使用Dify服务您可以实现将企业或个人的知识库集成到大模型应用中,从而创建出深度定制化的AI问答解决方案,并且可将其集成到您的业务场景,助力您提升日常研发管理效能。此外在ACK集群上部署服务还支持随业务需求变化即时、平滑地进行扩容,从而有力推动业务发展。
方案概览
Dify定制化AI应用示例
| 网页集成AI应用示例
|
配置一个专属AI问答助手,只需3步:
安装ack-dify组件:先通过容器服务创建一个ACK集群,并安装ack-dify组件。
添加AI问答助手:接着通过访问Dify服务,实现在网站中引入一个AI问答助手。
定制AI问答助手:最后可以通过准备专属知识库,让AI问答助手回答原本无法准确回答的问题,帮助您更好的应对专业问题的咨询。
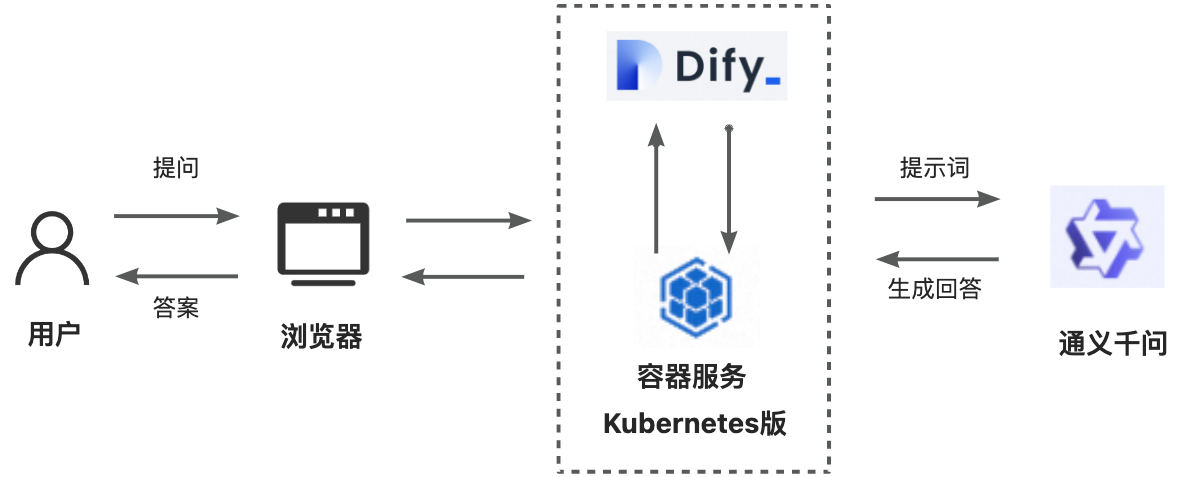
Dify服务和ACK集群交互详情如下图所示。

Dify简介
Dify是一款开源的大语言模型(LLM)应用开发平台。它融合了后端即服务(Backend as Service)和LLMOps的理念,使开发者可以快速搭建生产级的生成式AI应用。即使您是非技术人员,也能参与到AI应用的定义和数据运营过程中。同时Dify内置了构建LLM应用所需的关键技术栈,这为开发者节省了许多重复造轮子的时间,使其可以更加专注在创新和业务需求上。
技术架构如下图所示。

Dify的技术架构包括以下关键部分:
核心技术组件支撑:Dify集成了创建LLM应用程序的核心技术组件,涵盖了对众多模型的兼容支持、用户友好的Prompt设计界面、高性能的RAG(检索增强生成)系统,以及可自定义的Agent架构。
可视化编排和运营:Dify通过其直观的界面,实现了Prompt的可视化编排、运维流程及数据集的高效管理,极大地加速了AI应用程序的开发进程,使开发者能够在短时间内完成部署,或迅速将LLM融入现有系统中,并支持持续性的运维优化。
