背景
随着系统自动化的不断深入,核心业务系统的日益复杂,服务开发运维人员越来越迫切的需要了解系统的当前状态,在出现异常时及时了解服务异常原因以及评估业务的受损情况。服务提供方以及使用者都可以基于该关键指标实时观测系统状态,及观测到解服务异常。下面我们以OSS访问日志为例,来看下如何计算特定服务的可用性指标。
OSS服务
SLO关键指标
用户需要基于自己的业务、应用定义SLO指标,例如应用A用到了某些OSS的bucket, 就需要监控这几个Bucket的访问成功率,并排除某些特殊情形,比如跨区域复制、生命周期管理等API调用。这里为了简便,给出了如下所示的SLO指标,5分钟错误率:
每5分钟错误率 = 每5分钟失败请求数/每5分钟有效总请求数*100%
为了演示日志服务的灵活性,下面展示的时候还会去除了部分应用无关的API调用:不包括跨区域复制、生命周期管理、授权错误等。
访问日志
日志服务和OSS产品做了打通,可以极为方便的收集OSS访问日志到日志服务中,详情请参考官方文档。下面为一条典型的OSS访问日志(已忽略部分字段):
{
"content_length_in": "5462965657",
"referer": "www.wrq.mock.com",
"vpc_id": "3704",
"owner_id": "l7g7vtvz",
"__tag__:__receive_time__": "1672631115",
"bucket_storage_type": "archive",
"http_method": "PUT",
"response_body_length": "579137719",
"bucket_location": "oss-cn-beijing-p",
"delta_data_size": "1085",
"host": "www.gap.mock.com",
"client_ip": "183.190.169.186",
