
如需采集Knative服务的容器文本日志,您可以通过DaemonSet的方式,在每个节点上自动运行一个日志代理,以提升运维效率。ACK集群已兼容日志服务SLS,支持无侵入式采集日志。您可以安装日志采集组件,该组件会在节点上部署一个采集实例,用于收集节点上所有容器的日志,便于后续的管理和分析。
前提条件
已在集群中部署Knative,请参见部署与管理Knative组件。
-
已创建一个Knative服务,请参见快速部署一个Knative服务。
-
已开通日志服务。
步骤一:安装日志采集组件
安装LoongCollector(推荐)
LoongCollector目前支持在公有云的所有地域安装,但金融云和政务云暂不支持。
LoongCollector(原Logtail):Logtail是日志服务提供的日志采集Agent,用于采集阿里云ECS、自建IDC或其他云厂商等服务器上的日志。Logtail基于日志文件采集,无需修改应用程序代码,且采集日志不会影响应用程序运行。LoongCollector是日志服务推出的新一代采集Agent,是Logtail的升级版,兼容Logtail的同时性能更佳。
已有的ACK集群中安装loongcollector组件
登录容器服务管理控制台,在左侧导航栏选择集群列表。
在集群列表页面,单击目标集群名称,然后在左侧导航栏,选择运维管理 > 组件管理。
在日志与监控页签中,找到 loongcollector,然后单击安装。
说明LoongCollector组件和logtail-ds组件不能同时存在。如果集群之前已经安装logtail-ds组件,升级方案请参见Logtail与LoongCollector兼容性说明。
安装完成后,日志服务会自动生成名为k8s-log-${your_k8s_cluster_id}的Project,并在该Project下生成如下资源,您可登录日志服务控制台查看。
资源类型 | 资源名称 | 作用 | 示例 |
机器组 | k8s-group- | loongcollector-ds的机器组,主要用于日志采集场景。 | k8s-group-my-cluster-123 |
k8s-group- | loongcollector-cluster的机器组,主要用于指标采集场景。 | k8s-group-my-cluster-123-cluster | |
k8s-group- | 单实例机器组,主要用于部分单实例采集配置。 | k8s-group-my-cluster-123-singleton | |
Logstore | config-operation-log | 用于采集和存储loongcollector-operator组件日志。 重要 请勿删除名为 | config-operation-log |
安装Logtail
Logtail采集:Logtail是日志服务提供的日志采集Agent,用于采集阿里云ECS、自建IDC或其他云厂商等服务器上的日志。Logtail基于日志文件,无侵入式采集日志。您无需修改应用程序代码,且采集日志不会影响您的应用程序运行。
已有的ACK集群中安装Logtail组件
登录容器服务管理控制台,在左侧导航栏选择集群列表。
在集群列表页面,单击目标集群名称,然后在左侧导航栏,单击组件管理。
在日志与监控页签中,找到logtail-ds,然后单击安装。如未找到logtail-ds组件,请安装LoongCollector组件。
LoongCollector组件为logtail-ds组件的升级版,两个组件不能同时存在,推荐使用LoongCollector组件。
新建ACK集群时安装Logtail组件
登录容器服务管理控制台,在左侧导航栏选择集群列表。
单击创建集群,在组件配置页面,选中使用日志服务。
本文只描述日志服务相关配置,关于更多配置项说明,请参见创建ACK托管集群。
当选中使用日志服务后,会出现创建项目(Project)的提示。
