
预测与异常检测函数通过预测时序曲线、寻找预测曲线和实际曲线之间误差的Ksigma与分位数等特性进行异常检测。
函数列表
函数 | 说明 |
利用默认参数对时序数据进行建模,并进行简单的时序预测和异常点的检测。 | |
使用自回归模型对时序数据进行建模,并进行简单的时序预测和异常点的检测。 | |
使用移动自回归模型对时序数据进行建模,并进行简单的时序预测和异常点检测。 | |
使用带有差分的移动自回归模型对时序数据进行建模,并进行简单的时序预测和异常点检测。 | |
针对具有周期性、趋势性的单时序序列,进行准确的预测。 使用场景:计量数据的预测、网络流量的预测、财务数据的预测、以及具有一定规律的不同业务数据的预测。 | |
针对批量曲线进行时序异常检测后,可以按照用户定义的异常模式来过滤异常检测的结果,帮助用户快速找出异常的实例曲线。 |
ts_predicate_simple
函数格式:
select ts_predicate_simple(x, y, nPred, isSmooth) 参数说明如下:
参数 | 说明 | 取值 |
x | 时间列,从小到大排列。 | 格式为Unixtime时间戳,单位为秒。 |
y | 数值列,对应某时刻的数据。 | - |
nPred | 预测未来的点的数量。 | long类型,取值大于等于1。 |
isSmooth | 是否需要对原始数据做滤波操作。 | bool类型,默认为true表示对原始数据做滤波操作。 |
示例:
查询分析
* | select ts_predicate_simple(stamp, value, 6) from (select ("__time__" - ("__time__" % 60)) as stamp, avg(v) as value from log GROUP BY stamp order by stamp)输出结果
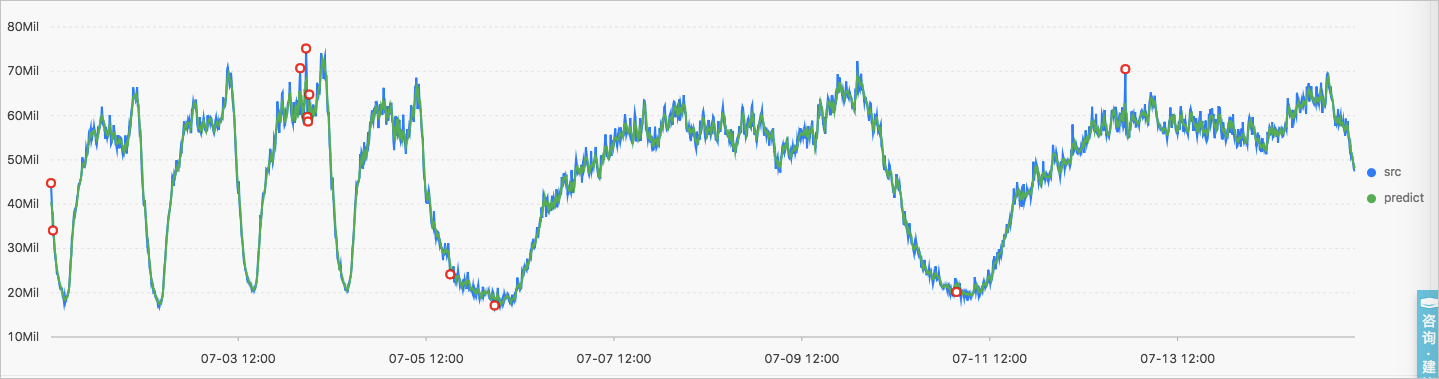
显示项如下:
显示项 | 说明 | |
横轴 | unixtime | 数据的Unixtime时间戳,单位为秒。 |
纵轴 | src | 原始数据。 |
predict | 预测的数据。 | |
upper | 预测的上界。当前置信度为0.85,不可修改。 | |
lower | 预测的下界。当前置信度为0.85,不可修改。 | |
anomaly_prob | 该点为异常点的概率,范围为0~1。 | |
ts_predicate_ar
函数格式:
select ts_predicate_ar(x, y, p, nPred, isSmooth) 参数说明如下:
参数 | 说明 | 取值 |
x | 时间列,从小到大排列。 | 格式为Unixtime时间戳,单位为秒。 |
y | 数值列,对应某时刻的数据。 | - |
p | 自回归模型的阶数。 | long类型,取值范围为2~8。 |
nPred | 预测未来的点的数量。 | long类型,取值范围为1~5*p。 |
isSmooth | 是否需要对原始数据做滤波操作。 | bool类型,默认为true表示对原始数据做滤波操作。 |
查询分析示例:
* | select ts_predicate_ar(stamp, value, 3, 4) from (select ("__time__" - ("__time__" % 60)) as stamp, avg(v) as value from log GROUP BY stamp order by stamp)输出结果与ts_predicate_simple函数相似,具体请参见ts_predicate_simple函数的输出结果。
