您可以在ACK集群使用阿里云第八代企业级实例ECS g8i作为Worker节点,并结合IPEX技术来加速文生图模型的推理速度。您也可以在集群中创建TDX机密虚拟机节点池,并将示例服务迁移至其中,提升推理服务数据的安全性。本文以Stable Diffusion XL Turbo模型为例,介绍如何在合理运用CPU加速策略和模型推理的前提下,基于g8i CPU实例获得类似于GPU实例的使用体验,实现稳定、高效、高性价比且安全机密的文生图服务。
背景信息
阿里云第八代企业级实例g8i
阿里云第八代企业级通用计算实例ECS g8i采用CIPU+飞天技术架构,搭载最新的Intel第五代至强可扩展处理器(代号EMR),性能进一步提升。同时,ECS g8i实例拥有AMX加持的AI能力增强,拥有AI增强和全面安全防护的两大特色优势。此外,ECS g8i实例全量支持Intel® TDX技术能力。您无需更改业务应用代码,即可将工作负载部署到可信执行环境(TEE,Trusted Execution Environment)中,不仅能有效降低技术门槛,还支持以极低的性能损耗为大模型等AI应用提供隐私增强算力。请参见通用型实例规格族g8i。
Intel® TDX
Intel® TDX是一项基于CPU硬件的云服务器ECS保护技术,TDX实例的CPU寄存器、内存数据、中断处理等均受到CPU硬件的机密保护,云厂商和外部攻击者均无法监控或篡改TDX实例的内部运行状态(如运行的进程、计算中的敏感数据等)。关于Intel® TDX技术的更多信息,请参见Intel® Trusted Domain Extension(Intel® TDX)。
Intel® TDX可以为您的实例和应用提供默认的安全保护,即您可以将现有应用直接迁移至TDX实例上并获得TDX能力带来的安全保护,而无需重新开发现有的应用程序。
IPEX
Intel® Extension for PyTorch(IPEX)是由Intel开源并维护的一个PyTorch扩展库,大幅度提升了使用PyTorch在Intel处理器上运行AI应用,尤其是深度学习应用的性能。Intel正不断为PyTorch贡献IPEX的优化性能,为PyTorch社区提供最新的Intel硬件和软件改进。更多信息,请参见IPEX。
阿里云不对第三方模型“Stable Diffusion”和“stabilityai/sdxl-turbo”的合法性、安全性、准确性进行任何保证,阿里云不对由此引发的任何损害承担责任。
您应自觉遵守第三方模型的用户协议、使用规范和相关法律法规,并就使用第三方模型的合法性、合规性自行承担相关责任。
本文的示例服务仅用于教程实践、功能测试、POC等场景,其结果数据仅为参考值,实际数据可能会因您的操作环境而发生变化。
前提条件
已在华北2(北京)地域创建一个ACK托管集群Pro版。具体操作,请参见创建ACK托管集群。
准备节点池
普通节点池:已在集群内创建一个使用阿里云第八代企业级实例g8i的节点池,且满足以下要求:
地域及可用区:在ECS实例支持的地域和可用区内。更多信息,请参见ECS实例规格可购买地域总览。
实例规格:CPU为16 vCPU及以上,推荐使用
ecs.g8i.4xlarge、ecs.g8i.8xlarge或ecs.g8i.12xlarge。磁盘空间:节点池内节点可用磁盘空间为200GiB以上(可设置节点系统盘大于200GiB或者增加一块大于200GiB的数据盘)。
TDX机密计算节点池:如您需要将示例应用无缝迁移到TDX机密计算节点池,为推理服务提供数据安全保护,准备工作请参见前提条件。
已通过kubectl工具连接集群。具体操作,请参见获取集群KubeConfig并通过kubectl工具连接集群。