"server_cost_time": "4711",
"vpc_addr": "121.206.61.61",
"sign_type": "NormalSign",
"user_agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_6_8) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.45 Safari/535.19",
"key": "data%2Fcur_file98Itxt",
"object_size": "4685",
"__time__": 1672631111,
"sync_request": "-",
"__topic__": "oss_access_log",
"__source__": "127.0.0.1",
"http_type": "http",
"logging_flag": "false",
"request_uri": "/request/path-0/file-4",
"bucket": "bucket1865",
"request_length": "8037",
"content_length_out": "4555252327",
"__tag__:__receive_time___0": "1672631115",
"error_code": "-",
"http_status": "200",
"response_time": "2839",
"time": "02/Jan/2023:03:45:11",
"operation": "DeleteObject",
"request_id": "q9il0l7l7g",
"object": "245-da918c3e2dd9dc9cb4d9283b%2F5658e1271f54b7ed91ba881d45650102.model",
"requester_id": "39cluded64"
}不仅是OSS访问日志,日志服务还和多种其它云产品做了打通,能够一键开启访问日志。用户可以在官方文档中寻找感兴趣的云产品。
OSS Lens
除了基础的OSS访问日志,日志服务还提供了更为高级的功能:Cloud Lens。Cloud Lens能够通过日志、指标、配置计量等数据的关联分析,提供阿里云产品的用量分析、性能监控、安全分析、数据保护、异常检测、访问分析等服务。如果用户使用场景较为通用,可以直接使用Cloud Lens for OSS来监控服务可用性。
自定义指标
下面来介绍下如何通过访问日志计算,按照上面可用性指标的定义,我们需要重点关注以下几个字段:
字段名称 |
说明 |
示例 |
status |
状态响应码 |
304 |
__time__ |
用户请求时间戳 |
1672194785 |
error_code |
错误码 |
AccessDenied |
当然,用户也可以根据自己的需求为指标增加各种维度信息,方便后续计算多种维度的可用性指标:
字段名称 |
说明 |
示例 |
client_ip |
请求IP |
127.98.12.1 |
bucket |
请求Bucket |
TestBucket |
operation |
用户行为 |
ProcessImage |
method |
HTTP method |
GET |
指标计算
我们可以通过日志服务的SQL来计算服务错误率。
添加索引
在计算之前,我们需要为关键字段添加索引,只有开启索引的字段才能够使用SQL继续统计分析。关于索引管理,可以参考文档配置索引。如果使用的是OSS访问日志,日志服务已经为用户配置好了索引信息,不需要额外配置。
计算SQL