使用已有Project
可选择一个已有的Project来管理采集到的容器日志。

创建新Project
日志服务自动创建一个Project来管理采集到的容器日志。其中
ClusterID为新建的Kubernetes集群的唯一标识。
在组件配置页中,默认开启控制面组件日志,开启此配置会在Project中自动配置并采集集群控制面组件日志并遵循按量计费,因此请根据自身情况选择是否需要开启,相关信息请参考管理控制面组件日志。
安装完成后,自动生成名为k8s-log-<YOUR_CLUSTER_ID>的Project,并在该Project下生成如下资源,可登录日志服务控制台查看资源。
资源类型 | 资源名称 | 作用 | 示例 |
机器组 | k8s-group- | logtail-daemonset的机器组,主要用于日志采集场景。 | k8s-group-my-cluster-123 |
k8s-group- | logtail-statefulset的机器组,主要用于指标采集场景。 | k8s-group-my-cluster-123-statefulset | |
k8s-group- | 单实例机器组,主要用于部分单实例采集配置。 | k8s-group-my-cluster-123-singleton | |
Logstore | config-operation-log | 用于存储Logtail组件中的alibaba-log-controller日志。建议不要在此Logstore下创建采集配置。该Logstore可以删除,删除后不会再采集alibaba-log-controller的运行日志。该Logstore的收费标准和普通的Logstore收费标准是一致的,具体请参见按写入数据量计费模式计费项。 | 无 |
步骤二:配置采集配置
以下介绍四种采集配置方式。请选择一种方式来管理采集配置。
配置方式 | 配置说明 | 场景适用 |
(推荐)CRD-AliyunPipelineConfig | 通过K8s CRD管理日志采集配置。 | 适用于需要复杂采集和处理需求以及在ACK集群中确保日志与应用版本一致性的场景。 说明 需要ACK的logtail-ds组件版本高于1.8.10。升级详情请参见升级Logtail latest版本。 |
日志服务控制台 | 图形化界面直接管理,快速部署配置。 | 适合少量Logtail采集配置的创建和管理,部分高级功能和自定义需求无法通过实现。 |
环境变量 | 通过环境变量快速配置日志参数。 | 进行简单配置调整,不支持复杂处理逻辑,仅支持单行文本日志。可满足以下定制需求:
|
CRD-AliyunLogConfig | 旧版CRD管理方式。 | 支持已知场景的旧版管理方式。 需要逐渐迁移到新版本CRD-AliyunPipelineConfig以享受更好的扩展性和稳定性。两类CRD采集方式对比请参见CRD类型。 |
(推荐)CRD-AliyunPipelineConfig
创建Logtail采集配置
使用AliyunPipelineConfig,需要日志组件版本最低为0.5.1。
您只需要创建AliyunPipelineConfig CR即可创建iLogtail采集配置,创建完成后自动生效。对于通过CR创建的iLogtail采集配置,其修改只能通过更新相应的CR来实现。
执行如下命令创建一个YAML文件。
cube.yaml为文件名,请根据实际情况替换。vim cube.yaml在YAML文件输入如下脚本,并根据实际情况设置其中的参数。
重要请确保
configName字段值在安装Logtail组件的Project中唯一。每个iLogtail采集配置必须单独设置一个对应的CR,如果多个CR关联同一个Logtail配置,后配置的CR将不会生效。
