
Kubernetes原生ResourceQuota的静态资源分配机制可能导致集群资源利用率较低。为此,ACK基于Scheduling Framework扩展机制,通过弹性配额组提供了Capacity Scheduling功能,在保障用户资源配额的同时支持资源共享,有效提升集群资源利用率。
前提条件
已创建1.20及以上版本的ACK托管集群Pro版。如需升级集群,请参见创建ACK托管集群。
Capacity Scheduling核心功能
在多用户集群环境中,为保障不同用户的可用资源充足,管理员会将集群资源进行固定分配。传统模式通过Kubernetes原生的ResourceQuota进行资源的静态分配。但由于用户资源使用存在时间和模式差异,可能导致部分用户资源紧张,而部分用户配额闲置,继而造成整体资源利用率降低。
为此,ACK基于Scheduling Framework的扩展机制,在调度侧实现了Capacity Scheduling的功能,在确保用户的资源分配的基础上通过资源共享的方式来提升整体资源的利用率。Capacity Scheduling具体功能如下。
支持定义不同层级的资源配额:根据业务情况(例如公司的组织结构)配置多个层级的弹性配额。弹性配额组的叶子节点可以对应多个Namespace,但同一个Namespace只能归属于一个叶子节点。
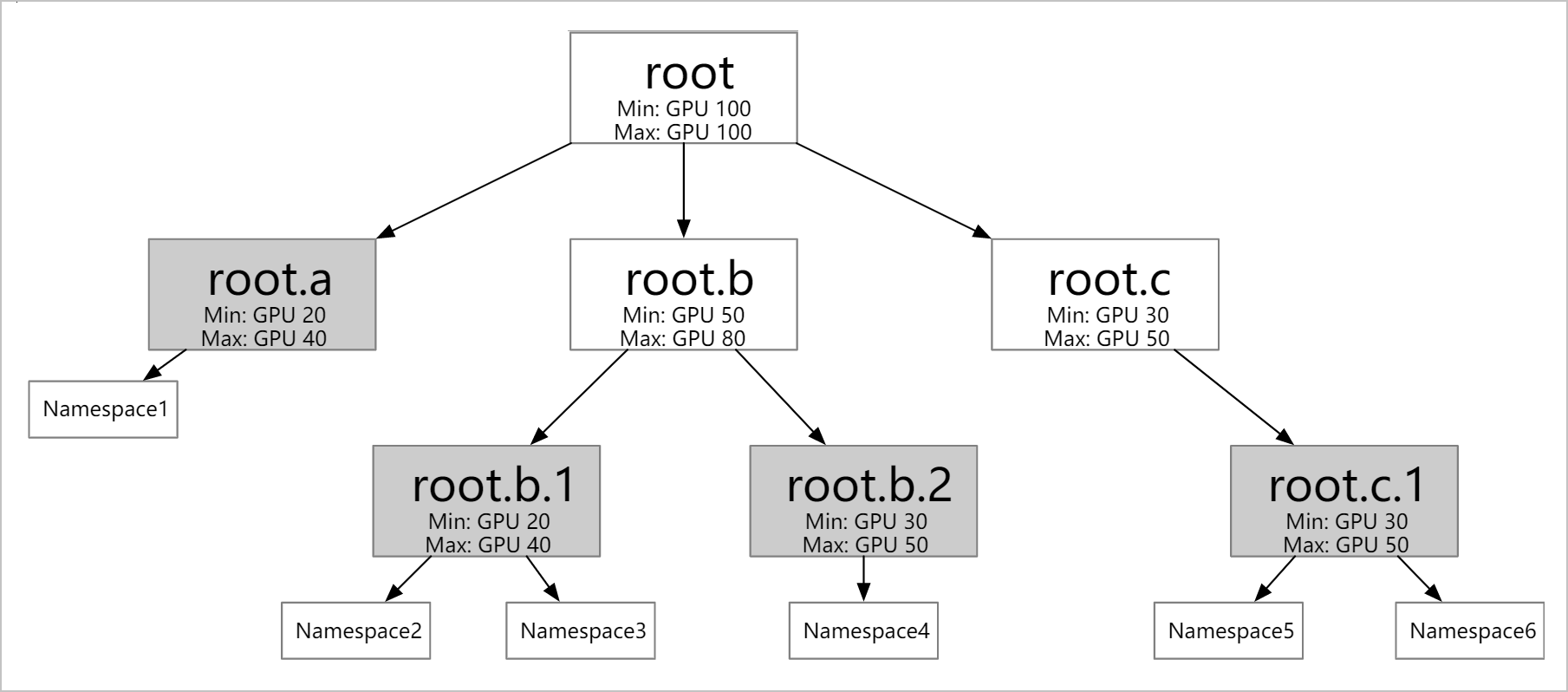
支持不同弹性配额之间的资源借用和回收。
Min:定义可使用的保障资源(Guaranteed Resource)。当整个集群资源紧张时,所有用户使用的Min总和需要小于集群的总资源量。
Max:定义可使用的资源上限。
工作负载可借用其他用户的闲置资源额度,但借用后可使用的资源总量依然不超过Max;未使用的Min资源配额支持借用,但当原用户需要使用时可抢占回收。
支持多种资源的配置:除CPU和内存资源外,也支持配置GPU等任何Kubernetes支持的扩展资源(Extended Resource)。
支持配额绑定节点:使用ResourceFlavor选择节点,并将ResourceFlavor与ElasticQuotaTree中的某个配额关联,关联后该弹性配额中的Pod只能被调度到ResourceFlavor选中的节点中。
Capacity scheduling配置示例
本示例集群中,节点为1台ecs.sn2.13xlarge机器(56 vCPU 224 GiB)。
创建如下Namespace。
kubectl create ns namespace1 kubectl create ns namespace2 kubectl create ns namespace3 kubectl create ns namespace4参见以下YAML,创建相应的弹性配额组。
根据以上YAML配置,在
namespaces字段配置对应的命名空间,在children字段配置对应子级的弹性配额。配置时,需要满足以下要求。同一个弹性配额中的Min≤Max。
子级弹性配额的Min之和≤父级的Min。
Root节点的Min=Max≤集群总资源。
Namespace只与弹性配额的叶子节点有一对多的对应关系,且同一个Namespace只能归属于一个叶子节点。
查看弹性配额组是否创建成功。
kubectl get ElasticQuotaTree -n kube-system预期输出:
NAME AGE elasticquotatree 68s
闲置资源的借用
参见以下YAML,在
namespace1中部署服务,Pod的副本数为5个,每个Pod请求CPU资源量为5核。查看集群Pod的部署情况。
kubectl get pods -n namespace1预期输出:
NAME READY STATUS RESTARTS AGE nginx1-744b889544-52dbg 1/1 Running 0 70s nginx1-744b889544-6l4s9 1/1 Running 0 70s nginx1-744b889544-cgzlr 1/1 Running 0 70s nginx1-744b889544-w2gr7 1/1 Running 0 70s nginx1-744b889544-zr5xz 0/1 Pending 0 70s由于当前集群存在闲置资源(
root.max.cpu=40),当在namespace1下的Pod申请CPU资源量超过root.a.1设置的min.cpu=10时,还可以继续借用其他闲置资源。最多可以申请使用root.a.1设置的配额max.cpu=20。当Pod申请CPU资源量超过
max.cpu=20时,再申请的Pod会处于Pending状态。因此,申请的5个Pod中,4个处于Running状态,1个处于Pending状态。
参见以下YAML,在
namespace2中部署服务,其中Pod的副本数为5个,每个Pod请求CPU资源量为5核。查看集群Pod的部署情况。
kubectl get pods -n namespace1预期输出:
NAME READY STATUS RESTARTS AGE nginx1-744b889544-52dbg 1/1 Running 0 111s nginx1-744b889544-6l4s9 1/1 Running 0 111s nginx1-744b889544-cgzlr 1/1 Running 0 111s nginx1-744b889544-w2gr7 1/1 Running 0 111s nginx1-744b889544-zr5xz 0/1 Pending 0 111skubectl get pods -n namespace2预期输出:
NAME READY STATUS RESTARTS AGE nginx2-556f95449f-4gl8s 1/1 Running 0 111s nginx2-556f95449f-crwk4 1/1 Running 0 111s nginx2-556f95449f-gg6q2 0/1 Pending 0 111s nginx2-556f95449f-pnz5k 1/1 Running 0 111s nginx2-556f95449f-vjpmq 1/1 Running 0 111s同
nginx1一致。由于当前集群存在闲置资源(root.max.cpu=40),当在namespace2下Pod申请CPU资源量超过root.a.2设置的min.cpu=10时,还可以继续借用其他闲置资源。最多可以申请使用root.a.2设置的配额max.cpu=20。当Pod申请CPU资源量超过
max.cpu=20时,再申请的Pod处于Pending状态。因此,申请的5个Pod中,4个处于Running状态,1个处于Pending状态。此时,集群中
namespace1和namespace2中的Pod所占用的资源已经为root设置的root.max.cpu=40。
借用资源的归还
参见以下YAML,在
namespace3中部署服务,其中Pod的副本数为5个,每个Pod请求CPU资源量为5核。执行以下命令,查看集群Pod的部署情况。
kubectl get pods -n namespace1预期输出:
NAME READY STATUS RESTARTS AGE nginx1-744b889544-52dbg 1/1 Running 0 6m17s nginx1-744b889544-cgzlr 1/1 Running 0 6m17s nginx1-744b889544-nknns 0/1 Pending 0 3m45s nginx1-744b889544-w2gr7 1/1 Running 0 6m17s nginx1-744b889544-zr5xz 0/1 Pending 0 6m17skubectl get pods -n namespace2预期输出:
NAME READY STATUS RESTARTS AGE nginx2-556f95449f-crwk4 1/1 Running 0 4m22s nginx2-556f95449f-ft42z 1/1 Running 0 4m22s nginx2-556f95449f-gg6q2 0/1 Pending 0 4m22s nginx2-556f95449f-hfr2g 1/1 Running 0 3m29s nginx2-556f95449f-pvgrl 0/1 Pending 0 3m29skubectl get pods -n namespace3预期输出:
NAME READY STATUS RESTARTS AGE nginx3-578877666-msd7f 1/1 Running 0 4m nginx3-578877666-nfdwv 0/1 Pending 0 4m10s nginx3-578877666-psszr 0/1 Pending 0 4m11s nginx3-578877666-xfsss 1/1 Running 0 4m22s nginx3-578877666-xpl2p 0/1 Pending 0 4m10snginx3的弹性配额root.b.1的min设置为10,为了保障其设置的min资源,调度器会将root.a下之前借用root.b的Pod资源归还,使得nginx3能够至少得到配额min.cpu=10的资源量,保证其运行。调度器会综合考虑
root.a下作业的优先级、可用性以及创建时间等因素,选择相应的Pod归还之前抢占的资源(10核)。因此,nginx3得到配额min.cpu=10的资源量后,有2个Pod处于Running状态,其他3个仍处于Pending状态。参见以下YAML,在
namespace4中部署服务nginx4,其中Pod的副本数为5个,每个Pod请求CPU资源量为5核。执行以下命令,查看集群Pod的部署情况。
kubectl get pods -n namespace1预期输出:
NAME READY STATUS RESTARTS AGE nginx1-744b889544-cgzlr 1/1 Running 0 8m20s nginx1-744b889544-cwx8l 0/1 Pending 0 55s nginx1-744b889544-gjkx2 0/1 Pending 0 55s nginx1-744b889544-nknns 0/1 Pending 0 5m48s nginx1-744b889544-zr5xz 1/1 Running 0 8m20skubectl get pods -n namespace2预期输出:
NAME READY STATUS RESTARTS AGE nginx2-556f95449f-cglpv 0/1 Pending 0 3m45s nginx2-556f95449f-crwk4 1/1 Running 0 9m31s nginx2-556f95449f-gg6q2 1/1 Running 0 9m31s nginx2-556f95449f-pvgrl 0/1 Pending 0 8m38s nginx2-556f95449f-zv8wn 0/1 Pending 0 3m45skubectl get pods -n namespace3预期输出:
NAME READY STATUS RESTARTS AGE nginx3-578877666-msd7f 1/1 Running 0 8m46s nginx3-578877666-nfdwv 0/1 Pending 0 8m56s nginx3-578877666-psszr 0/1 Pending 0 8m57s nginx3-578877666-xfsss 1/1 Running 0 9m8s nginx3-578877666-xpl2p 0/1 Pending 0 8m56skubectl get pods -n namespace4预期输出:
nginx4-754b767f45-g9954 1/1 Running 0 4m32s nginx4-754b767f45-j4v7v 0/1 Pending 0 4m32s nginx4-754b767f45-jk2t7 0/1 Pending 0 4m32s nginx4-754b767f45-nhzpf 0/1 Pending 0 4m32s nginx4-754b767f45-tv5jj 1/1 Running 0 4m32s同理,
nginx4的弹性配额root.b.2的min设置为10,为了保障其设置的min资源,调度器会将root.a下之前借用root.b的Pod资源归还,使得nginx4能够至少得到配额min.cpu=10的资源量,保证其运行。调度器会综合考虑
root.a下作业的优先级、可用性以及创建时间等因素,选择相应的Pod归还之前抢占的资源(10核)。因此,nginx4得到配额min.cpu=10资源量后,有2个Pod处于Running状态,其他3个仍处于Pending状态。此时,集群所有的弹性配额都使用其
min设置的保障资源(Guaranteed Resource)。
ResourceFlavor配置示例
前提条件
已参见ResourceFlavorCRD安装ResourceFlavor(ACK Scheduler默认未安装)。
ResourceFlavor资源中仅nodeLabels字段有效。
调度器版本高于6.9.0。组件变更记录,请参见kube-scheduler;组件升级入口,请参见组件。
ResourceFlavor作为一种Kubernetes自定义资源(CRD),通过定义节点标签(NodeLabels)建立弹性配额与节点的绑定关系。当将其与特定弹性配额关联后,该配额下的Pod既受配额资源总量的限制,又仅能调度至匹配NodeLabels的目标节点。
ResourceFlavor示例
一个ResourceFlavor的简单示例如下。
apiVersion: kueue.x-k8s.io/v1beta1
kind: ResourceFlavor
metadata:
name: "spot"
spec:
nodeLabels:
instance-type: spot关联弹性配额示例
为了将弹性配额与ResourceFlavor进行关联,需在ElasticQuotaTree中通过attributes字段进行声明,例如如下所示。
apiVersion: scheduling.sigs.k8s.io/v1beta1
kind: ElasticQuotaTree
metadata:
name: elasticquotatree
namespace: kube-system
spec:
root:
children:
- attributes:
resourceflavors: spot
max:
cpu: 99
memory: 40Gi
nvidia.com/gpu: 10
min:
cpu: 99
memory: 40Gi
nvidia.com/gpu: 10
name: child
namespaces:
- default
max:
cpu: 999900
memory: 400000Gi
nvidia.com/gpu: 100000
min:
cpu: 999900
memory: 400000Gi
nvidia.com/gpu: 100000
name: root提交后,属于Quota child的Pod将只能调度到带有instance-type: spot标签的节点上。
相关文档
kube-scheduler发布记录,请参见kube-scheduler。
Kube-scheduler支持Gang scheduling的能力,强制关联Pod组必须同时调度成功(否则都不会被调度),适用于Spark、Hadoop等大数据处理任务场景,详情请参见使用Gang scheduling。