日志服务的查询分析语句包含两部分,并用竖线隔开。其中左半部分为查询语句,可以实现数据过滤,右半部分为SQL分析语句,能够进行统计分析。日志服务的SQL语法不仅完全兼容标准SQL,而且还支持在分析语句中定义Lambda表达式,简化SQL复杂度。可以看到,下面的错误率计算SQL使用了filter函数,过滤出期望的错误日志。
not operation: - not status: 403 not operation: GetBucketLifecycle not operation: PutBucketLifecycle not operation: GetBucketReplication not operation: GetBucketReplicationProgress not GetService | select 'cn-nanjing' as region, bucket, client_ip, operation, error_count,
(total_count - error_count) as success_count, timestamp, uid
from
(
select min(__time__) * 1000 as timestamp, bucket, client_ip, operation,
count(1) filter(
where status != 200 and status != 424 and status != 408
) as error_count, count(1) as total_count
from log group by bucket, client_ip, operation
) limit 1000000定时SQL
日志服务已经支持定时SQL,能够很好的适用于这个场景,详情可以参考官方文档。在日志服务的控制台执行上面的SQL语句,成功后可以看到定时保存分析结果的按钮,点击即可保存为定时SQL。
计算配置略过不讲,用户可以参考官方文档。下面说明下调度配置:
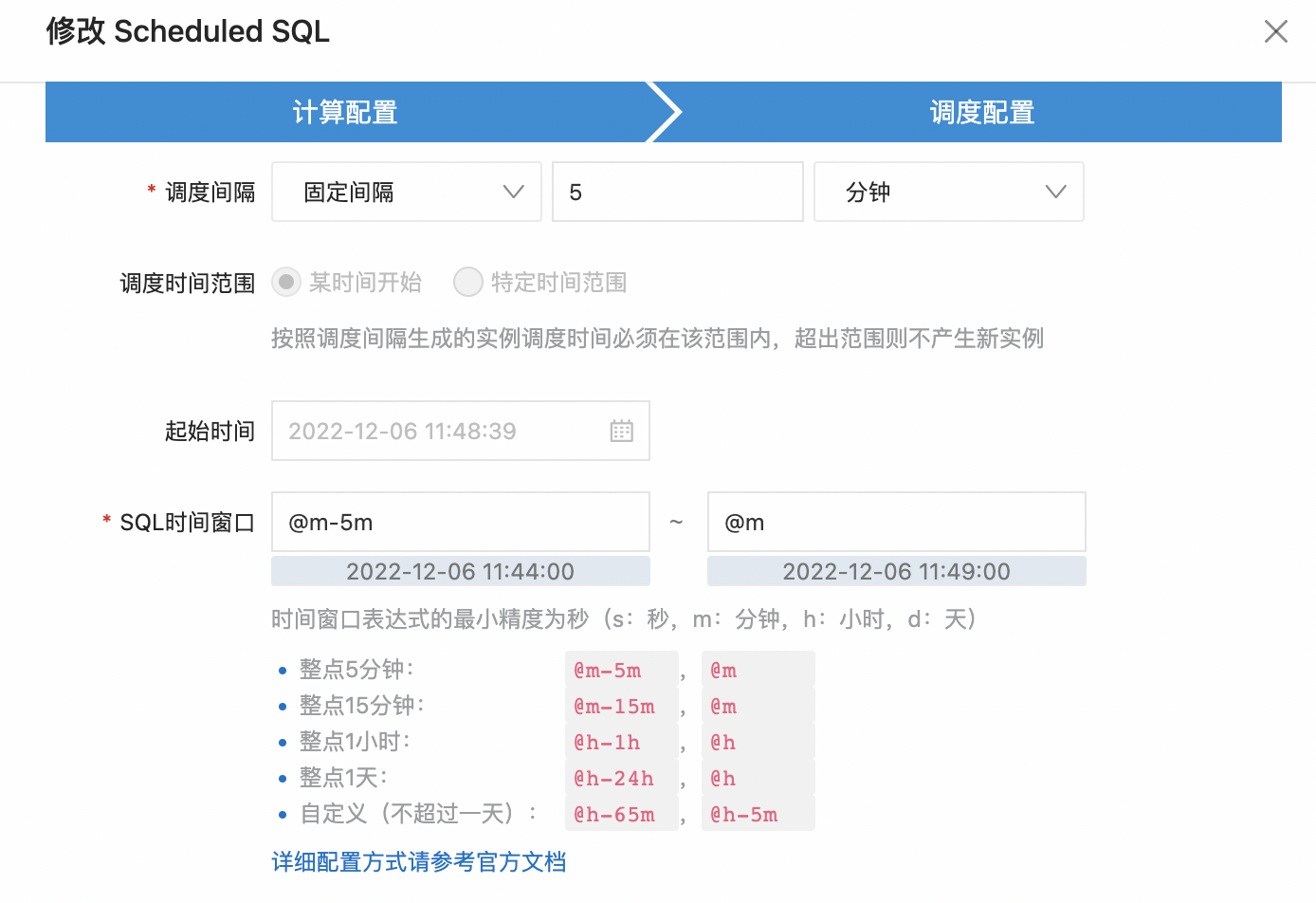