应用模板和编排框架:Dify为开发者配备了开箱即用的应用模板和编排架构,使得开发者能够依托这些资源迅速开发出基于大规模语言模型的生成式AI应用程序。此外,该平台还支持随业务需求变化即时、平滑地进行扩容,从而有力推动业务发展。
通过这些技术架构的关键组成部分,Dify为开发者提供了一个全面、灵活且易于使用的平台,以支持生成式AI应用的快速开发和部署。
1. 安装ack-dify组件
一键部署
如果您首次使用ACK集群,不了解集群的创建流程,您可以单击文档顶部右上角的一键部署创建Dify服务所需要的运行环境。
建议您在使用一键部署之前检查是否已开通和授权容器服务ACK集群。具体操作,请参见首次使用容器服务Kubernetes版。
本方案的技术架构包括以下云服务:
容器服务 Kubernetes 版:搭建1个ACK Pro集群环境。
云服务器 ECS:2台提供集群服务的ECS。
专有网络 VPC(Virtual Private Cloud):1个专有网络,提供云上私有网络。
弹性公网 IP:允许您将公网IP地址与云服务器、负载均衡等资源进行绑定或解绑。
负载均衡:将来自公网或内网的访问请求根据转发规则和算法分配到后端多台服务器上。
文件存储 NAS:存储您在集群中产生的相关数据。
云盘存储卷:存储卷挂载到容器中满足数据的持久化存储需求。
相关计费信息,请参见计费相关。
如下图①所示,在资源编排ROS中选择您的地域华东1(杭州),然后按照ROS模板选择您的集群可用区、实例规格、实例密码、安全确认等重要信息,其余信息保持默认即可,设置完成后点击创建。
由于集群所需资源较多,需要您耐心等待15分钟左右完成。集群创建完成后,登录容器服务管理控制台,在左侧导航栏选择集群。单击目标集群名称,进入集群详情页面,如下图所示,按照②③④序号依次单击,查看目标集群是否已正常安装ack-dify组件。
