型会部署至该资源组。关于如何创建专属资源组,请参见创建资源组。
数据准备
基于PAI-iTAG智能数据标注平台,先将原始图片数据存储在OSS中,然后利用PAI数据集管理将原始数据扫描生成索引文件,再利用PAI-iTAG进行数据标注。最终我们得到标注结果数据集,用于后续的模型训练。
如果您的业务场景是将图像整体进行风险类别的分类时,请选择图像分类的内容风控解决方案流程;如果您的业务场景是将图像中的某些高风险的实体进行框选检测时,请选择目标检测的内容风控解决方案流程。
步骤一:登录OSS控制台
将原始图片存储在OSS中。为了后续将训练集和测试集分别注册PAI数据集及标注,需要将存储在OSS的数据集分成训练集和测试集,从而用于后续的模型构建。
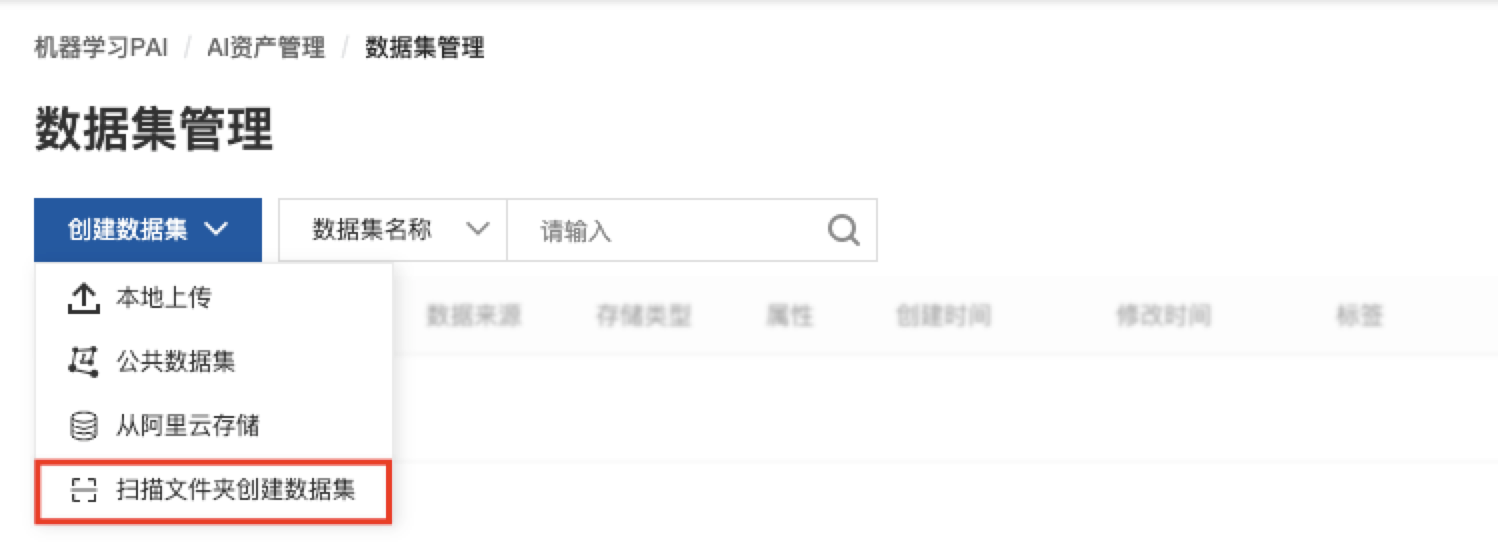
步骤二:利用PAI数据集管理生成manifest索引文件
登录PAI控制台。
在左侧导航栏中,选择AI资产管理->数据集管理。
点击创建数据集,选择扫描文件夹创建数据集。
将存储在OSS中的原始数据扫描生成manifest索引文件,并注册数据集,用于后续标注。
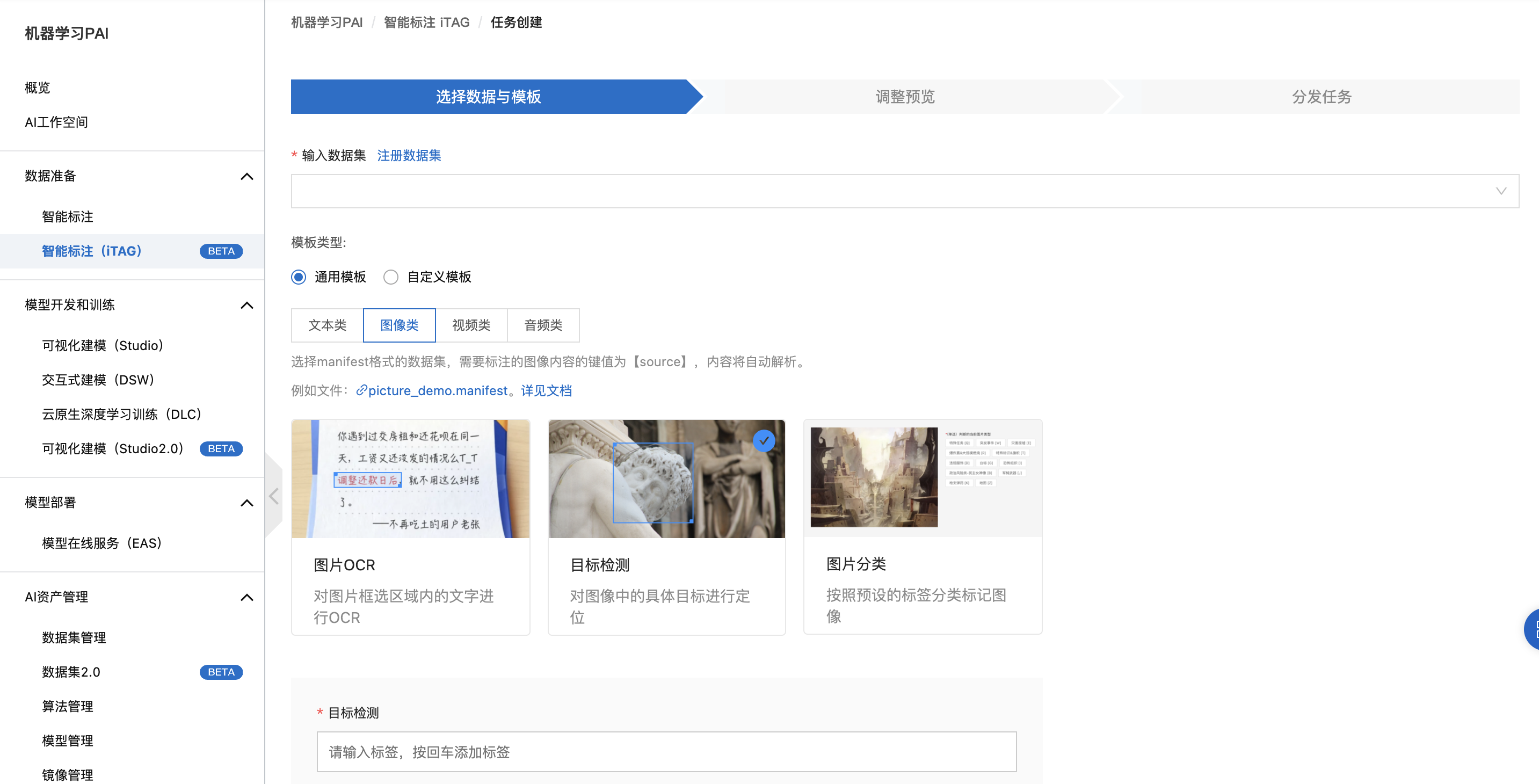
步骤三:利用PAI-iTAG进行数据标注
登录PAI控制台。
在左侧导航栏中,选择数据准备 -> 智能标注(iTAG)。
点击创建任务,在输入数据集处选择刚刚注册的数据集,然后选择所需要的标注场景图像分类/目标检测,然后完成标注任务的创建。
在PAI-iTAG控制台中,点击右上角的前往标注页面,在标注页面完成标注任务。
回到PAI-iTAG控制台,针对刚才标注完成的任务,点击获取标注结果,得到标注结果数据集,存储到指定的OSS目录中。
模型构建
利用PAI提供的可视化建模Studio平台,基于预训练模型,基于自己的业务场景,可以选择利用resnet50进行图像分类模型构建,也可以选择利用yoloV5进行目标检测模型构建。(本示例实验构建在上海region)
如果您的业务场景是将图像整体进行风险类别的分类时,请选择图像分类的内容风控解决方案流程;如果您的业务场景是将图像中的某些高风险的实体进行框选检测时,请选择目标检测的内容风控解决方案流程。
图像分类
步骤一:进入PAI-Designer控制台
登录PAI控制台。