根据可用性指标的定义,这里需要选择调度间隔为5分钟,SQL时间窗口也同样为5分钟,从而满足SLO的计算要求。最后点击确认保存任务。
自定义指标
我们还可以根据访问日志计算服务关键指标,发现服务问题,及时止血。下面同样基于OSS访问日志,介绍下如何计算部分服务关键指标。
请求流量/次数
not operation: - |select sum(content_length_in)/1024/1024/1024 as request_length , sum(content_length_out) /1024/1024/1024 as response_length, count(1) as request_count, (__time__ - __time__ % 60) as ts from log group by ts order by ts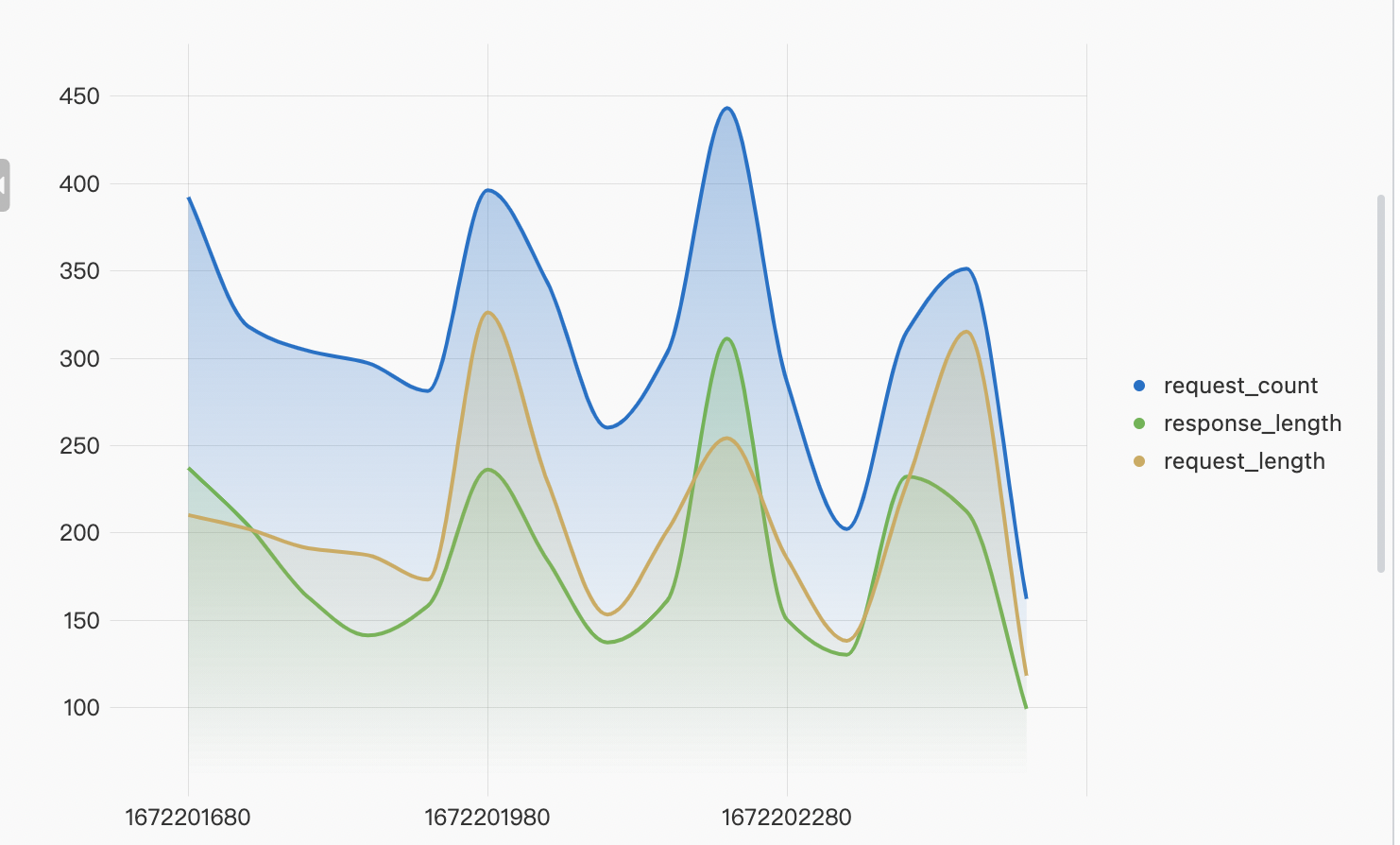
操作类别
not operation: - | select operation, count(1) as cnt from log group by operation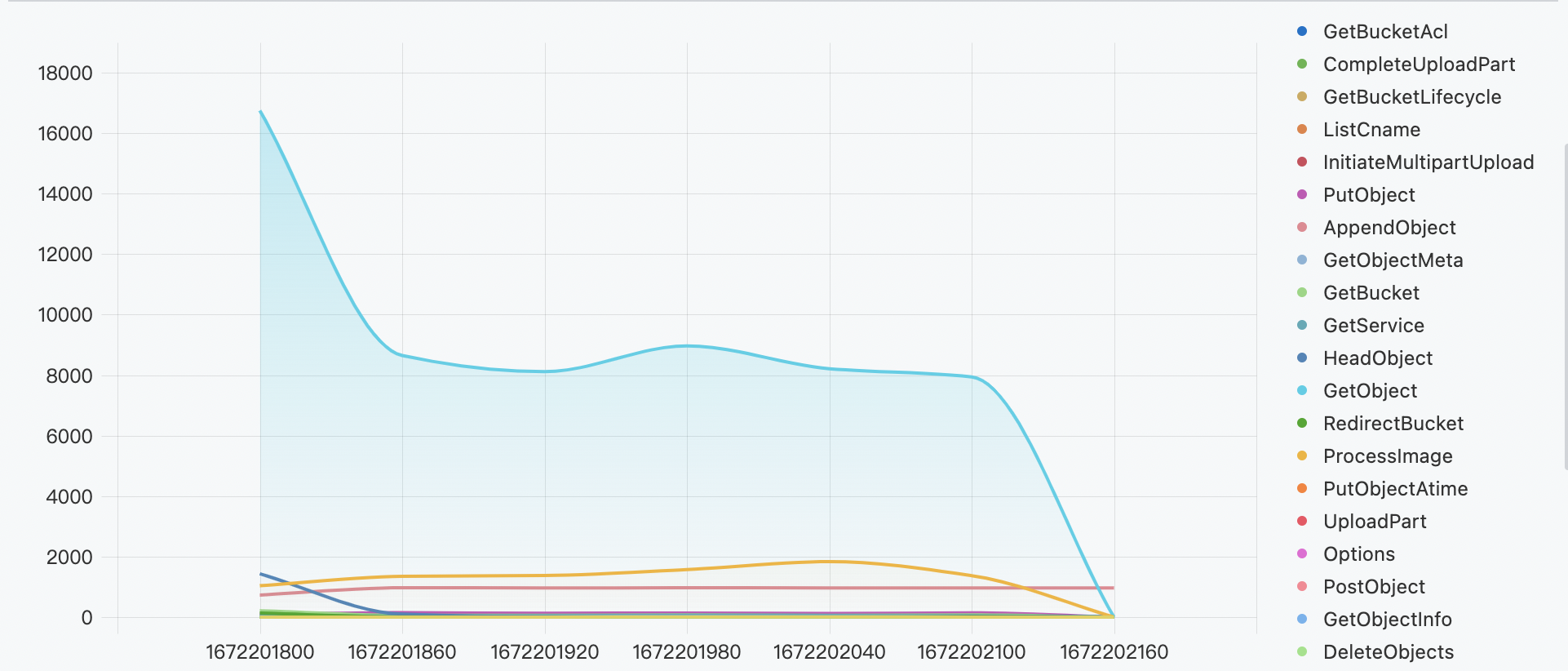
传输性能
(sync_request: - AND (NOT objectname:-) AND http_status < 300 AND ((OPERATION: GetObject AND response_time > 100 AND response_body_length > 100) OR (OPERATION: AppendObject OR OPERATION: PutObject OR OPERATION: UploadPart OR OPERATION: PostObject)))| SELECT if(sum((CASE