如果您发现有Pod处于Pending状态,可能是因为已有集群缺少ack-dify的PVC依赖,请为集群创建默认的CNFS文件系统以及对应的NAS StorageClass。具体操作,请参见通过CNFS管理NAS文件系统(推荐)。更多Pod异常问题排查,请参见Pod异常问题排查。
ack-dify组件安装完成后,您可继续执行下一步操作添加AI问答助手。
手动部署
如果您熟悉ACK集群创建的相关流程,您可以按照以下文档指引自主创建适合您业务的集群环境。
1.1 环境准备
已创建ACK Pro集群,且集群版本为1.22及以上。具体操作,请参见创建ACK托管集群、升级集群。
为确保集群能够稳定运行,您需要为集群预留最小可用资源(2核CPU和4 GB内存),并配置依赖组件CSI。
新建集群时,请选中创建默认NAS文件系统和CNFS容器网络文件系统动态存储类型,并默认开启 NAS 回收站特性,支持数据快速恢复。

已通过kubectl工具连接Kubernetes集群。具体操作,请参见获取集群KubeConfig并通过kubectl工具连接集群。
1.2 组件部署
Dify服务使用的ack-dify组件需要部署在ACK集群之上,您可以按照以下步骤部署组件并排查问题。
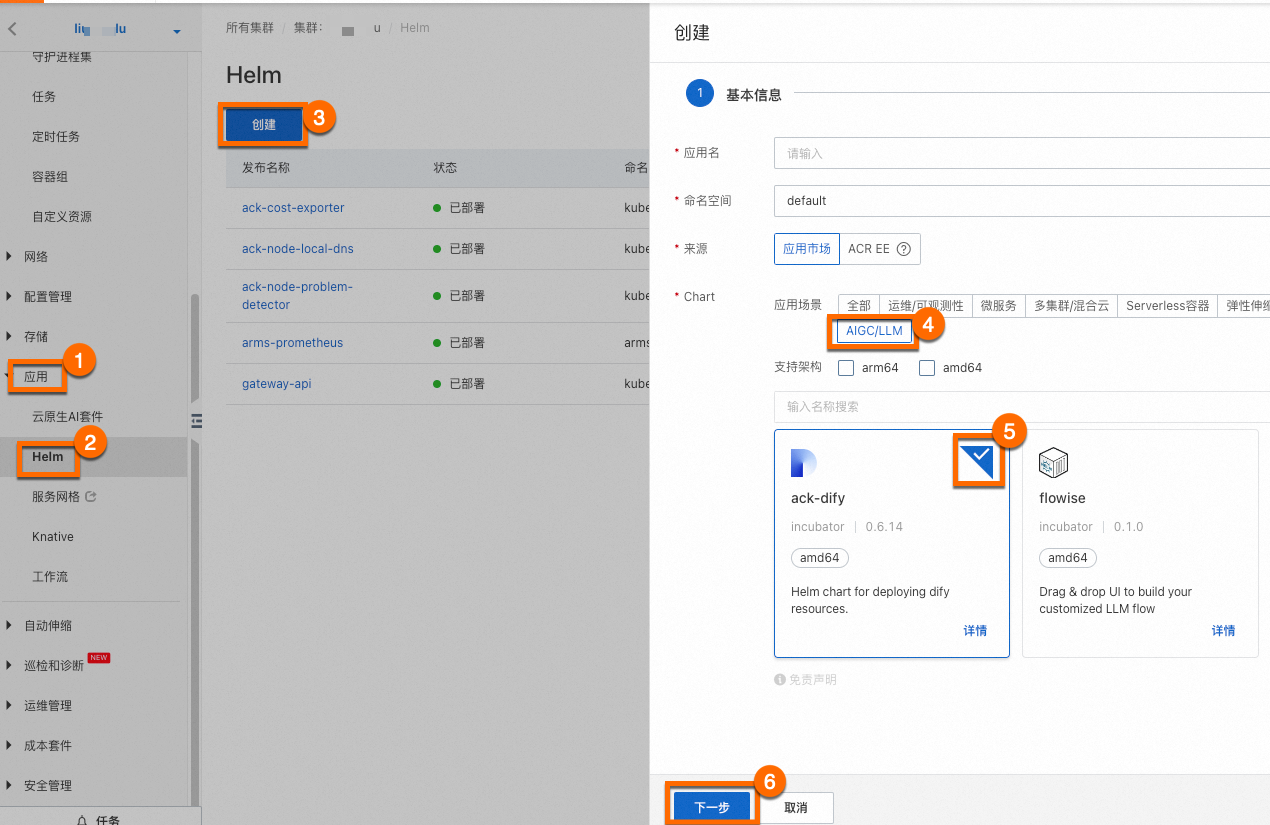
登录容器服务管理控制台,在左侧导航栏选择集群。单击目标集群名称,进入集群详情页面,如下图所示,按照序号依次单击,为目标集群安装ack-dify组件。
您无需为组件配置应用名和命名空间,单击⑥下一步后会出现一个请确认弹框,单击是,即可使用默认的应用名(ack-dify)和命名空间(dify-system)。然后选择Chart 版本为最新版本,单击确定即可完成ack-dify组件安装。