在左侧导航栏中,选择 模型开发和训练 ->可视化建模(Designer)。
步骤二:构建实验
在可视化建模(Studio 2.0)控制台中,选择实验模板,在实验模板列表中找到图像分类,点击并创建实验。
在实验列表中找到刚才创建好的模板实验,并进入实验。
系统根据预置的模板,自动构建实验,如下图所示。运行过程中,可以点击组件右键,查看运行日志。
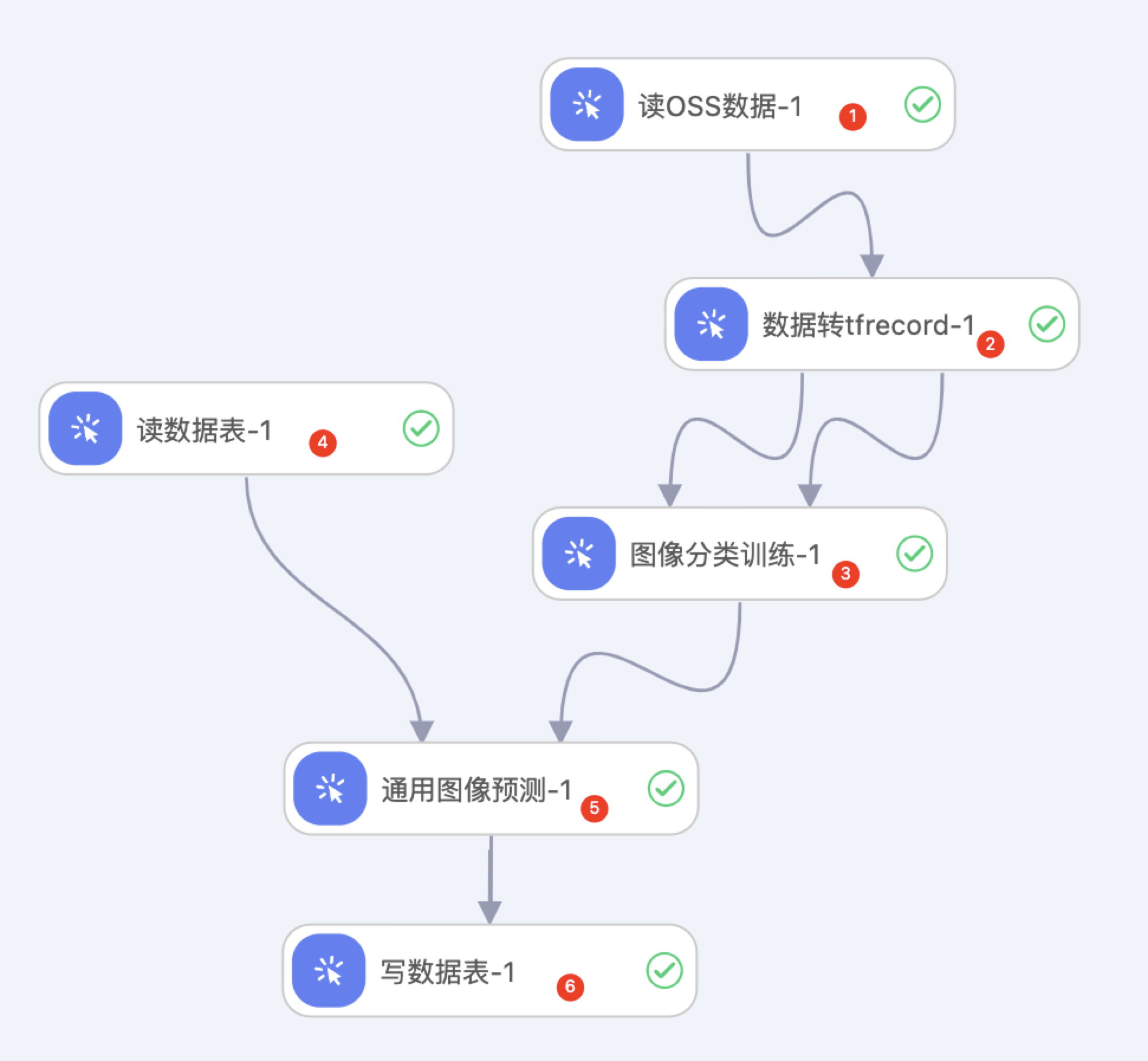
区域①:选择标注结果数据集的OSS路径。例如选择:oss://pai-online-shanghai.oss-cn-shanghai-internal.aliyuncs.com/ev_demo/图像智能审核检测标注_1626960686929.manifest
区域②:将数据集拆分成图像分类所需要的训练集和测试集。
数据转tfrecord-字段设置:
参数 | 描述 | 示例 |
转换配置文件路径 | 转化配置文件的OSS路径。 | 无需填写 |
输出tfrecord路径 | 输出tfrecord文件的OSS路径。 | oss://pai-online-shanghai.oss-cn-shanghai-internal.aliyuncs.com/test/convert_img_inspect_cls |
输出tfrecord前缀 | 自定义输出tfrecord文件名称的前缀。 | img_cls |
数据转tfrecord-参数设置:
参数 | 描述 | 示例 |
转换数据用于何种模型训练 | 请根据自己训练类型选取. | CLASSIFICATION |
类别列表文件路径 | 类别列表文件的OSS路径 | oss://pai-online-shanghai.oss-cn-shanghai-internal.aliyuncs.com/ev_demo/图像审核-分类标注_class.txt |
测试数据分割比例 | 测试数据分割比例,设置为0,则所有数据转换为训练数据, 0.1表示10%数据作为验证集 | 0.1 |
图片最大边限制 | 如果设置,大图片将被resize后存入tfrecord,节省存储、提高数据读取速度。可选参数,默认为none(即不指定该参数) | 无需填写 |
测试图片最大边限制 | 选择测试图片最大边限制 | 无需填写 |
默认类别名称 | 默认类别名称 | 无需填写 |
