在ACK集群中,企业可以通过AI套件中的任务管理工具Arena、队列调度管理系统Kube Queue、配额管理工具ElasticQuotaTree以及Prometheus监控打造企业级任务调度系统。本文将从实际案例出发自底而上地介绍如何基于ACK集群构建一个任务调度系统。
背景介绍
批处理任务(Batch Job)常应用于数据处理、仿真计算、科学计算和人工智能等领域,主要用于执行一次数据处理或模型训练任务。由于这类任务往往需要消耗大量计算资源,因此必须根据任务的优先级和提交者的可用资源情况进行合理排队,才能最大化集群资源的利用效率。为了解决批处理任务的调度问题,企业需要自上而下地解决任务管理、配额管理、任务调度、用户隔离、日志收集、集群监控、资源供给等多方面问题。
为解决以上问题,您可以使用ACK集群来管理大规模集群的管理系统,其较为完善的生态为企业打造大规模任务调度系统扫清了障碍,简化了企业集群管理系统搭建的流程。
用户角色
企业的任务调度系统中通常有两类角色,分别为提交任务的开发人员以及任务调度系统的运维人员。开发人员和运维人员对任务调度系统的需求有所区别。
角色类型 | 说明 |
开发人员 | 专注于自身的业务领域,对任务调度系统使用的Kubernetes系统可能并不熟悉,日常对系统的操作仅为提交任务,因此只需能够简化提交任务流程的工具,并且在提交完任务后,需要能够方便地查看任务的运行时日志以进行Bug修复。 |
运维人员 | 对Kubernetes系统较为熟悉,而对具体的业务领域并不熟悉,需要进行系统的维护并为用户提供高效可靠的任务调度系统,因此需要对Kubernetes集群进行整体的监控。 |
实际使用场景中,开发人员很有可能来自于公司的不同部门,这些不同的部门内部有着自己的任务优先级定义规则,不同部门之间的任务优先级没有关联或关联不大,因此需要将不同部门的任务单独进行排队。
同时,公司内部的可用资源是有限的,为了将资源倾斜给更重要的项目,这些部门的资源配额通常是互不相同。这些资源是受保障资源,只在这些部门的资源配额空闲时允许其他部门临时借用资源运行自己的任务。当集群整体资源紧张时,保障资源的拥有者有权主动驱逐借用资源的部门的任务。
实现原理
如下图所示,企业内部有两个部门:Department-a和Department-b。Department-a有两名员工(User-a和User-b),Department-b有一名员工(User-c)。企业在ACK上构建任务调度系统的过程为:
首先,运维人员需要创建一个ACK集群,并在ACK集群中安装队列调度系统Kube Queue、Prometheus监控以及Arena组件。
Kube Queue可以帮助企业有效地管理大量并发任务,确保资源的合理分配。Kube Queue通过监听ElasticQuotaTree自动为配额生成对应的任务队列,共享同一个配额的任务会一起进行排队。
Prometheus监控提供了实时监控能力,使运维人员能够快速识别并诊断集群中潜在的问题,保证任务调度系统的稳定性和资源利用率。
Arena组件可以简化GPU资源的申请、任务提交、监控等流程。
然后,运维人员再对ElasticQuotaTree以及ResourcePolicy进行配置。
ElasticQuotaTree是一种弹性配额管理机制。通过对Department-a和Department-b分别设定合理的配额,可以确保各部门在共享集群资源时互不影响,避免资源争抢或浪费。
ResourcePolicy定义了资源的使用规则和优先级,通过该方式实现当ECS资源耗尽时将Pod调度到Virtual Node上,触发ECI实例的创建和运行,从而保持整体资源使用的均衡和效率。
最后,开发人员可以通过企业的任务提交平台提交任务或通过ACK AI套件的开发控制台提交任务。

步骤一:搭建环境
已创建ACK集群,且集群版本为1.20及以上。具体操作,请参见创建Kubernetes托管版集群。
ACK集群支持的GPU机型,请参见ACK支持的GPU机型。
为ACK集群部署云原生AI套件,并在部署云原生AI套件时安装Kube Queue和Arena组件。具体操作,请参见安装云原生AI套件。
Kube Queue支持管理TFJob、PyTorchJob以及MPIJob。若需要进一步使用SparkApplication、Argo Workflow、RayJob等工作负载,可以在应用市场页面分别安装ack-spark-operator、ack-workflow以及ack-kuberay等组件。这些组件会在集群中启动各自任务类型的Operator,当集群中对应任务类型被提交时负责在集群中执行相应的任务。
关于应用市场组件的安装,请参见应用市场。关于Kube Queue的详细信息,请参见使用任务队列ack-kube-queue。
为ACK集群安装ACK Virtual Node组件。具体操作,请参见部署ack-virtual-node组件。
