
本文介绍Nginx Ingress异常问题的诊断流程、排查思路、常见检查方法和解决方案。
本文目录
类别 | 内容 |
诊断流程 | |
排查思路 | |
常见排查方法 | |
常见问题及解决方案 |
|
背景信息
当前Kubernetes社区官方维护的是Ingress NGINX Controller。ACK的Nginx Ingress Controller组件采用Kubernetes社区提供的版本,支持社区所有的Annotations 配置。
为了使Nginx Ingress资源正常工作,集群中必须要有一个Nginx Ingress Controller来解析Nginx Ingress的转发规则。Nginx Ingress Controller收到请求,匹配Nginx Ingress转发规则,将请求转发到后端Service所对应的Pod,由Pod处理请求。Kubernetes中的Service、Nginx Ingress与Nginx Ingress Controller有着以下关系:
Service是后端真实服务的抽象,一个Service可以代表多个相同的后端服务。
Nginx Ingress是反向代理规则,用来规定HTTP/HTTPS请求应该被转发到哪个Service所对应的Pod上。例如根据请求中不同的Host和URL路径,让请求落到不同的Service所对应的Pod上。
Nginx Ingress Controller是Kubernetes集群中的一个组件,负责解析Nginx Ingress的反向代理规则。如果Nginx Ingress有增删改的变动,Nginx Ingress Controller会及时更新自己相应的转发规则,当Nginx Ingress Controller收到请求后就会根据这些规则将请求转发到对应Service的Pod上。
Nginx Ingress Controller通过API Server获取Ingress资源的变化,动态地生成负载均衡(例如Nginx)所需的配置文件(例如nginx.conf),然后重新加载负载均衡(例如执行nginx -s reload重新加载Nginx)来生成新的路由转发规则。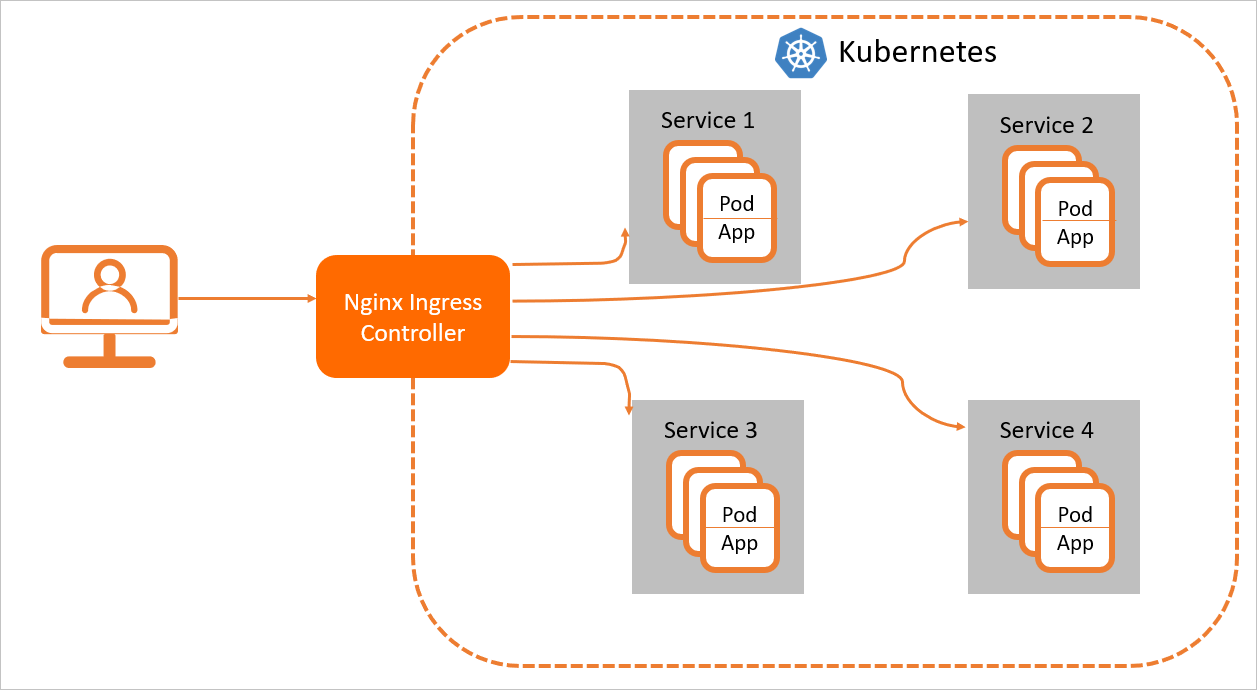
诊断流程
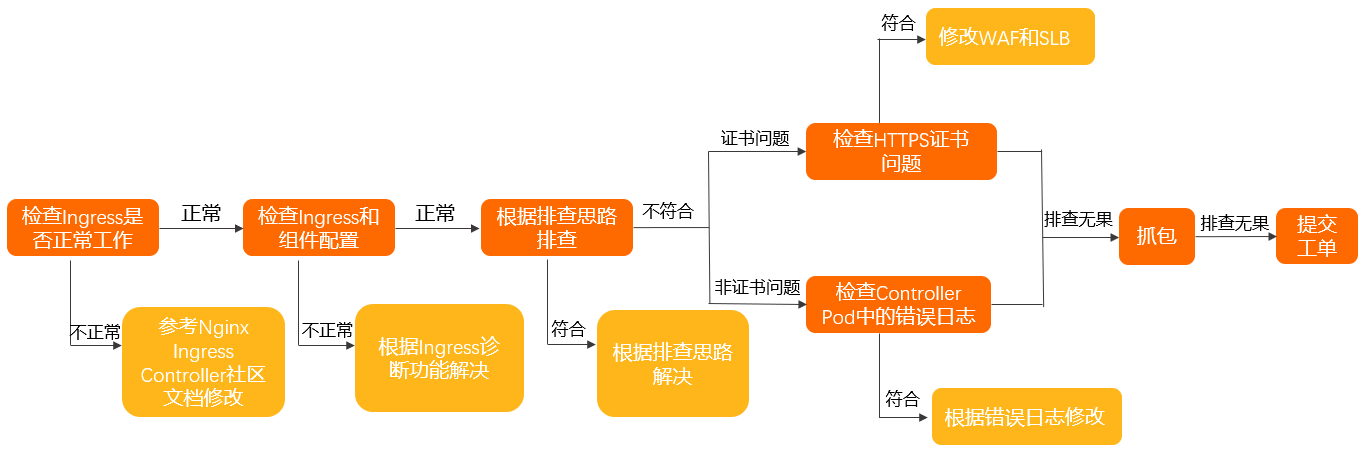
按照以下步骤,检查是否是由于Ingress所导致的问题,确保Ingress Controller的配置正确。
在Controller Pod中确认访问是否符合预期。具体操作,请参见在Controller Pod中手动访问Ingress和后端Pod。
确认Nginx Ingress Controller使用方法正确。具体操作,请参见Nginx Ingress社区使用文档。
使用Ingress诊断功能检查Ingress和组件配置,并且根据相关提示进行修改。关于Ingress诊断功能具体操作,请参见使用Ingress诊断功能。
按照排查思路,确认相关问题及解决方案。
如果以上排查无果,请按照以下步骤排查:
针对HTTPS证书问题:
检查域名上是否启用了WAF接入或WAF透明接入。
如果启用了,请确认WAF或透明WAF没有设置TLS证书。
如果没启用,请执行下一步。
检查SLB是否为七层监听。
如果是,请确认SLB七层监听上没有设置TLS证书。
如果不是,请执行下一步。
非HTTPS证书问题,检查Controller Pod中错误日志。具体操作,请参见检查Controller Pod中错误日志。
如果以上排查无果,请在Controller Pod和对应后端的业务Pod中进行抓包,确认问题。具体操作,请参见抓包。
排查思路
排查思路 | 问题现象 | 解决方案 |
访问不通 | 集群内部Pod到Ingress访问不通 | |
Ingress访问自己不通 | ||
无法访问TCP、UDP服务 | ||
HTTPS访问出现问题 | 证书未更新或返回默认证书 | |
返回 | ||
添加Ingress资源时出现问题 | 报错failed calling webhook... | |
添加了Ingress,但是没有生效 | ||
访问不符合预期 | 无法获得客户端源IP | |
IP白名单不生效或不按预期生效 | ||
无法连接到通过Ingress暴露的gRPC服务 | ||
灰度不生效 | ||
灰度规则错误或影响到别的流量 | ||
出现 | ||
出现502、503、413、499等错误 | ||
加载页面时部分资源加载不出来 | 配置了 | |
资源访问时出现 |
常见检查方法
使用Ingress诊断功能
登录容器服务管理控制台,在左侧导航栏选择集群列表。
在集群列表页面,单击目标集群名称,然后在左侧导航栏,选择。
在故障诊断页面,单击Ingress诊断。
在Ingress诊断面板,单击诊断,然后输入出现问题的URL,例如https://www.example.com。选中我已知晓并同意,然后单击发起诊断。