ts_predicate_arma
函数格式:
select ts_predicate_arma(x, y, p, q, nPred, isSmooth) 参数说明如下:
参数 | 说明 | 取值 |
x | 时间列,从小到大排列。 | 格式为Unixtime时间戳,单位为秒。 |
y | 数值列,对应某时刻的数据。 | - |
p | 自回归模型的阶数。 | long类型,取值范围为2~100。 |
q | 移动平均模型的阶数。 | long类型,取值范围为2~8。 |
nPred | 预测未来的点的数量。 | long类型,取值范围为1~5*p。 |
isSmooth | 是否需要对原始数据做滤波操作。 | bool类型,默认为true表示对原始数据做滤波操作。 |
查询分析示例:
* | select ts_predicate_arma(stamp, value, 3, 2, 4) from (select ("__time__" - ("__time__" % 60)) as stamp, avg(v) as value from log GROUP BY stamp order by stamp) 输出结果与ts_predicate_simple函数相似,具体请参见ts_predicate_simple函数的输出结果。
ts_predicate_arima
函数格式:
select ts_predicate_arima(x, y, p, d, q, nPred, isSmooth) 参数说明如下:
参数 | 说明 | 取值 |
x | 时间列,从小到大排列。 | 格式为Unixtime时间戳,单位为秒。 |
y | 数值列,对应某时刻的数据。 | - |
p | 自回归模型的阶数。 | long类型,取值范围为2~8。 |
d | 差分模型的阶数。 | long类型,取值范围为1~3。 |
q | 移动平均模型的阶数。 | long类型,取值范围为2~8。 |
nPred | 预测未来的点的数量。 | long类型,取值范围为1~5*p。 |
isSmooth | 是否需要对原始数据做滤波操作。 | bool类型,默认为true表示对原始数据做滤波操作。 |
查询分析示例:
* | select ts_predicate_arima(stamp, value, 3, 1, 2, 4) from (select ("__time__" - ("__time__" % 60)) as stamp, avg(v) as value from log GROUP BY stamp order by stamp)输出结果与ts_predicate_simple函数相似,具体请参见ts_predicate_simple函数的输出结果。
ts_regression_predict
函数格式:
select ts_regression_predict(x, y, nPred, algotype,processType)参数说明如下:
参数 | 说明 | 取值 |
x | 时间列,从小到大排列。 | 格式为Unixtime时间戳,单位为秒。 |
y | 数值列,对应某时刻的数据。 | - |
nPred | 预测未来的点的数量。 | long类型,取值范围为1~500。 |
algotype | 针对的预测的算法类型。 | 取值包括:
|
processType | 数据对应的预处理流程。 | 取值包括:
|
示例:
查询分析