步骤一:准备Stable Diffusion XL Turbo模型
本示例服务使用的Stable Diffusion XL Turbo模型为stabilityai/sdxl-turbo。
操作步骤
使用官方stabilityai/sdxl-turbo模型
将以下示例代码保存为values.yaml文件。您也可以根据集群节点池内的实例规格来调整资源配置。
resources:
limits:
cpu: "16"
memory: 32Gi
requests:
cpu: "14"
memory: 24Gi自定义stabilityai/sdxl-turbo模型
您可以使用存储在OSS上的自定义stabilityai/sdxl-turbo模型。请创建具有OSS访问权限的RAM用户并获取其AccessKey,供下文步骤使用。
操作步骤
将以下示例代码保存为models-oss-secret.yaml。
apiVersion: v1 kind: Secret metadata: name: models-oss-secret namespace: default stringData: akId: <yourAccessKeyID> # 替换为RAM用户的AccessKey ID。 akSecret: <yourAccessKeySecret> # 替换为RAM用户的AccessKey Secret。执行以下命令,创建Secret。
kubectl create -f models-oss-secret.yaml预期输出:
secret/models-oss-secret created将以下内容保存为models-oss-pv.yaml。
apiVersion: v1 kind: PersistentVolume metadata: name: models-oss-pv labels: alicloud-pvname: models-oss-pv spec: capacity: storage: 50Gi accessModes: - ReadOnlyMany persistentVolumeReclaimPolicy: Retain csi: driver: ossplugin.csi.alibabacloud.com volumeHandle: models-oss-pv nodePublishSecretRef: name: models-oss-secret namespace: default volumeAttributes: bucket: "<yourBucketName>" # 替换为待挂载的OSS Bucket的名称。 url: "<yourOssEndpoint>" # 替换为待挂载的OSS的接入域名,推荐使用内网地址。本示例使用oss-cn-beijing-internal.aliyuncs.com。 otherOpts: "-o umask=022 -o max_stat_cache_size=0 -o allow_other" path: "/models" # 模型存放路径,该路径下需要存在stabilityai/sdxl-turbo目录。关于OSS参数配置的更多信息,请参见使用ossfs 1.0静态存储卷。
执行以下命令创建静态卷PV。
kubectl create -f models-oss-pv.yaml预期输出:
persistentvolume/models-oss-pv created将以下内容保存为models-oss-pvc.yaml。