诊断完成后,根据诊断结果解决问题。
通过日志服务SLS的Controller Pod查看访问日志
Ingress Controller访问日志格式可以在ConfigMap中看到(默认ConfigMap为kube-system命名空间下的nginx-configuration)。
ACK Ingress Controller默认的日志格式为:
$remote_addr - [$remote_addr] - $remote_user [$time_local]
"$request" $status $body_bytes_sent "$http_referer" "$http_user_agent" $request_length
$request_time [$proxy_upstream_name] $upstream_addr $upstream_response_length
$upstream_response_time $upstream_status $req_id $host [$proxy_alternative_upstream_name]改动日志格式后,SLS的日志收集规则也需要做相应改动,否则无法在SLS日志控制台看到正确日志信息,请您谨慎修改日志格式。
日志服务控制台的Ingress Controller日志如下图所示。具体操作,请参见采集ACK集群容器日志。
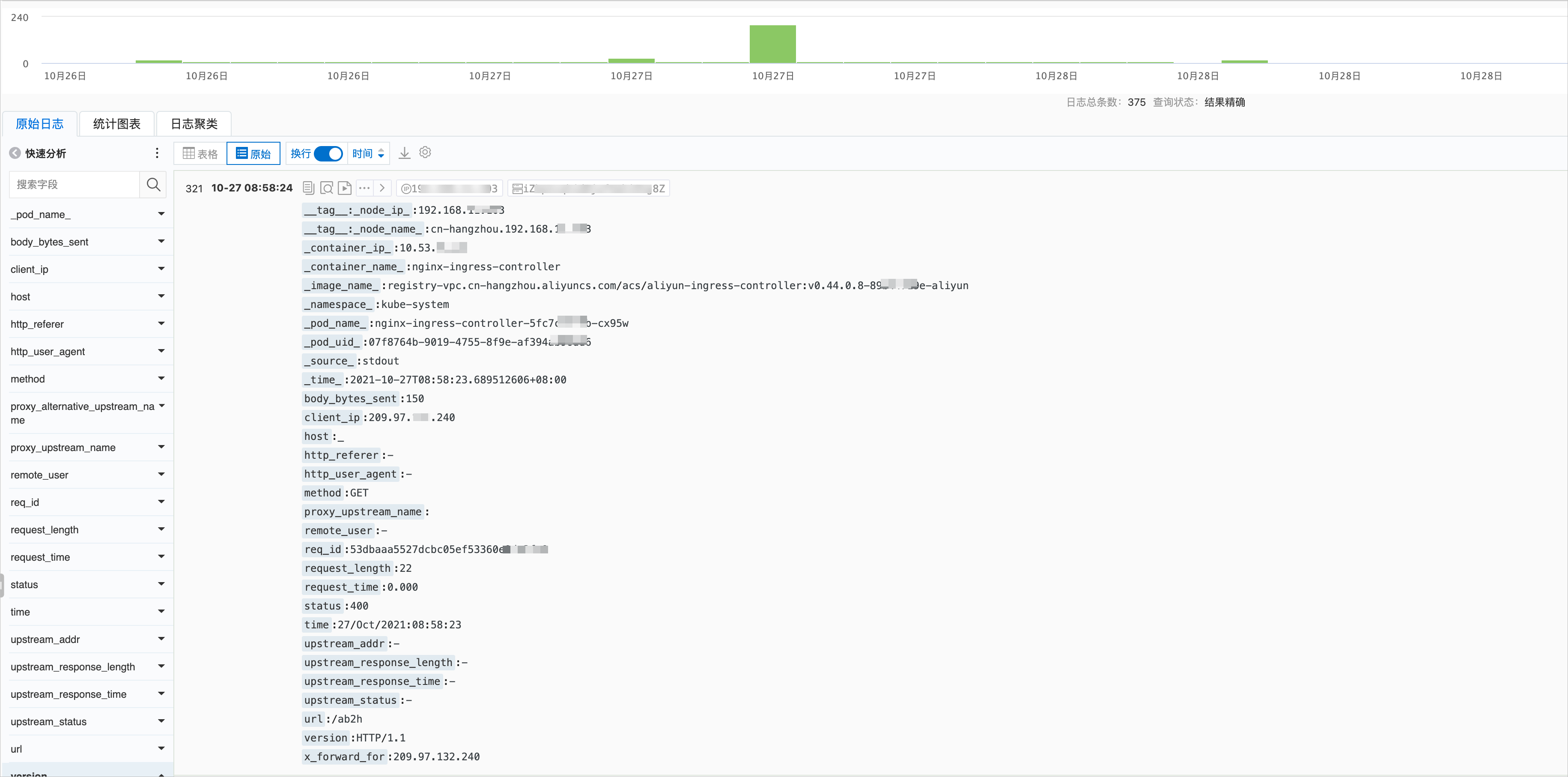
日志服务控制台的日志和实际日志字段名称会有部分不同,已在下表列出,字段解释如下表所示。
字段 | 说明 |
| 客户端的真实IP。 |
| 请求的信息。包括请求的方法、URL以及HTTP版本。 |
| 本次请求的时间。从接收客户端请求起,到发送完响应数据的总时间。该值可能会受到客户端网络条件等因素的影响,无法代表请求真实的处理速度。 |
| 后端upstream的地址,如果该请求没有到达后端,则该值为空。当后端因为失败请求多个upstream时,该值为半角逗号(,)分隔列表。 |
| 后端upstream返回的 HTTP code。如果该值为正常 HTTP status code,代表该值由后端upstream返回。当没有后端可以访问时,该值为502。有多个值时由半角逗号(,)分开。 |
| 后端upstream的响应时间,单位为秒。 |
| 后端upstream的名称。命名规则为 |
| 后端alternative upstream的名称。当该请求转发到alternative upstream(例如使用Canary设置的灰度服务)时,该值不为空。 |
默认情况下,执行以下命令,您也可以直接在容器中看到近期的访问日志。
kubectl logs <controller pod name> -n <namespace> | less预期输出:
42.11.**.** - [42.11.**.**]--[25/Nov/2021:11:40:30 +0800]"GET / HTTP/1.1" 200 615 "_" "curl/7.64.1" 76 0.001 [default-nginx-svc-80] 172.16.254.208:80 615 0.000 200 46b79dkahflhakjhdhfkah**** 47.11.**.**[]
42.11.**.** - [42.11.**.**]--[25/Nov/2021:11:40:31 +0800]"GET / HTTP/1.1" 200 615 "_" "curl/7.64.1" 76 0.001 [default-nginx-svc-80] 172.16.254.208:80 615 0.000 200 fadgrerthflhakjhdhfkah**** 47.11.**.**[]检查Controller Pod中错误日志
您可以根据Ingress Controller Pod中的日志,进一步缩小问题范围。Controller Pod中错误日志分为以下两种:
Controller错误日志:一般在Ingress配置错误时产生,可以执行以下命令过滤出Controller错误日志。
kubectl logs <controller pod name> -n <namespace> | grep -E ^[WE]说明Ingress Controller在启动时会产生若干条W(Warning)等级错误,属于正常现象。例如未指定kubeConfig或未指定Ingress Class等Warning信息,这些Warning信息不影响Ingress Controller的正常运行,因此可以忽略。
Nginx错误日志:一般在处理请求出现错误时产生,可以执行以下命令过滤出Nginx错误日志。
kubectl logs <controller pod name> -n <namespace> | grep error