WHEN OPERATION = 'GetObject' THEN response_time ELSE 0 END)) = 0, 0, round(sum((CASE WHEN OPERATION = 'GetObject' THEN response_body_length ELSE 0 END))*1.0/sum((CASE WHEN OPERATION = 'GetObject' THEN response_time ELSE 0 END))/1024, 2)) AS dowload, if(sum((CASE WHEN OPERATION <> 'GetObject' THEN response_time ELSE 0 END)) = 0, 0, round(sum((CASE WHEN OPERATION <> 'GetObject' THEN content_length_in ELSE 0 END))*1.0/sum((CASE WHEN OPERATION <> 'GetObject' THEN response_time ELSE 0 END))/1024, 2)) AS upload, (__time__ - __time__% 60) AS ts GROUP BY ts ORDER BY ts DESC LIMIT 1000000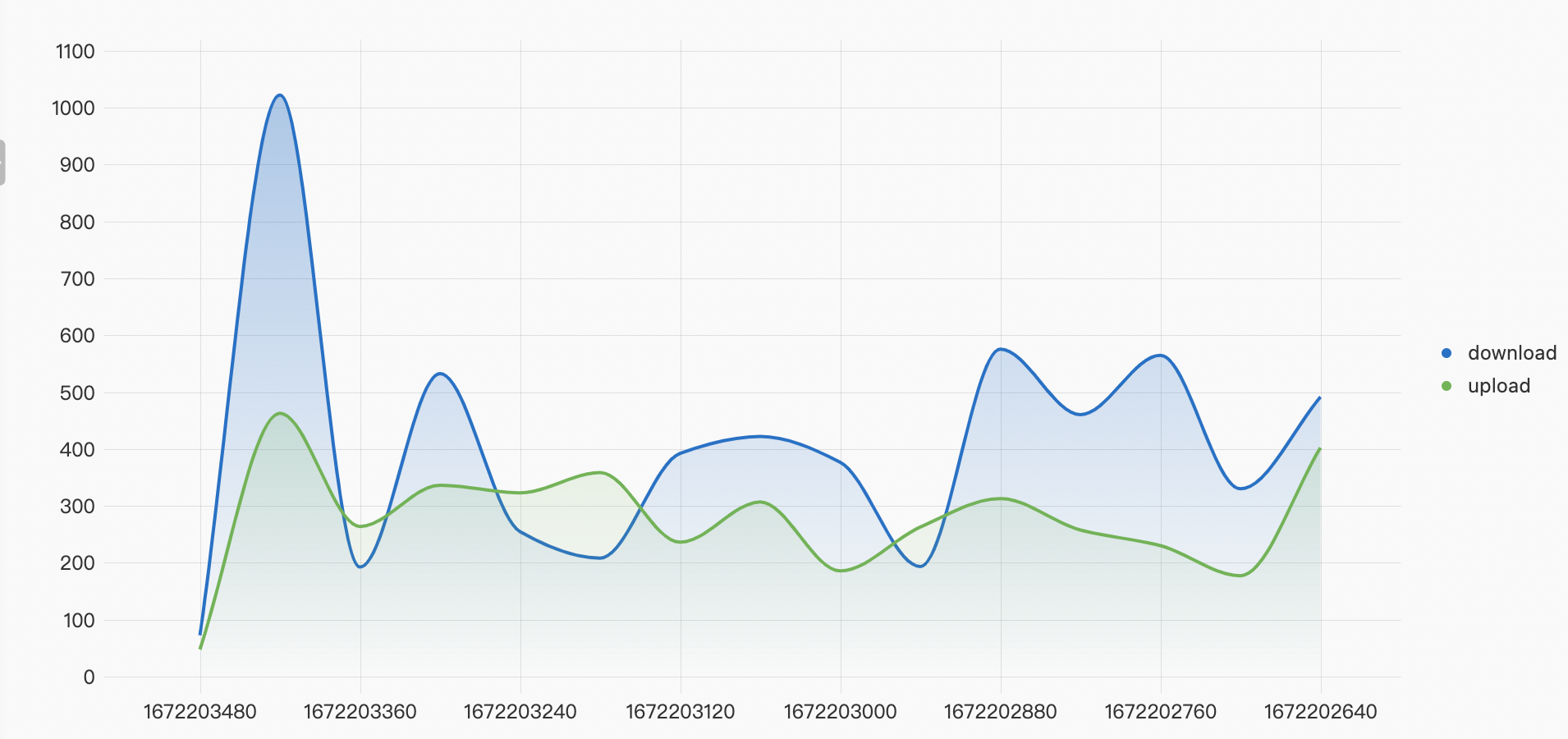
指标大盘
除此之外,还可以将服务指标保存为一张监控大盘,可以更为直观的随时查看服务当前状态。
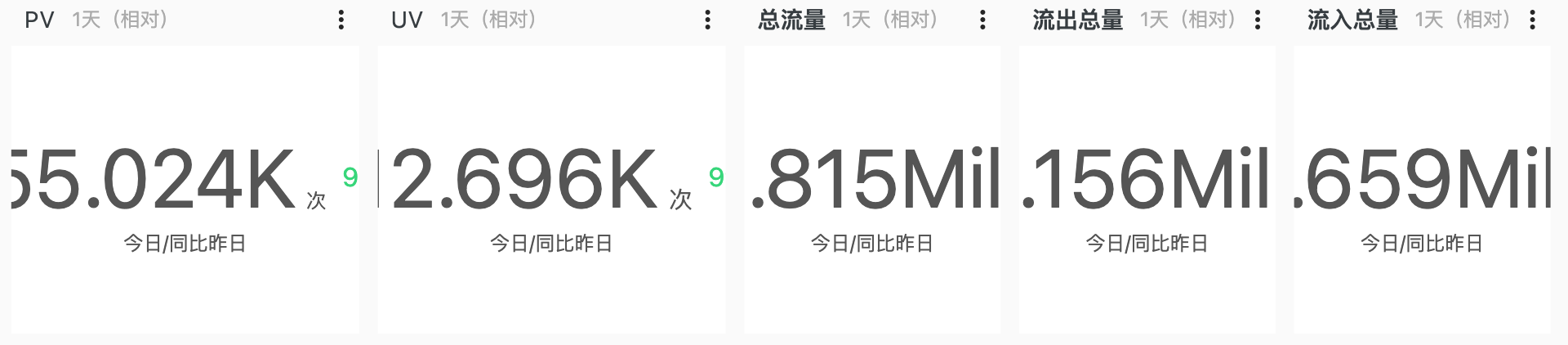
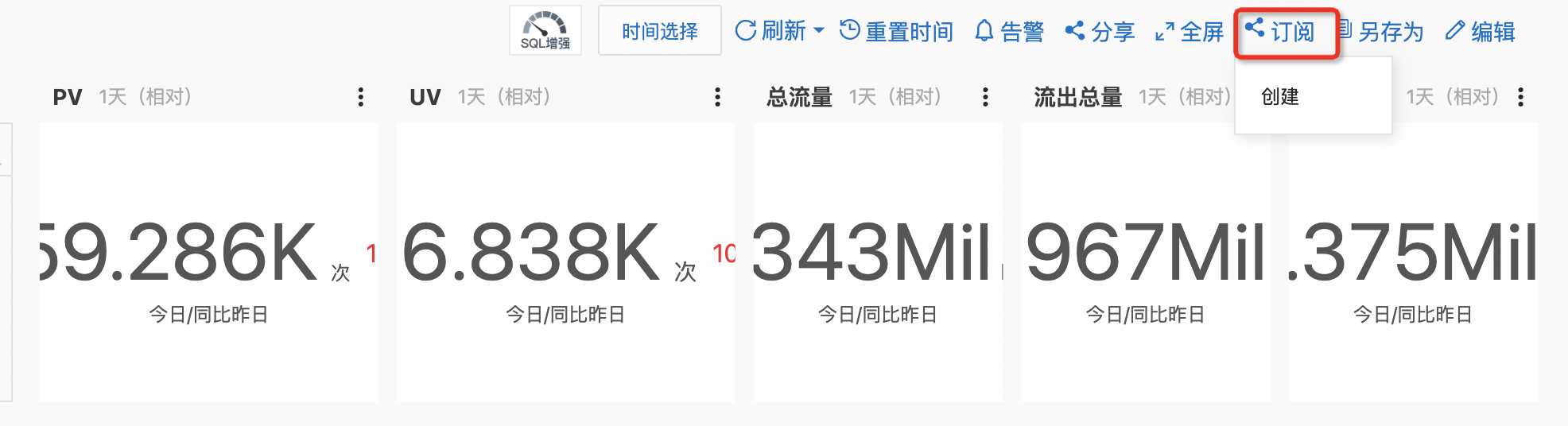
大盘订阅
除了能够随时查看大盘指标,日志服务还支持报表订阅,定期将仪表盘渲染为图片,通过邮件、钉钉等方式发送给指定人员。在大盘的右上角点击订阅按钮,随后点击创建,在弹出窗口中填写订阅相关的配置信息即可,非常方便。