AliyunPipelineConfig的参数,请参见【推荐】使用AliyunPipelineConfig管理采集配置。本文的iLogtail采集配置样例包含基础的文本日志采集功能,参数说明参见创建Logtail流水线配置。请确保config.flushers.Logstore参数配置的Logstore已存在,可以通过配置spec.logstore参数自动创建Logstore。
采集指定容器内的单行文本日志
创建名为
example-k8s-file的iLogtail采集配置,对于集群内名称包含app的所有容器,以单行文本模式采集/data/logs/app_1路径下的test.LOG文件,直接发送到名称为
k8s-file的Logstore,该Logstore属于名称为k8s-log-test的Project。apiVersion: telemetry.alibabacloud.com/v1alpha1 # 创建一个 ClusterAliyunPipelineConfig kind: ClusterAliyunPipelineConfig metadata: # 设置资源名,在当前Kubernetes集群内唯一。该名称也是创建出的iLogtail采集配置名 name: example-k8s-file spec: # 指定目标project project: name: k8s-log-test # 创建用于存储日志的 Logstore logstores: - name: k8s-file # 定义iLogtail采集配置 config: # 定义输入插件 inputs: # 使用input_file插件采集容器内文本日志 - Type: input_file # 容器内的文件路径 FilePaths: - /data/logs/app_1/**/test.LOG # 启用容器发现功能。 EnableContainerDiscovery: true # 添加容器信息过滤条件,多个选项之间为“且”的关系。 ContainerFilters: # 指定待采集容器所在 Pod 所属的命名空间,支持正则匹配。 K8sNamespaceRegex: default # 指定待采集容器的名称,支持正则匹配。 K8sContainerRegex: ^(.*app.*)$ # 定义输出插件 flushers: # 使用flusher_sls插件输出到指定Logstore。 - Type: flusher_sls # 需要确保该 Logstore 存在 Logstore: k8s-file # 需要确保 endpoint 正确 Endpoint: cn-hangzhou.log.aliyuncs.com Region: cn-hangzhou TelemetryType: logs采集所有容器内的多行文本日志并正则解析
创建名为
example-k8s-file的iLogtail采集配置,以多行文本模式采集集群内所有容器内的/data/logs/app_1路径下的test.LOG文件,对采集到的数据进行JSON解析,直接发送到名称为k8s-file的Logstore,该Logstore属于名称为k8s-log-test的Project。下面样例中的日志原文通过input_file插件读取后格式为
{"content": "2024-06-19 16:35:00 INFO test log\nline-1\nline-2\nend"},会被正则解析插件解析为{"time": "2024-06-19 16:35:00", "level": "INFO", "msg": "test log\nline-1\nline-2\nend"}apiVersion: telemetry.alibabacloud.com/v1alpha1 # 创建一个 ClusterAliyunPipelineConfig kind: ClusterAliyunPipelineConfig metadata: # 设置资源名,在当前Kubernetes集群内唯一。