在Controller Pod中手动访问Ingress和后端Pod
执行以下命令,进入Controller Pod。
kubectl exec <controller pod name> -n <namespace> -it -- bashPod中已预装好了curl、OpenSSL等工具,您可以通过这些工具测试连通性、证书配置的正确性等。
执行以下命令,测试能否通过Ingress访问到后端。
# 请将your.domain.com替换为实际要测试的域名。 curl -H "Host: your.domain.com" http://127.0.0.1/ # for http curl --resolve your.domain.com:443:127.0.0.1 https://127.0.0.1/ # for https执行以下命令,验证证书信息。
openssl s_client -servername your.domain.com -connect 127.0.0.1:443访问后端Pod测试的正确性。
说明Ingress Controller不会通过Service Cluster IP的形式来访问后端Pod,而是直接访问后端Pod IP。
执行以下命令,通过kubectl获得后端Pod IP。
kubectl get pod -n <namespace> <pod name> -o wide预期输出:
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES nginx-dp-7f5fcc7f-**** 1/1 Running 0 23h 10.71.0.146 cn-beijing.192.168.**.** <none> <none>由预期输出获得,后端Pod IP为10.71.0.146。
执行以下命令,在Controller Pod中访问该Pod,确认Controller Pod到后端Pod能够正常连通。
curl http://<your pod ip>:<port>/path
Nginx Ingress排查相关命令
kubectl-plugin
Kubernetes官方Ingress控制器原先基于Nginx,但自0.25.0版本起改用OpenResty。控制器通过监听API Server上Ingress资源的更改,自动产生相应的Nginx配置,然后Reload重新加载配置以使之生效。更多详情,请参见官方文档。
随着Ingress数量增加,所有配置汇聚于单一的Nginx.conf文件,造成配置文件过长且难以调试。尤其是从0.14.0版本开始,Upstream部分采用Lua-resty-balancer动态生成,增加了调试难度。因此,社区贡献了一个Kubectl插件Ingress-nginx,以简化Ingress-nginx配置的调试过程。相关操作,请参见kubectl-plugin。
执行以下命令,获取Ingress-nginx控制器当前已知后端的服务信息。
kubectl ingress-nginx backends -n ingress-nginxdbg命令
除了Kubectl-plugin插件方式外,也可以使用
dbg命令来进行相关信息的查看和诊断。执行以下命令,进入Nginx Ingress容器。
kubectl exec -it -n kube-system <nginx-ingress-pod-name> -- bash执行
/dbg命令可看到如下输出。nginx-ingress-controller-69f46d8b7-qmt25:/$ /dbg dbg is a tool for quickly inspecting the state of the nginx instance Usage: dbg [command] Available Commands: backends Inspect the dynamically-loaded backends information certs Inspect dynamic SSL certificates completion Generate the autocompletion script for the specified shell conf Dump the contents of /etc/nginx/nginx.conf general Output the general dynamic lua state help Help about any command Flags: -h, --help help for dbg --status-port int Port to use for the lua HTTP endpoint configuration. (default 10246) Use "dbg [command] --help" for more information about a command.
