
通过ACK Edge集群,您可以轻松地将分布在不同地域的计算资源纳入统一管理,实现云原生应用的全生命周期管理和高效资源调度。本文将演示如何使用ACK Edge集群管理分布在多地域的ECS资源。
适用场景
您可以通过一个Kubernetes集群来统一管理以下场景中的ECS实例和应用。
在多个VPC中都有ECS实例。
在多个地域中都有ECS实例。
在多个账号中都有ECS实例。
管理多个地域分散的应用
在如下场景中,当有大量分散在不同地域的ECS需要统一管理或者部署相同的业务时,您可以创建一个ACK Edge集群来统一接入不同地域的ECS。具体操作,请参见下文示例一:使用ACK Edge集群管理地域分散的应用。
安全防护场景
在分布式计算环境中,为防止系统被恶意攻击、数据泄露等问题,通常需要在分布式资源上部署网络安全的Agent来为系统提供安全保障,您可以使用ACK Edge集群完成安全Agent的统一部署和运维。
分布式压测、拨测场景
在大规模的业务压测场景中,压测工具从各个地域同时发起压测任务。因此,压测工具需要部署在地域分散的资源中,您可以使用ACK Edge集群来纳管这些资源,快速地向不同地域部署压测工具。
缓存加速场景
分布式缓存加速服务需要在各个地域部署缓存服务,以加速网络内容的传输速度,您可以使用ACK Edge集群实现对分布式缓存服务的统一部署和运维。

解决单地域GPU资源不足问题
当您在某个地域部署任务时,如果遇到该地域下GPU资源不足的问题,您可以跨地域购买需要的GPU实例,然后将对应的GPU实例接入ACK Edge集群中,集群可以将任务调度到满足条件的GPU实例上。具体操作,请参见下文示例二:单地域GPU资源不足时,可跨地域购买GPU实例扩容。

方案优势
低成本:提供标准的云原生接口,采用云原生的方式运维分布式应用,降低业务运维成本。
免运维:Kubernetes集群的控制面由阿里云托管,并提供SLA保障,无需运维Kubernetes集群。
高可用:与已有的云产品,包括弹性、网络、存储、可观测等能力融合,保障应用的稳定运行。同时提供边缘自治、云边运维通道、单元化管理,支持中心管边场景下的运维、稳定性以及业务通信需求。
强兼容:支持数十种不同操作系统的异构计算资源接入。
高性能:优化了云边通信流量,成功降低了流量成本,单集群可纳管上千节点。
使用示例
示例一:使用ACK Edge集群管理地域分散的应用
准备环境
选择一个地域作为中心地域,在该地域下创建ACK Edge集群。
已安装OpenKruise组件。具体操作,请参见组件管理。
为每个地域分别创建边缘节点池, 并将ECS实例接入到对应的节点池中。
操作步骤
您可以通过原生的DaemonSet或者OpenKruise的DaemonSet两种方式部署并管理业务。
使用原生的DaemonSet
部署示例
登录容器服务管理控制台,在左侧导航栏选择集群列表。
在集群列表页面,单击目标集群名称,然后在左侧导航栏,选择。
在守护进程集页面,根据需求选择命名空间及部署方式,输入应用名称,选择类型为守护进程集(DaemonSet),根据提示完成部署。
关于部署守护进程集的更多信息,请参见创建守护进程集工作负载DaemonSet。