该名称也是创建出的iLogtail采集配置名 name: example-k8s-file spec: # 指定目标project project: name: k8s-log-test # 创建用于存储日志的 Logstore logstores: - name: k8s-file # 定义iLogtail采集配置 config: # 日志样例(可不填写) sample: | 2024-06-19 16:35:00 INFO test log line-1 line-2 end # 定义输入插件 inputs: # 使用input_file插件采集容器内多行文本日志 - Type: input_file # 容器内的文件路径 FilePaths: - /data/logs/app_1/**/test.LOG # 启用容器发现功能。 EnableContainerDiscovery: true # 开启多行能力 Multiline: # 选择自定义行首正则表达式模式 Mode: custom # 配置行首正则表达式 StartPattern: \d+-\d+-\d+.* # 定义处理插件 processors: # 使用正则解析插件解析日志 - Type: processor_parse_regex_native # 源字段名 SourceKey: content # 解析用的正则表达式,用捕获组"()"捕获待提取的字段 Regex: (\d+-\d+-\d+\s*\d+:\d+:\d+)\s*(\S+)\s*(.*) # 提取的字段列表 Keys: ["time", "level", "msg"] # 定义输出插件 flushers: # 使用flusher_sls插件输出到指定Logstore。 - Type: flusher_sls # 需要确保该 Logstore 存在 Logstore: k8s-file # 需要确保 endpoint 正确 Endpoint: cn-hangzhou.log.aliyuncs.com Region: cn-hangzhou TelemetryType: logs执行如下命令使iLogtail采集配置生效。iLogtail采集配置生效后,Logtail开始采集各个容器上的文本日志,并发送到日志服务中。
cube.yaml为文件名,请根据实际情况替换。kubectl apply -f cube.yaml重要采集到日志后,您需要先创建索引,才能在Logstore中查询和分析日志。具体操作,请参见创建索引。
CRD-AliyunLogConfig
您只需要创建AliyunLogConfig CR即可创建iLogtail采集配置,创建完成后自动生效。对于通过CR创建的iLogtail采集配置,其修改只能通过更新相应的CR来实现。
执行如下命令创建一个YAML文件。
cube.yaml为文件名,请根据实际情况替换。vim cube.yaml在YAML文件输入如下脚本,并根据实际情况设置其中的参数。
重要请确保
configName字段值在安装Logtail组件的Project中唯一。如果多个CR关联同一个iLogtail采集配置,则删除或修改任意一个CR均会影响到该iLogtail采集配置,导致其他关联该iLogtail采集配置的CR状态与日志服务中iLogtail采集配置的状态不一致。
CR字段的格式请参见使用AliyunLogConfig管理采集配置。本文的iLogtail采集配置样例包含基础的文本日志采集功能,具体参数参见创建Logtail采集配置。
采集指定容器内的单行文本日志
“创建名为