错误类别名称 | 含有该类别的物体和box将会被过滤,不参与训练。可选,默认不传该参数 | 无需填写 |
忽略类别名称 | 只用于检测模型,含有该类别的box会在训练中被忽略。可选,默认不传该参数。 | 无需填写 |
转换类名称 | 选择标注数据的来源类型 | PAI标注格式 |
分隔符 | 选择分隔符 | 无需填写 |
图片编码方式 | 选择图片编码方式 | jpg |
数据转tfrecord-执行调优:
参数 | 描述 | 示例 |
读取并发数 | 训练过程读取并发数 | 10 |
写tfrecord并发数 | 训练过程写tfrecord并发数 | 1 |
每个tfrecord保存图片数 | 训练过程每个tfrecord保存图片数 | 256 |
worker个数 | 训练过程worker个数 | 3 |
CPU Core个数 | 训练过程CPU Core个数 | 800 |
memory大小 | 训练过程memory大小 | 20000 |
区域③:对图像分类训练模型的参数进行选择。
模型训练-字段设置:
参数 | 描述 | 示例 |
训练所用OSS目录 | 训练所选择的OSS目录 | oss://pai-online-shanghai.oss-cn-shanghai-internal.aliyuncs.com/test/test_image_inspection |
训练数据文件OSS路径 | 训练数据文件的OSS路径。 | 无需填写 |
评估数据OSS路径 | 评估数据文件的OSS路径。 | 无需填写 |
label_map_path文件OSS路径 | 类别列表文件的OSS路径。 | 无需填写 |
是否使用预训练的模型 | 是否使用预训练的模型 | 是 |
预训练模型OSS路径 | 如果有预训练模型,则填入预训练模型的OSS路径。不填则使用PAI提供的默认预训练模型。 | 无需填写 |
模型训练-参数设置:
参数 | 描述 | 示例 |
识别模型网络 | 选择想要使用的识别模型网络,涵盖了当前主流的识别模型。 | resnet_v1_50 |
分类类别数目 | 选择数据中类别标签的数目。 | 4 |
图片resize大小 | 图片resize大小 | 224 |
是否使用crop进行数据增强 | 是否使用crop进行数据增强 | 是 |
是否针对每个类别单独做评估 | 是否针对每个类别单独做评估 | 否 |