监控告警
有了多种健康指标,我们就可以针对关键指标设置告警,及时发现问题。下面以请求流量变化为例介绍如何在sls中设置告警。
请求流量环比
通过服务指标中计算得到的请求流量request_length,我们可以计算环比:
*|select this_hour, last_hour, (this_hour - last_hour) as request_diff from ( select
(case when diff[1] is null then 0 else diff[1] end) as this_hour,
(case when diff[2] is null then 0 else diff[2] end) as last_hour
from (select compare(content_length_in/1024/1024/1024, 3600) as diff from log))
where (this_hour - last_hour) > 10当同环比的值大于给定阈值的时候,就应该触发告警,引起重视。
保存为告警
点击右上角的另存为告警按钮,在下拉框中选择新版告警,经过简单的配置即可存储为一个告警任务。关于告警的更多信息,可以查看官方文档。

自动检测
有时我们无法为监控告警设置一个固定的异常阈值,而是希望能够根据以往指标自动检测出异常情况。为此,日志服务提供了机器学习功能,能够为用户提供多种功能丰富的算法和便捷的调用方式,用户可以在日志查询分析中通过分析语句和机器学习函数调用机器学习算法,分析某一字段或若干字段在一段时间内的特征。
异常检测
下面以最常见的异常检测为例,介绍如何通过日志服务自动发现系统中的异常。日志服务提供了多种异常检测算法,我们选择ts_predicate_simple来检测请求流量异常:
select ts_predicate_simple(ts, content_length_in, 10) from (
select sum(content_length_in) as content_length_in, (__time__ - __time__ % 60) as ts from log
group by ts
)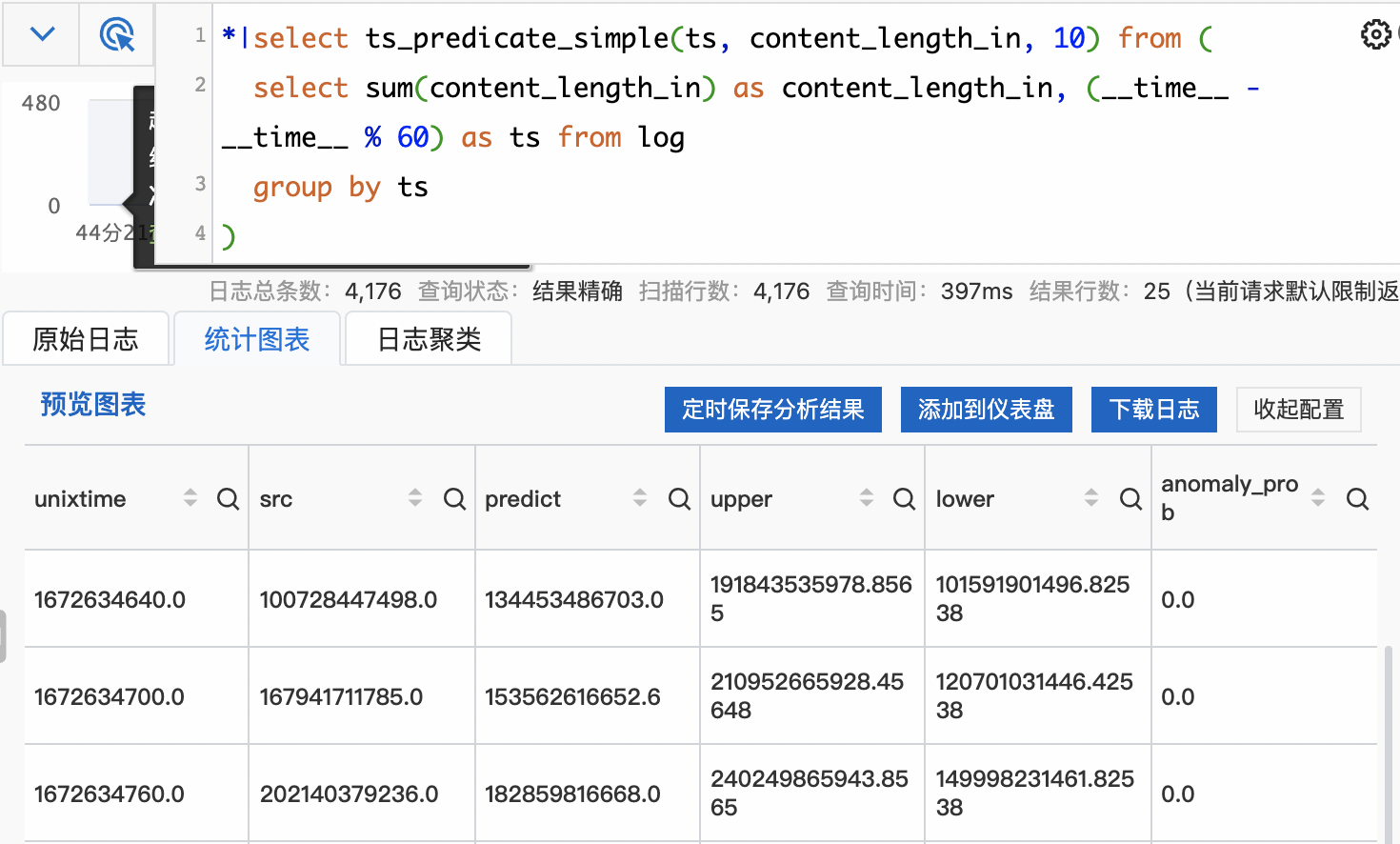
之后就可以根据anomaly_prob来判断流量的异常情况,在此过程中不涉及任何复杂的算法编写。
跨域安全
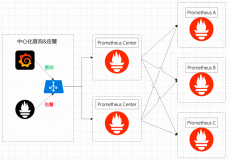
数据以及服务的跨域安全变得越来越重要,告警监控系统也不例外,我们需要保障访问日志或者据此计算出的服务指标的跨域安全。我们可以首先通过数据加工将指标数据搬运到其他地域,然后通过告警模板为这些指标配置相同的监控告警,确保其跨域安全性。
数据加工
日志服务的数据加工可用于数据的规整、富化、流转、脱敏和过滤,是极为便捷的流逝数据处理服务。我们这里仅仅使用其数据复制功能,关于数据加工的更多功能,可以参考官方文档。假如我们想把南京地域的指标数据复制到杭州,并加入地域标签,可以使用如下加工语句,点击预览数据查看效果:
e_set("data_region", "cn-nanjing")
e_output("cn-hangzhou-oss")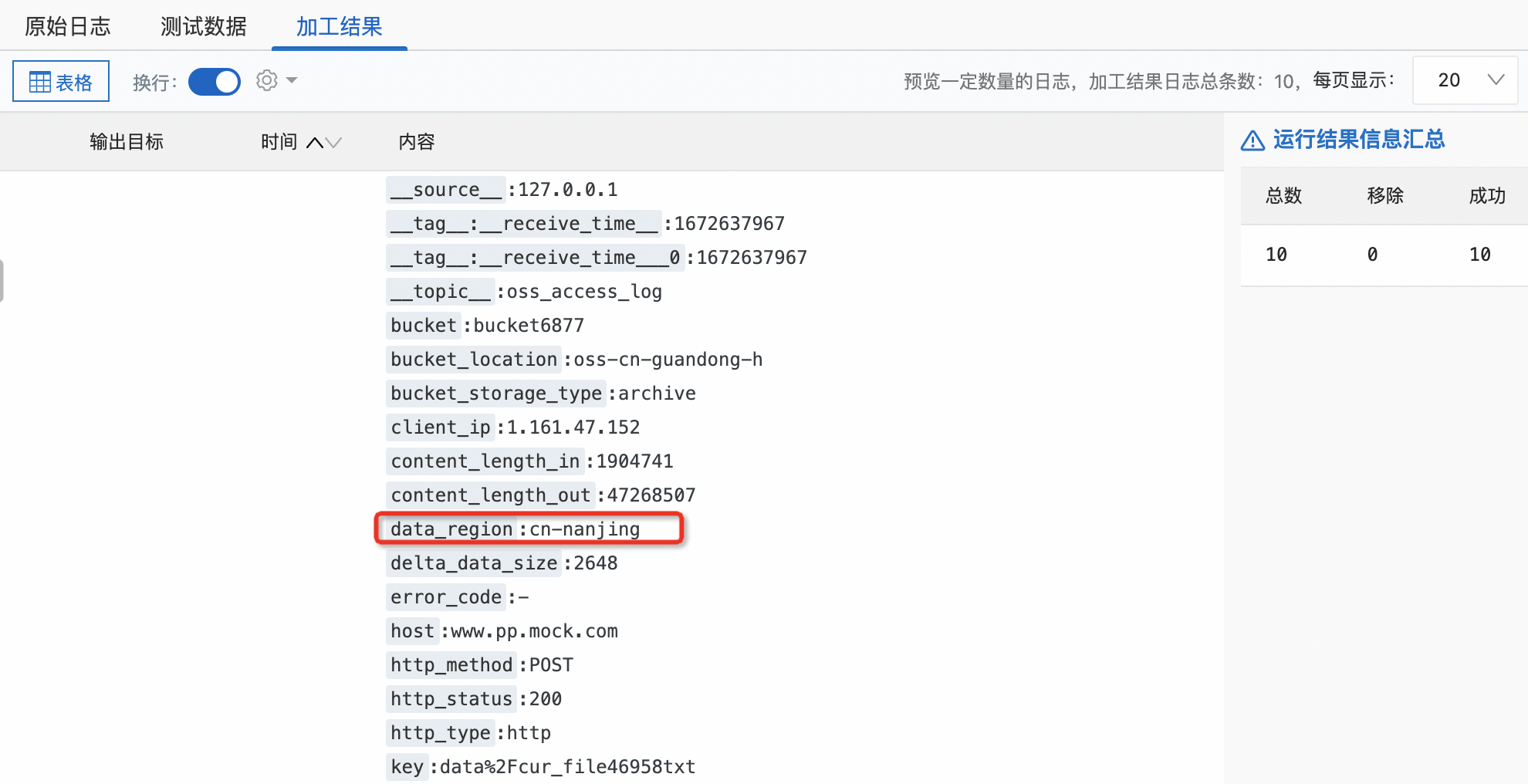
告警模板
为了方便用户将相同的告警规则应用到多个不同的数据源,日志服务提供了告警模板功能。只需要在告警中心找到对应的告警规则,点击转为模板即可。

总结
可以看到,日志服务提供了丰富多样的便捷功能方便客户监控服务的可用性。本文虽然是以OSS访问日志为例介绍的各项功能,但是同样的方法和功能适用于多种不同的云产品日志以及用户自定义日志。用户还可以在此基础上构建丰富的自定义指标,满足自己多样的业务需求。