example-k8s-file的iLogtail采集配置,以单行文本模式采集集群内所有名称开头为app的Pod的容器内的/data/logs/app_1路径下的test.LOG文件,直接发送到名称为k8s-file的Logstore,该Logstore属于名称为k8s-log-test的Project。”apiVersion: log.alibabacloud.com/v1alpha1 kind: AliyunLogConfig metadata: # 设置资源名,在当前Kubernetes集群内唯一。 name: example-k8s-file namespace: kube-system spec: # 设置目标project名称(可不填写,默认为k8s-log-<YOUR_CLUSTER_ID>) project: k8s-log-test # 设置Logstore名称。如果您所指定的Logstore不存在,日志服务会自动创建。 logstore: k8s-file # 设置iLogtail采集配置。 logtailConfig: # 设置采集的数据源类型。采集文本日志时,需设置为file。 inputType: file # 设置iLogtail采集配置的名称。 configName: example-k8s-file inputDetail: # 指定通过极简模式采集文本日志。 logType: common_reg_log # 设置日志文件所在路径。 logPath: /data/logs/app_1 # 设置日志文件的名称。支持通配符星号(*)和半角问号(?),例如log_*.log。 filePattern: test.LOG # 采集容器的文本日志时,需设置dockerFile为true。 dockerFile: true #设置容器过滤条件。 advanced: k8s: K8sPodRegex: '^(app.*)$'执行如下命令使其iLogtail采集配置生效。iLogtail采集配置生效后,Logtail开始采集各个容器上的文本日志,并发送到日志服务中。
cube.yaml为文件名,请根据实际情况替换。kubectl apply -f cube.yaml重要采集到日志后,您需要先创建索引,才能在Logstore中查询和分析日志。具体操作,请参见创建索引。
日志服务控制台
登录日志服务控制台。
单击控制台右侧的快速接入数据,在接入数据区域单击Kubernetes-文件卡片。

选择目标Project和Logstore,单击下一步。选择您在安装Logtail组件时所使用的Project。Logstore为您自定义创建的Logstore。
在机器组配置页面完成如下操作。机器组相关信息,详细请参见机器组。
根据实际场景,单击以下页签:
- 重要
不同页签的后续配置步骤不同,请根据实际需求正确选择。
确认目标机器组已在应用机器组列表中,然后单击下一步。在ACK中安装Logtail组件后,日志服务自动创建名为
k8s-group-${your_k8s_cluster_id}的机器组,您可以直接使用该机器组。重要如果需要新建机器组,请单击创建机器组,按照右侧面板进行创建。更多信息,请参见采集ACK集群容器日志。
如果机器组心跳为FAIL,您可单击自动重试。如果还未解决,请参见Logtail机器组无心跳进行排查。
创建Logtail采集配置,单击下一步创建Logtail采集配置,日志服务开始采集日志。
说明Logtail采集配置生效时间最长需要3分钟,请耐心等待。
配置项
说明
日志样例
待采集日志的样例,请务必使用实际场景的日志。日志样例可协助您配置日志处理相关参数,降低配置难度。支持添加多条样例,总长度不超过1500个字符。
[2023-10-01T10:30:01,000] [INFO] java.lang.Exception: exception happened at TestPrintStackTrace.f(TestPrintStackTrace.java:3) at TestPrintStackTrace.g(TestPrintStackTrace.java:7) at TestPrintStackTrace.main(TestPrintStackTrace.java:16)多行模式