apiVersion: v1 kind: PersistentVolumeClaim metadata: name: models-oss-pvc spec: accessModes: - ReadOnlyMany resources: requests: storage: 50Gi selector: matchLabels: alicloud-pvname: models-oss-pv执行以下命令创建静态卷PVC。
kubectl create -f models-oss-pvc.yaml预期输出:
persistentvolumeclaim/models-oss-pvc created将以下示例代码保存为values.yaml。
您可以根据集群节点池内的实例规格调整来资源配置。
resources: limits: cpu: "16" memory: 32Gi requests: cpu: "14" memory: 24Gi useCustomModels: true volumes: models: name: data-volume persistentVolumeClaim: claimName: models-oss-pvc
服务部署配置说明values.yaml
步骤二:部署示例服务
执行以下命令,在集群内部署一个使用IPEX加速的Stable Diffusion XL Turbo模型。
helm install stable-diffusion-ipex https://aliacs-app-catalog.oss-cn-hangzhou.aliyuncs.com/pre/charts-incubator/stable-diffusion-ipex-0.1.7.tgz -f values.yaml预期输出:
NAME: stable-diffusion-ipex LAST DEPLOYED: Mon Jan 22 20:42:35 2024 NAMESPACE: default STATUS: deployed REVISION: 1 TEST SUITE: None等待约10分钟,然后执行以下命令检查Pod状态,确保运行正常。
kubectl get pod |grep stable-diffusion-ipex预期输出:
stable-diffusion-ipex-65d98cc78-vmj49 1/1 Running 0 1m44s
服务部署完成后,对外提供了一个文生图API。关于API的说明,请参见API说明。
步骤三:测试示例服务
操作步骤
执行以下命令,将Stable Diffusion XL Turbo模型服务转发到本地。
kubectl port-forward svc/stable-diffusion-ipex 5000:5000预期输出:
Forwarding from 127.0.0.1:5000 -> 5000 Forwarding from [::1]:5000 -> 5000使用提示词,请求本地服务生成图片。
本步骤以生成
512x512或1024x1024的图片为例。512x512的图片
执行以下命令,使用提示词
A panda listening to music with headphones. highly detailed, 8k.请求本地的服务执行任务,生成图片。curl -X POST http://127.0.0.1:5000/api/text2image \ -d '{"prompt": "A panda listening to music with headphones. highly detailed, 8k.", "number": 1}'预期输出:
{ "averageImageGenerationTimeSeconds": 2.0333826541900635, "generationTimeSeconds": 2.0333826541900635, "id": "9ae43577-170b-45c9-ab80-69c783b41a70", "meta": { "input": { "batch": 1, "model": "stabilityai/sdxl-turbo", "number": 1, "prompt": "A panda listening to music with headphones. highly detailed, 8k.", "size": "512x512", "step": 4 } }, "output": [ { "latencySeconds": 2.0333826541900635, "url": "http://127.0.0.1:5000/images/9ae43577-170b-45c9-ab80-69c783b41a70/0_0.png" } ], "status": "success" }您可以在浏览器中访问输出包含的URL,查看生成的图片。
1024x1024的图片
执行下面的命令,使用提示词
A panda listening to music with headphones. highly detailed, 8k.请求本地的服务执行任务,生成图片。curl -X POST http://127.0.0.1:5000/api/text2image \ -d '{"prompt": "A panda listening to music with headphones. highly detailed, 8k.", "number": 1, "size": "1024x1024"}'预期输出:
{ "averageImageGenerationTimeSeconds": 8.635204315185547, "generationTimeSeconds": 8.635204315185547, "id": "ac341ced-430d-4952-b9f9-efa57b4eeb60", "meta": { "input": { "batch": 1, "model": "stabilityai/sdxl-turbo", "number": 1, "prompt": "A panda listening to music with headphones. highly detailed, 8k.", "size": "1024x1024", "step": 4 } }, "output": [ { "latencySeconds": 8.635204315185547, "url": "http://127.0.0.1:5000/images/ac341ced-430d-4952-b9f9-efa57b4eeb60/0_0.png" } ], "status": "success" }您可以在浏览器中访问输出包含的URL,查看生成的图片。
测试数据
以下为容器服务ACK团队使用不同ECS g8i实例规格在Stable Diffusion XL Turbo模型中生成512x512、1024x1024图片的耗时信息。下表结果数据仅为实验参考,实际数据可能会因您的操作环境而发生变化。
实例规格 | Pod Request/Limit | 参数 | 单次平均耗时 (512x512) | 单次平均耗时 (1024x1024) |
ecs.g8i.4xlarge (16 vCPU 64 GiB) | 14/16 | batch: 1 step: 4 | 2.2s | 8.8s |
ecs.g8i.8xlarge (32 vCPU 128 GiB) | 24/32 | batch: 1 step: 4 | 1.3s | 4.7s |