等待1分钟左右,在本地执行以下命令,如果
dify-system命名空间下的Pod均已处于Running状态, 表明ack-dify组件已经安装成功。kubectl get pod -n dify-system如果您发现有Pod处于Pending状态,可能是因为已有集群缺少ack-dify的PVC依赖,请为集群创建默认的CNFS文件系统以及对应的NAS StorageClass。具体操作,请参见通过CNFS管理NAS文件系统(推荐)。更多Pod异常问题排查,请参见Pod异常问题排查。
2. 添加AI问答助手
2.1 访问Dify服务
为ack-dify服务开启公网访问功能。
如果您使用的是生产环境,为了您的应用数据安全,建议您开启访问控制功能。

配置完成后,您会看到ack-dify服务的外部IP地址(External IP),将该外部IP地址输入浏览器地址栏即可访问Dify服务。

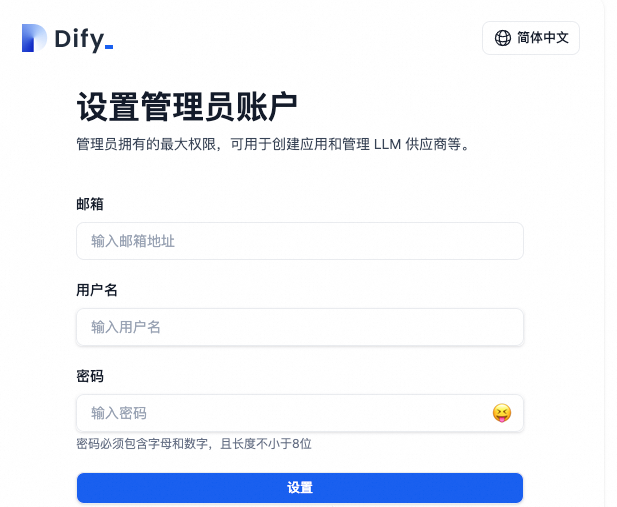
注册账号。
访问外部IP地址(External IP),请根据页面提示设置管理员账户(即邮箱地址、用户名和密码),以注册Dify平台来使用服务。
2.2 创建AI问答助手
在浏览器中输入外部IP地址(External IP),登录Dify平台。
添加并配置所需要的AI模型(以通义千问为例),并为模型配置对应的API Key。如下图所示:
通义千问提供的免费额度消耗完后按Token计费,相比您自主部署大模型可以显著降低初期的投入成本。
获取API Key:依次单击用户名称>设置>模型供应商>通义千问(设置)>从阿里云获取API Key。
将获取到的API Key输入到下图所示的输入栏中,单击保存。