ACK Virtual Node组件安装成功后会在ACK集群中生成一个代表ECI实例的虚拟节点,当有Pod需要使用ECI时,该组件会负责完成ECI实例的创建、实例与Pod的绑定,当Pod删除时,该组件会自动清除ECI实例。
默认情况下,调度器不会将Pod调度到Virtual Node上(即不会使用到ECI实例)。如需实现快速扩容和避免消耗过多预算,您可以通过配置ResourcePolicy的方式实现当ECS资源耗尽时将Pod调度到Virtual Node上,从而触发ECI实例的创建和运行,同时,这种配置方式也支持限制ECI实例中的Pod数量。
关于ResourcePolicy的具体用法,请参见自定义弹性资源优先级调度。
(可选)为ACK集群开启阿里云Prometheus监控,并根据需要安装日志组件。具体操作,请参见开启阿里云Prometheus监控。
步骤二:设置集群配额
ElasticQuotaTree介绍
如下图所示,ElasticQuotaTree利用树状结构清晰地展现了企业资源在不同层级(如部门级、用户级)的分配与管理情况。通过为每个User分配独立的Namespace,并将这些Namespace与树中的Children(即资源配额)关联起来,确保了User间资源使用的隔离性,同时允许资源在需要时进行共享。

ElasticQuotaTree中的Root代表整个企业的总资源限额,Children则代表不同的部门(如Department-a和Department-b),如果某个Children下包含多个User的Namespace,说明这些User共享这一部分资源。ElasticQuotaTree中的每个User都有自己单独的Namespace,每个Children都与一个或多个User的Namespace相联系。
操作步骤
创建3个命名空间,分别是user-a、user-b和user-c。
具体操作,请参见管理命名空间与配额。
配置ElasticQuotaTree。YAML文件样例如下所示:
通过ElasticQuotaTree配置文件,给企业中的两个不同部门规划配额。ElasticQuotaTree可以实现部门间资源的动态共享与调整,确保在资源紧张时优先保障各部门的基本需求,同时允许在资源充裕时充分利用集群资源。
当集群资源充足时,Department-a和Department-b的工作负载可以分别使用至各自Max部分所指定的资源上限。
当集群资源不足时,若某个部门的实际资源使用量低于其Min部分的保障性资源,该部门有权抢占另一个部门超出Min部分的资源,以确保自身的资源需求得到满足。
配置完ElasticQuotaTree文件后,执行以下命令,可以看到kube-queue-controller组件会根据ElasticQuotaTree的定义自动为每个叶子Quota在kube-queue命名空间下创建一个Queue对象。
kubectl get queue -n kube-queue预期输出:
NAME AGE root-department-a-user-a 58s root-department-b-user-c 58s设置队列超卖比例。
为了严格按照Quota下发任务,需要您将队列启动参数中的
oversellrate参数调整为1。登录容器服务管理控制台,在左侧导航栏选择集群。
在集群列表页面,单击目标集群名称,然后在左侧导航栏,选择。
在无状态页面的kube-queue命名空间下,单击kube-queue-controller组件操作列下的编辑,将
oversellrate参数由默认值2调整为1。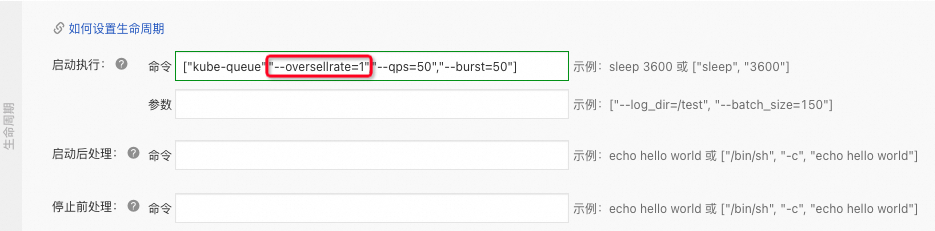
单击页面右侧的更新,在确认弹出框中单击确定,保存参数配置。
步骤三:提交任务并分析结果
场景一:同Quota下,任务按照轮转方式出队
使用以下YAML样例配置任务。
Job配置完成后,将以下命令执行两次,即同一个Quota下提交两次任务。
kubectl create -f pi.yaml # pi.yaml为提交Job的名称。Job的名称可自定义。预期输出:
job.batch/pi-8k5pn created # 第一次提交任务的输出结果。 job.batch/pi-2xtcj created # 第二次提交任务的输出结果。预期输出表明,两个任务均已成功提交。
执行以下命令,查看任务运行情况。
kubectl get pod -n user-a预期输出:
NAME READY STATUS RESTARTS AGE pi-8k5pn-8dn4k 1/1 Running 0 25s pi-8k5pn-lkdn5 1/1 Running 0 25s pi-8k5pn-s9cvm 1/1 Running 0 25s pi-8k5pn-tvw6c 1/1 Running 0 25s pi-8k5pn-wh9zv 1/1 Running 0 25s pi-8k5pn-zsdqs 1/1 Running 0 25s预期输出显示仅第一个任务创建了6个Pod,而非12个Pod,表明仅有第一个任务在运行,第二个任务未启动成功。即同一个Quota下的资源全部被的第一次提交的任务使用了。