多行日志的类型:多行日志是指每条日志分布在连续的多行中,需要从日志内容中区分出每一条日志。
自定义:通过行首正则表达式区分每一条日志。
多行JSON:每个JSON对象被展开为多行,例如:
{ "name": "John Doe", "age": 30, "address": { "city": "New York", "country": "USA" } }
切分失败处理方式:
Exception in thread "main" java.lang.NullPointerException at com.example.MyClass.methodA(MyClass.java:12) at com.example.MyClass.methodB(MyClass.java:34) at com.example.MyClass.main(MyClass.java:10)对于以上日志内容,如果日志服务切分失败:
丢弃:直接丢弃这段日志。
保留单行:将每行日志文本单独保留为一条日志,保留为一共四条日志。
处理模式
处理插件组合,包括原生插件和拓展插件。有关处理插件的更多信息,请参见处理插件概述。
重要处理插件的使用限制,请以控制台页面的提示为准。
2.0版本的Logtail:
原生处理插件可任意组合。
原生处理插件和扩展处理插件可同时使用,但扩展处理插件只能出现在所有的原生处理插件之后。
低于2.0版本的Logtail:
不支持同时添加原生插件和扩展插件。
原生插件仅可用于采集文本日志。使用原生插件时,须符合如下要求:
第一个处理插件必须为正则解析插件、分隔符模式解析插件、JSON解析插件、Nginx模式解析插件、Apache模式解析插件或IIS模式解析插件。
从第二个处理插件到最后一个处理插件,最多包括1个时间解析处理插件,1个过滤处理插件和多个脱敏处理插件。
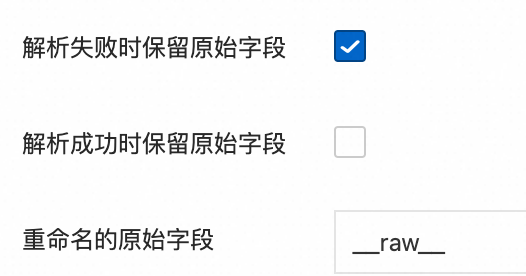
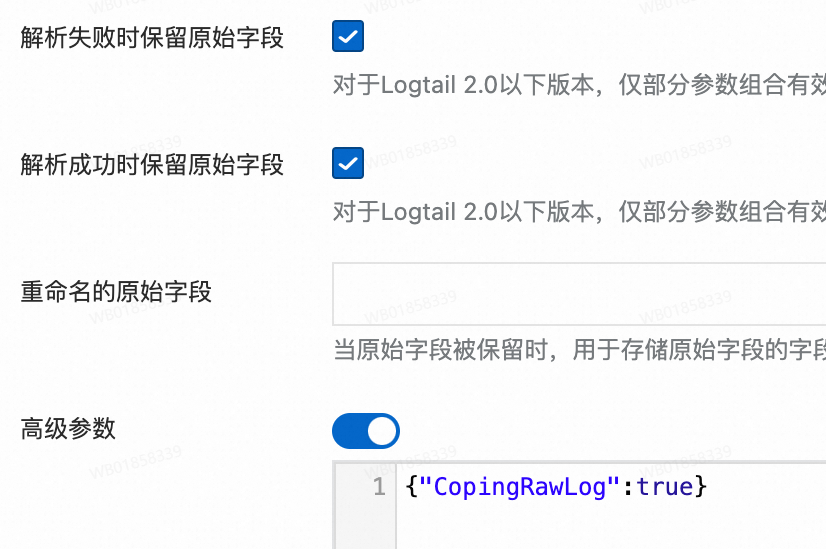
对于解析失败时保留原始字段和解析成功时保留原始字段参数,只有以下组合有效,其余组合无效。
只上传解析成功的日志:

解析成功时上传解析后的日志,解析失败时上传原始日志:

解析成功时不仅上传解析后的日志,并且追加原始日志字段,解析失败时上传原始日志。
例如,原始日志
"content": "{"request_method":"GET", "request_time":"200"}"解析成功,追加原始字段是在解析后日志的基础上再增加一个字段,字段名为重命名的原始字段(如果不填则默认为原始字段名),字段值为原始日志{"request_method":"GET", "request_time":"200"}。
创建索引和预览数据,然后单击下一步。日志服务默认开启全文索引。您也可以根据采集到的日志,手动创建字段索引,或者单击自动生成索引,日志服务将自动生成字段索引。更多信息,请参见创建索引。
重要如果需要查询日志中的所有字段,建议使用全文索引。如果只需查询部分字段、建议使用字段索引,减少索引流量。如果需要对字段进行分析(SELECT语句),必须创建字段索引。
单击查询日志,系统将跳转至Logstore查询分析页面。
您需要等待1分钟左右,待索引生效后,才能在原始日志页签中,查看已采集到的日志。更多信息,请参见查询与分析快速指引。
环境变量
您可以在创建Knative服务时参见下方YAML模板配置日志采集。
登录容器服务管理控制台,在左侧导航栏选择集群列表。
在集群列表页面,单击目标集群名称,然后在左侧导航栏,选择。
-
单击服务管理页签,选择命名空间后单击使用模板创建,选择示例模板为自定义,按照页面指引参见以下YAML文件完成创建。
YAML模板的语法同Kubernetes语法,但是为了给容器指定采集配置,需要使用