创建一个通用型AI问答助手。
依次单击工作室>创建空白应用,并为AI问答助手输入名称和描述,其他参数保持默认即可。

2.3 验证AI问答助手
现在您可以在页面输入问题以查看目前AI问答助手配置的最新效果。由于下图示例中调用的是一个通用型聊天机器人,所以只能进行简单对话,暂时还无法回答Dify相关的专业问题。

3. 定制AI问答助手
3.1 创建知识库
通过前面的操作,您已经拥有了一个可以对话的AI问答助手。但是如果您想让AI问答助手像专业人士一样,更加精准且专业地回答Dify技术相关的问题,您还需要为AI问答助手配置专属语料知识库。
为简化操作步骤,本示例已经为您整理好语料文件dify_doc.md,您只需按照如下步骤进行操作,即可完成创建和上传专属知识库。
将整理好的语料文件dify_doc.md上传至知识库。
依次单击知识库>创建知识库>导入已有文本>选择文件>下一步。
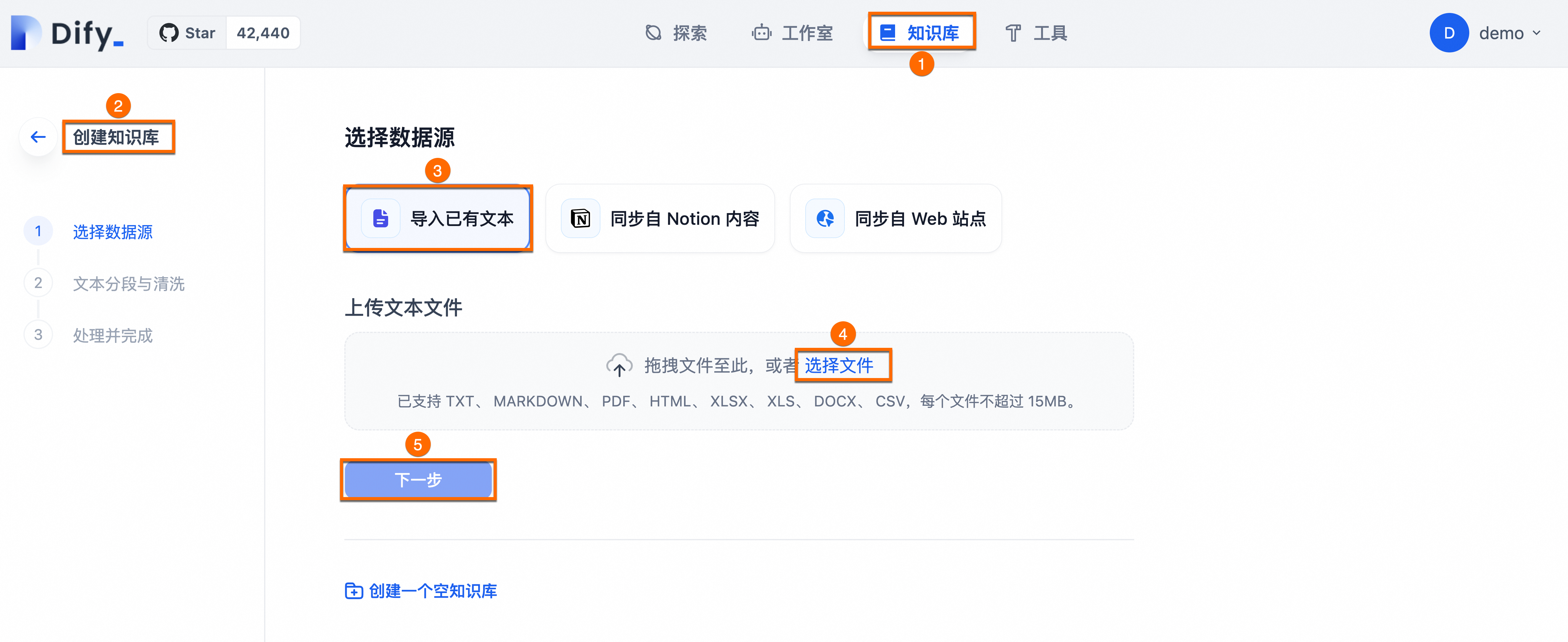
单击下一步后,您可根据页面引导,进行文本分段与清洗。
此处的配置参数保持默认即可。知识库将自动为上传的文档进行清洗、分段并建立索引,以便后续AI问答助手在回答时检索参考。
如果您需要了解上述语料文件是如何整理为一个.md文件,请展开下方折叠项查看详细信息。
3.2 编排并发布AI问答助手
为已创建的AI助手配置提示词并添加上下文知识库。
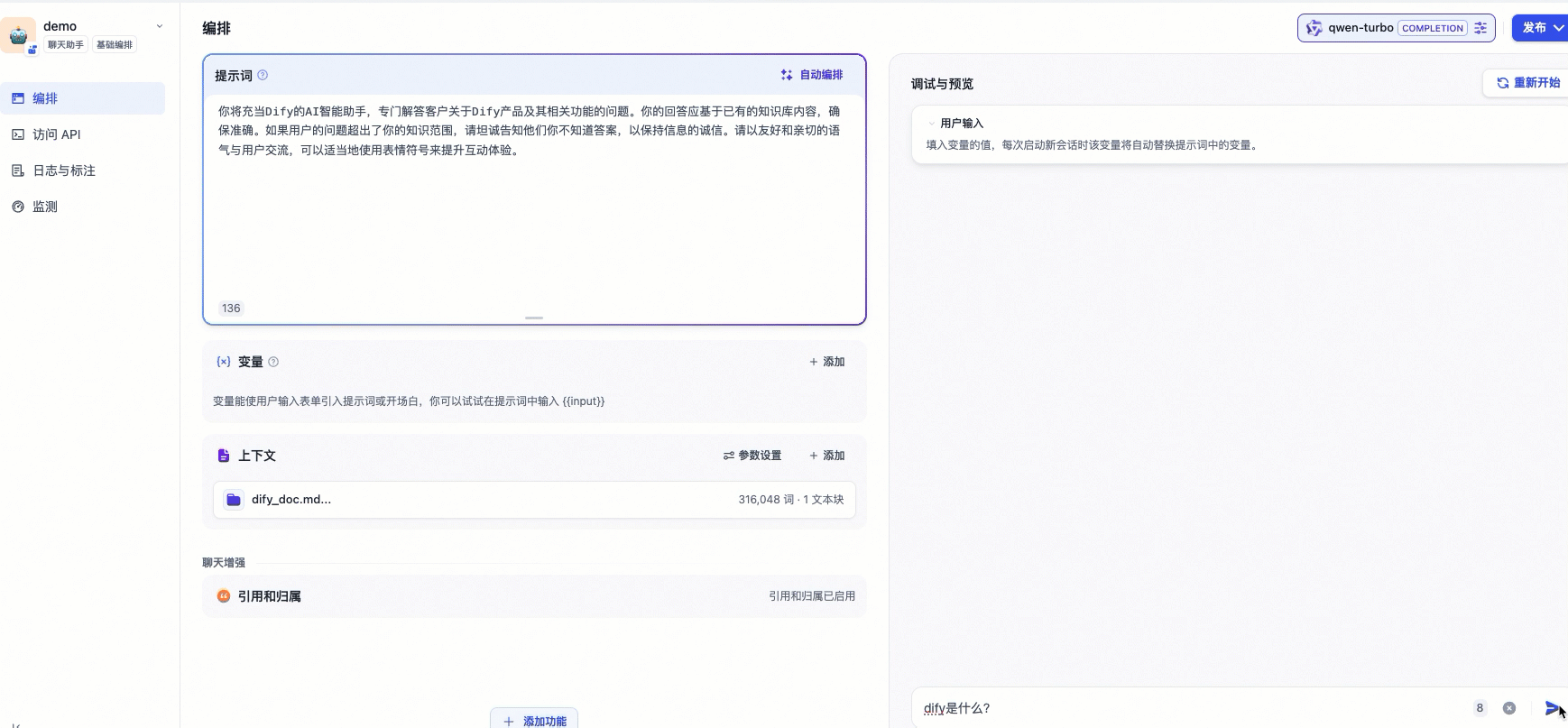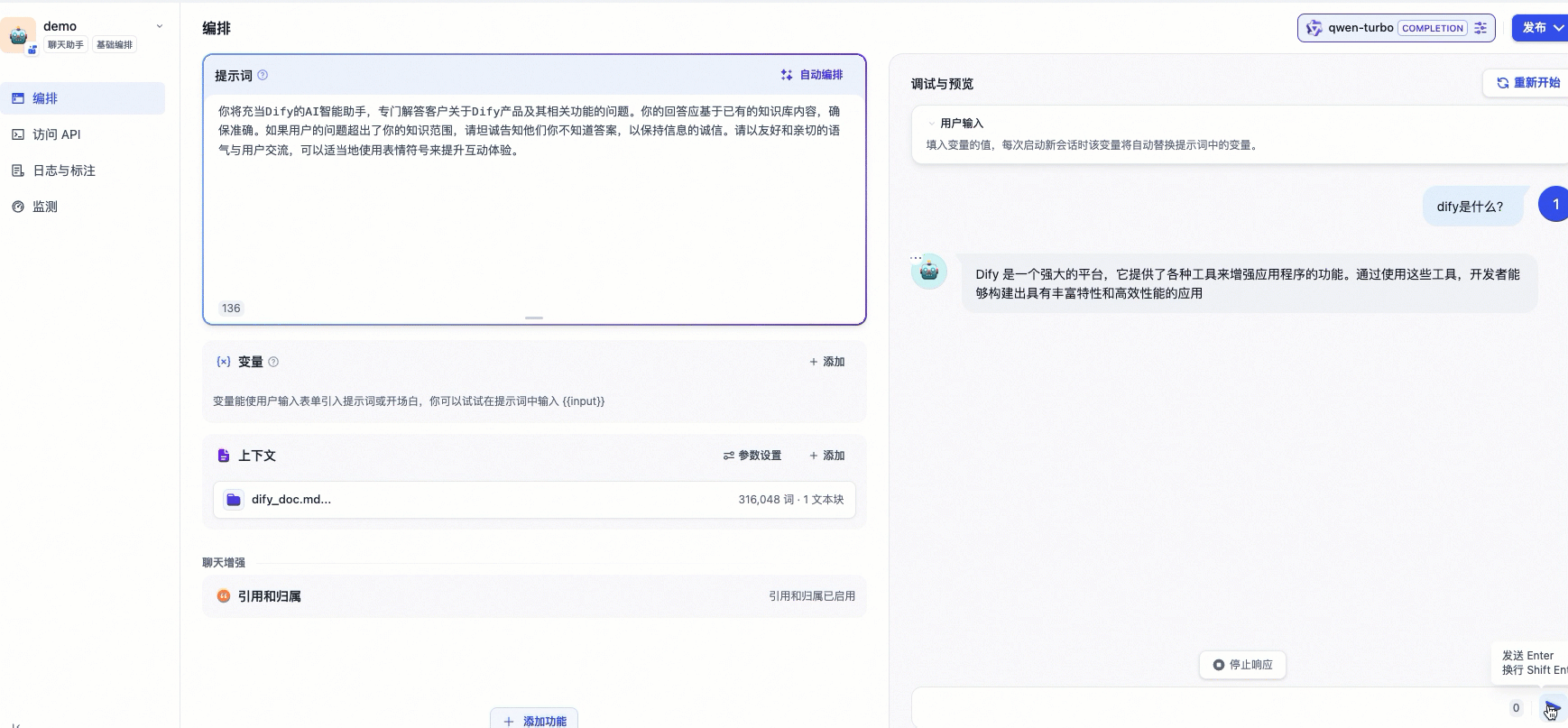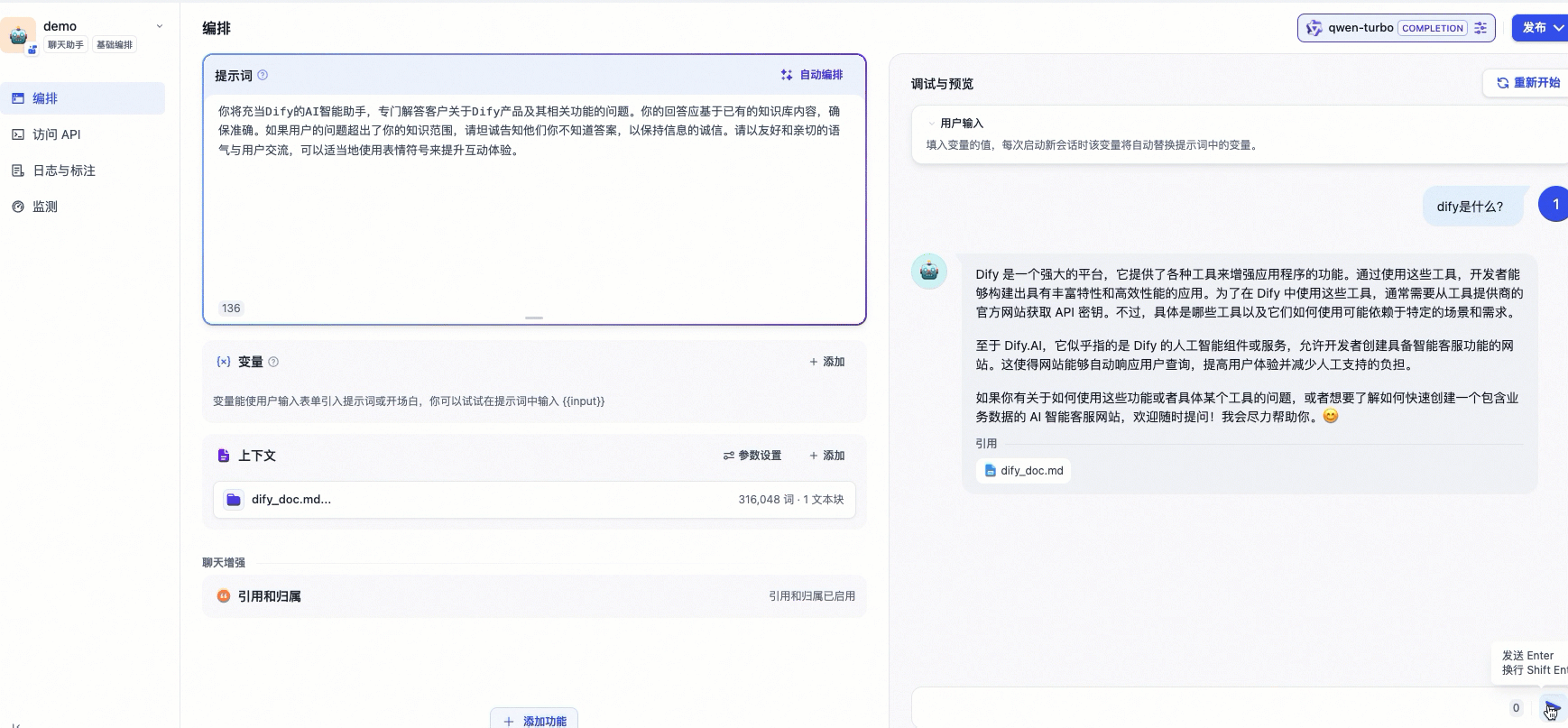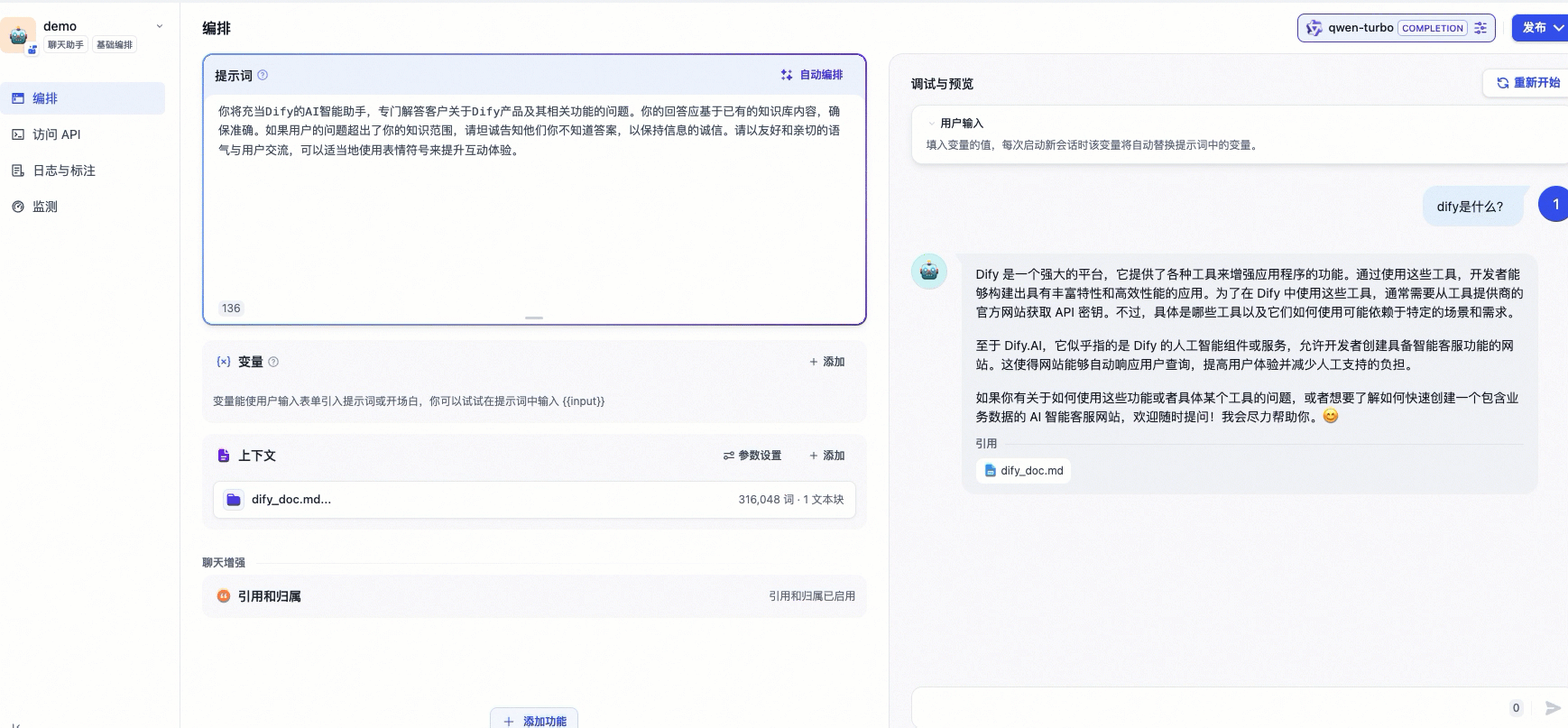