* and h : nu2h05202.nu8 and m: NET | select ts_regression_predict(stamp, value, 200, 'origin') from (select ("__time__" - ("__time__" % 60)) as stamp, avg(v) as value from log group by stamp order by stamp)输出结果
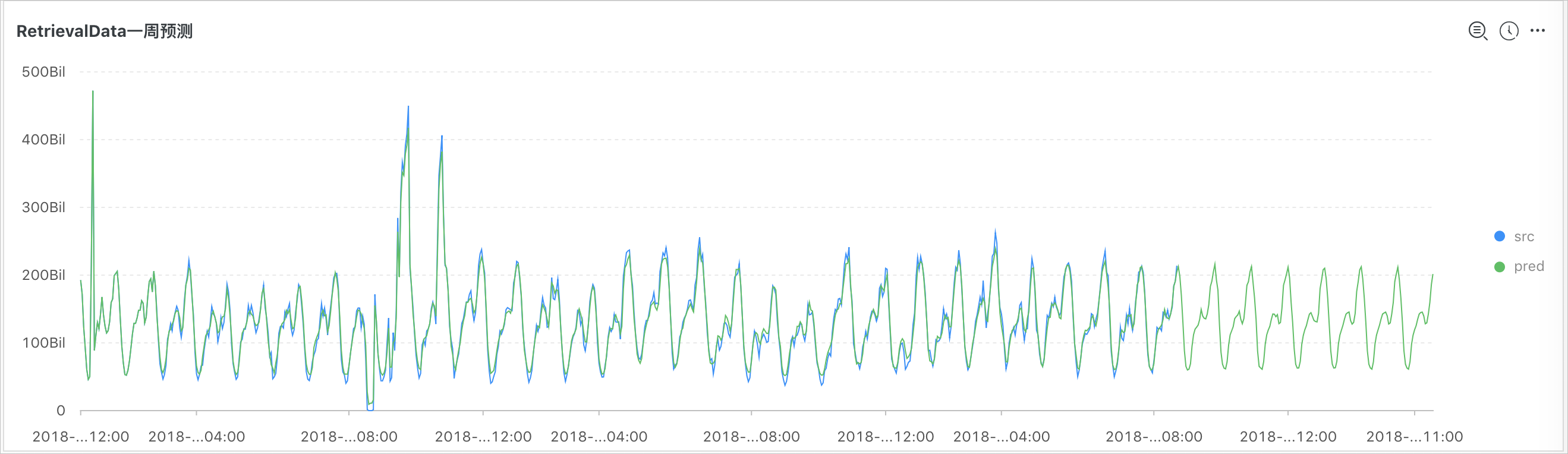
显示项如下:
显示项 | 说明 | |
横轴 | unixtime | 数据的Unixtime时间戳,单位为秒。 |
纵轴 | src | 原始数据。 |
predict | 预测数据。 | |
ts_anomaly_filter
函数格式:
select ts_anomaly_filter(lineName, ts, ds, preds, probs, nWatch, anomalyType)参数说明如下:
参数 | 说明 | 取值 |
lineName | varchar类型,表示每条曲线的名称。 | - |
ts | 曲线的时间序列,表示当前这条曲线的时间信息。array(double)类型,由小到大排列。 | - |
ds | 曲线的实际值序列,表示当前这条曲线的数值信息。array(double)类型,长度与ts相同。 | - |
preds | 曲线的预测值序列,表示当前这条曲线的预测值。array(double)类型,长度与ts相同。 | - |
probs | 曲线的异常检测序列,表示当前这条曲线的异常检测结果。array(double)类型,长度与ts相同。 | - |
nWatch | long类型,表示当前曲线中最近观测的实际值的数量,长度必须小于实际的曲线长度。 | - |
anomalyType | long类型,表示要过滤的异常类型的种类。 | 取值包括:
|
示例:
查询分析
* | select res.name, res.ts, res.ds, res.preds, res.probs from ( select ts_anomaly_filter(name, ts, ds, preds, probs, cast(5 as bigint), cast(1 as bigint)) as res from ( select name, res[1] as ts, res[2] as ds, res[3] as preds, res[4] as uppers, res[5] as lowers, res[6] as probs from ( select name, array_transpose(ts_predicate_ar(stamp, value, 10)) as res from ( select name, stamp, value from log where name like '%asg-%') group by name)) );输出结果
| name | ts | ds | preds | probs | | ------------------------ | ---------------------------------------------------- | ----------- | --------- | ----------- | | asg-bp1hylzdi2wx7civ0ivk | [1.5513696E9, 1.5513732E9, 1.5513768E9, 1.5513804E9] | [1,2,3,NaN] | [1,2,3,4] | [0,0,1,NaN] |