执行以下命令,查看user-a命名空间下任务的排队情况。
kubectl get queue -n kube-queue root-department-a-user-a -o yaml预期输出表明,root-department-a-user-a的Queue对象采用了轮转(Round)调度策略,当前队列中有1个活跃工作项。
执行以下命令,从ElasticQuotaTree的Status中查看集群中每个Quota的使用情况。
kubectl -n kube-system get eqtree -ojson elasticquotatree | jq 'status'您将会从预期输出中看到user-a分配到了Root的全部资源,而与user-a处于同一个Quota下的user-b并没有分配到资源。
场景二:同Quota下,任务按照优先级进行阻塞式的出队
本场景基于场景一进行配置。
ack-kube-queue处理任务时默认采用任务轮转机制,如果需要集群中的任务按照优先级进行阻塞式的出队,可以在kube-queue-controller组件中增加一个StrictPriority=true的环境变量,就可以看到所有的队列均已变为Block状态。
为任务开启阻塞队列。具体操作,请参见开启阻塞队列。
提交一个高优先级任务(其优先级需要高于场景一所提交的任务)。示例YAML如下所示:
执行以下命令,查看Queue的状态。
kubectl get queue -n kube-queue root-department-a-user-a -o yaml预期输出表明,高优先级的任务排在了第一位。
场景三:不同Quota下,任务按照优先级进行阻塞式的出队
本场景基于以上的场景二进行配置。
ack-kube-queue处理任务时默认采用任务轮转机制,如果需要集群中的任务按照优先级进行阻塞式的出队,可以在kube-queue-controller组件中增加一个StrictPriority=true的环境变量,就可以看到所有的队列均已变为Block状态。
在user-c命名空间下,提交一个更高优先级的任务,将集群中的资源全部利用。
执行以下命令,查看user-a命名空间下资源的使用情况。
kubectl get pod -o wide -n user-a预期输出:
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES pi-6nsc7-psz9k 1/1 Running 0 45s 192.XX.XX.XX cn-hangzhou.192.XX.XX.XX <none> <none> pi-6nsc7-qtkcc 1/1 Running 0 45s 192.XX.XX.XX cn-hangzhou.192.XX.XX.XX <none> <none> pi-6nsc7-rvklt 1/1 Running 0 45s 192.XX.XX.XX cn-hangzhou.192.XX.XX.XX <none> <none> pi-6nsc7-z4hhc 1/1 Running 0 45s 192.XX.XX.XX cn-hangzhou.192.XX.XX.XX <none> <none> pi-8k5pn-lkdn5 1/1 Running 0 26m 192.XX.XX.XX cn-hangzhou.192.XX.XX.XX <none> <none> pi-8k5pn-ql4fx 1/1 Running 0 25s 192.XX.XX.XX cn-hangzhou.192.XX.XX.XX <none> <none> pi-8k5pn-tcdlb 1/1 Running 0 25s 192.XX.XX.XX cn-hangzhou.192.XX.XX.XX <none> <none> pi-8k5pn-tvw6c 1/1 Running 0 26m 192.XX.XX.XX cn-hangzhou.192.XX.XX.XX <none> <none> pi-8k5pn-wh9zv 1/1 Running 0 26m 192.XX.XX.XX cn-hangzhou.192.XX.XX.XX <none> <none> pi-8k5pn-zsdqs 1/1 Running 0 26m 192.XX.XX.XX cn-hangzhou.192.XX.XX.XX <none> <none>预期输出表明,由于用户user-c提交的任务未达到预设的资源下限(Min),系统允许user-a通过抢占其他任务资源的方式来满足自身需求的过程。
相关文档
关于任务队列的更多信息,请参见使用任务队列ack-kube-queue。