配置提示词:拷贝以下内容至提示词中。提示词用于对AI的回复做出指令和约束,可以提升AI问答助手的回答表现和结果准确性。
您将充当Dify的AI智能助手,专门解答客户关于Dify产品及其相关功能的问题。您的回答应基于已有的知识库内容,确保准确。如果客户的问题超出了您的知识范围,请坦诚告知他们您不知道答案,以保持信息的诚信。请以友好和亲切的语气与客户交流,可以适当地使用表情符号来提升互动体验。添加上下文知识库:单击上下文区域的添加,根据页面提示为AI问答助手配置的专属知识库,使AI问答助手获得精准且专业回答问题的能力。
在页面右上角单击发布>更新手动保存配置信息,使Dify服务的配置生效。
配置效果如下所示:

3.3 检验效果
相较于上文的通用型聊天机器人,配置了专属知识库的AI助手通过集成相关领域的知识库,能够提供更加专业、准确的信息和建议。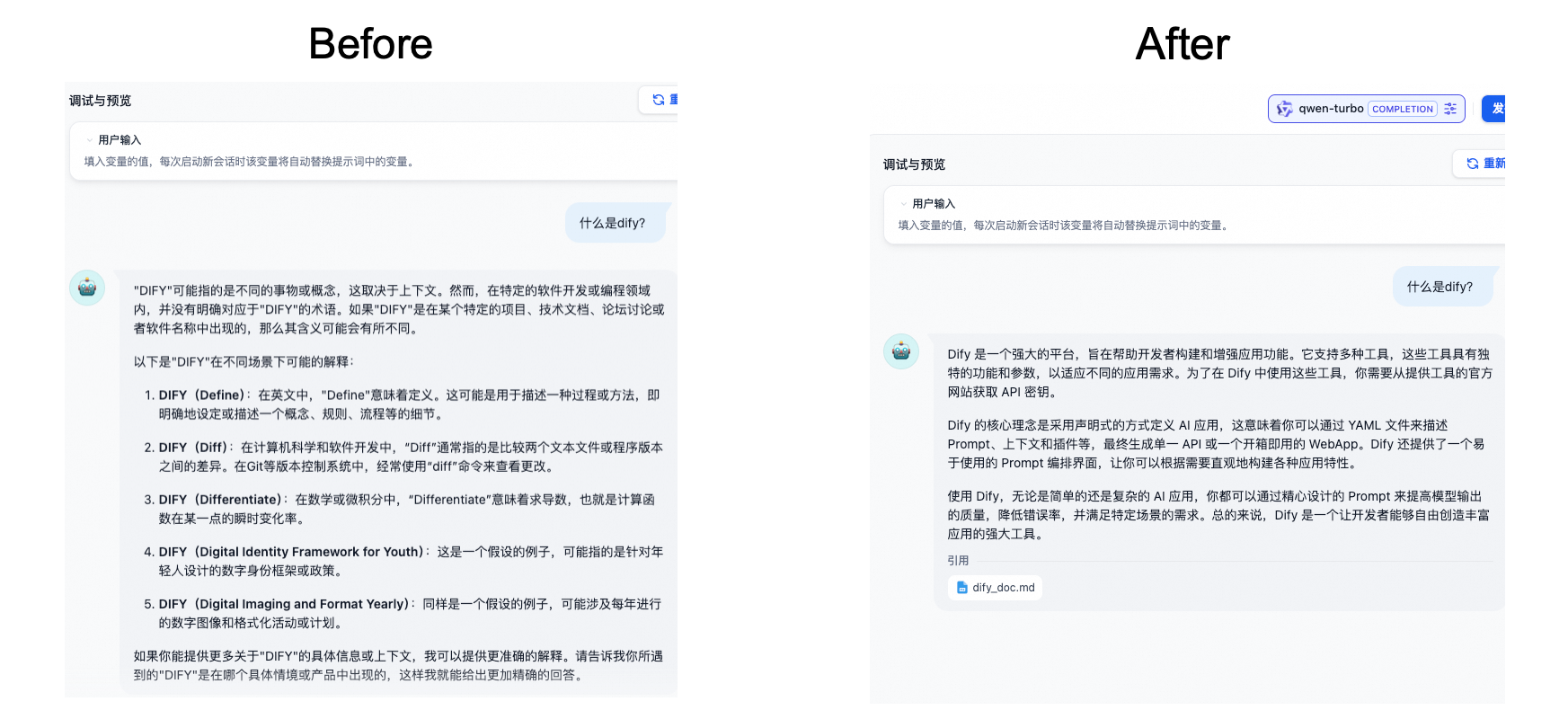
总结
下表归纳总结了Dify具备的核心功能,您可根据个人或企业场景来自主选择使用。
Dify核心功能 | 说明 |
全面的LLMOps | 对于已部署的AI应用,Dify提供完善的运维支持,包括实时监控应用日志和性能指标,以及基于生产数据和用户反馈持续优化提示、数据集和模型。 |
RAG引擎 | Dify提供端到端的RAG管道,支持从文档摄入到信息检索的全流程,能够直接处理PDF、PPT等常见文档格式,简化数据准备工作。 |
Agent | Dify允许开发者基于LLM函数调用或ReAct范式定义Agent,并为其添加预构建或自定义工具,平台内置50多种工具。 |
workflow工作流编排 | Dify提供了一个可视化的画布,允许开发者通过拖拽和连接不同的组件,快速构建复杂的AI工作流,无需深入复杂的代码编写,大大降低了开发门槛。 |