学习率调整策略 | 学习率调整策略 | exponential_decay |
初始学习率 | 选择初始学习率 | 0.001 |
decay_epoches | 学习率迭代过程中,连续两次衰减之间,间隔的轮数 | 10 |
decay_factor | 选择学习率迭代过程的衰减比率 | 0.9 |
staircase | 勾选则按照离散间隔进行学习率衰减,不勾选则按照连续间隔进行学习率衰减。 | 是 |
训练batch_size | 选择训练批大小,一次模型迭代/训练过程中所使用的样本数目 | 32 |
评估batch_size | 选择评估批大小,一次模型迭代/训练过程中所使用的样本数目 | 32 |
训练迭代轮数 | 选择训练迭代轮数 | 80 |
评估数据条目数 | 选择评估数据条目数 | 200 |
评估过程可视化显示的样本数目 | 选择评估过程可视化显示的样本数目 | 64 |
保存checkpoint的频率 | 保存模型文件的频率 | 5 |
模型训练-执行调优:
参数 | 描述 | 示例 |
优化方法 | 模型训练的优化方法 | momentum |
读取训练数据线程数 | 读取训练数据线程数 | 4 |
单机或分布式 | 训练选择单机或分布式 | 单机maxCompute |
是否使用GPU | 训练是否使用GPU | 100 |
区域④:选择模型预测需要的预测集输入。利用odpscmd工具,将准备好的测试集数据利用tunnel命令上传到MaxCompute中。
# 建表语句
CREATE TABLE cv_risk_train(url STRING);
# 上传语句
tunnel upload /Users/tongxin/xxx/cv_risk_train.csv cv_risk_train;预测集数据表例如:pai_online_project.pascal_predict_hz,数据样式如下图所示。
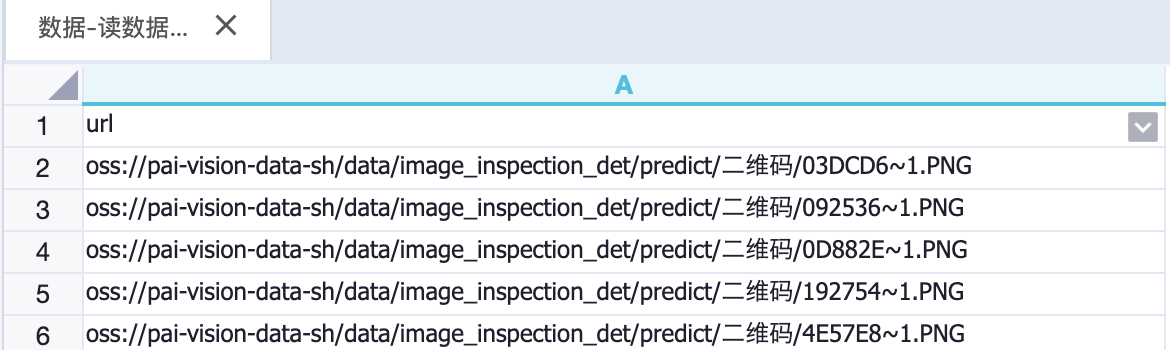
区域⑤:对训练好的图像分类模型进行预测,数据来源选择Table,模型类型选择classifier,图片列名根据表的列名来选择,此处为url。保留列名中也选择url,方便预测结果的展示。
区域⑥:将预测的结果写入数据表中,例如填写test_image_inspection_cls。