业务升级
在守护进程集页面,单击目标进程右侧操作列下的编辑,通过编辑DaemonSet的模板来实现业务版本及配置的升级。
使用OpenKruise的DaemonSet
部署示例
登录容器服务管理控制台,在左侧导航栏选择集群列表。
在集群列表页面,单击目标集群名称,然后在左侧导航栏,选择。
在容器组页面,单击使用YAML创建资源,然后选择示例模板为自定义,将需要部署的YAML复制粘贴至编辑框后,单击创建。
业务升级
在集群列表页面,单击目标集群名称,然后在左侧导航栏,选择。
在自定义资源页面,单击资源对象浏览器,找到对应的DaemonSet,在其右侧操作列下,单击YAML 编辑。通过编辑DaemonSet的模板来实现业务版本及配置的升级。
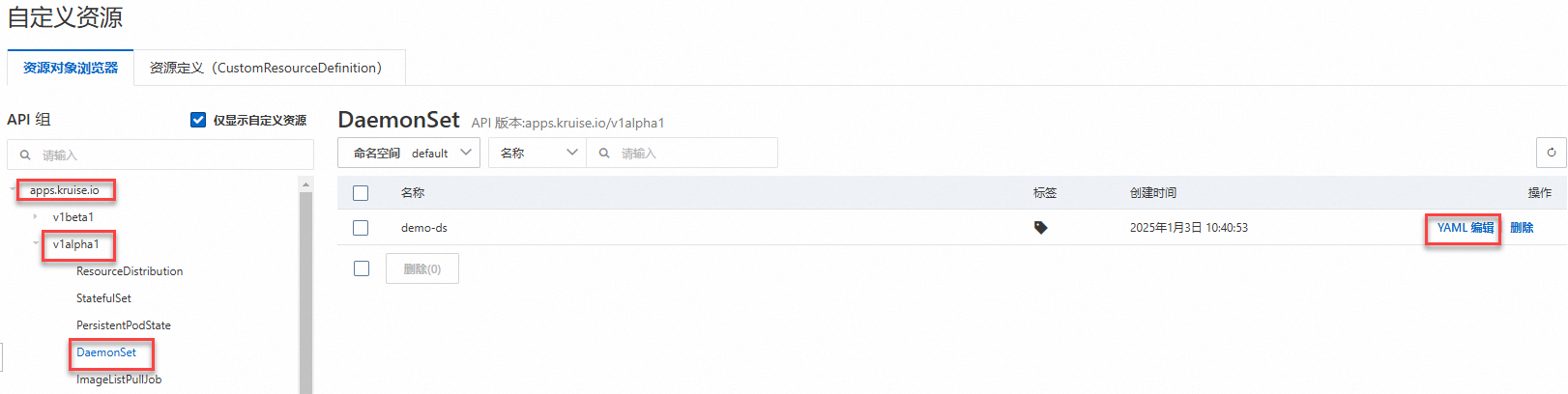
示例二:单地域GPU资源不足时,可跨地域购买GPU实例扩容
准备环境
操作步骤
本示例以部署推理任务为例,介绍当集群地域GPU资源不足时,如何通过ACK Edge集群接入跨地域的GPU实例,最终实现任务的调度部署。
部署推理任务并查看任务状态。
创建tensorflow-mnist.yaml文件。
部署推理任务。
kubectl apply -f tensorflow-mnist.yaml查看推理任务状态。
kubectl get pods预期输出:
NAME READY STATUS RESTARTS AGE tensorflow-mnist-664cf976d8-whrbc 0/1 pending 0 30s当前推理任务状态为
pending,经确认属于GPU资源不足问题。
创建边缘节点池。具体操作,请参见创建边缘节点池。
将GPU实例作为边缘节点,添加到已创建的边缘节点池中。具体操作,请参见添加GPU节点。
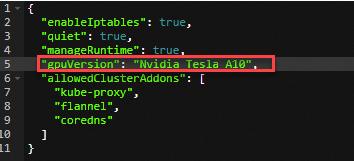
查看边缘节点状态。
kubectl get nodes预期输出:
NAME STATUS ROLES AGE VERSION cn-hangzhou.192.168.XX.XX Ready <none> 9d v1.30.7-aliyun.1 iz2ze21g5pq9jbesubr**** Ready <none> 8d v1.30.7-aliyun.1 izf8z0dko1ivt5kwgl4**** Ready <none> 8d v1.30.7-aliyun.1 izuf65ze9db2kfcethw**** Ready <none> 8d v1.30.7-aliyun.1 # 新添加的GPU边缘节点。查看推理任务的状态。
kubectl get pods -owide预期输出:
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES tensorflow-mnist-664cf976d8-whrbc 1/1 running 0 23m 10.12.XX.XX izuf65ze9db2kfcethw**** <none> <none>预期输出表明,推理任务已调度到新添加的GPU节点上,并部署成功。