查看某个域名对应的证书是否存在。
/dbg certs get <hostname>查看当前所有后端服务信息。
/dbg backends all
Nginx Ingress状态
Nginx包含一个自检模块,可输出运行统计信息;在Nginx Ingress容器中,通过Curl访问10246端口的nginx_status,可以查看Nginx的请求和连接统计数据。
执行以下命令,进入Nginx Ingress容器。
kubectl exec -itn kube-system <nginx-ingress-pod-name> bash执行以下命令,查看当前Nginx的请求、连接相关统计状态信息。
nginx-ingress-controller-79c5b4d87f-xxx:/etc/nginx$ curl localhost:10246/nginx_status Active connections: 12818 server accepts handled requests 22717127 22717127 823821421 Reading: 0 Writing: 382 Waiting: 12483自Nginx启动以来,它接受并处理了22717127个连接,且每个连接都成功处理,未出现立即关闭的情况。这22717127个连接共处理了823821421个请求,意味着每个连接平均处理约36.2个请求。
Active connections:表示当前Nginx服务器上的活跃连接总数为12818个。
Reading:表示Nginx当前正在读取请求头的连接数是0。
Writing:表示Nginx当前正在发送响应的连接数是382。
Waiting:表示保持长连接(keep-alive)的连接数12483个。
抓包
当无法定位问题时,需要抓包进行辅助诊断。
根据初步问题定位结果,简单判断网络问题出现在Ingress Pod还是业务Pod。如果信息不足,可以对两方的包都进行抓取。
登录出现异常的业务Pod或Ingress Pod所在节点。
在ECS(非容器内)执行以下命令,可以将Ingress流量信息抓取到文件中。
tcpdump -i any host <业务Pod IP或Ingress Pod IP> -C 20 -W 200 -w /tmp/ingress.pcap观察日志,当出现预期错误时,结束抓包。
结合业务日志的报错,定位到精准的报错时间的报文信息。
说明在正常情况下,抓包对业务无影响,仅会增加小部分的CPU负载和磁盘写入。
以上命令会对抓取到的包进行轮转,最多可以生成200个20 MB的.pcap文件。
集群内访问集群LoadBalancer外部地址不通
问题现象
集群中有部分节点下的Pod通过Nginx Ingress Controller外部地址(负载均衡实例IP地址)无法访问后端Pod,部分能够访问。
问题原因
该问题由而Controller所属Service的externalTrafficPolicy配置导致,该配置决定了外部流量的处理规则:当设置为local时,仅有与Controller所属Pod处于同一节点的后端Pod可以成功接收请求;当设置为cluster时,则可以正常访问。而集群中的资源使用LoadBalancer的外部地址访问时,请求也会被作为外部流量处理。
解决方案
(推荐)在Kubernetes集群内通过ClusterIP或者Ingress的服务名访问。其中Ingress的服务名为
nginx-ingress-lb.kube-system。执行
kubectl edit svc nginx-ingress-lb -n kube-system命令,修改Ingress的服务。将LoadBalancer的Service中externalTrafficPolicy修改为Cluster。如果集群容器网络插件为Flannel,请求会丢失客户端源IP,如果使用Terway则可保留源IP。
示例如下:
apiVersion: v1 kind: Service metadata: annotations: service.beta.kubernetes.io/backend-type: eni # 直通ENI。 labels: app: nginx-ingress-lb name: nginx-ingress-lb namespace: kube-system spec: externalTrafficPolicy: Cluster关于Service的Annotation的更多信息,请参见通过Annotation配置传统型负载均衡CLB。
无法访问Ingress Controller自己
问题现象
对于Flannel集群,在Ingress Pod中通过域名、SLB IP、Cluster IP访问Ingress自身时,出现部分请求或全部请求不成功的情况。
问题原因
Flannel目前的默认配置不允许回环访问。
解决方案
(推荐)如果条件允许,建议您重建集群,并使用Terway的网络插件,将现有集群业务迁移至Terway模式集群中。
如果没有重建集群的条件,可以通过修改Flannel配置,开启
hairpinMode解决。配置修改完成后,重建Flannel Pod使修改生效。执行以下命令,编辑Flannel。
kubectl edit cm kube-flannel-cfg -n kube-system在返回结果cni-conf.json中的
delegate增加"hairpinMode": true。示例如下:
cni-conf.json: | { "name": "cb0", "cniVersion":"0.3.1", "type": "flannel", "delegate": { "isDefaultGateway": true, "hairpinMode": true } }执行以下命令,删除重建Flannel。
kubectl delete pod -n kube-system -l app=flannel
集群中添加或修改了TLS证书,但是访问时还是默认证书或旧的证书
问题现象
您已经在集群中添加或修改Secret并在Ingress中指定secretName后,访问集群仍使用了默认的证书(Kubernetes Ingress Controller Fake Certificate)或旧的证书。
问题原因
证书不是由集群内Ingress Controller返回的。
证书无效,未能被Controller正确加载。
Ingress Controller根据SNI来返回对应证书,但TLS握手时可能未携带SNI。
解决方案
通过以下任一方式,确认建立TLS连接时是否携带了SNI字段:
使用支持SNI的较新版本浏览器。
使用