目标检测
步骤一:进入PAI-Studio控制台
登录PAI控制台。
在左侧导航栏中,选择【模型开发和训练】->【可视化建模(Studio 2.0)】。
步骤二:构建实验
在可视化建模(Studio 2.0)控制台中,选择实验模板,在实验模板列表中找到【基于Yolov5模型的目标检测】,点击并创建实验。
在实验列表中找到刚才创建好的模板实验,并进入实验。
系统根据预置的模板,自动构建实验,如下图所示。运行过程中,可以点击组件右键,查看运行日志。
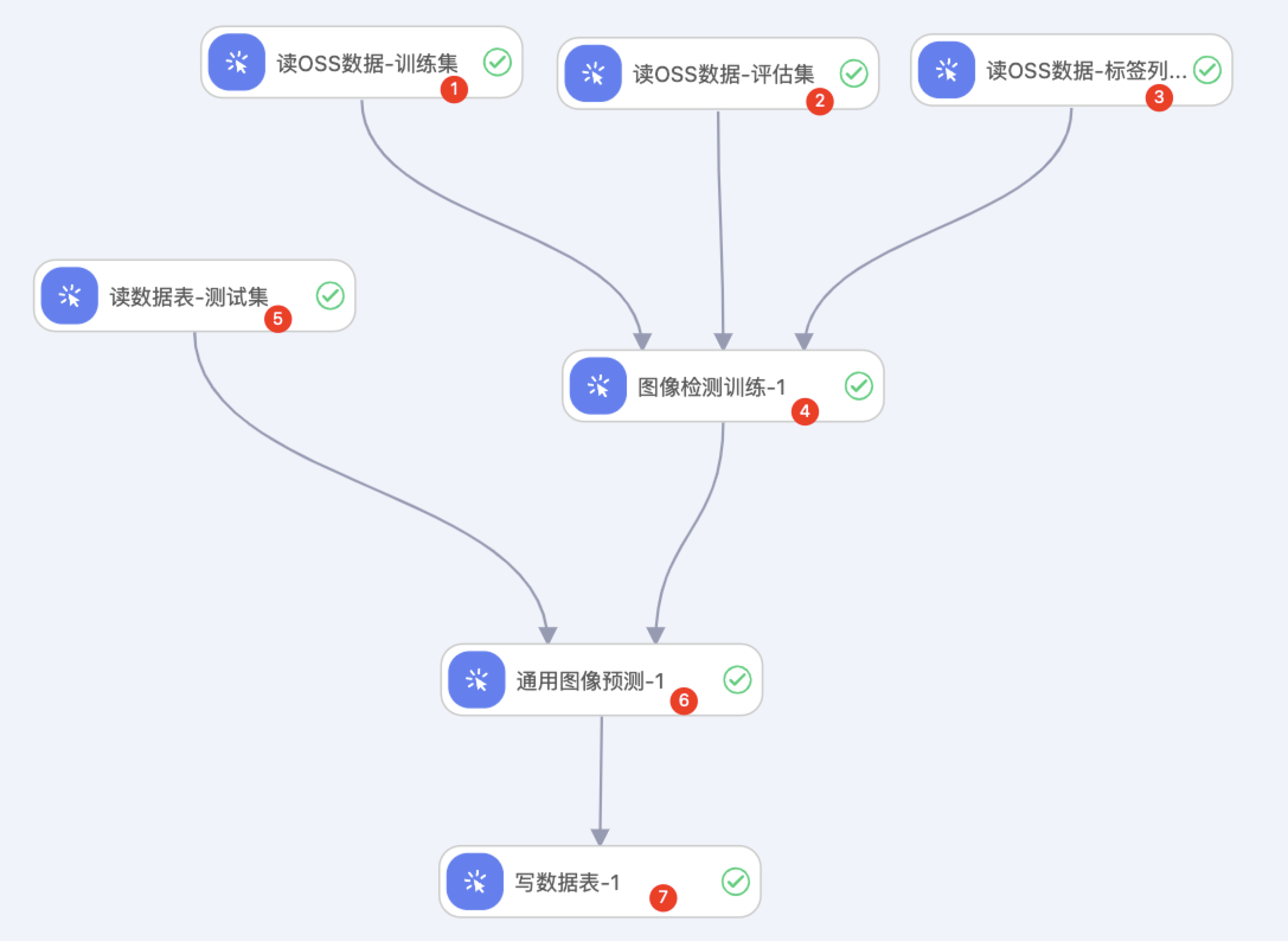
区域①:选择标注结果数据集中训练集的OSS路径。例如选择oss://pai-online-shanghai.oss-cn-shanghai-internal.aliyuncs.com/ev_demo/risk_det_train.manifest
区域②:选择标注结果数据集中评估集的OSS路径。例如选择oss://pai-online-shanghai.oss-cn-shanghai-internal.aliyuncs.com/ev_demo/risk_det_dev.manifest
区域③:选择数据的标签列表文件的OSS路径。例如文件:。例如选择:oss://pai-online-shanghai.oss-cn-shanghai-internal.aliyuncs.com/ev_demo/图像审核-检测标注_class.txt
区域④:对图像检测模型的参数进行选择。
模型训练-字段设置:
参数 | 描述 | 示例 |
训练模型类型 | 训练所选的模型类型。 | YOLOV5 |
训练所用OSS目录 | 训练所选择的OSS目录 | oss://pai-online-shanghai.oss-cn-shanghai-internal.aliyuncs.com/test/risk_det_yolov5/ckpt/ |
训练数据文件OSS路径 | 训练数据文件的OSS路径。 | 无需填写 |
评估数据OSS路径 | 评估数据文件的OSS路径。 | 无需填写 |
类别列表文件OSS路径 | 类别列表文件的OSS路径。 | 无需填写 |
YOLOV5数据源格式 | 选择标注数据的来源类型,支持PAI/VOC/YOLO三种标注格式的检测数据。 | PAI标注格式 |