env来为容器增加采集配置和自定义Tag,并根据采集配置,创建对应的volumeMounts和volumes。以下是一个简单的Pod示例。根据您的需求,按照以下顺序进行配置。
-
通过环境变量来创建您的采集配置和自定义Tag,所有与配置相关的环境变量都采用
aliyun_logs_作为前缀。-
创建采集配置的规则如下:
- name: aliyun_logs_log-stdout value: stdout - name: aliyun_logs_log-varlog value: /var/demo/*.log示例中创建了两个采集配置,格式为
aliyun_logs_{key},对应的{key}分别为log-stdout和log-varlog。-
aliyun_logs_log-stdout:该env表示创建一个名为log-stdout的Logstore,日志采集路径为stdout的配置,对应的日志服务采集配置名称也是log-stdout,目的是将容器的标准输出采集到log-stdout这个Logstore中。 -
aliyun_logs_log-varlog:该env表示创建一个Logstore名为log-varlog,日志采集路径为/var/demo/*.log的配置,对应的日志服务采集配置名称也是log-varlog,目的是将容器的/var/demo/*.log文件内容采集到log-varlog这个Logstore中。
-
-
创建自定义Tag的规则如下:
- name: aliyun_logs_mytag1_tags value: tag1=v1配置Tag后,当采集到该容器的日志时,会自动附加对应的字段到日志服务。其中
mytag1为任意不包含'_'的名称。
-
-
如果您的采集配置中指定了非stdout的采集路径,需要在此部分创建相应的
volumeMounts。示例中采集配置添加了对/var/demo/*.log的采集,因此相应地添加了/var/demo的
volumeMounts。
-
-
(可选)配置环境变量的高级参数。
通过容器环境变量配置采集支持多种配置参数。可根据实际需求设置高级参数,以满足日志采集的特殊需求。
重要通过容器环境变量配置采集日志的方式不适用于边缘场景。
字段
说明
示例
注意事项
aliyun_logs_{key}
必选项。{key}只能包含小写字母、数字和-。
若不存在aliyun_logs_{key}_logstore,则默认创建并采集到名为{key}的logstore。
当值为stdout时表示采集容器的标准输出;其他值为容器内的日志路径。
- name: aliyun_logs_catalina value: stdout- name: aliyun_logs_access-log value: /var/log/nginx/access.log
默认采集方式为极简模式。如需解析日志内容,建议使用日志服务控制台,或者CRD进行配置。
{key}表示日志服务中Logtail采集配置的名称,需保持在K8s集群内唯一。
aliyun_logs_{key}_tags
可选。值为{tag-key}={tag-value}类型,用于对日志进行标识。
- name: aliyun_logs_catalina_tags value: app=catalina不涉及。
aliyun_logs_{key}_project
可选。值为指定的日志服务Project。当不存在该环境变量时,为安装时所选的Project。
- name: aliyun_logs_catalina_project value: my-k8s-projectProject需与Logtail工作所在的Region一致。
aliyun_logs_{key}_logstore
可选。值为指定的日志服务Logstore。当不存在该环境变量时,Logstore和{key}一致。
- name: aliyun_logs_catalina_logstore value: my-logstore不涉及。