可观测性 | 提供了对LLM应用程序的质量和成本的跟踪和评估能力,通过其监控仪表板,您可以轻松配置和激活这些功能,以增强LLM应用程序的可观测性。 |
企业功能(SSO/访问控制) | 企业组织可降低信息泄露和数据损害的风险,确保信息安全和业务连续。 |
应用到生产环境
如果您想将开发的AI问答助手引入到您企业或个人的生产环境,可以通过以下四种方式操作。
公开分享的网站。
您使用Dify创建AI应用可以发布为一个可供您在互联网上公开访问的Web应用,该应用将根据您的Prompt和编排设置进行工作。详细操作,请参见发布为公开Web站点。
基于API接口调用。
Dify基于“后端即服务”理念为所有应用提供了API,开发者可以直接在前端应用中获取大型语言模型的强大能力,而无需关注复杂的后端架构和部署过程。详细操作,请参见基于APIs开发。
基于前端组件再开发。
如果您是从头开发新产品或者在产品原型设计阶段,您可以使用Dify快速发布AI站点。详细操作,请参见基于前端组件再开发。
嵌入到您企业或个人网站。
Dify支持将您的AI应用嵌入到业务网站中,您可以使用该能力在几分钟内制作具有业务数据的官网AI客服、业务知识问答等应用。详细操作,请参见嵌入网站。
示例(将AI应用嵌入到网站)
下面将为您详细介绍如何将开发的LLM应用嵌入到您企业或个人网站,您可以按照以下示例进行操作。
本示例作为演示,为了您的应用数据安全,建议您在生产环境同时开启访问控制功能。
已为ack-dify服务开启公网访问功能,将该外部IP地址输入浏览器地址栏即可访问Dify服务。更多操作,请参见访问Dify服务。
在ACK集群中快速构建简单的Web应用来调试您的AI问答助手。
下面是一个在ACK集群中部署Web应用的示例,它会在您的ACK集群上运行,您可以嵌入在Dify服务中开发的LLM应用。
获取Dify服务代码。