openssl s_client命令测试证书时,携带-servername参数。使用
curl命令时,添加hosts或使用--resolve参数映射域名,而不是使用IP+Host请求头的方式。
确认WAF、WAF透明接入或SLB七层监听上没有设置TLS证书,TLS证书应该由集群内Ingress Controller返回的。
在智能运维控制台进行Ingress诊断,观察是否存在配置错误和错误日志。具体操作,请参见使用Ingress诊断功能。
执行以下命令,手动查看Ingress Pod错误日志,根据错误日志中相关提示进行修改。
kubectl logs <ingress pod name> -n <pod namespace> | grep -E ^[EW]
无法连接到通过Ingress暴露的gRPC服务
问题现象
通过Ingress无法访问到其后的gRPC服务。
问题原因
未在Ingress资源中设置Annotation,指定后端协议类型。
gRPC服务只能通过TLS端口进行访问。
解决方案
在对应Ingress资源中设置Annotation:
nginx.ingress.kubernetes.io/backend-protocol:"GRPC"。确认客户端发送请求时使用的是TLS端口,并且将流量加密。
无法连接到后端HTTPS服务
问题现象
通过Ingress无法访问到其后的HTTPS服务。
访问时回复可能为400,并提示
The plain HTTP request was sent to HTTPS port。
问题原因
Ingress Controller到后端Pod请求使用了默认的HTTP请求。
解决方案
在Ingress资源中设置Annotation:nginx.ingress.kubernetes.io/backend-protocol:"HTTPS"。
Ingress Pod中无法保留源IP
问题现象
Ingress Pod中无法保留真实客户端IP,显示为节点IP或100.XX.XX.XX网段或其他地址。
问题原因
Ingress所使用的Service中
externalTrafficPolicy设为了Cluster。SLB上使用了七层代理。
使用了WAF接入或WAF透明接入服务。
解决方案
对于设置
externalTrafficPolicy为Cluster,且前端使用了四层SLB的情况。可以将
externalTrafficPolicy改为Local。但这可能会导致集群内部使用SLB IP访问Ingress不通,具体解决方案,请参见集群内访问集群LoadBalancer外部地址不通。对于使用了七层代理(七层SLB、WAF、透明WAF)的情况,可以按以下步骤解决:
确保使用的七层代理且开启了X-Forwarded-For请求头。
在Ingress Controller的ConfigMap中(默认为kube-system命名空间下的nginx-configuration)添加
enable-real-ip: "true"。观察日志,验证是否可以获取到源IP。
对于链路较长,存在多次转发的情况(例如在Ingress Controller前额外配置了反向代理服务),可以在开启
enable-real-ip时通过观察日志中remote_addr的值,来确定真实IP是否是以X-Forwarded-For请求头传递到Ingress容器中。若不是,请在请求到达Ingress Controller之前利用X-Forwarded-For等方式携带客户端真实IP。
灰度规则不生效
问题现象
在集群内设置了灰度,但是灰度规则不生效。
问题原因
可能原因有两种:
在使用
canary-*相关Annotation时,未设置nginx.ingress.kubernetes.io/canary: "true"。在使用
canary-*相关Annotation时,0.47.0版本前的Nginx Ingress Controller,需要在Ingress规则里的Host字段中填写您的业务域名,不能为空。
解决方案
根据上述原因,修改
nginx.ingress.kubernetes.io/canary: "true"或Ingress规则里的Host字段。详细信息,请参见路由规则。如果上述情况不符合,请参见流量分发与灰度规则不一致或其他流量进入灰度服务。
流量分发与灰度规则不一致或其他流量进入灰度服务
问题现象
设置了灰度规则,但是流量没有按照灰度规则进行分发,或者有其他正常Ingress的流量进入灰度服务。
问题原因
Nginx Ingress Controller中,灰度规则不是应用在单个Ingress上,而是会应用在所有使用同一个Service的Ingress上。
关于产生该问题的详情,请参见带有灰度规则的Ingress将影响所有具有相同Service的Ingress。
解决方案
针对需要开启灰度的Ingress(包括使用service-match和canary-*相关Annotation),创建独立的Service(包括正式和灰度两个Service)指向原有的Pod,然后再针对该Ingress启用灰度。更多详情,请参见通过Nginx Ingress实现灰度发布和蓝绿发布。
创建Ingress资源时报错 "failed calling webhook"
问题现象
添加Ingress资源时显示"Internal error occurred: failed calling webhook...",如下图所示。

问题原因
在添加Ingress资源时,需要通过服务(默认为ingress-nginx-controller-admission)验证Ingress资源的合法性。如果链路出现问题,(例如服务被删除,Ingress controller被删除),会导致验证失败,拒绝添加Ingress资源。
解决方案
按照Webhook链路检查资源是否均存在且正常工作,链路为ValidatingWebhookConfiguration→Service→Pod。
确认Ingress Controller Pod的admission功能已打开,且能够正常从外部访问到该Pod。
如果Ingress Controller已被删除或不需要Webhook功能,可以直接将ValidatingWebhookConfiguration资源删除。
HTTPS访问报SSL_ERROR_RX_RECORD_TOO_LONG错误
问题现象
访问HTTPS时报错SSL_ERROR_RX_RECORD_TOO_LONG或routines:CONNECT_CR_SRVR_HELLO:wrong version number。
问题原因
HTTPS请求访问到了非HTTPS端口,例如HTTP端口。