预训练模型OSS路径 | 如果有预训练模型,则填入预训练模型的OSS路径。 | 无需填写 |
模型训练-参数设置:
参数 | 描述 | 示例 |
YOLOV5检测模型使用的模型大小 | 选择YOLOV5检测模型使用的模型大小和网络结构。 | yolov5s |
检测类别数目 | 选择数据中类别标签的数目,可不填,默认从数据集中分析得到。 | 3 |
yolov5输入图片大小 | yolov5输入图片大小, 整数,高*宽=image_size | 640 |
初始学习率 | 选择网络训练的学习率 | 0.01 |
训练batch_size | 选择训练批大小,一次模型迭代/训练过程中所使用的样本数目 | 32 |
评估batch_size | 选择评估批大小,一次模型迭代/训练过程中所使用的样本数目 | 30 |
总的训练迭代epoch轮数 | 选择总的训练迭代轮数 | 50 |
保存checkpoint的频率 | 选择保存模型文件的频率 | 1 |
模型训练-执行调优:
参数 | 描述 | 示例 |
读取训练数据线程数 | 读取训练数据线程数 | 4 |
单机或分布式(maxCompute/DLC) | 单机或分布式(maxCompute/DLC) | 分布式DLC |
worker个数 | worker个数 | 1 |
cpu机型选择 | 计算资源cpu机型选择 | 32vCPU+128GB Mem-ecs.g6.8xlarge |
gpu机型选择 | 计算资源gpu机型选择 | 48vCPU+368GB Mem+4xv100-ecs.gn6e-c12g1.12xlarge |
区域⑤:选择模型预测需要的预测集输入。利用odpscmd工具,将准备好的测试集数据索引利用tunnel命令上传到MaxCompute中。
# 建表语句
CREATE TABLE cv_risk_train(url STRING);
# 上传语句
tunnel upload /Users/tongxin/xxx/cv_risk_train.csv cv_risk_train;预测集数据表例如:pai_online_project.pascal_predict_hz,数据样式如下图所示。
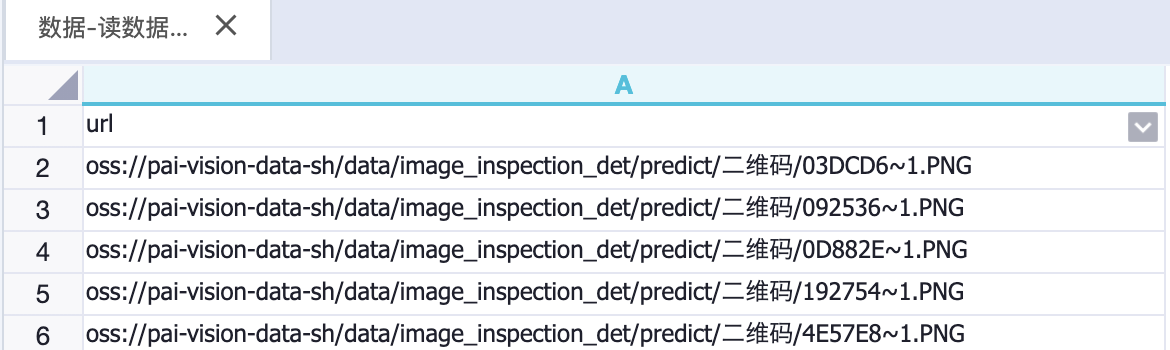