aliyun_logs_{key}_shard
可选。值为创建Logstore时的shard数,取值范围为[1 , 10]。当不存在该环境变量时,值为2。
说明若logstore已经存在,则该参数不生效。
- name: aliyun_logs_catalina_shard value: '4'不涉及。
aliyun_logs_{key}_ttl
可选。值为指定的日志保存时间,取值范围为[1 , 3650]。
当取值为3650时,指定日志的保存时间为永久保存。
当不存在该环境变量时,默认指定日志的保存时间为90天。
说明若Logstore已经存在,则该参数不生效。
- name: aliyun_logs_catalina_ttl value: '3650'不涉及。
aliyun_logs_{key}_machinegroup
可选。值为应用的机器组。当不存在该环境变量时与安装Logtail的默认机器组一致。关于该参数的详细使用方法,请参见下文的采集ACK集群容器日志。
- name: aliyun_logs_catalina_machinegroup value: my-machine-group不涉及。
aliyun_logs_{key}_logstoremode
可选。值为指定的日志服务Logstore的类型,不指定该参数的话,默认值为standard,取值:
说明若Logstore已经存在,则该参数不生效。
standard:支持日志服务一站式数据分析功能,适用于实时监控、交互式分析以及构建完整的可观测性系统等场景。
query:支持高性能查询,索引流量费用约为standard的一半,但不支持SQL分析,适用于数据量大、存储周期长(周、月级别以上)、无日志分析的场景。
- name: aliyun_logs_catalina_logstoremode value: standard- name: aliyun_logs_catalina_logstoremode value: query
该参数需要logtail-ds镜像版本>=1.3.1。
步骤三:查询分析日志
登录日志服务控制台。
在Project列表中,单击目标Project,进入对应的Project详情页面。
在对应的日志库右侧的
图标,选择查询分析,查看Kubernetes集群输出的日志。

 图标,选择查询分析,查看Kubernetes集群输出的日志。
图标,选择查询分析,查看Kubernetes集群输出的日志。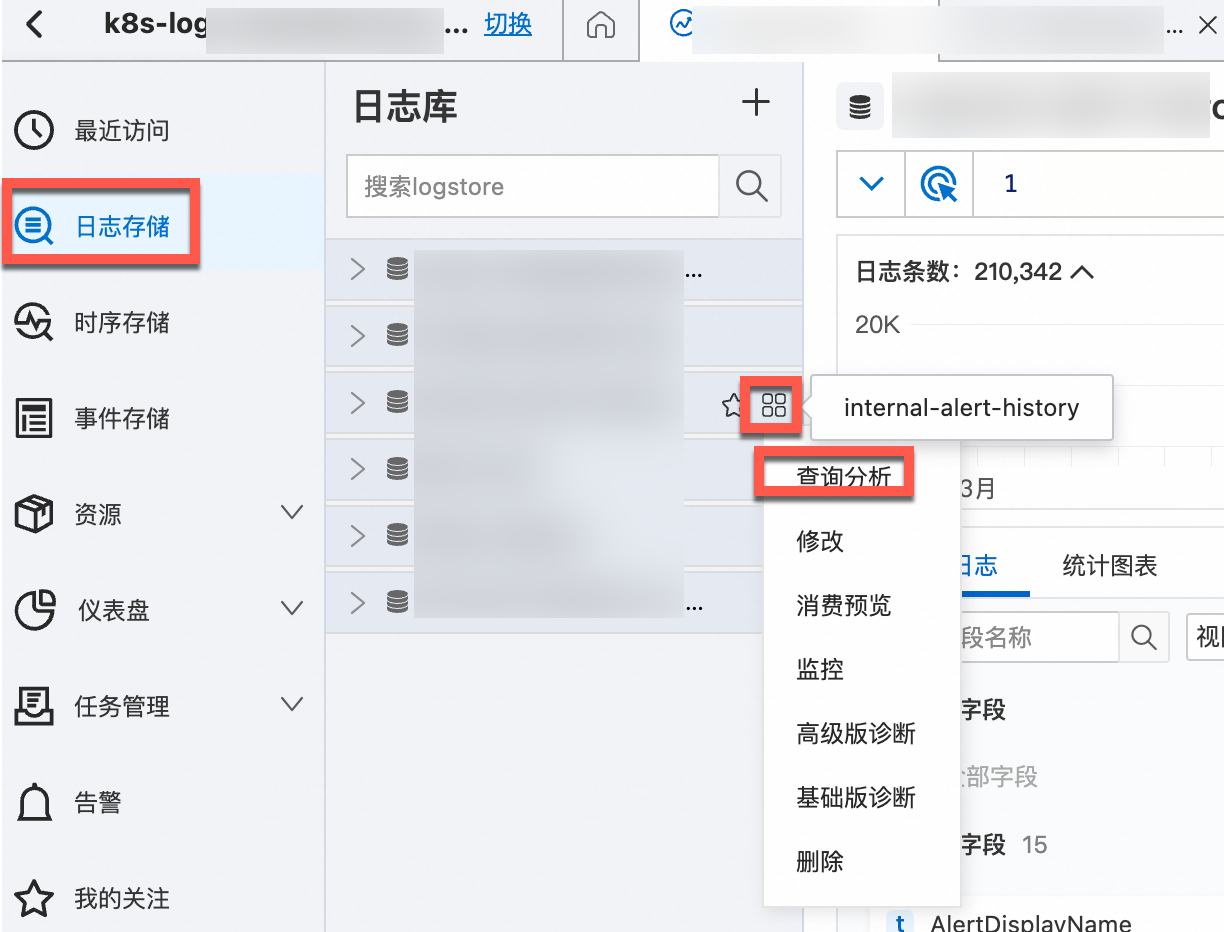
容器日志文本默认字段
K8s每条容器文本日志默认包含的字段如下表所示。
字段名称 | 说明 |
__tag__:__hostname__ | 容器宿主机的名称。 |
__tag__:__path__ | 容器内日志文件的路径。 |
__tag__:_container_ip_ | 容器的IP地址。 |
__tag__:_image_name_ | 容器使用的镜像名称。 说明 若存在多个相同Hash但名称或Tag不同的镜像,采集配置将根据Hash选择其中一个名称进行采集,无法确保所选名称与YAML文件中定义的一致。 |
__tag__:_pod_name_ | Pod的名称。 |
__tag__:_namespace_ | Pod所属的命名空间。 |
__tag__:_pod_uid_ | Pod的唯一标识符(UID)。 |
相关文档
-
关于容器采集异常排查思路,请参见如何查看Logtail采集错误信息、如何排查容器日志采集异常。
-
关于如何通过DaemonSet方式部署Logtail采集ACK集群文本的日志,请参见采集ACK集群容器日志。
-
您可以查看Knative应用的监控大盘,请参见查看Knative服务监控大盘。
-
您可以基于SLS实现监控告警,请参见为Knative服务开启监控告警。