常见的原因如下:
SLB的443端口绑定了Ingress Pod的80端口。
Ingress Controller所对应服务的Service 443端口映射到了Ingress Pod的80端口。
解决方案
根据实际情况修改SLB设置或Service设置,使得HTTPS能够访问到正确的端口。
出现常见HTTP错误码
问题现象
请求出现非2xx、非3xx错误,例如502、503、413、499等错误。
问题原因及解决方案
查看日志,判断是否为Ingress Controller返回的错误。具体方法,请参见通过日志服务SLS的Controller Pod查看访问日志。若是,请参考以下解决方案:
413错误
问题原因:Nginx Ingress Controller正常工作,但该请求的数据大小超过了最大限制
解决方案:通过
kubectl edit cm -n kube-system nginx-configuration修改Controller配置,按需求调整nginx.ingress.kubernetes.io/client-max-body-size及nginx.ingress.kubernetes.io/proxy-body-size值(默认值20m)
499错误
问题原因:客户端由于某些原因提前断开了连接,不一定是组件或者后端业务问题。
解决方案:
有少量499错误时,取决于业务,可能为正常现象,可以忽略。
有大量499错误时,请检查后端业务处理时间和前端请求超时时间是否符合预期。
502错误
问题原因:Nginx Ingress正常工作,但其所属的Pod无法连接到目标后端Pod。
解决方案:
必现情况:
可能由于后端Service及Pod内配置错误导致。请检查后端Service的端口配置以及容器内业务代码。
偶发情况
可能由于Nginx Ingress Controller所属Pod负载过高导致。您可通过Controller所属负载均衡实例的请求数与连接数评估负载,并参见配置高负载场景的Nginx Ingress Controller为Controller提供更多资源。
可能由于后端Pod主动关闭会话导致。Nginx Ingress Controller默认开启长连接,请确认后端长连接的连接空闲超时时间大于Controller的连接空闲超时时间(默认900秒)。
以上方法都无法确定问题的情况下,请进行抓包分析。
503错误
问题原因:Ingress Controller没有找到后端Pod,或所有Pod均无法访问。
解决方案:
偶发情况
查看502错误解决方案。
检查后端业务就绪状态,配置合理健康检查。
必现情况
检查后端Service配置是否正确,是否存在Endpoint。
出现net::ERR_HTTP2_SERVER_REFUSED_STREAM错误
问题现象
访问网页时,部分资源无法正确加载,控制台中有net::ERR_HTTP2_SERVER_REFUSED_STREAM或net::ERR_FAILED报错。
问题原因
资源并行请求数较多,达到HTTP/2最大流数限制。
解决方案
(推荐)在ConfigMap中根据实际需要,调整
http2-max-concurrent-streams至更大值(默认128)。具体操作,请参见http2-max-concurrent-streams。在ConfigMap中直接关闭HTTP2支持,设置
use-http2为false。具体操作,请参见use-http2。
出现报错“The param of ServerGroupName is illegal”
问题原因
ServerGroupName的生成格式是namespace+svcName+port。服务器组名称的长度为2~128个字符,必须以大小写字母或中文开头,可包含数字、半角句号(.)、下划线(_)和短划线(-)。
解决方案
按照服务器组名称的格式要求修改。
创建Ingress时报错“certificate signed by unknown authority”
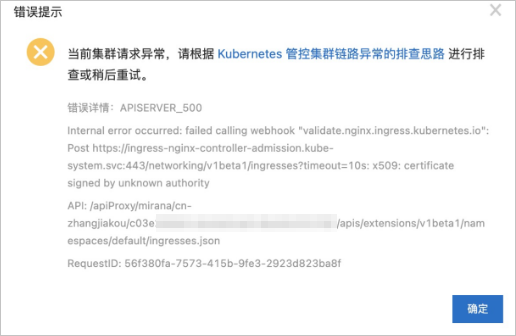
问题原因
创建Ingress时,出现上图报错,原因是部署了多套Ingress,而各Ingress之间使用了相同的资源 (可能包括Secret、服务、Webhook配置等),导致Webhook执行时与后端服务通信时使用的SSL证书不一致,从而出现错误。
解决方案
重新部署两套Ingress,两套Ingress包含的资源不能重复。关于Ingress中包含的资源信息,请参见在ACK组件管理中升级Nginx Ingress Controller组件时,系统会有哪些更新?。
Ingress Pod健康检查失败导致重启
问题现象
Controller Pod出现健康检查失败导致Pod重启。
问题原因
Ingress Pod或所在节点负载较高,导致健康检查失败。
集群节点上设置了
tcp_tw_reuse或tcp_timestamps内核参数,可能会导致健康检查失败。
解决方案
对Ingress Pod进行扩容,观察是否还有该现象。具体操作,请参见Nginx Ingress Controller的高可靠部署方式。
关闭
tcp_tw_reuse或设置为2,且同时关闭tcp_timestamps,观察是否还有该现象。
添加TCP、UDP服务
在对应ConfigMap中(默认为kube-system命名空间下的tcp-services和udp-services)添加对应条目。
例如default空间下example-go的8080端口映射到9000端口,示例如下。
apiVersion: v1 kind: ConfigMap metadata: name: tcp-services namespace: ingress-nginx data: 9000: "default/example-go:8080" # 8080端口映射到9000端口。在Ingress Deployment中(默认为kube-system命名空间下的nginx-ingress-controller)添加所映射的端口。
在Ingress对应的Service中添加所映射的端口。
关于添加TCP和UDP服务的更多信息,请参见暴露TCP和UDP服务。
Ingress规则没有生效
问题现象
添加或修改了Ingress规则,但是没有生效。
问题原因
Ingress配置出现错误,导致新的Ingress规则无法被正确加载。
Ingress资源配置错误,与预期配置不相符。
Ingress Controller的权限出现问题,导致无法正常监视Ingress资源变动。
旧的Ingress使用了
server-alias配置了域名,与新的Ingress冲突,导致规则被忽略。