区域⑥:对训练好的图像检测模型进行预测,数据来源选择Table,模型类型选择yolo5预测,图片列名根据表的列名来选择,此出为url。保留列名中也选择url,方便预测结果的展示。
区域⑦:将预测的结果写入数据表中,例如填写yolov5_predict。
模型部署调用
利用PAI提供的EAS模型在线服务平台,将训练好的内容风控模型进行在线部署,并在实际的生产环境中进行推理实践。
步骤一:登录PAI-EAS控制台
登录PAI控制台。
在左侧导航栏中,选择模型部署 -> 模型在线服务(EAS)。
步骤二:模型上传部署
在PAI-EAS控制台中,单击模型上传部署进行新建服务,具体参数配置如下:
参数 | 图像分类模型 | 图像检测模型 |
自定义模型名称 | 自定义输入模型的名称。 | 自定义输入模型的名称。 |
资源组种类 | 建议创建专属资源组并使用,避免公共资源组资源有限导致服务排队。 | 建议创建专属资源组并使用,避免公共资源组资源有限导致服务排队。 |
资源种类 | 选择GPU。 | 选择GPU。 |
Processor种类 | 选择EasyVision。 | 选择EasyVision。 |
模型类型 | 选择classfier。 | 选择torch_detector。 |
模型文件 | 选择OSS文件导入,此处选择模型训练的模型存储OSS输出目录,选择export文件夹中的模型文件夹(其中包含 | 选择OSS文件导入,此处选择模型训练的模型存储OSS输出目录,选择 |
点击下一步,配置模型服务占用资源:选择1个实例数、1张卡、1个核,内存选择为16384M。
点击部署,等待一段时间完成模型部署任务的创建。
步骤三:脚本批量调用
在PAI EAS模型在线服务页面,单击已部署服务的服务方式列下的调用信息。
在调用信息对话框的公网地址调用页签,查看公网调用的访问地址和Token。
创建图像分类的Python脚本
cv_risk_cls.py。
import requests
import base64
import sys
import json
resp = requests.get('https://tongxin-lly.oss-cn-hangzhou.aliyuncs.com/iTAG/pic_public/1.jpg')
ENCODING = 'utf-8'
datas = json.dumps( {