ecs.g8i.12xlarge (48 vCPU 192 GiB) | 32/32 | batch: 1 step: 4 | 1.1s | 3.9s |
(可选)步骤四:将服务迁移到TDX机密虚拟机节点池
示例服务部署完成后,您可以将该应用无缝迁移到TDX机密计算节点池中,为您的推理服务提供数据安全保护。
前提条件
已在ACK集群内创建一个TDX机密虚拟机节点池,且TDX机密虚拟机节点池需满足其使用限制。具体操作,请参见创建TDX机密虚拟机计算节点池。
同时,TDX机密虚拟机节点池还需满足以下条件:
实例规格:CPU为16 vCPU及以上(推荐使用ecs.g8i.4xlarge)。
磁盘空间:节点池内节点可用磁盘空间为200GiB以上(可设置节点系统盘大于200GiB或者增加一块大于200GiB的数据盘)。
节点标签:配置节点标签为
nodepool-label=tdx-vm-pool。
操作步骤
将以下内容保存为tdx_values.yaml。
关于values.yaml的完整说明,请参见服务部署配置说明values.yaml。
说明此处以为TDX机密虚拟机节点池配置了标签
nodepool-label=tdx-vm-pool为例。如果您配置了其他标签,需替换nodeSelector中nodepool-label取值。nodeSelector: nodepool-label: tdx-vm-pool执行以下命令,将部署的Stable Diffusion示例模型迁移到TDX机密计算节点池。
helm upgrade stable-diffusion-ipex https://aliacs-app-catalog.oss-cn-hangzhou.aliyuncs.com/pre/charts-incubator/stable-diffusion-ipex-0.1.7.tgz -f tdx_values.yaml预期输出:
Release "stable-diffusion-ipex" has been upgraded. Happy Helming! NAME: stable-diffusion-ipex LAST DEPLOYED: Wed Jan 24 16:38:04 2024 NAMESPACE: default STATUS: deployed REVISION: 2 TEST SUITE: None等待约10分钟,然后检查Pod状态,确保运行正常。
kubectl get pod |grep stable-diffusion-ipex预期输出:
stable-diffusion-ipex-7f8c4f88f5-r478t 1/1 Running 0 1m44s参见步骤三:测试示例服务,再次测试部署在TDX机密计算节点池中的Stable Diffusion示例模型。
参考资料
API说明
当您使用stabilityai/sdxl-turbo模型部署Stable Diffusion XL Turbo服务后,该服务对外提供了一个文生图API。API说明如下。
请求语法
POST /api/text2image请求参数
请求示例
响应参数
响应示例
性能比对
在ACK集群的TDX机密虚拟机节点池中,通过采用ECS g8i实例并结合AMX + IPEX技术,能够有效加速文生图模型的推理速度,并可以开启TEE实现对模型推理的安全保护。本实践教程采用阿里云第八代(Intel至强第五代处理器)ecs.g8i.4xlarge机型运行stabilityai/sdxl-turbo模型及相关的微调模型为例,展示如何实现高性价比、模型安全的文生图推理服务。
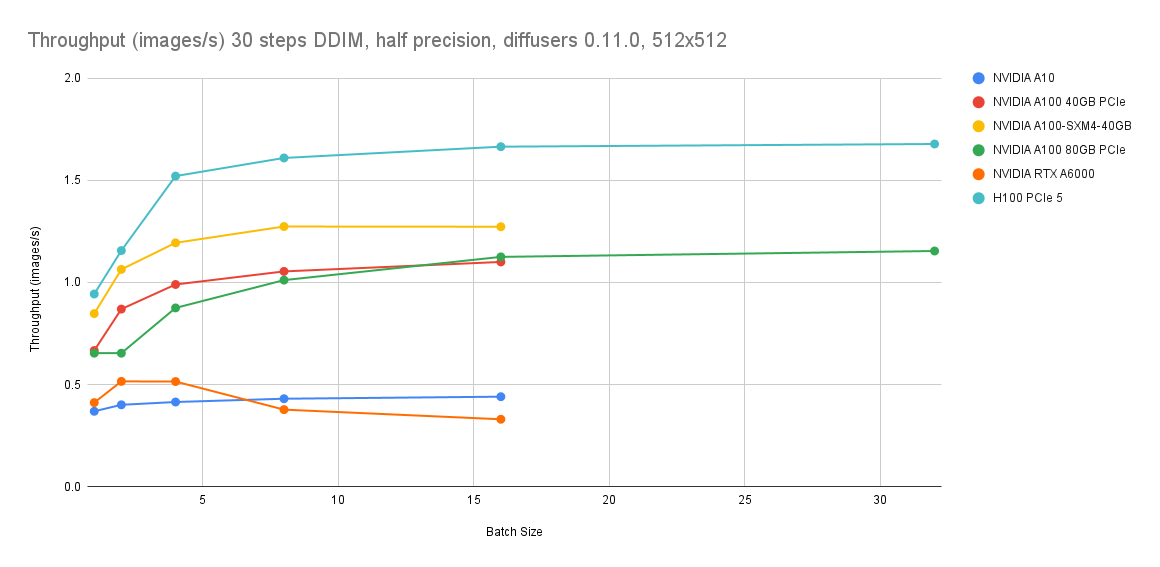