解决方案
使用智能运维控制台的Ingress诊断工具进行诊断,并按照提示进行操作。具体操作,请参见使用Ingress诊断功能。
检查旧的Ingress是否有配置错误或配置冲突问题:
针对非
rewrite-target,且路径中使用了正则表达式的情况,确认Annotation中配置了nginx.ingress.kubernetes.io/use-regex: "true"。检查PathType是否与预期相符(
ImplementationSpecific默认与Prefix作用相同)。
确认与Ingress Controller相关联的ClusterRole、ClusterRoleBinding、Role、RoleBinding、ServiceAccount都存在。默认名称均为ingress-nginx。
进入Controller Pod容器,查看nginx.conf文件中已添加的规则。
执行以下命令,手动查看容器日志,确定问题。
kubectl logs <ingress pod name> -n <pod namespace> | grep -E ^[EW]
重写到根目录后部分资源无法加载或白屏
问题现象
通过Ingress rewrite-target annotation重写访问后,页面部分资源无法加载,或出现白屏。
问题原因
rewrite-target可能没有使用正则表达式进行配置。业务中请求资源路径写死在根目录。
解决方案
检查
rewrite-target是否与正则表达式以及捕获组一起使用。具体操作,请参见Rewrite。检查前端请求是否访问到了正确的路径。
当版本升级后SLS解析日志不正常怎样修复
问题现象
ingress-nginx-controller组件当前主要有0.20和0.30两个版本,当通过控制台的组件管理从0.20升级到0.30版本后,在使用Ingress的灰度或蓝绿发布功能时,Ingress Dashboard会出现无法正确展示实际后端服务访问情况。
问题原因
由于0.20和0.30默认输出格式不同,在使用Ingress的灰度或蓝绿发布功能时,Ingress Dashboard会出现无法正确展示实际后端服务访问情况。
解决方案
执行以下操作步骤进行修复,更新nginx-configuration configmap和k8s-nginx-ingress配置。
更新
nginx-configuration configmap。如果您没有修改过
nginx-configuration configmap,保存以下内容为nginx-configuration.yaml,然后执行kubectl apply -f nginx-configuration.yaml命令进行部署。apiVersion: v1 kind: ConfigMap data: allow-backend-server-header: "true" enable-underscores-in-headers: "true" generate-request-id: "true" ignore-invalid-headers: "true" log-format-upstream: $remote_addr - [$remote_addr] - $remote_user [$time_local] "$request" $status $body_bytes_sent "$http_referer" "$http_user_agent" $request_length $request_time [$proxy_upstream_name] $upstream_addr $upstream_response_length $upstream_response_time $upstream_status $req_id $host [$proxy_alternative_upstream_name] max-worker-connections: "65536" proxy-body-size: 20m proxy-connect-timeout: "10" reuse-port: "true" server-tokens: "false" ssl-redirect: "false" upstream-keepalive-timeout: "900" worker-cpu-affinity: auto metadata: labels: app: ingress-nginx name: nginx-configuration namespace: kube-system如果您修改过
nginx-configuration configmap,为了避免覆盖您的配置,执行以下命令进行修复:kubectl edit configmap nginx-configuration -n kube-system
在
log-format-upstream字段末尾,添加[$proxy_alternative_upstream_name], 然后保存退出。更新
k8s-nginx-ingress配置。将以下内容保存为
k8s-nginx-ingress.yaml文件,然后执行kubectl apply -f k8s-nginx-ingress.yaml命令进行部署。
出现报错“cannot list/get/update resource”
问题现象
通过检查Controller Pod中错误日志中所述方法发现Pod内存在Controller错误日志。类似如下:
User "system:serviceaccount:kube-system:ingress-nginx" cannot list/get/update resource "xxx" in API group "xxx" at the cluster scope/ in the namespace "kube-system"问题原因
Nginx Ingress Controller缺少对应权限,无法更新相关资源。
解决方案
根据日志确认问题是由于ClusterRole还是Role产生的。
日志中包含
at the cluster scope,问题则产生自ClusterRole(ingress-nginx)。日志中包含
in the namespace "kube-system",问题则产生自Role(kube-system/ingress-nginx)。
确认对应权限以及权限绑定是否完整。
对于ClusterRole:
确保ClusterRole
ingress-nginx以及ClusterRoleBindingingress-nginx存在。若不存在,可以考虑自行新建、恢复、卸载组件重装。确保ClusterRole