"image": base64.b64encode(resp.content).decode(ENCODING),
})
head = {
"Authorization": "YjdhYWRhYWZhYzNjZTFlMDZlNjAxxxxxxxxxxxxxxxxxxxx"
}
for x in range(0,1):
resp = requests.post("http://1664081855183111.cn-shanghai.pai-eas.aliyuncs.com/api/predict/cv_risk_cls001", data=datas, headers=head)
print(resp.text)
print("test endding")创建图像检测的Python脚本
cv_risk_det.py。
import requests
import base64
import sys
import json
img_file = './xxx.jpg'
ENCODING = 'utf-8'
datas = json.dumps( {
"image": base64.b64encode(open(img_file, 'rb').read()).decode(ENCODING),
})
head = {
"Authorization": "NGVkMTVmZjNlNzA3ZGVlNWIzxxxxxxxxxxxxxx"
}
r = requests.post("http://1664081xxxxxxxxx.cn-shanghai.pai-eas.aliyuncs.com/api/predict/cv_risk_obj001", data=datas, headers=head)
print(r.text)将图像分类或图像检测脚本上传至您的任意环境,并在脚本上传后的当前目录执行如下调用命令,得到的预测结果如图所示。
$ python3 cv_risk_xxx.py
步骤五:监控服务指标
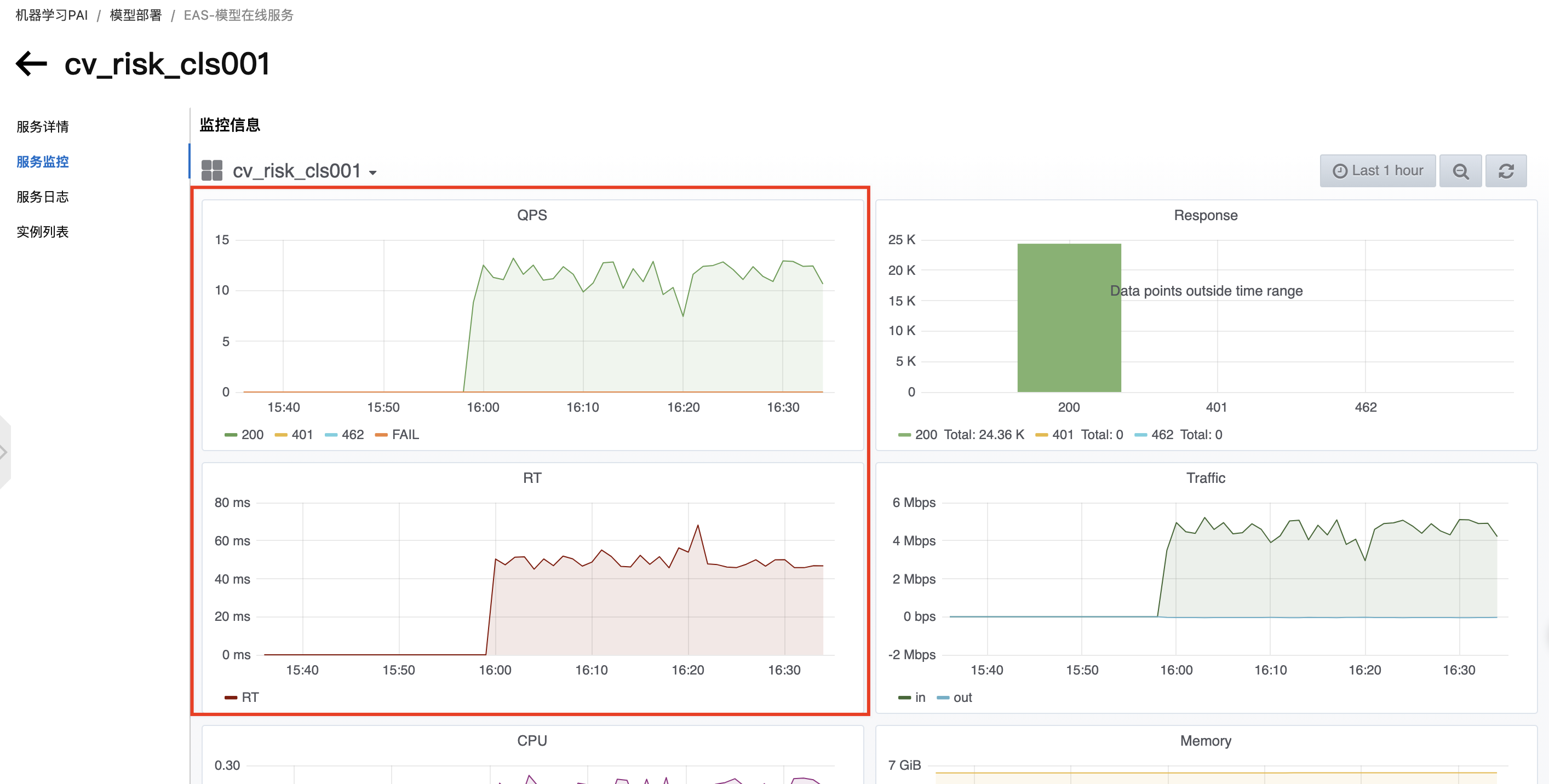
调用模型服务后,您可以查看模型调用的相关指标水位,包括QPS、RT、CPU、GPU及Memory。
在PAI EAS模型在线服务页面,单击已调用服务服务监控列下的监控图标。
在服务监控页签,即可查看模型调用的指标水位。从服务监控的水位图中可以看到部署的模型的时延在50 ms左右。