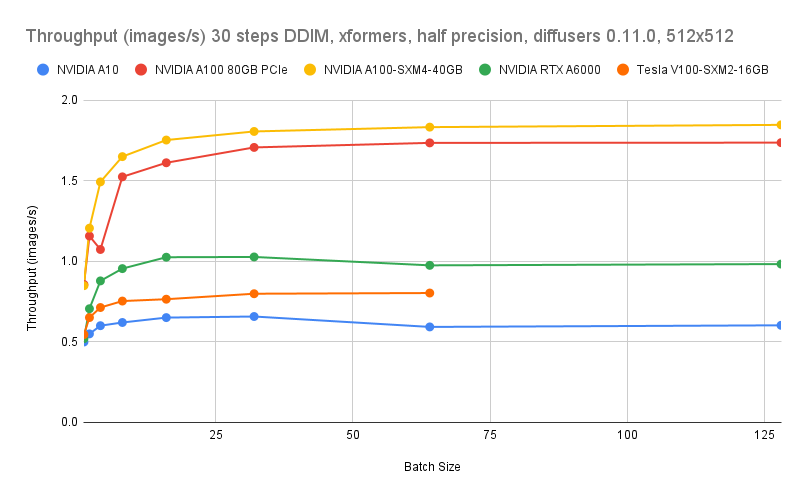
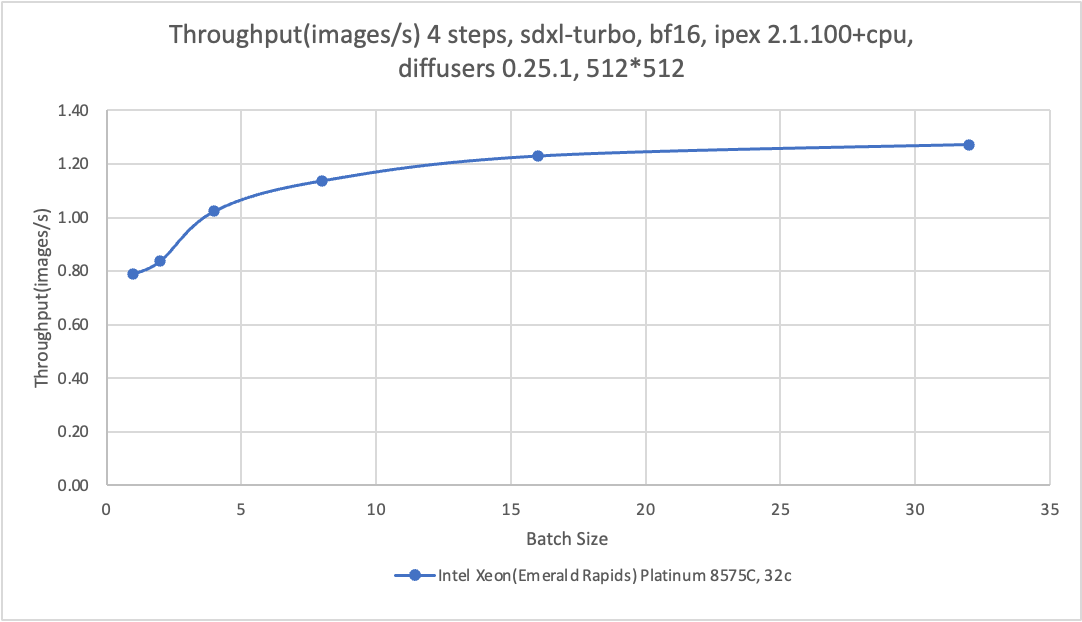
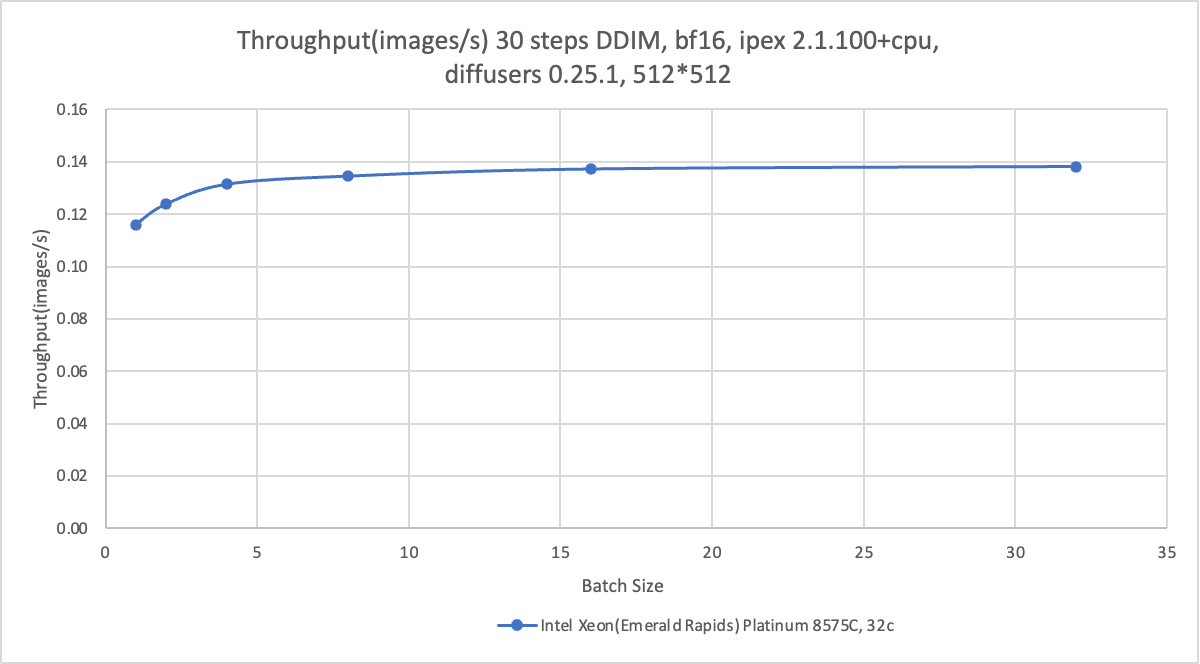
从推理速度的绝对性能来看,CPU的推理速度仍然与A10的GPU实例有所差距。采用ecs.g8i.8xlarge的CPU机型、step为30、batch为16时,图片生成速度为0.14 images/s;采用A10的GPU实例、step为30,batch为16时,图片生成速度为0.4 images/s。但从最佳图像生成质量的推理性能来看,采用ecs.g8i.8xlarge的CPU机型、step为4、batch为16时,图像生成速度为1.2 images/s,仍可实现秒级出图性能。
因此,通过合理运用CPU加速策略和文生图模型推理的最佳实践,ECS g8i等第八代CPU实例可用于替代GPU实例,提供稳定、高效、高性价比且安全机密的文生图服务。
在追求性价比、模型安全TEE和大规模资源供给的文生图推理场景下,建议采用ecs.g8i.4xlarge机型运行stabilityai/sdxl-turbo及相关的微调模型,以最优性价比的方式提供高质量的文生图服务。
使用ecs.g8i.8xlarge实例代替ecs.gn7i-c8g1.2xlarge时,可有效节省约9%的成本,并依然保持1.2 images/s的图像生成速度。
使用ecs.g8i.4xlarge实例替代ecs.gn7i-c8g1.2xlarge时,图像生成速度降为0.5 images/s,但可有效节省超过53%的成本。
不同地域的ECS实例价格请以云服务器ECS定价中的实例价格页签定价为准。
CPU机型
本实践使用阿里云ecs.g8i.8xlarge机型,展示了不同Benchmark取值下及使用不同应用模型时的性能结果。具体信息参见下表。更多信息,请参见Benchmark Tools:lambda-diffusers。
本结果数据仅为参考值,实际数据可能会因您的操作环境而发生变化。
实例规格 | AlibabaCloud ecs.g8i.8xlarge 32vCPU,128GiB VM, EMR | AlibabaCloud ecs.g8i.8xlarge 32vCPU,128GiB VM, EMR |
step | 4 | 30 |
模型 | sdxl-turbo | stable-diffusion-2-1-base |
执行命令 | python sd_pipe_sdxl_turbo.py --bf16 --batch 1 --height 512 --width 512 --repeat 5 --step 4 --prompt "A panda listening to music with headphones. highly detailed, 8k" | python sd_pipe_infer.py --model /data/models/stable-diffusion-2-1-base --bf16 --batch 1 --height 512 --width 512 --repeat 5 --step 30 --prompt "A panda listening to music with headphones. highly detailed, 8k" |
性能趋势 |
|
|
GPU机型
下方数据源于Lambda Diffusers的测试数据,仅供参考。其Benchmark可能会发生变化。实际数据及更多信息请以官方页面Lambda Diffusers Benchmarking inference为准。