ingress-nginx中包含日志中所对应的权限(图例中为networking.k8s.io/ingresses的List权限)。若权限不存在,可以手动添加至ClusterRole中。
对于Role:
确认Role
kube-system/ingress-nginx以及RoleBindingkube-system/ingress-nginx存在。若不存在,可以考虑自行新建、恢复、卸载组件重装。确认Role
ingress-nginx中包含日志中所对应权限(图例中为ConfigMapingress-controller-leader-nginx的Update权限)。若权限不存在,可以手动添加至Role中。


出现报错“configuration file failed”
问题现象
通过检查Controller Pod中错误日志中所述方法发现Pod内存在Controller错误日志。类似如下:
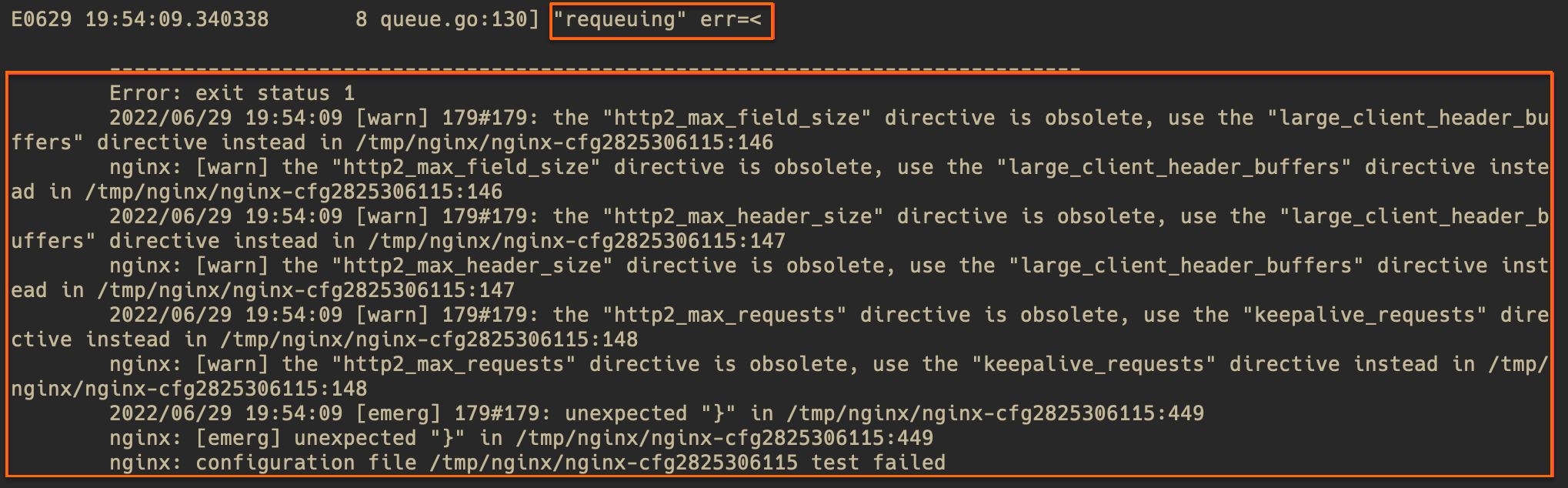
requeuing……nginx: configuration file xxx test failed(多行内容)问题原因
配置错误,导致Nginx配置reload失败,一般为Ingress规则或ConfigMap中插入的Snippet语法错误导致的。
解决方案
查看日志中错误提示(warn等级的提示可忽略),大致定位问题位置。若错误提示不够清晰,可以根据错误提示中的文件行数,进入Pod中查看对应文件。以下图为例,文件为/tmp/nginx/nginx-cfg2825306115的第449行。
执行如下命令,查看对应行附近的配置是否有错误。
# 进入Pod执行命令。 kubectl exec -n <namespace> <controller pod name> -it -- bash # 带行数信息查看出错的文件,在输出中查看对应行附近的配置有无错误。 cat -n /tmp/nginx/nginx-cfg2825306115根据错误提示和配置文件,根据自身实际配置,定位错误原因并修复。
出现报错“Unexpected error validating SSL certificate”
问题现象
通过检查Controller Pod中错误日志中所述方法发现Pod内存在Controller错误日志。类似如下:
Unexpected error validating SSL certificate "xxx" for server "xxx"
问题原因
证书配置错误,常见的原因有证书所包含域名与Ingress中配置域名不一致。部分Warning等级日志不会影响到证书的正常使用(如证书中未携带SAN扩展等),请根据实际情况判断是否出现问题。
解决方案
根据错误内容检查集群中证书问题。
证书的cert和key格式及内容是否正确。
证书所包含域名与Ingress中所配置域名是否一致。
证书有无过期。
关于Controller存在大量未被清理的配置文件问题
问题现象
在旧版本(低于1.10)的Nginx Ingress Controller中,有一个已知的BUG。正常情况下,生成的nginx-cfg文件应该被及时清理。然而,当Ingress配置存在错误并导致最终渲染的nginx.conf配置出错时,这些错误配置文件未能如期清理,导致nginx-cfgxxx文件逐渐累积,占用大量磁盘空间。
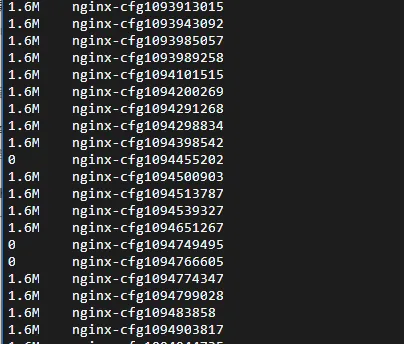
问题原因
问题的原因是清理逻辑存在缺陷。虽然正确生成的配置文件会被正确清理,但对于生成无效配置文件的情况,清理机制无法正常工作,导致这些文件始终保留在系统中。详细信息请参见社区的GitHub Issue #11568。
解决方案
为解决此问题,可以考虑以下方案。
升级Nginx Ingress Controller:建议将Nginx Ingress Controller 升级到1.10或更高版本。详情请参见升级Nginx Ingress Controller组件。
手动清理旧文件:定期手动删除未被清理的
nginx-cfgxxx文件。可以编写脚本来自动化此过程,以减少手动操作的负担。检查配置错误:在应用新的Ingress配置之前,务必仔细检查其正确性,以避免生成无效的配置文件。
Controller升级后Pod持续Pending的问题排查
问题现象
在升级Nginx Ingress Controller 时,可能会出现Pod无法成功调度的情况,即Pod长时间处于Pending状态。
问题原因
在升级Nginx Ingress Controller时,由于默认配置了节点亲和性和Pod反亲和性规则,可能会导致新版本的Pod无法调度。需要确保集群中有足够的可用资源。
您可以使用以下命令来查看具体的原因:
kubectl -n kube-system describe pod <pending-pod-name>kubectl -n kube-system get events解决方案
为解决此问题,可以考虑以下方案。
扩容集群资源:增加新的节点,以满足亲和性规则的要求。详情请参见手动扩缩容节点池。
调整亲和性:在资源紧张的情况下,可以通过执行
kubectl edit deploy nginx-ingress-controller -n kube-system命令来放宽反亲和性要求,从而允许Pod被调度到同一节点。这种方法可能会降低组件的高可用性。
Flannel CNI+IPVS集群高并发下Nginx Ingress多CLB导致TCP串流问题
问题现象
在采用Flannel CNI和IPVS网络模式的ACK集群中,如果Nginx Ingress Controller绑定了多个负载均衡(CLB),可能会在高并发情况下导致TCP串流问题。通过抓包可观察到以下异常。
报文重传
异常的TCP连接重置(reset)
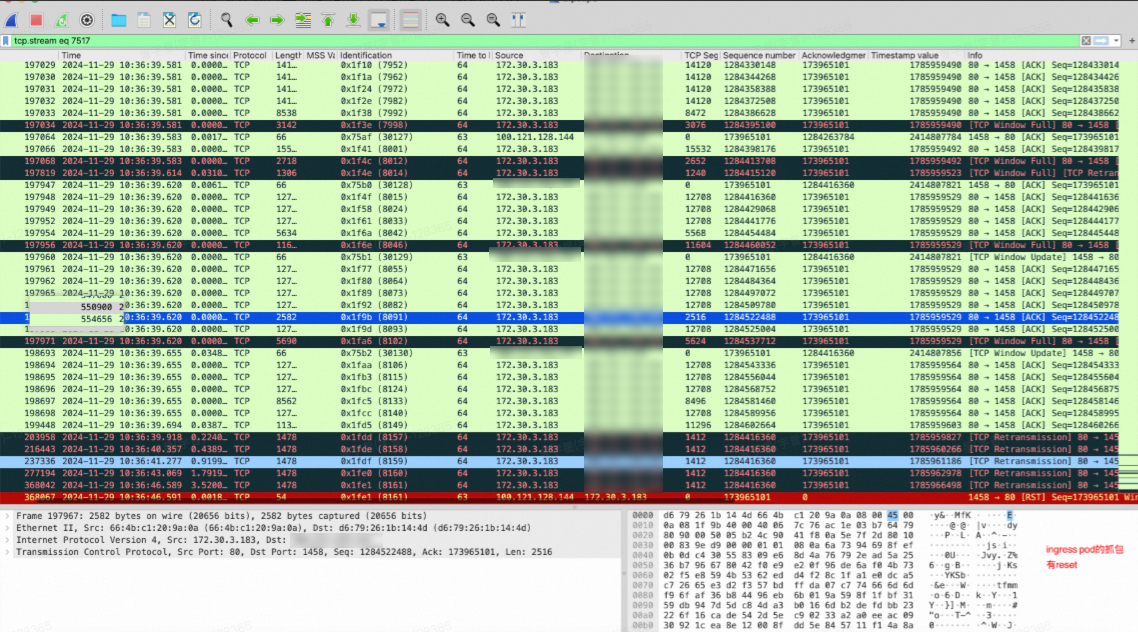
问题原因
在使用Flannel网络插件配置的ACK集群中,CLB会将流量转发到Nginx Ingress Controller所在节点的NodePort端口。然而,当多个Service使用不同的NodePort时,高并发情况下可能会导致IPVS会话出现冲突问题。
解决方案
单一负载均衡器策略:仅创建一个Nginx Ingress Controller的LoadBalancer Service。其他CLB通过手动配置的方式绑定到节点的NodePort,以减少冲突的可能性。
避免多个NodePort同时生效:在同一节点上,尽量避免让多个NodePort同时生效,以减少IPVS会话的冲突风险。