如下图所示,选择一种方式将聊天应用的对应的代码嵌入到您的网站中。
在ACK集群中,创建一个Deployment来运行您的Web应用,并创建Service来暴露应用。
以下是一个简单的YAML示例,展示如何部署一个包含静态HTML的Nginx服务器。
登录容器服务管理控制台,在配置项页面,选择命名空间为default,然后单击使用YAML创建资源,将下方YAML内容复制到模板中,并将③处的内容替换成您上一步骤获取的Dify服务代码。

具体代码信息,请参考下方示例。
成功部署截图如下所示:
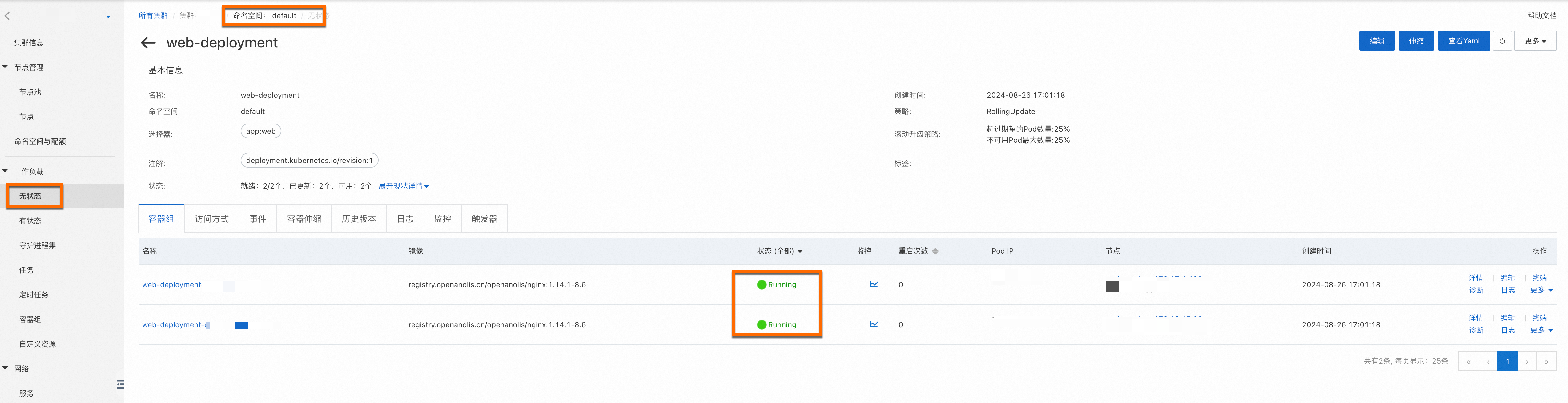
为已部署的服务开启公网访问。
为了您的应用数据安全,建议您在生产环境同时开启访问控制功能。
配置完成后,您会看到web-service服务的外部IP地址(External IP),将该外部IP地址输入浏览器地址栏即可访问Web服务。
 重要
重要如果您想让其他设备访问,请确保您的集群防火墙或安全组中设置允许流量通过80端口。具体操作,请参见添加安全组规则。
确保您的代码和第三方代码是安全的,避免可能的XSS或恶意代码嵌入。给您提供了一个基本示例以供演示,您可以根据自己的需求进行扩展和修改。
结果展示。

持续改进
如果您想进一步改进优化LLM应用,您可以考虑学习并通过阿里云大模型ACA认证,该认证配套的免费课程能帮助您进一步了解大模型的能力和应用场景,以及如何优化大模型的应用效果。
计费相关
使用本功能会收取ACK Pro集群管理费用和阿里云云产品资源费用。使用本功能涉及的阿里云云产品有:ECS云服务器、CLB负载均衡、EIP弹性公网IP、NAS文件存储等,您需要按照各云产品计费规则为使用的资源付费,费用由各云产品收取。关于集群管理费和云产品资源费用的更多信息,请参见计费说明。